智能指针
我们不爱裸指针的原因:
- 裸指针的声明没办法告诉我们它指向的是单个对象还是数组。
- 没办法知道用完这个裸指针后要不要销毁它指向的对象。
- 没办法知道怎么销毁这个裸指针,是用
operator delete还是什么其它自定义的途径。 - 参照原因1,没办法知道该用
delete还是delete[],如果用错了,结果未定义。 - 很难保证调用路径上恰好销毁这个指针一次,可能内存泄露,也可能double free。
- 通常没办法知道裸指针是否是空悬指针,即是否指向已销毁的对象。
智能指针就是来解这些问题的,它们用起来像裸指针,但能避免以上的很多陷阱。C++11中有4种智能指针:std::auto_ptr、std::unique_ptr、std::shared_ptr、std::weak_ptr。其中std::auto_ptr已经过时了,C++11中可以被std::unique_ptr取代了。
unique_ptr
std::unique_ptr体现了显式所有权的语义:
- 非空的
std::unique_ptr总是拥有它指向的对象 - 移动一个
std::unique_ptr会将源指针持有的所有权移交给目标指针; - 不允许复制
std::unique_ptr;(无拷贝构造和拷贝赋值)- 注意可以通过直接初始化使用裸指针构造一个
unique_ptr(如下面的ptr3)
- 注意可以通过直接初始化使用裸指针构造一个
- 只允许移动
std::unique_ptr(只有移动构造和移动赋值) - 非空的
std::unique_ptr总是销毁它持有的资源,默认是通过delete。
所以使用 std::unique_ptr 管理具备专属所有权的资源。unique_ptr的作用基本上就是帮助你进行资源释放(析构)
创建指针
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
struct myobj{
myobj(int x):val(x){}
int val;
};
void deleter(myobj* ptr){
cout <<"deleter called" << endl;
delete ptr; //需要在这里删掉new出来的内容 如果不写的话会内存泄漏。因为智能指针不再执行自己的释放资源的函数。改为执行这个函数。但是这个函数里面如果没有释放资源就会内存泄漏。
ptr = nullptr;
}
template<typename T>
class mydeleter{ //自定义删除器类。functor
public:
void operator()(T* ptr) const{
cout <<"deleter called" << endl;
delete ptr;
ptr = nullptr;
}
};
int main(){
unique_ptr<myobj> ptr1; //空指针
unique_ptr<myobj> ptr2 = new myobj(5); //错误。智能指针构造函数是explicit的。禁止隐式转换,所以不允许带有隐式转换的拷贝初始化。但是可以用直接初始化
unique_ptr<myobj> ptr3(new myobj(5)); //ok
unique_ptr<myobj> ptr3_1 = move(ptr3); //使用move拷贝初始化
unique_ptr<myobj> ptr3_2(move(ptr3)); //使用move直接初始化
unique_ptr<myobj, void(*)(myobj*)> ptr4(new myobj(5), deleter); //自定义删除器。注意需要在自定义删除器内部进行资源释放,因为使用自定义删除器后,智能指针不会接管释放资源。注意这里传入的是函数指针,会使unique_ptr整体增大,变成两个指针。正确使用应该是下面那种定义类型。
unique_ptr<myobj, mydeleter<myobj>> ptr4_1(new myobj(5)); //自定义删除器。注意,这里在尖括号内传入的是仿函数类型。这样会直接使用类型的可调用对象做为删除器。这样效率很高,少一个指针
//所以写自定义删除器的意义是如果你想在某一个资源的析构函数或者是释放资源的同时执行其他动作,就需要写这个。因为,资源的释放阶段是全部交给智能指针接管的。
unique_ptr<myobj> ptr5 = make_unique<myobj>(new myobj(5)); //错误 使用make方法。make_unique是把传入参数完美转发至对象构造函数。只需要传递参数即可,无需再次new。
unique_ptr<myobj> ptr5 = make_unique<myobj>(5); //使用make方法。make方法无法使用自定义删除器和大括号初始化(列表初始化)
unique_ptr<myobj> ptr5_1(make_unique<myobj>(5)); //使用make方法。直接初始化
unique_ptr<myobj> ptr5(ptr3); //禁止拷贝。因为只能有一个unique_ptr指向一个资源。所有权语义。
ptr5 = ptr3; //禁止拷贝赋值。
//------------------------------------------------------------------------
unique_ptr<int>a_ptr(new int(20)); //使用直接初始化
a_ptr = make_unique<int>(30); //依旧可以。这里调用的是operator=,参数是unique_ptr<int>&&。因为make_unique会按值返回一个unique_ptr对象,所以是右值。并且unique_ptr& operator=( unique_ptr&& r )会先把自己的资源释放掉,再接管新的资源,此处不会有内存泄漏。
}
关于make方法无法使用大括号初始化(列表初始化)可以用auto先把大括号接住(推导出一个list initializer类型),然后把auto声明的变量拿过来用。(使用列表初始化构造)。
注意,正确使用自定义删除器应该是定义一个类型并且这个类型需要是空基类而不是传入一个函数指针,这也是为什么unique_ptr把删除器当作类型一部分的原因。如果传入函数指针的话,智能指针大小将会是16。因为他会额外包含一个指针。这里最后提到。
- 关于自定义删除器的意思是:智能指针不再调用自己的函数来释放资源。改为调用你指定的函数。
- 但是要注意,因为智能指针不再调用自己的函数释放资源,你必须在你自己定义的函数内释放对应的资源。
unique_ptr做为自定义对象的成员时,如何构造
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class myobj{
public:
int val;
string str;
unique_ptr<int>u_ptr = nullptr;
myobj(int x, const string& rhsstr, int num): val(x), str(rhsstr), u_ptr(make_unique<int>(num)){} //可以,使用make方法直接初始化
myobj(int x, const string& rhsstr, int num): val(x), str(rhsstr), u_ptr(new int(num)){} //可以,直接使用构造函数初始化
myobj(int x, const string& rhsstr, int num): val(x), str(rhsstr){} //可以
myobj(int x, const string& rhsstr, int num): val(x), str(rhsstr){
u_ptr = make_unique<int>(num); //可以。使用operator=搭配make_unique方法。看上面横线下方的例子。
}
myobj(int x, const string& rhsstr, int* num): val(x), str(rhsstr), u_ptr(num){} //可以。使用裸指针直接初始化
myobj(int x, const string& rhsstr, unique_ptr<int> num): val(x), str(rhsstr), u_ptr(move(num)){} //可以,使用move
myobj(int x, const string& rhsstr, unique_ptr<int> num): val(x), str(rhsstr), u_ptr(num){} //不可以,禁止拷贝初始化
myobj(int x, const string& rhsstr, int num): val(x), str(rhsstr), u_ptr(num){} //不行。unique_ptr没有这个构造函数
myobj(int x, const string& rhsstr, int num): val(x), str(rhsstr){
u_ptr = new int(5); //不可以。没有形参为裸指针的operator=函数。
}
};
- 传入裸指针的时候注意double free问题。
使用get()来获取内部包含的普通指针
1
2
unique_ptr<myobj> ptr5 = make_unique<myobj>(5);
ptr5.get();
所有智能指针都可以通过解引用直接获取值。和普通指针一样。
release()和reset()
release()
u.release()是放弃对指针的控制权,返回指针,并将u置空。意思是释放后会返回裸指针,我们可以继续使用。(释放所有权,但是指向的对象不会被销毁)
reset()
1
void reset( pointer ptr = pointer() ) noexcept;
给定指向 *this 所管理对象的指针 current_ptr ,进行下列行动,以此顺序:
- 保存当前指针的副本
old_ptr = current_ptr - 以传入参数重写当前指针
current_ptr = ptr。 - 若旧指针非空,则删除先前管理的对象
if(old_ptr != nullptr) get_deleter()(old_ptr)。
u.reset()销毁u指向的对象,并将u置为空。意思是释放后无法继续使用。u.reset(q)销毁u原来指向的对象,令u获取q指向对象的所有权。(q的所有权被接管后会成为空指针)- 注意这个要这么用
1 2 3 4
unique_ptr<int> ptr1(new int (10)); unique_ptr<int> ptr2(new int (20)); ptr2.reset(ptr1.release()); //等同于 ptr2 = move(ptr1); ptr2.reset(ptr1); //错误!!!不能这么用。
强调一下上面reset()的顺序。之所以是这个顺序是为了保证抛出异常的时候,新的对象需要被当前指针接管。这样就算再删除旧的对象的时候发生了异常,新的对象已经被当前指针接管了,不会产生悬空对象的问题。因为前两步都是指针之间的赋值,不会有什么异常的可能。但是删除销毁对象的时候则可能出现问题。
operator=(std::nullptr_t)
u = nullptr和使用reset等效- https://zh.cppreference.com/w/cpp/memory/unique_ptr/operator%3D
可能的实现
查看uptr.cpp。简陋版本。
unique_ptr 做为函数入参如何传递比较好?
