C++ 杂记
拷贝初始化,拷贝构造 直接初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
1 #include <iostream>
2 #include <cstring>
3 using namespace std;
4 class ClassTest
5 {
6 public:
7 ClassTest()
8 {
9 c[0] = '\0';
10 cout << "ClassTest()" << endl;
11 }
12 ClassTest& operator=(const ClassTest &ct)
13 {
14 strcpy(c, ct.c);
15 cout << "ClassTest& operator=(const ClassTest &ct)" << endl;
16 return *this;
17 }
18 ClassTest(ClassTest&& ct)
19 {
20 cout << "ClassTest(ClassTest&& ct)" << endl;
21 }
22 ClassTest & operator=(ClassTest&& ct)
23 {
24 strcpy(c, ct.c);
25 cout << "ClassTest & operator=(ClassTest&& ct)" << endl;
26 return *this;
27 }
28 ClassTest(const char *pc)
29 {
30 strcpy(c, pc);
31 cout << "ClassTest (const char *pc)" << endl;
32 }
33 //private:
34 ClassTest(const ClassTest& ct)
35 {
36 strcpy(c, ct.c);
37 cout << "ClassTest(const ClassTest& ct)" << endl;
38 }
39 virtual int ff()
40 {
41 return 1;
42 }
43 private:
44 char c[256];
45 };
46 ClassTest f1()
47 {
48 ClassTest c;
49 return c;
50 }
51 void f2(ClassTest ct)
52 {
53 ;
54 }
55 int main()
56 {
57 ClassTest ct1("ab");//直接初始化
58 ClassTest ct2 = "ab";//复制初始化
59 ClassTest ct3 = ct1;//复制初始化
60 ClassTest ct4(ct1);//直接初始化
61 ClassTest ct5 = ClassTest("ab");//复制初始化
62 ClassTest ct6 = f1();
63 f1();
64 f2(ct1);
65 return 0;
66 }
(1)什么是拷贝初始化(也称为复制初始化):将一个已有的对象拷贝到正在创建的对象,如果需要的话还需要进行类型转换。拷贝初始化发生在下列情况:
拷贝初始化的含义是从另一个对象初始化对象。
- 使用赋值运算符定义变量
- 将对象作为实参传递给一个非引用类型的形参(值传递)
- 将一个返回类型为非引用类型的函数返回一个对象(返回值)
- 用花括号列表初始化一个数组中的元素或一个聚合类中的成员
(2)什么是直接初始化:在对象初始化时,通过括号给对象提供一定的参数,并且要求编译器使用普通的函数匹配来选择与我们提供的参数最匹配的构造函数。 意思就是找到最匹配的一个构造函数来进行调用。不一定调用哪一个。
(3)在底层实现中,可以看出编译器的思想是能不用临时对象就不用临时对象。因此对于下面这些拷贝初始化,都不会生成临时对象再进行拷贝或移动到目标对象,而是直接通过函数匹配调用相应的构造函数。
1
2
1 ClassTest ct2 ="ab"; //相当于ClassTest ct2("ab");
2 ClassTest ct5 = ClassTest("ab"); //相当于ClassTest ct5("ab")
(4)下面的语句,visual studio才会生成一个无名的临时对象(位于main函数的栈中),注意:f1的返回值类型是非引用的,f2的形参类型是非引用的。
通常如下三种情况会生成临时对象:
- 以值的方式给函数传参;(调用拷贝构造)
- 类型转换;
- 函数需要返回一个对象时;
1
2
1 f1(); //临时对象用于存储f1的返回值
2 f2(ct1); //临时对象用于拷贝实参,并传入函数
而下面则是直接传入赋值表达式左边对象地址,然后再对该对象进行移动拷贝,注意f1返回值类型是非引用的,如果是引用的,则会调用拷贝构造函数。
上面这句话的意思是 把f1()作为参数放进ct6调用的operator=重载函数里。然后这个函数里面把f1()函数的返回的对象移动到ct6
本质上应该是复制。但是因为这里他写了移动构造所以采用了移动。
1
1 ClassTest ct6 = f1();
(5)直接初始化和拷贝初始化效率基本一样,因为在底层的实现基本一样,所以将拷贝初始化改为直接初始化效率提高不大。
(6)拷贝初始化什么时候使用了移动构造函数:当你定义了移动构造函数,下列情况将调用移动构造函数
- 将一个返回类型为非引用类型的函数返回一个[临时]对象 [并赋值给一个对象](如上面的
ClassTest ct6 = f1();)
(7)我们需要先知道什么时候调用拷贝构造函数:
- 当用类一个对象去初始化另一个对象时。
- 如果函数形参是类对象。
- 如果函数返回值是类对象,函数执行完成返回调用时。
(8)拷贝初始化什么时候使用拷贝构造函数:
- 赋值表达式右边是一个对象
- 直接初始化时,括号内的参数是一个对象
- 用花括号列表初始化一个数组中的元素或一个聚合类中的成员
- 将一个返回类型为引用类型的函数返回一个对象
- 形参为非引用类型的函数,其中是将实参拷贝到临时对象
总之,拷贝构造函数有严格的参数限制。只能是本类的对象初始化本类的对象。如果用其他类对象初始化本类对象,那么形参必须是其他类对象。那么这个东西叫做构造函数。而不是拷贝构造函数。
类
T的复制构造函数是首个形参是 T&、const T&、volatile T& 或 const volatile T&,而且要么没有其他形参,要么剩余形参均有默认值的非模板构造函数
(9)什么时候使用到拷贝赋值运算符:
- 赋值表达式右边是一个左值对象(如果需要,可以调用构造函数类型转换,生成一个临时对象)
- 当赋值表达式右边是一个右值对象,且没有定义移动赋值运算符函数
(10)什么时候使用移动赋值运算符:
- 当赋值表达式右边是一个右值对象,且定义了移动赋值运算符函数
(11)即使编译器略过了拷贝/移动构造函数,但是在这个程序点上,拷贝/移动构造函数必须存在且是可访问的(例如:不能是private),如下:
1
ClassTest ct2 = "ab";//复制初始化
编译器会将其等同下面的语句,调用的是ClassTest的ClassTest(const char *pc)构造函数
1
ClassTest ct2("ab");//直接初始化
但是ClassTest的拷贝或移动构造函数需要定义至少其中一个,否则会报错
拷贝初始化看起来像是给变量赋值,实际上是执行了初始化操作,与先定义再赋值本质不同。 对于内置类型变量(如 int,double,bool 等),直接初始化与拷贝初始化差别可以忽略不计。
对于类类型的变量(如string或其他自定义类型):
直接初始化调用类的构造函数(调用参数类型最佳匹配的那个, 包括拷贝和移动构造。)
T s(...);或者T s{...};从明确的构造函数实参的集合初始化对象。
- 直接初始化会选择最匹配的一个构造函数。并且考虑全部的构造函数,和所有用户定义转换函数。不会忽略explicit修饰的构造函数和explicit 修饰的用户定义转换函数。
- 直接初始化看上去就是显式地调用类型的构造函数进行初始化。
- 显式地调用构造函数进行直接初始化实际上是显式类型转换的一种。我们称之为functional cast。
- 直接初始化会期待一个从初始化器到 目标类型 的构造函数实参的隐式转换。
- 直接初始化会选择最匹配的一个构造函数。并且考虑全部的构造函数,和所有用户定义转换函数。不会忽略explicit修饰的构造函数和explicit 修饰的用户定义转换函数。
拷贝(复制)初始化也会选择最匹配的一个构造函数(重申包括拷贝和移动构造),但是忽略任何explicit修饰的构造函数和explicit 修饰的用户定义转换函数。 (也就是看到等号就是拷贝初始化)
T s = ...;从另一个对象初始化对象。
- 如果 目标类型 是类类型,且 其他对象 的类型的无 cv 限定版本是 目标类型 或是从 目标类型 派生的类,那么检测 目标类型 的非显式构造函数,并由重载决议选择最佳匹配。然后调用构造函数以初始化该对象。
- 如果 目标类型 是类类型,且 其他对象 的类型的无 cv 限定版本不是 目标类型 或从 目标类型 派生,或如果 目标类型 是非类类型,但 其他对象 的类型是类类型,那么检测能从 其他对象 的类型转换到 目标类型 (或当 目标类型 是类类型且存在转换函数时,转换到从 目标类型 派生的类型)的用户定义转换序列,并通过重载决议选择最佳者。该转换的结果(如果使用转换构造函数,那么就是无 cv 限定的 目标类型 的右值临时量 (C++11 前)纯右值临时量 (C++11 起)(C++17 前)纯右值表达式 (C++17 起))会被用于直接初始化该对象。最后一步通常会被优化掉,而直接将转换结果构造于分配给目标对象的内存之中,但即便不会使用,也要求适合的构造函数(移动或复制)是可以访问的。 (C++17 前)