看情况。
- 一般情况强烈建议使用值传递。因为这显示了所有权转移。但是可能允许使用右值引用为形参。
如:
1
Base(std::unique_ptr<Base> &&n): next(std::move(n)) {}
这时候我可以合法传递临时对象:
1
Base newBase(std::unique_ptr<Base>(new Base));
传递非临时对象依旧必须使用move, 但是会引发一个问题,让调用者困惑。:
1
Base newBase(std::move(nextBase));
这个问题在于。在这一行之后,我们应该期望nextBase已经为空。因为move在那。但是这并不能保证。需要看函数内的代码。
- 什么时候这一行会使得move过的指针不为空:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
void funca(unique_ptr<int>&& ptr){ //注意我们的形参不是值传递,而是右值引用。所以我们没有拷贝,也没有赋值。什么都没做。引用传递不构造新对象对吧?右值引用也是引用呀。所以funca什么都没做。
cout <<"called " << endl;
}
int main(){
unique_ptr<int> ptr1(new int (10));
funca(move(ptr1)); //记住,这里move仅仅是static_cast成了一个右值引用的形式。这时候允许传入funca。具体是否要调用移动构造需要看funca是值传递还是引用传递。
if(ptr1.get() != nullptr){
cout <<"not null" << endl;
}
cout << *ptr1 << endl;
return 0;
}
/*
输出:
called
not null
10
*/
上面的代码看到,我们传入函数后没有对指针产生任何操作。所以是引用传入,然后什么也没干。从头到尾也只有第一行的ptr1和其在函数头的引用ptr在管理同一份资源。由于入参是引用,也没有double free。
记住move只是把参数变为右值。至于什么时候触发移动构造或移动赋值,则需要我们进行赋值或构造的动作。在这里没有任何赋值或构造的动作,自然不会触发移动。
- 什么时候这一行会使得move过的指针为空:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class v{
public:
unique_ptr<int> ptr;
v(unique_ptr<int>&& rhs): ptr(move(rhs)){} //注意这里,我们产生了构造动作。调用了移动构造。
};
void funca(unique_ptr<int>&& ptr){
cout <<"called " << endl;
}
int main(){
unique_ptr<int> ptr1(new int (10));
v obj(move(ptr1));
if(ptr1.get() != nullptr){
cout <<"not null" << endl;
}
else{
cout << "null" << endl;
}
return 0;
}
/*
输出
null
*/
从上面的代码看到,我们的v类构造函数再次使用了move把入参移动赋值给了类内的ptr。因为这里有了构造动作,所以调用了移动构造。所以这时候入参的rhs会被移动到ptr。所以构造对象后,外部的ptr1为空。
- 所以如果使用右值引用做为入参,则调用方不能仅通过函数签名确定传入的智能指针的所有权是否会被转移,依旧需要看函数内部执行了什么,会产生困惑。
如果按照值传递,则传入前需要move接管所有权。此时外部的智能指针已经无效。函数返回后指向的资源会被释放。意味着这个指针(里面包裹的指针)一旦传入函数就不能在函数返回后继续使用。因为已经无效。
- 如果按照引用传递,则表明需要在该函数内修改传入的智能指针。所以又想要在函数调用后继续使用该指针,又不想修改传入的智能指针,最好的办法是使用常量左值引用。
https://stackoverflow.com/questions/8114276/how-do-i-pass-a-unique-ptr-argument-to-a-constructor-or-a-function
https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#r33-take-a-unique_ptrwidget-parameter-to-express-that-a-function-reseats-thewidget
shared_ptr
std::shared_ptr内部有引用计数,被复制时,引用计数+1(因为多个指针指向了同一个对象),有std::shared_ptr析构时,引用计数-1,当引用计数为0时,析构持有的对象。引用就是计算有多少个std::shared_ptr指向了同一个对象。
- 注意,计数器为0释放资源的时候是通过控制块内的指向对象的指针释放的 (通过管理指针)。而不是通过外层的指向对象的指针释放的。(而不是通过存储指针)
引用计数的存在有以下性能影响:
std::shared_ptr的大小是裸指针的两倍:一个指针指向持有的对象,一个指针指向控制块。- 引用计数使用的内存必须动态分配,原因是
std::shared_ptr的引用计数是非侵入式的,必须要独立在对象外面。用std::make_shared能避免这次单独的内存分配。 - 引用计数的加减必须是原子的,因此你必须假设读写引用计数是有成本的。
注意,不是所有std::shared_ptr的构造都会增加引用计数,移动构造就不会。因此移动构造一个std::shared_ptr要比复制一个更快。
与std::unique_ptr类似,std::shared_ptr的默认销毁动作也是delete,且也可以接受自定义的销毁器。但与std::unique_ptr不同的是,std::shared_ptr的销毁器类型不必作为它的模板参数之一。
因此std::shared_ptr要比std::unique_ptr使用更灵活,比如不同销毁器的std::shared_ptr可以放到同一个容器中,而std::unique_ptr则不可以。
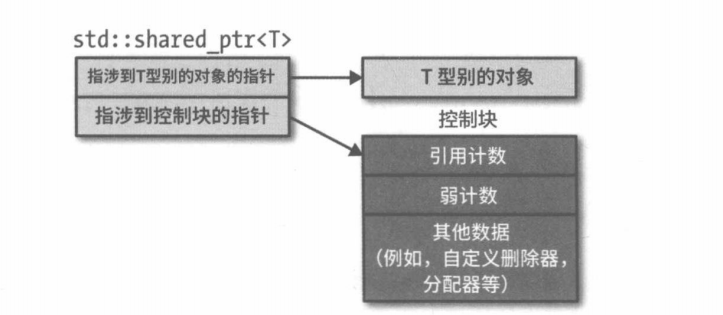
另外,不同的销毁器不会改变std::shared_ptr的大小。std::shared_ptr内部需要为引用计数单独开辟一块内存,那么这块内存中再放一个销毁器也没什么额外开销。实际上这块内存被称为”控制块”,它里面包含以下元素:
- 引用计数
- 弱引用计数 (由
weak_ptr控制) - 其它数据,包括:
- 自定义销毁器
- 内存分配器
- 一个指向对象的指针。但是这个指针的类型是对象的原始类型。这个指针可以叫管理指针。
- 比如
shared_ptr<father> ptr(new child)。这里控制块内指向对象的指针是child类的。而控制块外部另一个指向对象的指针是father类的。至于为什么,看下面的副作用。
- 比如
控制块的创建规则为:
std::make_shared总会创建一个控制块。- 通过一个独享所有权的指针(如
std::unique_ptr或std::auto_ptr)创建出的std::shared_ptr总会创建一个控制块。- 如
std::unique_ptr转为shared_ptr时会创建控制块,因为unique_ptr本身不使用控制块,同时unique_ptr置空)
- 如
- 通过裸指针创建的
std::shared_ptr会创建控制块。- 这意味从同一个裸指针出发来构造不止一个
std::shared_ptr时会创建多重的控制块,也意味着对象会被析构多次。如果想从一个己经拥有控制块的对象出发创建一个std::shared_ptr,可以传递一个shared_ptr或weak_ptr而非裸指针作为构造函数的实参,这样则不会创建新的控制块。
- 这意味从同一个裸指针出发来构造不止一个
- 再次重申,
shared_ptr对象并不包含控制块本身,它包含的是指向控制块的指针。由此会引出make方法的缺点。
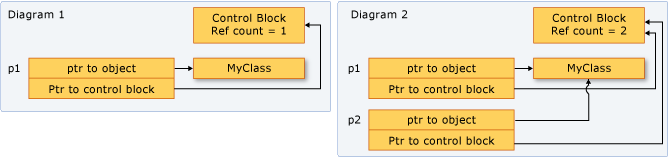
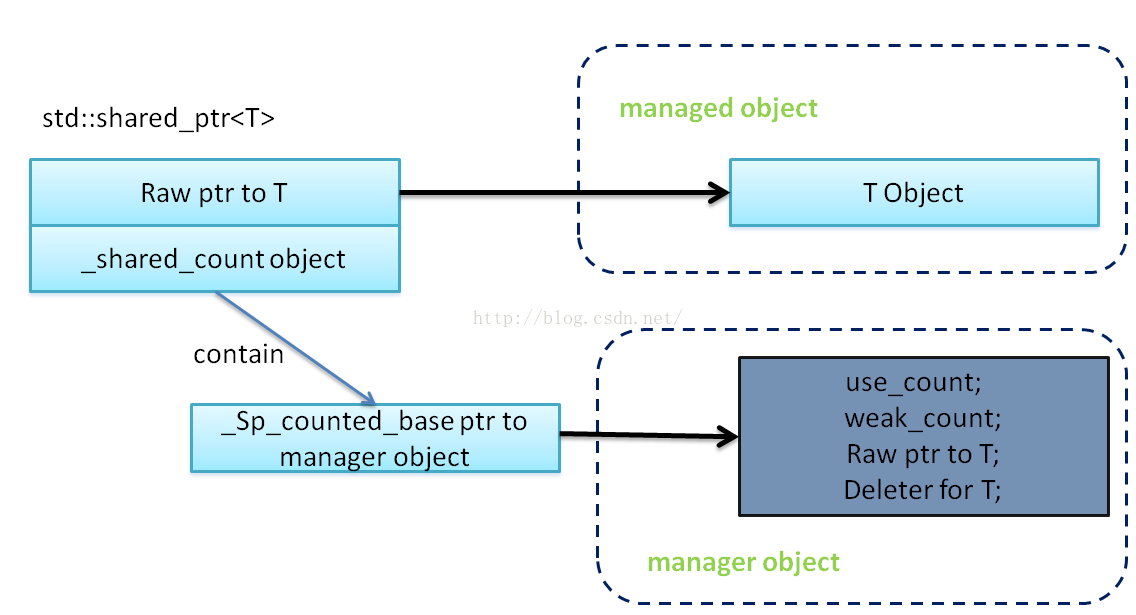
- 从上图我们可以看到,一个
shared_ptr会有两个指针指向同一块堆区内存。一个是外面的那个指针叫做存储指针,一个是控制块里面的那个指针叫管理指针。两者类型并不一定相同。 shared_ptr持有的指针是通过get()返回的(也就是外层的指针);而控制块所持有的指针/对象则是最终引用计数归零时会被删除的那个。两者并不一定相等。
创建指针
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
shared_ptr<myobj> ptr1(new myobj(5)); //创建共享指针
shared_ptr<myobj> ptr2(ptr1); //通过共享指针直接初始化共享指针。两个指针指向同一个数据,所以不新建控制块。引用计数+1
shared_ptr<myobj> ptr3 = ptr1; //可以通过赋值方法拷贝初始化共享指针。两个指针指向同一个数据,所以不新建控制块。引用计数+1
cout << ptr1.use_count() << endl; //使用use_count查看引用计数。输出3
cout << ptr2.use_count() << endl; //输出3
cout << ptr3.use_count() << endl; //输出3
shared_ptr<myobj> ptr4 = make_shared<myobj>(5); //使用make方法创建
shared_ptr<myobj> ptr4_1(make_shared<myobj>(5)); //使用make方法直接初始化
ptr4 = ptr3; //可以拷贝赋值。此时ptr4的控制块引用计数为0。因为被3覆盖了。所以ptr4指向的原始资源析构。ptr4此时和ptr3指向同一资源
cout << ptr4.use_count()<<endl; //共享控制块,此时为4。
shared_ptr<myobj> ptr5 = new myobj(4); //不可以。禁止隐式转换。智能指针构造函数是explicit的。所以不允许使用带有隐式转换的拷贝初始化。但可以使用直接初始化
shared_ptr<myobj> ptr5_1(new myobj(4)); //可以 裸指针直接初始化
shared_ptr<myobj> ptr6(new myobj(4), deleter); //自定义删除器。无需指定类型名。
使用get()来获取内部包含的普通指针
- 这个获取的指针指的是存储指针而非管理指针。
1
2
shared_ptr<myobj> ptr5 = make_shared<myobj>(5);
ptr5.get();
reset()
- 当函数没有实参时,该函数会使当前
shared_ptr所指堆内存的引用计数减 1,同时将当前对象重置为一个空指针。当然,如果指向对象的引用计数为0,则释放资源。注意这个重置为空指针的行为包括剥离与原控制块的访问权限!!因为它已经是空指针,没有理由继续和源对象的控制块有关联。所以就算此时指向的对象计数仍不为0,但是由于此时是空指针,访问空指针的控制块自然会返回引用计数为0。因为空的shared_ptr对象没有控制块- 注意,释放资源是通过控制块内的指向对象的指针释放的 (通过管理指针)。而不是通过外层的指向对象的指针释放的。(而不是通过存储指针)
- 但是reset会置空整个指针。包括控制块。所以意思是存储指针和管理指针都会被剥离(满足条件时释放资源)
- 通过新建临时对象后调用
swap()实现。shared_ptr().swap(*this);shared_ptr的默认构造函数是default的。也就是什么都不做。不给控制块分配空间也不持有任何数据。
- 注意,释放资源是通过控制块内的指向对象的指针释放的 (通过管理指针)。而不是通过外层的指向对象的指针释放的。(而不是通过存储指针)
- 当为函数传递一个新申请的堆内存时,则调用该函数的
shared_ptr对象会获得该存储空间的所有权,并且引用计数的初始值为 1。
举例:
1
2
3
shared_ptr<int> p1 = make_shared<int>(5); //创建指针
p1.reset(); //它将引用计数减少1,同时将当前对象重置为一个空指针。如果引用计数变为0,则释放内存并且删除指针。
p1.reset(new int(34)); //它将原对象引用计数减少1后指向新空间。
注意:置空包括对控制块置空
1
2
3
4
5
6
7
shared_ptr<myobj> shared = make_shared<myobj>(5);
shared_ptr<myobj> shared1(shared);
cout << shared1.use_count()<<endl; //输出2
cout << shared.use_count()<<endl; //输出2
shared1.reset();//把shared1指向对象的引用计数器-1,并且置空shared1指针。包括指向对象的指针和指向控制块的指针
cout << shared1.use_count()<<endl; //置空shared1输出0
cout << shared.use_count()<<endl; //输出1
我们看到,把shared1指向对象的引用计数器-1,并且置空shared1指针。包括指向对象的指针和指向控制块的指针。所以此时我们打印shared1的引用计数是0,如果打印shared的引用计数则是正常的1.
unique()
- 判断是否还有其他的共享指针指向当前指针指向的对象。
注意事项
通过一个裸指针创建两个std::shared_ptr,会创建两个控制块,进而导致这个裸指针会被析构两次!
所以
不要直接用裸指针构造
std::shared_ptr,尽量用std::make_shared直接创建指针。当然在需要自定义的销毁器时不能用std::make_shared。非要用
new构造std::shared_ptr的话,尽量直接new,不要传入已有的裸指针变量。比如1 2 3 4 5 6
myobj* ptr1 = new myobj(1); shared_ptr<myobj> ptr2(ptr1); //ptr2有控制块 shared_ptr<myobj> ptr3(ptr1); //ptr3也有控制块!这样会创建第二个。 //所以尽量直接这样new shared_ptr<myobj> ptr4(new myobj(1));
- 有一种场景下,我们可能无意间创建了对应同一指针的两个控制块。
1
std::vector<std::shared_ptr<Widget>> processedWidgets;
processedWidgets表示所有处理过的Widget。进一步假设Widget有一个成员函数process:
1
2
3
4
5
6
7
8
class Widget {
public:
...
void process() {
...
processedWidgets.emplace_back(this); // this is wrong!
}
};
如果被调用process的Widget对象本身就被std::shared_ptr所管理,上面那行代码会导致它又创建了一个新的控制块。这种情况下我们应该令Widget继承自std::enable_shared_from_this,它允许创建一个指向自身控制块的std::shared_ptr:
1
2
3
4
5
6
7
8
class Widget: public std::enable_shared_from_this<Widget> {
public:
...
void process() {
...
processedWidgets.emplace_back(shared_from_this());
}
};
- 通过栈对象创建
shared_ptr的时候一定要注意传入自定义删除器(接管资源管理)。因为共享指针在引用计数清零时会去delete指向的对象。但此时是个指向栈对象的指针。栈对象不能被delete
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class myobj{
public:
int val;
myobj(int x):val(x){}
};
void deleter(myobj* ptr){
cout <<"deleter called" << endl;
//这里不能delete了 因为是栈对象。
ptr = nullptr;
}
int main(){
myobj s = 100;
shared_ptr<myobj> ptr1(&s,deleter); //接管资源管理
cout << (*ptr1).val << endl;
return 0;
}
- 不要将
this指针返回给shared_ptr。当希望将this指针托管给shared_ptr时,类需要继承自std::enable_shared_from_this,并且从shared_from_this()中获得shared_ptr指针。
并发安全
多线程对同一个共享指针“写”是不安全的
当我们在多线程回调中修改shared_ptr指向的时候。
1
2
3
4
5
6
7
8
void fn(shared_ptr<A>& sp) {
...
if (..) {
sp = other_sp;
} else if (...) {
sp = other_sp2;
}
}
shared_ptr内数据指针要修改指向,sp原先指向对象的引用计数的值要减去1,other_sp指向的引用计数值要加1。然而这几步操作加起来并不是一个原子操作,如果多线程都在修改sp的指向的时候,那么有可能会出问题。比如在导致计数在操作减一的时候,其内部的指向,已经被其他线程修改过了。引用计数的异常会导致某个管理的对象被提前析构,后续在使用到该数据的时候触发core dump。
当然如果你没有修改指向的时候,是没有问题的。
https://juejin.cn/post/7038581008945872927
shared_ptr做为函数入参是用值传递还是引用传递? – 最好使用值传递。但是要具体情况具体分析。
- 首先,对
shared_ptr进行拷贝并不耗费特别多的资源。 - 其次,使用拷贝正是保证了在
shared_ptr对象的作用域中,它一定能指向一个有效的内存对象这一假设。 - 假设:如果我们使用引用传递了这个智能指针,我们在作用域内正在使用这个智能指针的过程中,由于引用计数没有增加,那么可能导致在多线程中,外部的这个资源已经被释放了。因为可能外部的剩下的指向这个资源的智能指针已经超出了生命周期。
- 但是,如果可以确定不会有释放问题,则可以用引用传递稍微的减少开销。但是意义小。
所以,传递shared_ptr参数在一般情况下还是用传值更好!但是依旧要具体情况具体分析。
函数返回值为shared_ptr解析
1
2
3
4
5
6
7
8
9
10
11
12
shared_ptr<int> func1(){
return make_shared<int>(10);
}
int main(){
shared_ptr<int> ptr = func1();
cout << ptr.use_count() << endl; //返回1
return 0;
}
为什么引用计数是1?
- 因为求值运算符从右向左计算,所以首先调用函数,函数返回一个临时的智能指针。所以首先我们
func1函数内make_shared生成(构造,调用构造)一个对象,此时引用计数为1。 - 然后
return产生(拷贝初始化,调用拷贝构造)了一个临时对象,这时候引用计数为2 - 然后离开
func1,对象被析构(调用析构),引用计数-1,此时为1。 - 然后回到
main,拷贝构造(拷贝初始化,调用拷贝构造)给ptr1。引用计数+1,此时为2。同时,因为函数的返回值是临时对象,所以函数返回后会被销毁(调用析构)。引用计数-1,现在依旧是1。+1和-1其实是几乎同步发生的。因为是拷贝到栈帧后直接释放临时对象栈帧。
可能的实现
查看sptr.cpp。简陋版本。
enable_shared_from_this
查看模板的21.2
注意使用问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class st:public enable_shared_from_this<st>{
public:
int val = 100;
shared_ptr<st> getptr(){
return shared_from_this();
}
};
int main(){
st obj;//错误
shared_ptr<st> obj(new st);//正确
shared_ptr<st> t = obj->getptr(); //别搞混了。访问储存的对象的成员函数用->
cout << t->val << endl;
cout << obj.use_count()<<endl;//访问shared_ptr本身的成员函数用.
cout << t.use_count()<<endl;
}
shared_from_this只能用在已经被托管在shared_ptr的对象上。具体原理在分析部分有。- 不能在构造自身的时候或构造函数中使用。
- 核心原因:我们是继承自
enable_shared_from_this。它先初始化,就算它初始化的时候储存的weak_ptr是延迟实例化,但是在我们自己的类被完全构造前,我们是不能构建shared_ptr指向自己的。因为构造函数未完成就是对象构建未完成。我们也不能使用shared_ptr储存一个不完整对象类型本身。因为此时this是不完整的
- 核心原因:我们是继承自
只容许在先前共享的对象,即 std::shared_ptr 所管理的对象上调用
shared_from_this。(特别是不能在构造 *this 期间shared_from_this。)
视频资料:Traps with Smart Pointers
http://hahaya.github.io/use-enable-shared-from-this
https://blog.csdn.net/gong_xucheng/article/details/26839069
https://www.cnblogs.com/fortunely/p/16370208.html
https://stackoverflow.com/questions/31924396/why-shared-from-this-cant-be-used-in-constructor-from-technical-standpoint
weak_ptr
有时候我们需要一种类似std::shared_ptr,但又不参与这个共享对象的所有权的智能指针。这样它就需要能知道共享对象是否已经销毁了。这就是std::weak_ptr。
std::weak_ptr不是单独存在的,它不能解引用,也不能检测是否为空,它就是配合std::shared_ptr使用的。
std::weak_ptr没有解引用和访问成员的功能。也就是不可以操作数据。而且不提供get()函数来获得裸指针。它只获得资源的观测权,不共享资源,它的构造不会引起指针强引用计数的增加。同样,在weak_ptr析构时也不会导致强引用计数的减少
一般来说,weak_ptr需要通过shared_ptr来创建。这样这两个指针会指向同一个数据。但是weak_ptr不会涉及到shared_ptr的强引用计数
- 使用
shared_ptr创建了一个weak_ptr后,计数器内的弱引用计数器会+1,weak_ptr析构后,弱引用计数器会-1
创建指针
1
2
3
4
5
6
7
8
weak_ptr<myobj> ptr2(ptr1); //可以 直接初始化
weak_ptr<myobj> ptr3 = ptr1; //可以 隐式隐式转换后使用拷贝初始化。
weak_ptr<myobj> ptr4(ptr1); //可以 弱指针初始化弱指针
ptr4 = ptr2; //可以 拷贝赋值
weak_ptr<myobj> ptr5(new myobj(7)); //不可以使用裸指针初始化弱指针。
unique_ptr<myobj> ptr7(new myobj(5));
weak_ptr<myobj> test1(ptr7); //不可以使用unique指针初始化弱指针
- 可以使显式使用构造函数通过
weak_ptr对象构建shared_ptr但是非常不推荐
1
shared_ptr<int> sptr(wkptr);
reset(), lock(), use_count(), expired()
use_count()
use_count()返回对应弱指针绑定的共享指针的强引用计数。
举例:
1
2
3
4
5
shared_ptr<myobj> ptr1(new myobj(5)); //创建共享指针
shared_ptr<myobj> ptr2(ptr1); //引用计数+1
weak_ptr<myobj> ptr3(ptr1); //创建弱指针
cout << ptr2.use_count() << endl; //输出2
cout << ptr3.use_count() << endl; //输出2
既然weak_ptr并不改变其所共享的shared_ptr实例的引用计数,那就可能存在weak_ptr指向的对象被释放掉这种情况。这时,就不能使用weak_ptr直接访问对象。那么如何判断weak_ptr指向对象是否存在呢?使用lock() 或 expired()来进行判断。
lock() – 原子地检测对象是否有效并返回一个共享指针。
- 它能原子地检测对象是否有效。如果对象存在,
lock()函数返回一个指向共享对象的shared_ptr(引用计数会增1),否则返回一个空shared_ptr。所以lock()并不是简单的判断。它是通过查看控制块的强引用计数判断的。
expired() – 检测所指向的对象是否被销毁
expired()函数用来判断所指对象是否已经被销毁。如果use_count()是0,则为true。
reset()
- 将对应的弱指针置空。
使用lock()和显式使用构造函数通过weak_ptr对象构建shared_ptr的区别
- 使用
lock()的时候,如果其资源已被释放(强引用计数已为0),则会构造一个空的shared_ptr并返回。 - 如果显式使用构造函数,如果其资源已被释放(强引用计数已为0),则此构造函数会抛出异常。
几种指针的大小
unique_ptr的大小是一个指针或两个指针- 一个指针的时候是不使用自定义删除器 或 使用了仿函数作为自定义删除器
- 两个指针大小的时候是使用了函数指针做为自定义删除器
shared_ptr的大小是两个指针。第一个指针指向的是对象,第二个指针指向的是控制块weak_ptr的大小是两个指针。推测原因:第一个指针指向的是对象,第二个指针指向的是控制块。因为weak_ptr和shared_ptr,继承自同一个基类_Ptr_base。这个基类有两个变量。一个是对象类型的指针element_type* _Ptr, 一个是指向控制块的指针_Ref_count_base* _Rep
weak_ptr和shared_ptr共享控制块
直到释放为止(手动或超出作用域),无论对应的共享指针和其指向的资源是否存在,弱指针都一直存在。只要弱指针还在,共享指针的控制块的弱引用计数就会在。控制块就不会被释放。所以这会产生下面的一个make方法的缺点。
unique_ptr和shared_ptr之间的转换
shared_ptr不可以转换为unique_ptr- 原因非常简单。转换的时候不能保证
shared_ptr的对象现在只被一个指针拥有。而unique_ptr必须保证独占所有权。这种由宽到窄的所有权语义转换是说不过去的。
- 原因非常简单。转换的时候不能保证
unique_ptr可以转换为shared_ptr。 使用move
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main(){
unique_ptr<int> myUnique = make_unique<int>(10);
//shared_ptr<int> myShared = move(myUnique); 也可以
shared_ptr<int> myShared(move(myUnique));
if(myUnique.get() == nullptr){
cout <<"unique释放" << endl;
}
cout << myShared.use_count() << endl;
return 0;
}
/*输出
unique释放
1
*/
unique_ptr也可以隐式转换为shared_ptr。
1
shared_ptr<int> sptr = make_unique<int>(5);
shared_ptr指针的循环引用问题
如下面代码所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class B;
class A{
public:
shared_ptr<B> bptr;
~A(){
cout << "A destory" << endl;
cout << bptr.use_count() << endl;
}
};
class B{
public:
//weak_ptr<A> aptr;
shared_ptr<A> aptr;
~B(){
cout << "B destory" << endl;
cout << aptr.use_count() << endl;
}
};
int main(){
{
shared_ptr<A> classA(new A());
shared_ptr<B> classB(new B());
cout << classA.use_count() << endl; //1
cout << classB.use_count() << endl; //1
classA->bptr = classB;
cout << classA.use_count() << endl; //1
cout << classB.use_count() << endl; //2
classB->aptr = classA;
cout << classA.use_count() << endl; //2 //换成弱指针之后这里为1。因为弱指针不计数
cout << classB.use_count() << endl; //2
//所有的析构都不会执行。
//换成弱指针,所有析构正常执行。
}
return 0;
}
当我们在两个类中互相包含一个指向对方类的shared_ptr的时候,会发生互相引用。这导致了每一个对象的引用计数都会永远至少保持为1。可以理解为两个指针互相都想让对方放开,但是两个人都必须等对方放开了自己才能放开对方。这样就发生了内存泄漏。
解决方案就是把其中一个类的共享指针换成弱指针。因为弱指针的引用不会增加计数。所以那个类的引用计数会到0从而正确释放。
如上面代码,把B的共享指针换成弱指针即可。
More Effective C++ 条款21
先做一下介绍,std::make_shared是在C++11中增加的,但std::make_unique却是在C++14中增加的。如果你想在C++11中就用上std::make_unique,自己写一个简单版的也不难:
1
2
3
4
template <typename T, typename... Ts>
std::unique_ptr<T> make_unique(Ts&&... params) {
return std::unique_ptr<T>(new T(std::forward<Ts>(params)...));
}
这个版本不支持数组,不支持自定义的销毁器,但这些都不重要,它足够用了。但要记住的是,不要把它放到namespace std下面。
这两个make函数的功能就不解释了,和它们类似的还有一个std::allocate_shared。
make方法的优点
make方法是把传入参数完美转发至对象构造函数。只需要传递参数即可,无需再次new。
- 第一个好处:不需要重复写一遍类型。所有程序员都知道:不要重复代码。代码越少,bug越少。
1
2
3
4
5
auto upw1(std::make_unique<Widget>());
std::unique_ptr<Widget> upw2(new Widget);
auto spw1(std::make_shared<Widget>());
std::shared_ptr<Widget> spw2(new Widget);
- 第二个好处:异常安全性。想象我们有两个函数:
1
2
void processWidget(std::shared_ptr<Widget> spw, int priority);
int computePriority();
调用代码很可能长成这个样子:
1
processWidget(std::shared_ptr<Widget>(new Widget), computePriority()); // potential resource leak!