如果 其他对象 是右值表达式,那么重载决议会选择移动构造函数并在复制初始化期间调用它。没有“移动初始化”的概念。
- **所以他最终会尝试去对等号右侧的值进行一个隐式类型转换(创建临时对象)以符合要求。拷贝(复制)初始化要求编译器将右侧运算对象对象拷贝到正在创建的对象中 **。
- 所以最后一定会调用拷贝或移动构造函数来使用等号右侧的对象来初始化左侧对象。
- 等号右侧的对象在构造中会涉及到类型转换,这时候就是调用对应的构造函数或类型转换函数了,但是最后等号右侧的对象类型一定和等号左侧的对象类型相同。因为只有这样才可以调用拷贝构造或移动构造。
- 所以最后一定会调用拷贝或移动构造函数来使用等号右侧的对象来初始化左侧对象。
- 拷贝(复制)初始化会忽略掉任何explicit 修饰的构造函数。
- 复制初始化中的隐式转换必须从初始化器直接生成 目标类型
- 特别的,当对类类型变量进行初始化时,如果类的构造函数采用了 explicit 修饰而且需要隐式类型转换时,则只能通过直接初始化而不能通过拷贝初始化进行操作。因为explicit禁止了对等号右侧的那个临时对象使用隐式类型转换。
- 如果自己实验发现没调用拷贝构造,把编译器优化关了就好了。
- 注意C++17后有拷贝省略。看杂记3
- 函数的值传递,和函数的值返回都是拷贝初始化
- 所以在函数传值的时候,防止隐式类型转换可以通过给转换(构造函数)加
explicit来解决。
- 所以在函数传值的时候,防止隐式类型转换可以通过给转换(构造函数)加
所以一般来说,复制初始化可能会发生隐式或显式(这时候是手动,不受explicit限制)类型转换(生成临时对象),然后通过移动或拷贝的方式初始化左侧的对象。注意,这个移动或拷贝意思是会调用移动或拷贝构造函数。因为此时是拷贝初始化的语义:通过对象来初始化对象。
注意是可能发生类型转换,什么时候不发生呢?就是当等号右侧和左侧的对象类型相同的时候。
而直接初始化,语义比较明确,直接通过传入的参数来寻找对应的构造函数,一步到位。符合直接初始化的语义:从明确的构造函数实参的集合初始化对象。
所以explicit卡在哪儿了?卡在隐式类型转换所需的构造等号右侧的临时对象了。
我们上面提到了如果其他对象的类型不是目标类型或从目标类型派生,那就需要找能转换的转换序列(包括转换构造函数和用户定义转换函数)。说人话就是我们要使用等号右面的这个东西,构建出一个等号左边的类型的临时对象。但是在这个临时对象的构造中(转换序列的查找中),忽略掉所有带explicit声明符的可用函数。这时候自然就防止了隐式类型转换。因为一般情况下,我们期望的是提供一系列参数,然后进行对象构造。按理说直接初始化提供的参数和拷贝初始化提供的参数是相同的。因为在拷贝初始化临时对象后,会调用拷贝构造或移动构造来对左侧的对象进行初始化。
但是,它有时候想的和你不太一样。比如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
explicit myobj(int x):val(new int(x)){ //explicit
cout <<"const" << endl;
}
myobj(int x, int y = 20):val(new int(x)){ //带默认值
cout <<"const with default value" << endl;
}
myobj b = 10; //可以
/*
const with default value
mv
dest
dest
*/
- 这个时候为啥可以呢?因为尽管通过
10来构造myobj临时对象的时候,第一个匹配的构造函数是explicit不能用,但是第二个可以用。所以此时依旧可以拷贝初始化。
原文地址:
https://www.cnblogs.com/cposture/p/4925736.html
https://nettee.github.io/posts/2018/What-happens-when-return-an-object-by-value-in-Cpp/
https://www.cnblogs.com/apocelipes/p/14415033.html
https://www.cnblogs.com/apocelipes/p/14415033.html#%E4%BB%80%E4%B9%88%E6%98%AF%E9%9A%90%E5%BC%8F%E7%B1%BB%E5%9E%8B%E8%BD%AC%E6%8D%A2
自己的提问 https://stackoverflow.com/questions/75480280/in-c-under-the-case-t-object-other-it-is-direct-initialization-or-copy#75480337
直接初始化,拷贝初始化的语义差别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
class otherc{
public:
otherc() = default;
otherc(int x):val(x){
cout <<"otherc" << endl;
};
int val = 20;
};
class myobj{
public:
myobj() = default;
myobj(const otherc&){
cout <<"convert const" << endl;
val = new int(10);
}
myobj(int x):val(new int(x)){ //构造
cout <<"const" << endl;
}
// int& getval(){
// return *val;
// }
myobj(const myobj& obj){ //拷贝构造
cout <<"copy const" << endl;
val = new int(*obj.val);
}
myobj& operator=(const myobj & rhs){ //拷贝赋值
cout <<"copy= const" << endl;
if(this == &rhs){
return *this;
}
delete this->val;
val = new int(*rhs.val);
return *this;
}
myobj(myobj&& obj){ //移动构造
cout <<"mv" << endl;
val = obj.val;
obj.val = new int(3939);
}
myobj& operator=(myobj&& rhs){ //移动赋值
cout <<"mv=" << endl;
if(this == &rhs){
return *this;
}
if(this->val != nullptr){
delete val;
}
val = rhs.val;
rhs.val = nullptr;
return *this;
}
~myobj(){
cout <<"dest" << endl;
delete val;
val = nullptr;
}
int* val;
};
int main(){
otherc c(10);
myobj other(c);
}
在这种情况下,输出
1
2
3
otherc
convert const
dest
因为是构建了对象c,然后other直接初始化,找到了最匹配的一个构造函数(接受otherc类型的那一个)。直接进行了构造函数调用。
但是,如果我们使用拷贝初始化
1
myobj other = c;
则会输出
1
2
3
4
5
otherc
convert const
mv
dest
dest
因为这时候相当于
1
2
myobj temp(c);
myobj other(move(temp));
- 如果 目标类型 是类类型,且 其他对象 的类型的无 cv 限定版本不是 目标类型 或从 目标类型 派生,或如果 目标类型 是非类类型,但 其他对象 的类型是类类型,那么检测能从 其他对象 的类型转换到 目标类型 (或当 目标类型 是类类型且存在转换函数时,转换到从 目标类型 派生的类型)的用户定义转换序列,并通过重载决议选择最佳者。该转换的结果(如果使用转换构造函数,那么就是无 cv 限定的 目标类型 的右值临时量 (C++11 前)纯右值临时量 (C++11 起)(C++17 前)纯右值表达式 (C++17 起))会被用于直接初始化该对象。最后一步通常会被优化掉,而直接将转换结果构造于分配给目标对象的内存之中,但即便不会使用,也要求适合的构造函数(移动或复制)是可以访问的。 (C++17 前)
所以,我们先有一个转换的结果,然后用结果直接初始化。
转换的结果就是myobj temp(c)。直接初始化就是myobj other(move(temp))
再来看一个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12
myobj a(10);
/*
const
dest
*/
myobj b = 10;
/*
const
mv
dest
dest
*/
- 发现了吗?再次重申:拷贝初始化的核心语义是通过对象来初始化对象,并且采用”拷贝“的方式。因为我们等号右侧会生成临时对象,然后通过拷贝或移动的方式初始化我们的真正对象。
- 例子当中,第一个
const是等号右侧的10发生了隐式类型转换,生成了myobj的临时对象,然后调用移动构造函数移动到b。
右值引用 移动语义 完美转发 万能引用
右值引用
什么是左值?