上面这行代码有内存泄漏的风险,为什么?根据C++标准,在processWidget的参数求值过程中,我们只能确定下面几点:
new Widget一定会执行,即一定会有一个Widget对象在堆上被创建。std::shared_ptr<Widget>的构造函数一定会执行。computePriority一定会执行。
new Widget的结果是std::shared_ptr<Widget>构造函数的参数,因此前者一定早于后者执行。除此之外,编译器不保证其它操作的顺序,即有可能执行顺序为:
new Widget- 执行
computePriority - 构造
std::shared_ptr<Widget>
如果第2步抛异常,第1步创建的对象还没有被std::shared_ptr<Widget>管理,就会发生内存泄漏。
如果这里我们用std::make_shared,就能保证new Widget和std::shared_ptr<Widget>是一起完成的,中间不会有其它操作插进来,即不会有不受智能指针保护的裸指针出现:
1
processWidget(std::make_shared<Widget>(), computePriority()); // no potential resource leak
- 第三个好处:更高效。
1
std:shared_ptr<Widget> spw(new Widget);
这行代码中,我们以为只有一次内存分配,实际发生了两次,第二次是在分配std::shared_ptr控制块。我们前文提到过,共享指针的控制块是单独建立在堆上的。所以如果使用直接new的方式,在分配完我们想要分配的变量后,系统会再次分配一块空间给控制块。所以分配了两次内存。
但是如果用std::make_shared,它会把Widget对象和控制块合并为一次内存分配。但是这也会成为缺点
make方法的缺点
第一个缺点:无法传入自定义删除器。
1 2 3 4 5
template<typename _Tp, typename... _Args> inline typename _MakeUniq<_Tp>::__single_object make_unique(_Args&&... __args){ return unique_ptr<_Tp>(new _Tp(std::forward<_Args>(__args)...)); }
- 这里返回的是默认删除器类型的
unique_ptr。 - 来自这里
- 第二个缺点:无法使用列表初始化。必须用
auto先推导出来一个initializer_list然后把初始化列表传入。 - 第三个缺点:对象和控制块分配在一块内存上,减少了内存分配的次数,但也导致对象和控制块占用的内存也要一次回收掉。即,如果还有
std::weak_ptr存在,控制块就要在(因为控制块中有一块弱引用,储存着弱指针的引用),对象占用的内存也没办法回收。如果对象比较大,且std::weak_ptr在对象析构后还可能长期存在,那么这种开销是不可忽视的。也就是假如shared_ptr本身被析构了(因为自己和控制块是分开的),weak_ptr可能过了很久才被析构。这样这一大块内存就都要存在,因为用make方法分配的是一整块
如果我们因为前面这三个缺点而不能使用std::make_shared,那么我们要保证,智能指针的构造一定要单独一个语句。回到之前processWidget的例子中,假设我们有个自定义的销毁器void cusDel(Widget* ptr);,因此不能使用std::make_shared,那么我们要这么写来保证异常安全性:
1
2
std::shared_ptr<Widget> spw(new Widget, cusDel);
processWidget(spw, computePriority());
但这么写还不够高效,这里我们明确知道spw就是给processWidget用的,那么可以使用std::move,将其转为右值,来避免对引用计数的修改:
1
2
std::shared_ptr<Widget> spw(new Widget, cusDel);
processWidget(std::move(spw), computePriority());
- 不适于使用
make系列函数的场景包括- 需要定制删除器,
- 期望直接传递大括号初始化物
- 需要自定义内存管理(自定义删除器)
- 内存紧张的系统
- 非常大的对象
- 存在比指涉到相同对象的
std: :shared_ptr生存期史久的std: :weak_ptr
稍微具体说一下自定义删除器为什么用类的时候不增加大小,用函数指针的时候会增加大小
先看一下unique_ptr的析构
1
2
3
4
5
6
_Compressed_pair<_Dx, pointer> _Mypair; //mypair定义。_Dx是自定义删除器类型
~unique_ptr() noexcept {
if (_Mypair._Myval2) {
_Mypair._Get_first()(_Mypair._Myval2); // call deleter
}
}
这里用_Get_first把_Mypair的第一个数据也就是自定义删除器提取出来,然后用()创建临时对象,然后把数据塞入这个临时对象的operator()里面完成资源释放。
但是这个_Compressed_pair有两个特化版本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
// store a pair of values, deriving from empty first
template <class _Ty1, class _Ty2, bool = is_empty_v<_Ty1> &&
!is_final_v<_Ty1>>
class _Compressed_pair final : private _Ty1 {
public:
_Ty2 _Myval2;
// ... the rest of impl
}
// store a pair of values, not deriving from first
template <class _Ty1, class _Ty2>
class _Compressed_pair<_Ty1, _Ty2, false> final {
public:
_Ty1 _Myval1;
_Ty2 _Myval2;
// ... the rest of impl
}
先看第二个版本,这个很直观,基本就是普通的 std::pair 的定义。
而当 _Ty1 (自定义删除器)是一个空类时,则会特化为第一个版本。这里 _Ty2 依然作为一个普通的成员,但 _Ty1 却通过继承的方式内嵌到 _Compressed_pair 中。乍一看这好像有点不伦不类,毕竟从概念上来说 _Compressed_pair 和 _Ty1 似乎不应该是继承的关系。但注意这里用的是 private 继承,相较于 public 继承表达的 is-a 关系,private 继承隐含的意思其实是 is-implemented-in-terms-of,即「由…实现出」。这就说得通了,_Ty1 是组成 _Compressed_pair 的一部分,反过来 _Compressed_pair 是由 _Ty1 实现的。这也是为什么很多情况下,组合和 private 继承这两种设计可以互换的原因,详细内容可以参阅 《Effective C++》Item 38。
空类继承不会增加体积。因为有空基类优化。所以传入一个仿函数(无成员变量,所以是空类)的时候会匹配到第一个模板,使用空基类优化使得不需要额外空间。
所以如果自定义删除器传入一个函数指针,因为不是空类而是一个函数指针,会被匹配到第二个模板。所以会把函数指针在_Ty1 _Myval1;这里存下来。就多了一个指针。
为什么删除器是unique_ptr的模板参数之一(是类型的一部分), 而shared_ptr不是?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template <class T, class D = default_delete<T>>
class unique_ptr {
public:
...
unique_ptr (pointer p,
typename conditional<is_reference<D>::value,D,const D&> del) noexcept;
...
};
template <class T>
class shared_ptr {
public:
...
template <class U, class D>
shared_ptr (U* p, D del); //删除器只是构造函数参数的一部分,而不是shared_ptr类型的一部分
...
};
首先,为了尽可能让unique_ptr的性能贴近裸指针,比如在删除器为非函数指针的时候,可以触发空基类优化,使得无需额外空间。其次,主要的一点是unique_ptr的删除器是编译时绑定的,所以我们必须显式指定其类型。而shared_ptr的删除器是运行期绑定的,所以不需要。正因为共享指针的删除器是运行时绑定,则必须要有一个额外的指针(控制块)指向(保存)删除器来让共享指针可以访问。因为删除器的类型是运行时绑定所以直到运行的时候才能知道。所以调用删除器的时候会有一次额外的寻址操作。
另外,正因为如此,unique_ptr的删除器,在使用reset更换的时候只可以更换同类型的删除器。而shared_ptr的删除器可以在reset的时候随意更换。因为类成员类型在运行期间是不可以改变的。而删除器的类型不是共享指针的一部分。
(此部分参照了c++ primer P.599)
https://fuzhe1989.github.io/2017/05/19/cpp-different-role-of-deleter-in-unique-ptr-and-shared-ptr/
https://stackoverflow.com/questions/24365250/why-does-stdunique-ptr-need-to-be-specialized-for-dynamic-arrays
lambda和智能指针之间的联系 (小米面经)
用lambda捕获uniquePtr应该怎么做 – 必须按照引用捕获
lambda我们知道,如果按值捕获,他会对捕获的对象进行一个拷贝。因为可以把lambda对象理解为一个匿名类,那么捕获的变量就是这个匿名类的成员变量。这个匿名类重载了operator()并且设置其为const
但是,unique_ptr是所有权语义。它不允许被拷贝。所以必须按照引用捕获。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct myobj{
myobj(int x):val(x){}
int val;
};
int main(){
unique_ptr<myobj> unique = make_unique<myobj>(5);
auto lambda = [=](int a){ unique->val = unique->val + a;}; //报错,因为unique_ptr不允许拷贝。
auto lambda = [&](int a){ unique->val = unique->val + a;};
lambda(10);
cout << unique->val<< endl; //输出15
return 0;
}
但是这样做也不好,会有语义问题。参考:https://zhuanlan.zhihu.com/p/101938827 和 下面的问题
lambda捕获uniquePtr后如何避免调用lambda时uniquePtr的指针已失效 – 使用c++14的移动捕获(通用捕获)[使用带有初始化器的捕获符捕获仅可移动的类型。]
也是为了解决上面的语义问题,我们应该把unique_ptr移入到lambda, 如果想的话也可以再移回原指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
struct myobj{
myobj(int x):val(x){}
int val;
};
int main(){
unique_ptr<myobj> unique = make_unique<myobj>(5);
auto lambda = [&, temp_unique = move(unique)](int a) mutable{ //注释1
temp_unique->val = temp_unique->val + a;
unique = move(temp_unique); //注释2
};
lambda(10);
cout << unique->val<< endl;
return 0;
}
//上面这个例子并不太好。因为我们做的事情是:引用捕获unique,然后把unique移动到一个新建的lambda内局部变量temp上。
//然后对temp进行处理,然后再移动到unique上。这也是为什么必须有一个&来引用捕获unique。这完全脱裤子放屁
//所以正常这种情况下的使用方式应该是移动进lambda后,外部不会再使用该智能指针
int main(){
unique_ptr<myobj> unique = make_unique<myobj>(5);
auto lambda = [temp_unique = move(unique)](int a) mutable{ //移动进来
temp_unique->val = temp_unique->val + a;
cout << temp_unique->val << endl; //对数据处理。
};
lambda(10);
//外部并不会再次使用unique指针。
return 0;
}
- 注释1
- 这里有一个看起来很奇怪的东西。
temp_unique = move(unique)。这个东西叫做带有初始化器的捕获符(列表)[来自校友赖斯理大佬的博客https://lesleylai.info/zh/c++-lambda/#fn-3] - 等号左侧是表达式中数据成员的名称,这个是由你自由决定的。等号右侧是初始化表达式,用于初始化数据成员。等号左右两侧的作用域是不同的,左侧的作用域在lambda表达式中,而右侧的作用域在表达式定义的区域。在上面的例子中,等号左侧的
temp_unique指的是lambda中的数据成员,而右侧则是在lambda表达式上方定义的unique。因此temp_unique = move(unique)意味着在lambda中创建一个数据成员temp_unique,并且用std::move一个本地变量的unique以初始化这个数据成员。
- 这里有一个看起来很奇怪的东西。
- 注释2
- 这里不可以写成
unique(move(temp_unique));因为这个叫函数调用。调用了一个叫unique的函数。
- 这里不可以写成
用lambda捕获sharedPtr要怎么做 – 值捕获,避免调用时sharedPtr对象已销毁
创建shared_ptr的引用不会改变其强引用计数器或弱引用计数器。
1
2
3
4
5
shared_ptr<myobj> shared = make_shared<myobj>(5);
shared_ptr<myobj> shared2 = shared;
cout << shared2.use_count() << endl; //输出2
shared_ptr<myobj>& sharedref = shared; //创建引用
cout << shared2.use_count() << endl; //依旧输出2
所以假如我们按照引用捕获了(再次强调,引用捕获相当于在匿名类内部创建了一个入参的引用类型的类成员变量),我们也知道了创建shared_ptr的引用不会改变其强引用计数器或弱引用计数器。所以会导致计数器并不会增加。这样,有可能外部该shared_ptr的计数器已经清零并且析构了,我们内部才刚要进行调用。
比如
1
2
3
4
5
6
7
8
9
10
int main(){
shared_ptr<myobj> shared = make_shared<myobj>(5);
auto lambda = [&](int b){ //错误地按照引用捕获
cout << shared->val + b << endl;
};
shared.reset(); //计数器-1,如果为0就释放。此时已经释放了
lambda(10); //崩溃
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
int main(){
shared_ptr<myobj> shared = make_shared<myobj>(5);
auto lambda = [=](int b){
cout << shared->val + b << endl;
cout <<"in lambda:" <<shared.use_count() << endl; //输出1
};
cout <<"out lambda:" <<shared.use_count() << endl; // 输出2
shared.reset(); //reset的是全局作用域的shared。
cout <<"out lambda:" <<shared.use_count() << endl; //输出0 不要惊讶
lambda(10);
return 0;
}
不要惊讶为什么输出0后lambda内部输出1。我们解释一下
首先我们按值捕获一个shared_ptr,相当于两个指针共享一份数据和一个数据块。reset全局作用域的shared后,我们提到过,这个reset不仅会给引用计数-1,而且会把自己置空,也就是自己的指向控制器的指针置空,自然就是0。详细的看一下上面reset使用部分。
但是我们lambda作用域内的shared依旧存在,所以它的引用计数器是正常的1。
捕获sharedPtr时如果不想延长对象生命周期怎么做(先赋值给weakPtr,再捕获)
这问题好没劲。
就是假设有一个情况,我们这个lambda挺无关紧要的,我不希望在外面我想释放shared_ptr的时候还要等lambda里面的shared_ptr释放后再释放。我们就可以新建一个weak_ptr, 然后把这个weak_ptr传入lambda。j记得每次使用的时候需要先用lock或者expired判断一下是否有效。
实现一个简单的make_unique
1
2
3
4
template<typename T, typename... Args> //变长参数模板
std::unique_ptr<T> my_make_unique(Args&&... args){ //函数会返回unique_ptr
return std::unique_ptr<T> (new T(std::forward<Args>(args)...)); //使用完美转发至对象的构造函数。构造智能指针。
}
实现一个简单的make_shared
1
2
3
4
template<typename T, typename... Args> //变长参数模板
std::shared_ptr<T> my_make_shared(Args&&... args){ //函数会返回unique_ptr
return std::shared_ptr<T> (new T(std::forward<Args>(args)...)); //使用完美转发至对象的构造函数。构造智能指针。
}
shared_ptr不能直接协变
shared_ptr不能直接协变,需要转换一下。参考这篇文章
个人理解是因为他找不到shared_ptr<Base>和shared_ptr<Derive>之间的直接联系
通过构造函数创建shared_ptr对象一个非常牛逼的副作用 :shared_ptr 可以正确地通过基类指针析构整个对象,即使基类没有定义基类析构函数为虚析构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct Base {
// no virtual here
~Base()
{
printf("~Base\n");
}
};
struct Derived : Base {
~Derived()
{
printf("~Derived\n");
}
};
int main(){
std::shared_ptr<Base> sp(new Derived()); //输出 ~Base 和 ~Derived
std::shared_ptr<Base> sp2 = make_shared<Derived>(); //输出 ~Base 和 ~Derived
Base* ptr = new Derived; //只输出~Base
delete ptr;
return 0;
}
这个“特性”目前是 shared_ptr 独有的,make_shared也可以。我们可以通过研究代码来理解为什么可以这样做。
我们提到过,控制块内有一个储存数据实际类型的指针。从一开始 shared_ptr 的构造函数到这里的 _Ref_count,所有相关函数都是 template,类型逐层传递保证 _Ref_count::_Ptr 是 heap 对象的实际类型,这意味着这个 shared_ptr 实现了在内部保存了管理对象的实际类型,并且 _Ref_count::_Destroy() 是直接对实际类型进行 delete。
所以,哪怕基类的析构函数不是 virtual,sp 一样能够正确析构。
假设我们现在有个例子是
1
shared_ptr<father> ptr(new child);
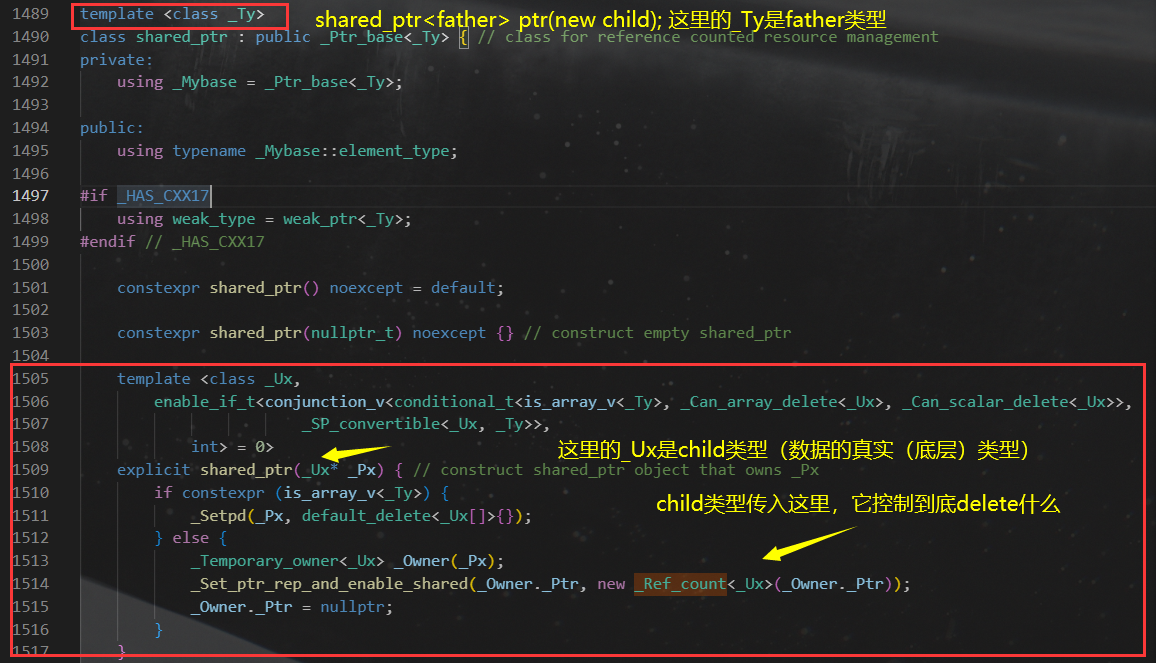
- 从上图我们看到了,模板类的类型也就是
shared_ptr<>里面写的是_Ty,而放到构造函数里面的也就是new的对象的类型是_Ux。_UX的类型会被自动推导不必显式指定。因为是函数模板。new child返回的指针类型是child

- 上图的析构是调用
_Decref

_Decref会在资源真正需要被销毁的时候调用_Destroy
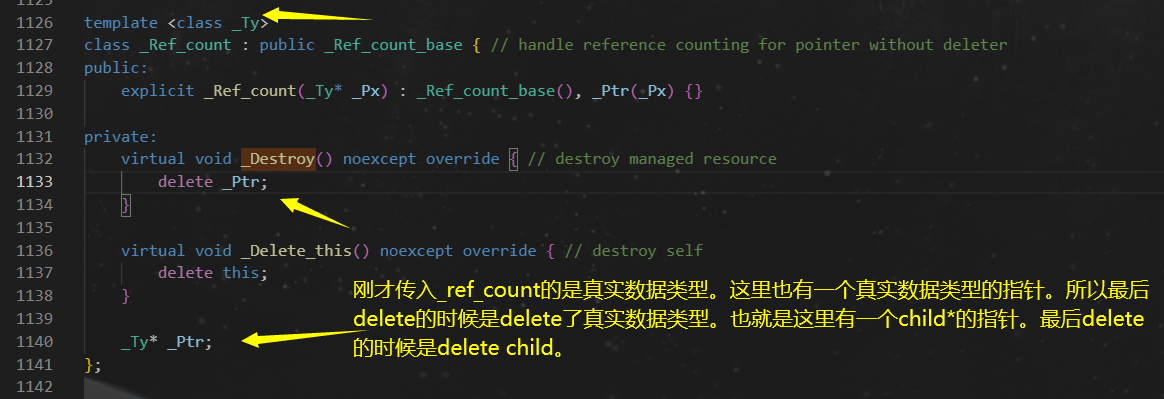
- 这里的传入
_Ref_count的_Ty类型就是刚才传入的_Ux。也就是实际数据类型child。调用_Destroy的时候直接delete的是child。所以可以正确释放。 _Ref_count_base就是控制块基类。
https://kingsamchen.github.io/2018/03/16/demystify-shared-ptr-and-weak-ptr-in-msvc-stl/
shared_ptr的别名构造函数 (Alias Constructor )
这个别名构造再标准库里的enable_shared_from_this中使用了。
通过上面的部分,我们理解了在shared_ptr中,指向对象的指针和控制块内指向对象的指针是完全独立的。后面的特征通过了Type erasure 而逃过了编译器的类型检查。内部控制块的模板参数(控制块内指向对象的指针的类型)和外部智能指针的模板参数(单独指向对象的那个指针的类型)毫无干系, 因此控制块指针和存储指针本质上是完全独立的.