描述: 能够用&取地址的表达式是左值表达式。
一个区分左值和右值的便捷方法:看能不能对表达式取地址,若能,则为左值,若不能则为右值。所有的具名变量都是左值,而右值是不具名的。
- 函数名和变量名
- 返回左值引用的函数调用
- 前置自增/自减运算符连接的表达式
++i/-–i - 由赋值运算符或复合赋值运算符连接的表达式
a=b、a+=b、a%=b - 解引用表达式
*p - 字符串字面值
”abc” - 具名的右值引用本身是左值
T&&
什么是纯右值?(prvalue)
描述: 满足下列条件之一的:
- 本身就是赤裸裸的、纯粹的字面值,如3、false;
- 求值结果相当于字面值 或 是一个不具名的临时对象。
举例:
- 除字符串字面值以外的字面值。比如
42,true,nullptr - 临时对象
- 返回非引用类型的函数调用(表达式)
- 翻译过来叫做按值返回的函数调用。
- 后置自增/自减运算符连接的表达式
i++/i-– - 算术表达式(
a+b、a&b、a<=b、a<b) - 取地址表达式
&a this指针- 一个转换至非引用类型的类型转换表达式。如
static_cast(x),std::string{},(int)42 - lambda表达式
什么是将亡值?(xvalue)
描述:在C++11之前的右值和C++11中的纯右值是等价的。C++11中的将亡值是随着右值引用的引入而新引入的。换言之,“将亡值”概念的产生,是由右值引用的产生而引起的,将亡值与右值引用息息相关。所谓的将亡值表达式,就是下列表达式:
- 返回右值引用的函数的调用表达式,例如
std::move(x) - 转换为右值引用的转换函数的调用表达式,例如
static_cast<char&&>(x);
在C++11中,用左值去初始化一个对象或为一个已有对象赋值时,会调用拷贝构造函数或拷贝赋值运算符来拷贝资源,而当用一个右值(包括纯右值和将亡值)来初始化或赋值时,会调用移动构造函数或移动赋值运算符来移动资源,从而避免拷贝,提高效率。当该右值完成初始化或赋值的任务时,它的资源已经移动给了被初始化者或被赋值者,同时该右值也将会马上被销毁(析构)。也就是说,当一个右值准备完成初始化或赋值任务时,它已经“将亡”了。这种右值常用来完成移动构造或移动赋值的特殊任务,扮演着“将亡”的角色,所以C++11给这类右值起了一个新的名字——将亡值。 declval也算。因为is_same<int&&, decltype(declval<int>())>::value是true。因为本身它就是add_rvalue_reference,也就是static_cast<T&&>
详细情况:
情况1: ++i是左值,而i++是右值
++i对i加1后再赋给i,最终的返回值就是i,所以,++i的结果是具名的,名字就是i; 而对于i++而言,是先对i进行一次拷贝,将得到的副本作为返回结果,然后再对i加1,由于i++的结果是对i加1前i的一份拷贝,所以它是不具名的。假设自增前i的值是6,那么,++i得到的结果是7,这个7有个名字,就是i;而i++得到的结果是6,这个6是i加1前的一个副本,它没有名字,i不是它的名字,i的值此时也是7。 可见,++i和i++都达到了使i加1的目的,但两个表达式的结果不同。
情况2: 解引用表达式*p是左值,取地址表达式&a是纯右值
&(p)一定是正确的,因为p得到的是p指向的实体,&(p)得到的就是这一实体的地址,正是p的值。由于&(p)的正确,所以*p是左值。 而对&a而言,得到的是a的地址,相当于unsigned int型的字面值,所以是纯右值。
情况3: a+b、a&&b、a==b都是纯右值
a+b得到的是不具名的临时对象,而a&&b和a==b的结果非true即false,相当于字面值。
情况4: 字符串字面值是左值,而非字符串的字面量是纯右值
不是所有的字面值都是纯右值,字符串字面值是唯一例外。
注意一下 虽然字符串字面值是左值,但是依旧不能用左值引用。因为字符串是常量 所以要么加const要么用右值引用
1
2
3
string &s = "abc"; // 错误。 虽然字符串字面值是左值,但是依旧不能用普通左值引用。因为字符串是常量 所以要么加const变成常量左值引用,要么用右值引用。
const string &s = "abc"; //正确 常量引用
string &&s = "abc"; // 右值引用这里是为了接管所有权。所以相当于把“abc"接管了。因为string类有自己的移动构造
情况5: 具名的右值引用是左值,不具名的右值引用是右值。
1
2
3
4
void B(int&& ref_r) {
ref_r = 1;
}
//这里的ref_r是左值
为啥右值不能绑定给左值引用,也就是为啥右值不能取地址?为什么右值可以绑定给常量左值引用?