1
2
template< class Y >
shared_ptr( const shared_ptr<Y>& r, element_type* ptr ) noexcept;
- 别名使用构造函数:构造
shared_ptr,与r的初始值共享所有权信息,但保有无关且不管理的指针ptr。若此shared_ptr是离开作用域的组中的最后者,则它将调用最初r所管理对象的析构函数。然而,在此shared_ptr上调用get()将始终返回ptr的副本。程序员负责确保只要此shared_ptr存在,此ptr就保持合法,例如在典型使用情况中,其中ptr是r所管理对象的成员,或是r.get()的别名(例如向下转型)。来自cppreference - 和拷贝构造函数一样。除了存储指针不同 来自cplusplus
- 注意,使用的时候算作对指针
r的资源的一次额外使用。也就是强引用计数+1。 来自cplusplus - 这句话翻译过来就是,这个指针的控制块使用的是
r的(共享控制块) [与r的初始值共享所有权信息]。但是实际指向的数据是ptr的 [但保有无关且不管理的指针ptr]- 控制块使用的是
r的 ,这句话代表了管理指针是指向r的。 - 实际指向的数据是
ptr的代表存储指针是指向ptr的。 - 白话就是,只要
r的计数器为0,就该释放ptr的资源了,我不管有没有人用。
- 控制块使用的是
第一部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class myobj {
public:
myobj(int n):val(n){}
~myobj() {
cout << "myobj析构 "<< val << endl;
}
int val;
};
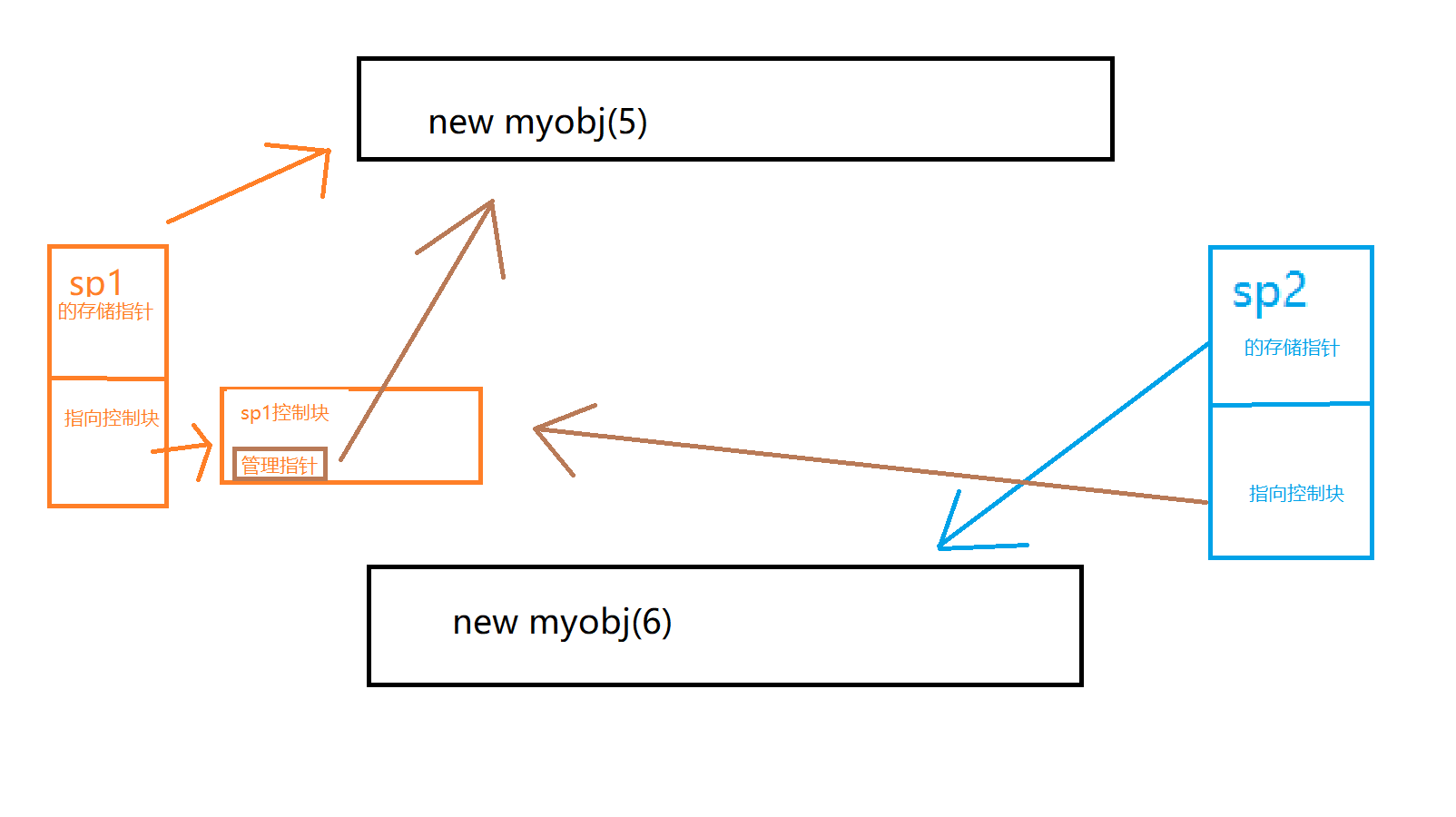
int main() {
shared_ptr<myobj> sp1{ new myobj(5) };//sp1是共享对象(也就是new出来的Person)的唯一拥有者。此时控制指针和储存指针都指向myobj(5)
shared_ptr<myobj> sp2{ sp1,new myobj(6) };//现在sp1,sp2都是共享对象的拥有者。但是注意,此时sp2的控制块和sp1共享。也就是此时sp1的引用计数和sp2的引用计数均为2。但是sp2的存储指针被替换为指向myobj(6)
cout << sp1.get()->val << endl; //get返回存储指针,此处输出5
cout << sp2.get()->val << endl; //get返回存储指针,此处输出6
cout << sp1.use_count() <<", "<< sp2.use_count()<< endl; //2,2 此时sp1的引用计数和sp2的引用计数均为2。
return 0;
}
- 上面的注释已经很详细了,但是还有一点,这里大家发现了有内存泄漏。
- 因为
sp2和sp1共享控制块,所以他们其实只对myobj(5)这个资源负责。而sp2的存储指针被替换为myobj(6),但是并没有指针管理。所以这块内存是泄漏的。 - 没有指针管理
myobj(6)是因为我们说过,shared_ptr的资源释放,释放的是管理指针指向的对象而非存储指针。
- 因为
第二部分:
我们继续上面的代码往下写:
1
2
3
4
5
6
sp1.reset(); //此时,sp1置空。和资源myobj(5),控制块都毫无关联。所以sp1存储指针为空,控制块依旧为空。因为已经和之前的控制块没有关系。
cout << sp1.use_count() <<", "<< sp2.use_count()<< endl; //0, 1
if(sp1.get() == nullptr){ //输出true。因为确实是空指针了。
cout <<"true" << endl;
}
cout << sp2.get()->val << endl; //这时候sp2依旧掌握myobj(6)
- 注释已经详细说明了。
第三部分:
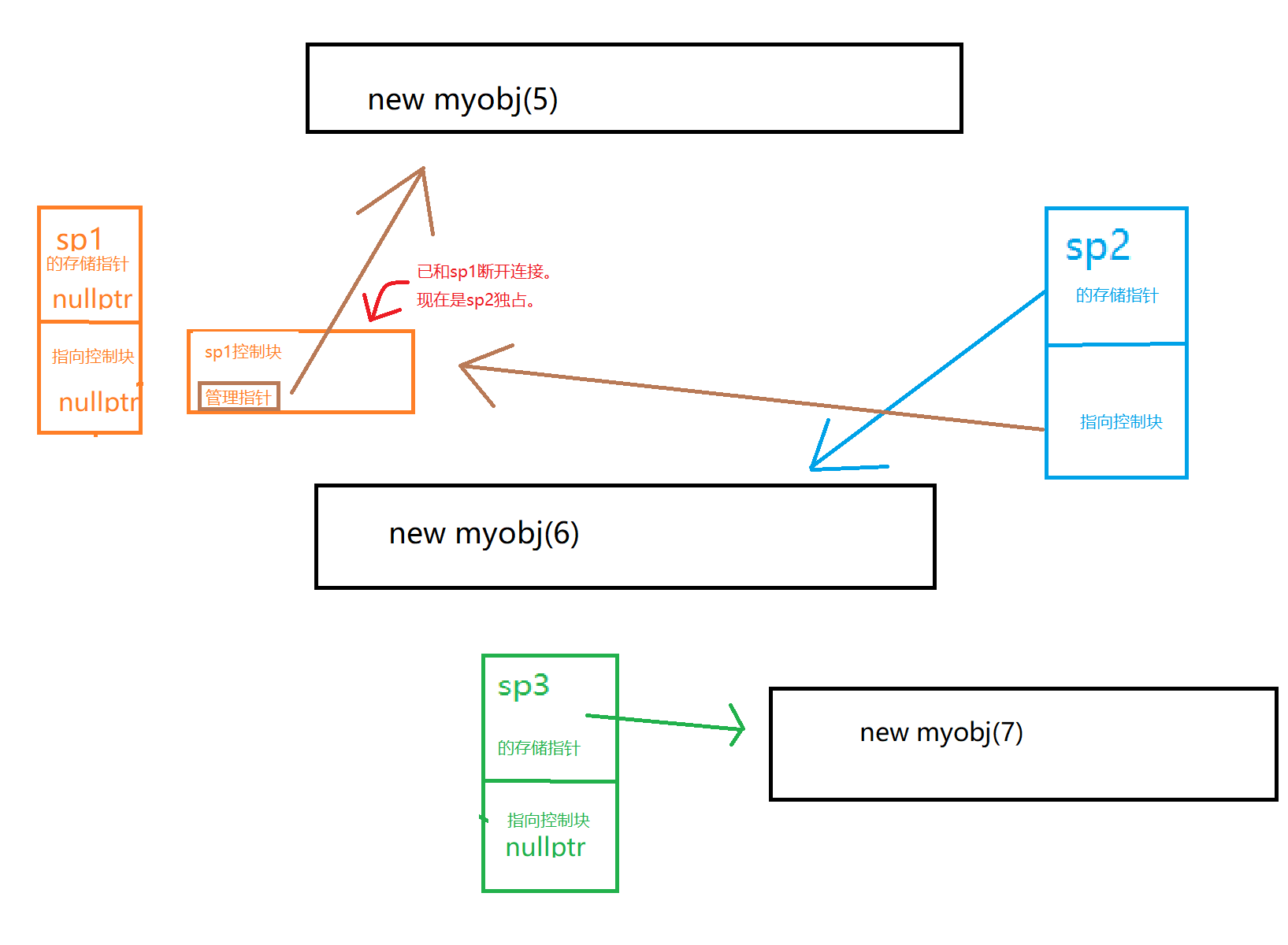
我们继续写:
1
2
3
shared_ptr<myobj> sp3(sp1,new myobj(7)); // 注意之前sp1的控制块为空。此时sp3和sp1共享控制块。也就是都没有控制块。自然没有引用计数。
cout << sp3.use_count() << endl; //0
cout << sp1.use_count() << ", " << sp2.use_count() << endl;//0,1
- 注意之前
sp1的控制块为空。此时sp3和sp1共享控制块。也就是都没有控制块。自然没有引用计数。reset的实现是临时对象+swap
- 所以此时内存泄漏两个位置。一个是
myobj(6)一个是myobj(7)
一般什么时候用?
- 不同类型对象共享生存期。
- 直接持有某个对象的成员。
举一个直接持有某个对象的成员的例子。对象的成员和对象本身,显然的确应该共享生存期
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class innerobj{
public:
int inner_val;
innerobj(int x):inner_val(x){}
};
class myobj {
public:
myobj(int n):obj(n){}
~myobj() {
cout << "myobj的析构 "<< obj.inner_val << endl;
}
innerobj obj;
};
int main() {
shared_ptr<myobj> ptr{ new myobj(5) };//ptr是共享对象(也就是new出来的myobj)的唯一拥有者
shared_ptr<innerobj> sub_ptr(ptr, &(ptr->obj)); //此时sub_ptr的控制块和ptr共享,但是subptr的存储指针直接指向myobj的innerobj成员变量。
//记得要取地址。第二个参数要传入指针。
cout << ptr.use_count() << endl; //2 引用计数被+1
cout << sub_ptr.use_count() << endl; //2 引用计数被+1
ptr.reset(); //reset, 此时ptr为空。
cout << ptr.use_count() << endl; //0 无控制块
cout << sub_ptr.use_count() << endl; //1 引用计数被-1
cout << sub_ptr->inner_val << endl; //正常输出5 。
return 0;
}
- 注意这里不会有内存泄漏。因为在
reset后,尽管实际持有的存储指针是子对象,但是由于共享控制块,控制块实际的管理指针依旧是myobj这个大类类型的。所以析构的时候调用的是myobj的析构。由于myobj和innerobj是包含关系,innerobj自然也会被正确析构。因为ptr->obj不会被单独管理,所以也不存在double free 错误
有时候,这个东西被叫做幻影指针(Phantom) ,依旧来自 Raymond Chen
https://blog.csdn.net/mingwu96/article/details/123327325
https://zhuanlan.zhihu.com/p/47744606
https://stackoverflow.com/questions/27109379/what-is-shared-ptrs-aliasing-constructor-for
常用部分总结
| 比较 | shared_ptr | unique_ptr | 备注 |
|---|---|---|---|
| 初始化 | ①shared_ptr<T> sp;② sp.reset(new T());② shared_ptr<T> sp(new T());③ shared_ptr<T> sp1 = sp; //拷贝构造④ auto sp = make_shared<int>(10); | ①unique_ptr<T> up; up.reset(new T());② unique_ptr<T> up(new T());③ unique_ptr<T> up1 = std::move(up);//移动构造④ auto up = make_unique<int>(10); | 两者的构造函数将声明为explicit,即不允许隐式类型转换,如shared_ptr<int> sp = new int(10); |
| 条件判断 | 如,if(sp){…} | 如,if(up){…} | 两都均重载operator bool() |
解引用(间接寻址运算符 *) | *sp | *up | 解引用,获得它所指向的对象 |
类成员访问运算符(->) | sp->mem | up->mem | 重载->运算符 |
| get() | sp.get() | up.get() | 返回智能指针中保存的裸指针,要小心使用。 |
| p.swap(q) | sp.swap(q); | up.swap(q); | 交换p和q指针 |
| 独有操作 | ①shared_ptr<T> p(q);//拷贝构造② p = q;//赋值③ p.unique();若p.use_count()为1,返回true,否则返回false。④p.use_count()//返回强引用计数 | ①up=nullptr;释放up指向的对象,并将up置空。② up.release();//up放弃对指针的控制权,返回裸指针,并将up置空③ up.reset();释放up指向的对象。 up.reset(q);其中q为裸指针。令up指向q所指对象。 up.reset(nullptr);置空 | 注意: ① unique_ptr不可拷贝和赋值,但可以被移动。② release会切断unique_ptr和它原来管理的对象间的联系。通常用来初始化另一个智能指针。 |
强烈建议以对待普通指针的方式对待智能指针。
- 如按值传递,按值返回。
- 按值传递
unique_ptr显示了所有权的转移。
关于侵入式和非侵入式智能指针。
什么是非侵入式智能指针
STL的shared_ptr属于非侵入式智能指针。从原理上来说就是它的实现完全放在智能指针模板里。也就是控制块是和指针在一个类里。
模板类有一个用于保存资源类对象的指针变量,和一个用于记录资源对象使用计数(控制块)的指针变量。
什么是侵入式智能指针
ITK, VTK和boost里的智能指针是侵入式的。从原理来说就是它的实现分散在智能指针模板和使用智能指针模板的类中:模板类只有一个用于保存对象的指针变量,对象的计数放在了资源类中。举例来说就是把控制块比如引用计数和对象绑定到一起。
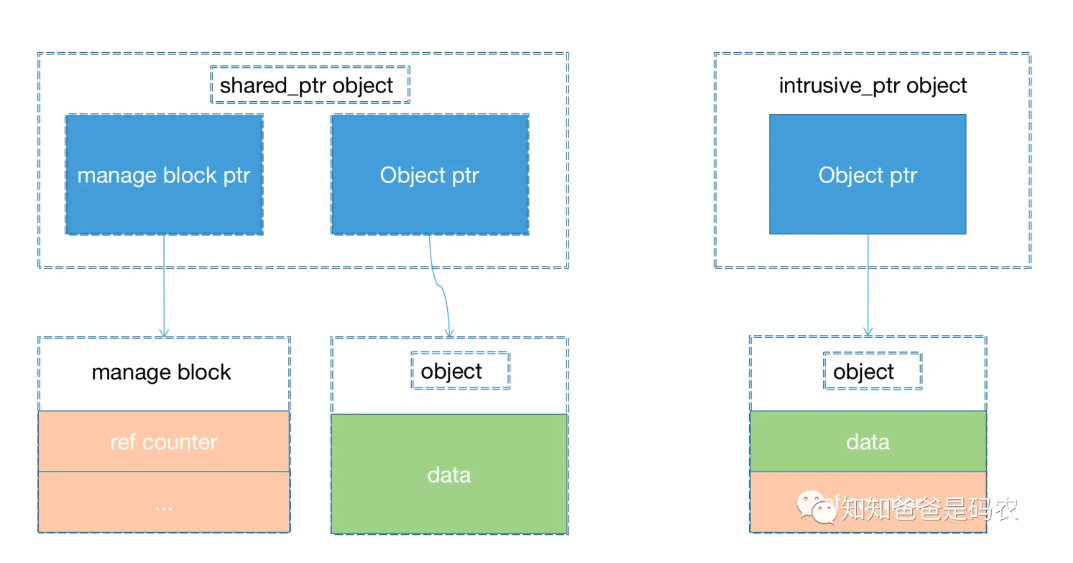
总结
非侵入式智能指针,它的引用计数变量为了保证所有对象共享,需要用堆里的内存,所以需要用new,这个都一样,不一样的是使用new的次数。
侵入式智能指针的引用计数变量保存在对象里,因为对象是唯一的,所以引用计数也是唯一的。
非侵入式智能指针的缺点:
- 在不使用
make_shared的时候,会为控制块单独分配一次内存。这导致性能问题。而如果使用make_shared,则在某些时候会导致整块内存都无法释放,比如弱引用计数仍不为0的情况下。 - 引用计数的内存区域和数据区域不一致,缓存失效导致性能问题。
- 编写代码不善,将导致同一个数据,绑定到了两个引用计数,从而导致双重删除问题。比如
1 2 3
obj *resource = new obj(100); shared_ptr<obj> ptr1(resource); //ptr1有控制块 shared_ptr<obj> ptr2(resource); //ptr2还有一个控制块。double free
- 在不使用
相比非侵入式智能指针,侵入式智能指针的好处是:
- 一个资源对象无论被多少个侵入式智能指针包含,从始至终只有一个引用计数变量,不需要在每一个使用智能指针对象的地方都new一个计数对象,这样子效率比较高,使用内存也比较少,也比较安全;
- 这句话理解就是如果在使用非侵入的时候我们有一个原始指针指向资源,我们使用这个原始指针初始化共享指针的时候会创建多个控制块。
- 因为引用计数存储在对象本身,所以在函数调用的时候可以直接传递资源对象地址,而不用担心引用计数值丢失(非侵入式智能指针对象的拷贝,必须带着智能指针模板,否则就会出现对象引用计数丢失)。
- 一个资源对象无论被多少个侵入式智能指针包含,从始至终只有一个引用计数变量,不需要在每一个使用智能指针对象的地方都new一个计数对象,这样子效率比较高,使用内存也比较少,也比较安全;
缺点是:
- 资源类必须有引用计数变量,并且该变量的增减可以被侵入式智能指针模板基类操作,这显得麻烦。也就是资源类必须继承自某个引用计数变量的基类或者是编写的时候将其编写进去。b
- 比如在
boost库中,需要继承boost::intrusive_ptr_base基类
- 比如在
- 如果该类并不想使用智能指针,它还是会带着引用计数变量。
- 资源类必须有引用计数变量,并且该变量的增减可以被侵入式智能指针模板基类操作,这显得麻烦。也就是资源类必须继承自某个引用计数变量的基类或者是编写的时候将其编写进去。b
可能的实现方法:
https://zhuanlan.zhihu.com/p/460983966
https://zhiqiang.org/coding/boost-intrusive-ptr.html
可能有用的参考资料
https://developer.aliyun.com/article/582674
https://www.cnblogs.com/5iedu/p/11622401.html
https://kingsamchen.github.io/2018/03/16/demystify-shared-ptr-and-weak-ptr-in-msvc-stl/ sharedptr源码分析 包含enable_shared_from_this
https://blog.csdn.net/lgp88/article/details/7529254 不完整类型
如果自己设计的话,如何让原始指针为形参的函数接受智能指针为实参?
可以使用转换构造函数。如
1
2
3
4
operator T*() const{
//return static_cast<T*>(this->object); 这行是VTK源码但不知道为何要这么做。
return this->object;
}
参考vtkNew和vtkSmartpointer。VTK8以前的vtkNew有意禁用了自动转换。但是8以后新增了转换构造所以可以进行转换。转换构造参见杂记2。
- 注意,这样做非常危险。因为你现在可以
delete一个智能指针了。delete会调用这个类型转换函数。所以这样设计的危险性就在于这里。—–Modern C++ design 7.7 和 more effective 条款28
为何智能指针支持 和继承有关的类型转换? more effective c++ -条款28(部分)
回顾我们曾经实现过的uptr,代码不在这里贴了。
- 首先我们知道,原始指针中,指向完整派生类类型的(可有 cv 限定的)空指针可转换成指向它的(有相同 cv 限定的)基类的指针。如果基类不可访问或有歧义,那么转换非良构(不能编译)。转换结果是指向原被指向对象内的基类子对象的指针。空指针值转换成目标类型的空指针值。也就是子类类型指针可以天然自然地转换为父类类型指针。(这是隐式类型转换中的第五级的指针转换。)
假设我们有如下场景
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
struct b{
};
struct d:b{
};
void func(area2::unique_ptr<b> ptr){
cout <<"called" << endl;
}
void formalfunc(unique_ptr<b> ptr){
cout <<"formal" << endl;
}
int main(){
area2::unique_ptr<b> ptr(new b());
func(move(ptr)); //可以。因为此时类型是b
area2::unique_ptr<b> ptr2(new d());
func(move(ptr2)); //可以。因为此时类型是b
area2::unique_ptr<d> ptr2(new d());
func(move(ptr2)); //不可以。因为此时类型是d
unique_ptr<d> uptr(new d()); //针对标准库的智能指针,这样可以,因为有隐式类型转换。
formalfunc(move(uptr)); //可以。有隐式类型转换。
}
- 我们发现我们实现的简易版和标准库的相比,我们无法做到和继承有关的类型转换。原因非常明显。就算
b和d有继承关系,但是unique_ptr<b>和unique_ptr<d>毫无关联。但是为什么标准库的智能指针可以让我们把一个子类类型的智能指针传入(赋值)给接受基类类型的智能指针的函数中呢?