所有规则都是人订的。其实就仨字:没意义。
我们有一个5。他在这了。你修改它有意义吗?没意义。取地址有意义吗?没意义。硬取可以取,万物皆有地址。但是没意义。
我们有一个临时变量。注意临时变量你看不见。你看不见所以你也动不了他,那给他取个地址有意义吗?没意义。修改有意义吗?没意义。
- 为什么左值引用没法指向右值呢?因为一般来说右值都是临时变量,而且右值是没有地址的。我们也知道引用是别名。所以左值引用无法修改右值,也无法指向右值。这也解释了为什么const 常量左值引用可以指向右值。因为常量左值引用保证用户无法修改指向的值。所以我们能看到vector的push_back使用了常量左值引用为形参。不然你没办法执行
v.push_back(5);这样的语句
https://www.cnblogs.com/philip-tell-truth/p/6370019.html
https://youtu.be/wkWtRDrjEH4?t=359
从语义上分析:
- 因为如果我们按照左值引用传递,语义上,函数会修改这个参数,而且调用方也希望看到这个修改。也就是副作用是可见的。但是如果我们传入一个右值,函数修改参数了,但是调用方无法看到这个修改,因为是临时对象。所以语义说不通。
所以,为什么常量左值引用可以接一切?因为常量左值引用保证了我们不会修改这个参数。可以维持住一个不修改的语义。
- 为什么右值引用传递不能传入左值引用?也是语义不通。右值引用传递,语义上是表明,这个值会被修改且调用方不再会使用这个对象存储的值。所以说如果传入左值引用,无法保证调用方不再使用的语义。
- 针对
move可以是因为程序员接管了这个保证语义正确的过程。也就是编译器允许程序员对语义进行把控。禁止传入本质上是一种提示。
- 针对
- 左值引用语义:
- 函数会修改数据。且调用方会观测任何的修改行为(副作用)
- 常量左值引用语义:
- 函数不会修改数据。在这个行为下,针对这个数据没有副作用。所以调用方是否观测不重要。
- 右值引用语义:
- 函数会修改数据。且调用方不会观测任何的修改行为。
万能引用 (原来叫universal reference,现在叫forwarding reference)
假设我们现在有一个需求。即加法函数。
我们可能会写:
1
2
3
int add(const int& x, const int& y){
return x + y;
}
所以我们可以这样使用:
1
2
3
4
5
6
int main(){
int a = 10;
int b = 20;
add(a, b); //return 30
return 0;
}
但是加法不可以直接接受数字 如 add(10, 20)似乎不是很直观。但是因为10 和 20都是右值。当然了,我们有了右值的概念,现在它难不倒我们。
1
2
3
int add(const int&& x, const int&& y){
return x + y;
}
所以我们可以这样用:
1
2
3
4
int main(){
add(10, 20);
return 0;
}
但是现在它无法接受左值了。如 add(a, b);。 尽管我们可以写出重载,但是有点麻烦。这样我们引出了万能引用,可以让这个函数不仅可以接受左值也可以接受右值。万能引用和右值引用的一个主要区别在于看模板参数和是不是auto声明 如果一个变量或者参数被声明为T&&,其中T是被推导的类型,那这个变量或者参数就是一个universal reference。也就是说,只有发生类型推导的时候,T&&才表示万能引用;否则,表示右值引用。
现在我们可以这样写:
1
2
3
4
5
6
7
8
9
10
11
12
13
template<typename T>
int add(T&& x, T&& y){
return x + y;
}
//这样如下代码可以通过编译
int main(){
int a = 5;
int b = 10;
add(a, b);
add(5, 10);
return 0;
}
因为此时发生了类型推导。所以是万能引用。
但是注意,因为底层用到了 不要这么玩。bind所以如果这样写
1
2
3
4
5
template<typename T>
int add(const T&& x, const T&& y){
return x + y;
}
则需要显式使用std::cref
1
2
3
4
5
6
7
8
int main(){
int a = 5;
int b = 10;
add(a, b); //失败
add(5, 10); //可以
add(std::cref(a), std::cref(b)); //可以
return 0;
}
下面我们来一点小贴士
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
int a = 1;
int &b = a; // 正确 左值引用
int &b = 1; // 错误 左值引用了右值
int &&b = 1; // 正确 正确的右值引用
int &&b = a; //错误 右值引用只能引用右值
int &&b = move(a); //正确 move(移动语义)可以将左值转换为右值然后进行右值引用。
int &&b = (int&&)a; // 正确 强制将左值a转换为右值(临时变量)形式并引用。尽量不要用这种方式,能用move就用move
int &&a = 1; // 这叫右值引用
void test(int && a){} //这也叫右值引用
auto &&b = 1; // 这不叫右值引用,这叫万能引用。因为是auto关键词修饰。所有的auto&&都是万能引用,因为总是有参数的推导过程
template<typename t>
void func(vector<t>&& param){}// 这不是万能引用, 是右值引用。虽然然有推导过程,但是这里模板只推导t的类型。但实际上param的类型一直都是vector<t>&&
template<typename t>
void func(t&& param){} // 这不是右值引用,这是万能引用。因为整个param的类型都需要被推导。
template<class T>
struct A
{
template<class U>
A(T&& x, U&& y, int* p); // x 不是转发引用:T 不是构造函数的类型模板形参。也就是T不涉及型别推导。
// 但 y 是转发引用。因为U是构造函数的类型模板形参。涉及到型别推导。
};
小技巧
- 如果
T和&&中间有<>间隔,那么就不是万能引用 如果不涉及型别推导,那么就算是
T&&也不是万能引用。(格外注意!!!!)当参数加上
const的时候一定不是万能引用,是右值引用- 所有的
auto&&都是万能引用- 除了从花括号包围的初始化器列表推导时。
具名的右值引用本身是个左值。所以它有地址。
若采用右值来初始化万能引用,就会得到一个右值引用,如果采用左值来初始化,则会得到一个左值引用。
- 万能引用只可在函数模板中被推导。类模板无法被推导,因为类模板的类型在实例化的时候已经被确定。所以如果想要在模板类中针对某一函数使用万能引用,则该函数也要为模板函数。
显式禁用某个函数接受右值引用
1
2
3
template <typename T>
void f(const T&&) = delete;
const T&&允许你重载一个函数模板,它只接受右值引用。如果const T&&也被当做universal reference,那么将没有办法让函数只接受右值引用。
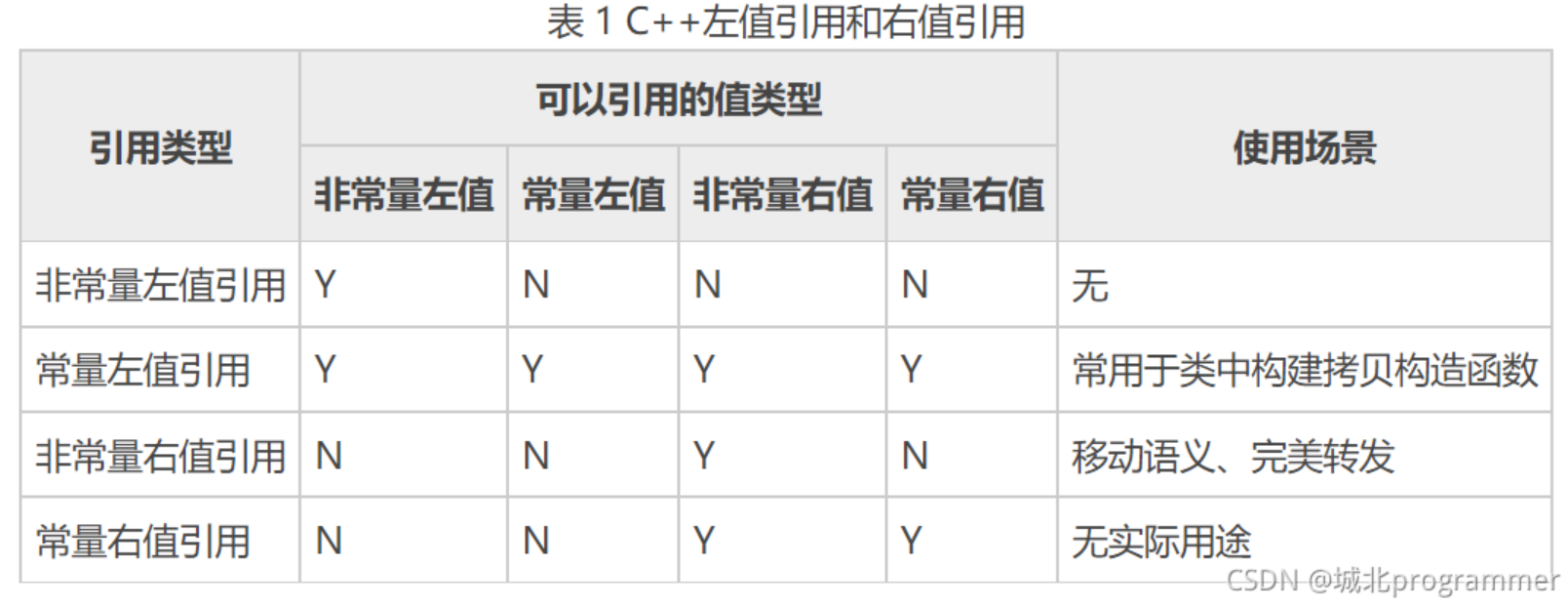
引用折叠(Universal Collapse)
万能引用说完了,接着来聊引用折叠(Universal Collapse),因为完美转发(Perfect Forwarding)的概念涉及引用折叠。
只有万能引用(auto, decltype, typedef)才有引用折叠 为什么?