标准库的做法我们从文档中可以窥见一斑:
通过从
u转移所有权给*this构造unique_ptr,其中u以指定的删除器(E)构造。它依赖于E是否是引用类型,如下:a) 若
E是引用类型,则从u的删除器复制构造此删除器(要求此构造不抛出)b) 若
E不是引用类型,则从u的删除器移动构造此删除器(要求此构造不抛出)此构造函数仅若下列皆为真才参与重载决议:
a)
unique_ptr<U, E>::pointer可隐式转换为pointerb)
U不是数组类型c)
Deleter是引用类型且E与D为同一类型,或Deleter不是引用类型且E可隐式转换为D
std::unique_ptr<Derived>通过重载 (6) 可隐式转换为std::unique_ptr<Base>(因为被管理指针和std::default_delete都可隐式转换)。
根据 more effective c++ 条款28,在简单层面,选择是添加一个简单的用户定义转换函数模板。但是如果照着标准库的方法模拟,则是这样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
template<typename _Tp>
struct default_delete
{
/// Default constructor
constexpr default_delete() noexcept = default; //默认删除器的默认构造
/** @brief Converting constructor.
*
* Allows conversion from a deleter for objects of another type, `_Up`,
* only if `_Up*` is convertible to `_Tp*`.
*/
template<typename _Up,
typename = _Require<is_convertible<_Up*, _Tp*>>>
_GLIBCXX23_CONSTEXPR
default_delete(const default_delete<_Up>&) noexcept { } //一个构造函数模板用来在查看默认删除器是否可以被类型转换后进行类型转换。这里很重要
/// Calls `delete __ptr`
_GLIBCXX23_CONSTEXPR
void
operator()(_Tp* __ptr) const
{
static_assert(!is_void<_Tp>::value,
"can't delete pointer to incomplete type");
static_assert(sizeof(_Tp)>0,
"can't delete pointer to incomplete type");
delete __ptr;
}
};
//unique_ptr的构造函数6
template<typename _Up, typename _Ep, typename = _Require<
__safe_conversion_up<_Up, _Ep>,
__conditional_t<is_reference<_Dp>::value,
is_same<_Ep, _Dp>,
is_convertible<_Ep, _Dp>>>>
_GLIBCXX23_CONSTEXPR
unique_ptr(unique_ptr<_Up, _Ep>&& __u) noexcept
: _M_t(__u.release(), std::forward<_Ep>(__u.get_deleter())) //非常单纯的赋值
{ }
上面的代码看起来复杂,其实用自己写的版本可以化简为这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
template<typename T>
void pivot(T p){
std::puts(__PRETTY_FUNCTION__); //查看函数签名
}
class myobj{
public:
int* ptrs;
myobj(int val):ptrs(new int(val)){}
~myobj(){
if(ptrs != nullptr){
delete ptrs;
ptrs = nullptr;
}
}
};
namespace area2{
template<typename T>
class default_deleter{ //默认形式的删除器
public:
default_deleter() = default;
//模拟默认删除器的构造函数模板
template<typename _Up, typename = typename enable_if<is_convertible<_Up*, T*>::value>::type> //注意必须是指针类型的可转换性
default_deleter(const default_deleter<_Up>&){
std::puts(__PRETTY_FUNCTION__); //2
}
default_deleter& operator=(const default_deleter& rhs){
cout <<"operator= called" << endl; //4
return *this;
}
void operator()(T *p) const {
std::puts(__PRETTY_FUNCTION__); //6
if(p != nullptr){
delete p;
p = nullptr;
}
}
};
template<typename T, typename Deleter = default_deleter<T>> //模板表示接受T类型一个接受T类型的删除器
class unique_ptr{
public:
T* p_ = nullptr; //T类型指针
Deleter d_; //删除器
//.....
//模拟构造函数6
template<typename U, typename E>
unique_ptr(unique_ptr<U,E>&& u){
this->p_ = u.p_; //指针赋值。自然转换
//----------------
pivot(u.d_); //1
default_deleter<T> temp(u.d_);
pivot(temp); //3
this->d_ = temp;
//----上面的区域可以换成下面一行------------
//this->d = u.d_
u.p_ = nullptr;
}
//......
}
1
2
3
4
5
6
void pivot(T) [with T = area2::default_deleter<d>] //1
area2::default_deleter<T>::default_deleter(const area2::default_deleter<_Up>&) [with _Up = d; <template-parameter-2-2> = void; T = b] //2
void pivot(T) [with T = area2::default_deleter<b>] //3
operator= called //4
called
void area2::default_deleter<T>::operator()(T*) const [with T = b] //6
核心原理就是把指针直接赋值过来。
当我们有
1
2
area2::unique_ptr<d> ptr3(new d());
area2::unique_ptr<b> ptr(move(ptr3));
的时候,首先我们发现这时候传入的指针的删除器类型是area2::default_deleter<d>。我们发现子类删除器和父类删除器area2::default_deleter<d>不一样,这就是为什么默认删除器要添加一个构造函数模板。
然后我们拆开写了,可以直接写this->d_ = u.d_。
第一步是查找合适的赋值方式。先查找d_有没有合适的operator=,明显没有,那么查看u.d_能不能转换为本类类型的默认拷贝赋值的参数类型,也就是area2::default_deleter<b>。我们发现default_deleter拥有一个构造函数模板:
1
2
3
4
template<typename _Up, typename = typename enable_if<is_convertible<_Up*, T*>::value>::type>
default_deleter(const default_deleter<_Up>&){
std::puts(__PRETTY_FUNCTION__); //2
}
它可以帮助我们转换。这个其实非常简单。先查看_Up*(子类指针,也就是本类中的d)能不能转换为T*(父类指针,也就是本类中的b)。然后就是构造了一个对象。
- 这里必须要用
is_convertible<_Up*, T*>而不是is_convertible<_Up, T>- 因为智能指针只有父类指针对子类指针进行
delete的时候才有意义。但是如果直接两个对象之间判断是否可以转换,语义不对。比如两个没有继承关系的但是有转换函数的对象是convertible的,int和long之间也是convertible的。但是int指针可以用long指针析构吗?显然不可以。所以必须使用指针类型进行判断是否convertible。 - 所以这里只有在有继承关系的子转父的时候,或者是转换CV限定(non-const to const)的时候才是true。语义才正确。
- 因为智能指针只有父类指针对子类指针进行
第二步就是我们得到了一个父类类型的默认删除器的临时对象。
第三部就是把这个删除器赋值即可。
因为默认删除器这个类没有任何数据。所以这样直接转换是符合我们直观意图的。
现在子类指针已经被转为父类。那么子类的删除器也应该变为父类。这样才正确。
测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
struct b{
};
struct d:b{
};
void func(area2::unique_ptr<b> ptr){
cout <<"called" << endl;
}
int main(){
area2::unique_ptr<d> ptr3(new d()); //现在不会报错了
func(move(ptr3));
}
智能指针的大师问答
来自这里
1. 如何决定是否使用和使用哪一种智能指针?– 默认使用unique_ptr
优先使用标准智能指针,默认情况下使用unique_ptr,如果需要共享,则使用shared_ptr。它们是所有 C++ 库都可以理解的通用类型。仅在需要与其他库进行互操作时,或者在需要使用标准指针上的删除器和分配器无法实现的自定义行为时,才使用其他智能指针类型。
2. shared_ptr应该如何构造?make_shared还是直接构造?
除了我们上面提到的那些关于make_shared的优缺点和区别以外,想在此补充一些。
第一个,C++20开始其实有了allocate_shared。 顾名思义就是自定义内存分配器,但是我们其实可以视make_shared是一种狭义的allocate_shared(因为实际上没有自定义自己的内存分配器)
第二个,除了上面说到的make方法的使用以外,有一个额外的工程层面问题可能会需要直接构造,也就是如果你采用指向从其他(通常是遗留的)代码传递给你的对象的原始指针,则可以直接从该原始指针构造一个shared_ptr。 其余情况下,应当尽可能的使用make_shared。因为不仅使代码更清晰,而且从内存角度来讲,一般情况下,局部性,碎片和分配次数比实际的大小对系统的影响更大
其他文章
设计智能指针 – more effective C++ 第七章
因为这本书非常老,所以我们可以从最原始的角度理解智能指针到底需要满足什么需求,有哪些设计方式,为什么最后成为了现在的这个样子。
7.2 语义
7.2讲的是语义。智能指针到底应该如何保有资源。这部分我想就是后面拆分的unique_ptr和shared_ptr
7.3 智能指针的存储
7.3讲的是智能指针的存储。应该保留一个什么类型的原始指针?同时提到了重载operator->的技巧。
7.4 成员函数
7.4讲的是成员函数。提到了智能指针不应该拥有如release()这样的成员函数。但是目前,它确实有。书中给到的不应该有的理由是:必须区分ptr->release()和ptr.release()的区别。因为可能智能指针保有的指针类型恰好也含有一个对应名字的函数。
7.5 所有权
7.5讲的是所有权。 相当于7.2的延伸。这部分涉及到了侵入式和非侵入式指针的设计。侵入式如VTK的智能指针,好处是智能指针本身不需要操心引用计数器。因为引用计数是和对象绑定在一起的。缺点是对象必须要继承引用计数类。同时,提到了几个引用计数的设计。这部分在我们上面提到的make方法中有所体现。同时,额外提到了一种利用双向链表来做为引用计数的方法(感觉没啥用)。最后提到了关于循环引用的问题。
7.6 取址操作符
7.6讲的是取址操作符。这一部分非常经典?理论上从不应该重载取址操作符,当然了,在某些代理类的时候除外。书中提到了重载了取址操作符的类不太好用于STL容器,因为所有&T都应该返回一个T*。当然了我觉得这是因为当时还没有std::address_of这个东西。不过也确实,STL的智能指针都没有重载operator&
7.7 隐式转换
这部分就是上面提到的:如果自己设计的话,如何让原始指针为形参的函数接受智能指针为实参?
答案是看情况。需要权衡利弊。
7.8 7.9 比较操作
STL目前是拥有智能指针的比较函数的。也就是重载了对应的函数。并且不是成员函数。
7.10 错误检测
比如是否可以把空值传入智能指针做为初始值?目前是可以的。但是书上说不太应该。但是也是case by case。
另一个就是关于是否要进行解引用前检测是否为空?我个人认为应该把这个留给用户。应该让智能指针在智能的同时,尽可能简约。
7.11 常量性
确实有一个很有意思的地方。无论指针的常量性是顶层还是底层还是皆有,delete都可正常使用。从某个角度来说是废话,但是从所有权的语义上理解可能就有了微妙的地方。为啥要在智能指针上面提到这种呢?因为智能指针也应该支持顶层和底层的const的语义区别。确实支持。毕竟原理就是type trait
7.12 数组类型
其实不太应该使用堆上的数组。当然了,标准库也对智能指针提供了[]数组特化的版本。
7.13 多线程
对于智能指针的多线程访问一直是一个比较令人困扰的问题。
一般来说,对于智能指针的多线程访问我们需要分成两个方向去讨论。第一个方向是指针保有的对象的多线程访问。另一个是指针的引用计数的多线程访问。
针对第一个,我们能做的东西不大。语义上我们希望智能指针帮我们做的事情越少越好,越少也就越透明,越自由。所以说在这一方面我们不应替用户操心太多。书中提到了自动锁定的应用,但我觉得不怎么样。用户自己会去针对并发访问进行处理。
针对第二个,我们可以肯定的是目前的shared_ptr的引用计数块的并发访问是不安全的。所以需要进行控制。原理还是一样,我们不应该在这个情况上替用户做过多决定。