template<typename T>
void refd(T& obj){
cout << obj << endl;
}
refd(T);
我们这个函数,只可以接受左值。而且,这个时候无论函数实参是否是引用,T都会被推导为T,因为引用属性会被去掉。看一下下面函数模板参数推导的解释即可。
然而
1
2
3
4
template<typename T>
void refd(T&& obj){
cout << obj << endl;
}
这个函数的形参是个万能引用。在函数模板参数推导的解释中,只有这样,T才有可能被推导(折叠)为左值引用或是普通的数据。
- 在实参传递给函数模板的时候,推导出来的模板形参会把实参是左值还是右值的信息”编码”到结果里面:如果传递的实参是个左值,
T的推导结果就是个左值引用型别;如果传递的实参是个右值,T的推导结果就是个非引用型别(注意这里的非对称性:左值的编码结果为左值引用型别,但右值的编码结果却是非引用型别。后续forward或move会使用这个特点)
1
2
3
4
5
6
7
8
template<typename T>
void func(T&& param);
Widget WidgetFactory() //返回右值
Widget w;
func(w); //T的推导结果是左值引用类型,T的结果推导为Widget&
func(WidgetFactory()); //T的推导结果是非引用类型(注意这个时候不是右值),T的结果推导为Widget.因为WidgetFactory()函数返回的是一个右值,然后被推导为非引用类型。这个时候使用完美转发,会被forward推导为&&。就变成右值了。
C++中,“引用的引用”是违法的,但是上面T的推导结果是Widget&时,就会出现 void func(Widget& && param);左值引用+右值引用
C++有单独的规则来把类型推断中出现的引用的引用转换为单个引用,称为“引用折叠”。折叠规则为:
一个模板函数,根据定义的形参和传入的实参的类型,我们可以有下面四中组合:
- 左值-左值
T&&# 函数定义的形参类型是左值引用,传入的实参是左值引用 - 左值-右值
T&&&# 函数定义的形参类型是左值引用,传入的实参是右值引用 - 右值-左值
T&&&# 函数定义的形参类型是右值引用,传入的实参是左值引用 - 右值-右值
T&&&&# 函数定义的形参类型是右值引用,传入的实参是右值引用
但是C++中不允许对引用再进行引用,对于上述情况的处理有如下的规则:
所有的折叠引用最终都代表一个引用,要么是左值引用,要么是右值引用。规则是:如果任一引用为左值引用,则结果为左值引用。否则(即两个都是右值引用),结果为右值引用。
即就是前面三种情况代表的都是左值引用,而第四种代表的右值引用。
- 引用折叠是为了让移动语义
move和完美转发forward正常运行。
值类别(Value category)和 数据类型(data type)
值类别只有五种:泛左值(glvalue),纯右值(prvalue),将亡值(xvalue),左值(lvalue),右值(rvalue)
1
int&& foo = 5;
foo的data type数据类型是右值引用(5)。但是foo的Value category值类别是左值(因为有一个名字)
所以我们说。具名右值引用本身是左值。因为它的数据类型是右值引用,但是值类别是左值。
小练习:
1
2
const Widget* foo;
void someMethod(const Widget&);
- 哪一种值类别value category可以被传入someMethod()?
- 任意一种。因为常量左值引用接一切。
- 哪一种数据类型data type可以被传入?
- Widget。
完美转发
为什么会有完美转发?我们知道具名的右值引用是左值。那我们一个函数接受右值引用然后将其放入另一个函数的时候这个具名的右值引用会变成左值,所以放入另一个函数的时候会变成左值。
完美转发的核心意义在于,我们要维持传入的参数的特性。我们传入的是左值,就维持左值特性。传入右值就维持右值特性。所以我们才使用forward。因为forward只有在传入的实参是右值的时候才会将其转换为右值。否则都当做左值看待。
尽管move和forward的第一层作用都是维持右值的右值性,但是forward是move的超集。因为forward可以搭配万能引用来进行坍缩(折叠)来维持左值的左值性。所以可以理解为完美转发 = 万能引用 + (引用折叠)+ forward
一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
using std::cout;
using std::endl;
template<typename T>
void func(T& param) {
cout << "传入的是左值" << endl;
}
template<typename T>
void func(T&& param) {
cout << "传入的是右值" << endl;
}
template<typename T>
void warp(T&& param) {
func(param);
}
int main() {
int num = 2019;
warp(num);
warp(2019);
return 0;
}
这个程序会有如下输出:
1
2
"传入的是左值"
"传入的是左值"
因为我们传入的2019在进入warp函数的时候,这个右值有了名字。它叫做param了。也就是它是一个具名右值引用。我们说过了具名右值引用是左值。所以会调用传入左值的func函数。
那我们如果依旧希望这个值是右值应该怎么办? 可以使用完美转发。std::forward<T>(u)有两个参数:T与 u。
- 当函数入参
(param)为左值或左值引用类型时,u将被转换为T类型(左值引用)。(注意这里是转换不是保持。因为u(param)在传进来的时候形参是T&&。带了&&会触发推导。无论函数实参入参的时候是int还是int&统一会被推导为int&。下面表格有)。- 上面我们说过,使用万能引用进行函数参数推导的时候,左值或左值引用类型的入参会被推断为左值引用类型。所以这里相当于维持或转换为左值引用的性质。
- 否则
u将被转换为T类型右值。- 上面我们说过,使用万能引用进行函数参数推导的时候,右值类型的入参会被推断为其本身的数据类型(不带引用)。这里就是维持右值特性。
- 仅当传入的实参被绑定到右值时,
std::forward才针对该实参实施向右值型别的强制型别转换
1
2
3
4
5
6
7
8
9
10
template<typename T>
void warp(T&& param) {
func(std::forward<T>(param));
}
int main(){
int num = 2019;
warp(2019); //这时候输出右值。
warp(num); //这时候输出左值。
return 0;
}
这里可能看起来有点奇怪。我们需要介绍一个很多人不会很仔细去看的小知识点 即 函数模板参数推导
具体实现
1
2
3
4
5
6
7
8
9
10
template<typename _Tp>
constexpr _Tp&&
forward(typename std::remove_reference<_Tp>::type& __t) noexcept //_Tp为左值引用的时候
{ return static_cast<_Tp&&>(__t); }
template<typename _Tp>
constexpr _Tp&&
forward(typename std::remove_reference<_Tp>::type&& __t) noexcept //_Tp为右值引用的时候。当且形如forward<int&&>(5)的时候或如同官方文档中的例子时才会匹配至这个版本
{return static_cast<_Tp&&>(__t);}
函数模板参数推导
举例子
1
2
3
4
5
6
7
8
9
10
template<typename T>
void f(P param){ //此处P为故意。P可以代表 T/T&/T&&/const T/const T&/const T&&
//这个param就是A。有的表格会把P换成A的部分。
//...
}
int main(){
f(A);
return 0;
}
其中 P 和 T 有关。 有下列的推导规则:
A的引用属性被忽略.P是非引用时,A的 cv 限定符被忽略.- 如果
P是无 cv 限定符的转发引用 (即T&&), 且A是左值时,T被推导为左值引用. - 如果
A是数组或函数,P是值时, 数组和函数退化为指针.P是引用时, 不退化为指针.
这里 cv 限定符指的是 const 和 volatile.
下面我们看上面的规则。
1
warp(num);
这里num是左值 即 int类型, 函数头为T&&。参照下面的表格,T被推导为int&。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
T = int&
void warp(int & && param){
func(std::forward<T>(param));
}
//折叠后:
T = int&
void warp(int& param){
func(std::forward<int&>(param));
}
//套用forward
constexpr int& && //折叠
forward(typename std::remove_reference<int &>::type& __t) noexcept //remove_reference的作用与名字一致,就是去掉<>内类型的引用。这里就是int&变成int
{ return static_cast<int & &&>(__t); } //折叠
//折叠后:
constexpr int& //折叠
forward(int& __t) noexcept
{ return static_cast<int&>(__t); } //折叠
所以最终会把参数param强制转换为int&一个左值引用。是左值,所以调用左值版本的func。
1
warp(2019);
这里参数是右值。函数头为T&&。参照下面表格,T被推导为int。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
T = int
void warp(int&& param){
func(std::forward<T>(param));
}
//不发生折叠。处理后:
T = int
void warp(int&& param){
func(std::forward<int>(param));
}
//套用forward
constexpr int &&
forward(typename std::remove_reference<int>::type& __t) noexcept //注意这里依旧匹配到的是&左值版本而不是&&右值版本
{ return static_cast<int &&>(__t); }
//处理后
constexpr int &&
forward(int & __t) noexcept
{ return static_cast<int &&>(__t); }
所以最终会把参数param强制转换为int&&。是一个右值。所以调用右值版本的func。
- 为什么这里的
forward依旧匹配的是左值版本而不是右值版本?我们说了,一旦右值参数被右值引用接住了,那么这时候这个参数就是左值了。所以说这时候param本身是左值。 - 那么什么时候可以匹配到右值引用呢?就是当括号内塞的本身是个右值的时候。比如
std::forward<int&&>(5)这个时候匹配的就是右值引用的forward
https://blog.csdn.net/qq_33850438/article/details/107193177 https://lamforest.github.io/2021/04/29/cpp/wan-mei-zhuan-fa-yin-yong-zhe-die-wan-neng-yin-yong-std-forward/
更加详细的例子:
如果函数模板参数以万能引用作为一个模板参数,当参数传入左值的时候,模板会自动将其类型认定(推导)为左值引用;当传入右值的时候,会当做(推导)成普通数据使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template<typename T>
void foo(T&& t){
//...
}
//随后传入一个右值,T的类型将被推导为:
foo(42); // foo<int>(42)
foo(3.14159); // foo<double>(3.14159)
foo(std::string()); // foo<std::string>(std::string())
//不过,向foo传入左值的时候,T会被推导为一个左值引用:
int i = 42;
foo(i); // foo<int&>(i)
//向foo传入右值的时候,T会被推导为一个普通数据:
foo(2019); //foo<int>(2019);
//因为函数参数声明为T&&,所以就是引用的引用,可以视为是原始的引用类型。那么foo<int&>()就相当于:
foo<int&>(); // void foo<int&>(int& t);
- 这就允许一个函数模板可以即接受左值,又可以接受右值参数;这种方式已经被
std::thread的构造函数所使用
若采用右值来初始化万能引用,就会得到一个右值引用,如果采用左值来初始化,则会得到一个左值引用。
一个其他情况
在我们不使用万能引用, 只使用std::forward的时候, 传入左值会被转换为右值引用. 原因看源码即可.
1
2
3
4
5
6
template <typename T>
void warp(T&& param) {
cout << __PRETTY_FUNCTION__ << endl;
func(std::forward<T>(param));
cout <<std::is_same<decltype(std::forward<T>(param)), int&&>::value << endl; // true
}
这种情况下 转发后的类型是右值引用.
所以std::forward应该总是搭配万能引用.
移动语义
我们知道使用对象来对另一个对象进行初始化的时候会调用拷贝构造。但是如果我们不想使用拷贝构造呢?我们可以定义一个移动构造,形参为右值引用。换句话说,右值引用允许我们在使用临时对象时避免不必要的拷贝。只有右值引用才能调用移动构造函数和移动赋值函数。但是如果我们使用的是一个左值而且不想使用拷贝构造应该怎么办呢? 我们可以用std::move移动语义来把一个左值转换为右值来触发移动构造。 std::move是一个非常有迷惑性的函数,不理解左右值概念的人们往往以为它能把一个变量里的内容移动到另一个变量,但事实上std::move移动不了什么,唯一的功能是把左值强制转化为右值,让右值引用可以指向左值。其实现等同于一个类型转换:static_cast<T&&>(lvalue)。
记住,在没有自定义的移动构造函数的时候,move函数仅仅是把左值转换为右值。当有移动构造函数的时候,调用过move(转换为右值)的参数就会触发移动构造,来实现移动语义(所有权转移)
- 当容器
vector<T>的类型T有自定义的移动构造的时候,使用move将其元素转换为右值后才会触发移动构造。并且移动构造函数应声明为noexcept方可被vector使用 - 移动构造函数中的异常问题: 对于移动构造函数来说,抛出异常有时是件危险的事情,因为可能移动语义还没完成,一个异常却被抛出来了,这就会导致一些指针成为悬挂指针。因此应尽量不要在移动构造函数中抛出异常,通过为其添加一个noexcept关键字,可以保证移动构造函数中抛出来的异常会直接调用terminate终止运行。
我们举一个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class A{
public:
int val = 0;
A(){}
A(int x):val(x){}
A(A&& rhs){ //移动构造
this->val = rhs.val;
cout <<"move" << endl;
rhs.val = 0;
}
A& operator=(A&& rhs){ //移动赋值
if(this != &rhs){
this->val = rhs.val;
cout <<"move equal" << endl;
rhs.val = 0;
}
}
};
当我们有自定义的移动构造的时候,我们可以试试看move
1
2
3
4
5
6
7
int main(){
A* a = new A(5);
A* b = new A(move(*a)); //输出move 因为调用的是移动构造
cout << a->val << endl; //输出0
cout << b->val << endl; //输出5
return 0;
}
请记住。当使用move对指针操作时,相当具有迷惑性。我们不应移动指针,应移动指针指向的对象。
错误示范:
1
2
3
4
5
int main(){
A* a = new A(5);
A* b = move(a);
return 0;
}
这里的move什么也没干。仅仅是把指针a本身转换成右值然后拷贝给指针b。还记得我们说过指针给指针赋值,结果是让两个指针指向同一个地址吗?所以这段代码执行后,我们会得到一个浅拷贝的指针。 即 指针a和指针b都指向一个地址。
1
2
3
4
5
6
7
8
int main(){
A* a = new A(5);
A* b = new A(0);
*b = move(*a); //输出 move equal 因为是移动赋值
cout << a->val << endl; //输出0
cout << b->val << endl; //输出5
return 0;
}
给已有对象操作时调用赋值,生成新对象时调用构造。
std::move 的底层实现
- 我们前面提到过一个引用折叠的知识点。可以回去查看。
- 我们也提到过
move仅仅是把一个值转换为右值。 move不会改变参数的常量性。也就是保持CV属性。- 这会导致在对 以常量左值引用 传入的参数 使用move的时候,移动无效转而进行拷贝的问题。
- 查看拷贝构造。
- https://www.nextptr.com/tutorial/ta1211389378/beware-of-using-stdmove-on-a-const-lvalue
- 这会导致在对 以常量左值引用 传入的参数 使用move的时候,移动无效转而进行拷贝的问题。
看一下原型定义:
1
2
3
4
5
template <typename T>
typename remove_reference<T>::type&& move(T&& t)
{
return static_cast<typename remove_reference<T>::type&&>(t);
}
首先,函数参数T&&是一个万能引用,通过引用折叠,此参数可以与任何类型的实参匹配(可以传递左值或右值,这是std::move主要使用的两种场景)。关于引用折叠如下:
- 第一种情况:折叠成左值的时候:
1
2
3
4
5
6
7
8
9
10
11
12
string s("hello");
此时s的型别为左值。然后通过引用折叠的规则,左值会被推导为左值引用的类型。也就是说此时的T由于是个左值,被推导为了T&
std::move(s) => std::move(string& &&) [被推导为T&也就是string &] => 触发折叠后 std::move(string& )
此时:T的类型为string&
typename remove_reference<T>::type为string
整个std::move被实例化如下
string&& move(string& t) //t为左值,移动后不能在使用t。[这里是string&的原因就是 T = string&, 那么 T&& = string& &&, 触发折叠 string&]
{
//通过static_cast将string&强制转换为string&&
return static_cast<string&&>(t);
}
- 第二种情况:折叠成右值的时候:
1
2
3
4
5
6
7
8
9
此时s的型别为右值。然后通过引用折叠的规则,右值会被推导为右值类型。也就是说此时的T由于是个右值,被推导为了T
std::move(string("hello")) => std::move(string&&) [被推导为T也就是string] => 触发折叠后 std::move(string&&)
//此时:T的类型为string
// remove_reference<T>::type为string
//整个std::move被实例如下
string&& move(string&& t) //t为右值
{
return static_cast<string&&>(t); //返回一个右值引用
}
- 总结:
- 首先,通过万能引用利用引用折叠原理:
- 右值经过
T&&传递类型保持不变还是右值 - 左值经过
T&&折叠为普通的左值引用T&,以保证模板可以传递任意实参,且保持类型不变。
- 右值经过
- 然后我们通过
static_cast<>T进行强制类型转换返回T&&右值引用,而static_cast<T>之所以能使用类型转换,是通过remove_refrence<T>::type模板移除T&&,T&的引用,获取具体类型T。
- 首先,通过万能引用利用引用折叠原理:
- 所以说,
move的效果和static_cast<T&&>()是一致的。
整理
- 在《Effective Modern C++》中建议(条款25):对于右值引用的最后一次使用实施
std::move,对于万能引用的最后一次使用实施std::forward。- 因为右值引用总是可以无条件转换为右值,因此用
std::move。所以函数形参为右值引用的时候,如果想使用参数的右值特性,可以直接使用move - 但万能引用不一定是右值,因此要用
std::forward做有条件的右值转换。如果无意间在万能引用接受的值实际是个左值引用的时候使用了move可能会出现严重问题。 - 局部对象在如下情况会触发RVO。此时使用
move或forward会带来负优化。- 局部对象类型和函数的返回值类型相同
- 返回的就是局部对象本身
- 因为右值引用总是可以无条件转换为右值,因此用
- 在《Effective Modern C++》中提到(条款23)
std::move()不move任何东西,std::forward()也不转发任何东西。这两者在运行期都无所作为。它们不会生成任何可执行代码,连一个字节都不会生成。他们都仅仅做了类型转换而已。真正的移动操作是在移动构造函数或者移动赋值操作符中发生的。std::move无条件的将它的参数转换成一个右值,而std::forward当特定的条件满足时,才会执行它的转换。反复强调std::forward仅当参数被右值绑定时,才会把参数转换为右值。也就是std::forward可以理解为conditional move - 使用move来转换为右值,使用forward来进行有条件的型别转换。在转换为右值后,相当于告诉编译器,我是右值,我可以被选择移动而不是拷贝。仅此而已。
- 如果一个类没有提供移动构造或移动赋值,使用
move转换为右值后,再进行构造新对象或赋值给对象的时候会匹配到拷贝构造或拷贝赋值。也就是能移动则移动,不能移动就拷贝。— 笔记拷贝构造中提到了。
- 如果一个类没有提供移动构造或移动赋值,使用
std::move()可以应用于左值(普通的变量int这些使用move与不使用move效果一样),但这么做要谨慎。因为一旦“移动”了左值,就表示当前的值不再需要了,如果后续使用了该值,产生的行为是未定义。- 注意,一个已经被移动过的对象被移动后仍然需要调用析构函数(或其析构函数仍然会被调用)。移动并不代表对象消亡。只是代表对象内含的数据的所有权转移。也就是说,移动的是对象蕴含的资源,而不是对象的状态。也就是说,移动后的对象虽然资源被窃取,但是其依旧是合法状态。
- 理解为目前是两个东西。只不过我们把第一个东西里面的数据转移给了第二个东西。但是现在依旧是俩东西。所以整个程序结束,还是有两次析构。这两个东西都要被析构。等于瓤只有一个,壳子有俩。只要销毁壳子,无论有没有瓤,都得析构。
- 所以说,一个对象被移动了,必须也能被析构。
- https://stackoverflow.com/questions/20589025/why-is-the-destructor-call-after-the-stdmove-necessary
1
2
3
4
5
6
7
8
9
myobj a(5);
//myobj b(move(a)); //这一种和下面的一种一样。都是调用移动构造。
myobj c = move(a);
/*
constructor
move constructor
destructor
destructor
*/
https://blog.csdn.net/qq_41453285/article/details/104447573
右值引用解决了什么问题?面试回答
右值引用分两个部分,移动语义和完美转发。
- 移动语义解决了所有权转移的问题,比如智能指针。而且可以配合移动构造函数避免使用临时对象的时候造成的拷贝。而且配合容器使用可以提升性能。可以理解为浅拷贝。
- 浅拷贝:我不需要两个指针指向同一个对象。那么可以把原来的指针指向的数据赋值给新的指针。这样数据依旧只有一份。
- 深拷贝:我需要两个指针指向两个数据相同的对象。那么需要在拷贝构造中额外开辟一块内存,进行新的数据的初始化。
- 完美转发就是保持传入值的特性,左值维持左值,右值维持右值。
函数类型推导表格
1
2
3
4
5
6
7
8
template<typename T>
void f(P param){
//...
}
int main(){
f(A);
return 0;
}
| P | A | T |
|---|---|---|
| T | int | int |
| T | int* | int* |
| T | int& | int |
| T | const int | int |
| T | const int * | const int * |
| T | int * const | int * |
| T | const int & | int |
| T | const int * const | const int * |
| T | char [2] | char * |
| T | const char [12] | const char * |
| T | void (int) | void (*)(int) |
| const T | int | int |
| const T | int * | int * |
| const T | int & | int |
| const T | const int | int |
| const T | const int * | const int * |
| const T | const int & | int |
| const T | const int * const | const int * |
| const T | char [2] | char * |
| const T | const char [12] | const char * |
| const T | void (int) | void (*)(int) |
| T& | int | int |
| T& | int * | int * |
| T& | int & | int |
| T& | const int | const int |
| T& | const int * | const int * |
| T& | const int & | const int |
| T& | const int * const | const int * const |
| T& | char [2] | char [2] |
| T& | const char [12] | const char [12] |
| T& | void (int) | void (int) |
| T&& | int | int & |
| T&& | int * | int *& |
| T&& | int & | int & |
| T&& | const int | const int & |
| T&& | const int * | const int *& |
| T&& | const int & | const int & |
| T&& | const int * const | const int * const & |
| T&& | char [2] | char (&)[2] |
| T&& | const char [12] | const char (&)[12] |
| T&& | void (int) | void (&)(int) |
| T&& | int && | int |
| const T& | int && | int |
https://www.cnblogs.com/5iedu/p/11183878.html
一些关于static 作用域的小问题
静态全局变量只能在当前的文件中访问,其它文件不可访问,即使是extern也不行。也就是其作用域是定义的文件内。
- 静态全局变量有以下特点:
- 该变量在全局数据区分配内存;
- 未经初始化的静态全局变量会被程序自动初始化为0(自动变量的值是随机的,除非它被显式初始化)
- 其它文件中可以定义相同名字的变量,不会发生冲突;
- 静态全局变量有以下特点:
静态局部变量有以下特点:
该变量在依然全局数据区分配内存;
静态局部变量在程序执行到该对象的声明处时被首次初始化,即以后的函数调用不再进行初始化;
静态局部变量一般在声明处初始化,如果没有显式初始化,会被程序自动初始化为0;
它始终驻留在全局数据区,直到程序运行结束。但其作用域为局部作用域,当定义它的函数或语句块结束时,其作用域随之结束;
静态函数
- 在函数的返回类型前加上static关键字,函数即被定义为静态函数。静态函数与普通函数不同,它只能在声明它的文件当中可见,不能被其它文件使用。
- 定义静态函数的好处:
- 静态函数不能被其它文件所用;
- 其它文件中可以定义相同名字的函数,不会发生冲突;
静态数据成员特点:
- 理解为带有作用域的全局变量,但是:同全局变量相比,使用静态数据成员有两个优势:
- 静态数据成员没有进入程序的全局名字空间,因此不存在与程序中其它全局名字冲突的可能性;
- 可以实现信息隐藏。静态数据成员可以是private成员,而全局变量不能;
- 对于非静态数据成员,每个类对象都有自己的拷贝。而静态数据成员被当作是类的成员。无论这个类的对象被定义了多少个,静态数据成员在程序中也只有一份拷贝,由该类型的所有对象共享访问。也就是说,静态数据成员是该类的所有对象所共有的。对该类的多个对象来说,静态数据成员只分配一次内存,供所有对象共用。所以,静态数据成员的值对每个对象都是一样的,它的值可以更新;
- 静态数据成员存储在全局数据区。静态数据成员定义时要分配空间,所以不能在类声明中定义。因为声明只是描述了如何分配内存, 但实际上并不真正分配内存。
- 静态数据成员和普通数据成员一样遵从public,protected,private访问规则;
- 因为静态数据成员在全局数据区分配内存,属于本类的所有对象共享,所以,它不属于特定的类对象,在没有产生类对象时其作用域就可见,即在没有产生类的实例时,我们就可以操作它;
- 静态数据成员初始化与一般数据成员初始化不同。静态数据成员初始化的格式为:
<数据类型><类名>::<静态数据成员名>=<值> - 类的静态数据成员有两种访问形式:
<类对象名>.<静态数据成员名>或<类类型名>::<静态数据成员名>如果静态数据成员的访问权限允许的话(即public的成员),可在程序中,按上述格式来引用静态数据成员 ; - 静态数据成员主要用在各个对象都有相同的某项属性的时候。比如对于一个存款类,每个实例的利息都是相同的。所以,应该把利息设为存款类的静态数据成员。这有两个好处,第一,不管定义多少个存款类对象,利息数据成员都共享分配在全局数据区的内存,所以节省存储空间。第二,一旦利息需要改变时,只要改变一次,则所有存款类对象的利息全改变过来了;
- 理解为带有作用域的全局变量,但是:同全局变量相比,使用静态数据成员有两个优势:
静态函数成员特点
与静态数据成员一样,我们也可以创建一个静态成员函数,它为类的全部服务而不是为某一个类的具体对象服务。静态成员函数与静态数据成员一样,都是类的内部实现,属于类定义的一部分。普通的成员函数一般都隐含了一个this指针,this指针指向类的对象本身,因为普通成员函数总是具体的属于某个类的具体对象的。通常情况下,this是缺省的。但是与普通函数相比,静态成员函数由于不是与任何的对象相联系,因此它不具有this指针。从这个意义上讲,它无法访问属于类对象的非静态数据成员,也无法访问非静态成员函数,它只能调用其余的静态成员函数。
出现在类体外的函数定义不能指定关键字static;
静态成员之间可以相互访问,包括静态成员函数访问静态数据成员和访问静态成员函数;
非静态成员函数可以任意地访问静态成员函数和静态数据成员;(因为this指针可以省略不放进静态函数的入参)
静态成员函数不能访问非静态成员函数和非静态数据成员;(缺一个this指针,肯定不行)
不可以同时用const和static修饰成员函数。(没有this指针)
由于没有this指针的额外开销,因此静态成员函数与类的全局函数相比速度上会有少许的增长;
调用静态成员函数,可以用成员访问操作符(.)和(->)为一个类的对象或指向类对象的指针调用静态成员函数,也可以直接使用如下格式:
<类名>::<静态成员函数名>(<参数表>)
类的静态函数为什么不能调用非静态成员?
类的非静态函数在编译后,第一个隐藏的参数是一个this指针。但是静态函数没有这个隐藏参数。如果调用了非静态成员,参数无法匹配。
- 类的非静态函数调用的时候大概长这样:
1 2
myDate.setMonth( 3 ); //非静态函数正常调用 setMonth(&myDate, 3); //非静态函数假设调用(显式标出this指针)
this指针的特性:
- this指针的类型:
类类型 *const; - this指针并不是对象的一部分,不会影响对象的大小;
- this指针是非静态成员函数的第一个隐含指针形参,是编译器自己处理的,我们不能在成员函数的形参中添加this指针的参数定义,也不能在调用时显示
- this指针的类型:
为什么类的静态成员变量必须在类外部初始化?
- 因为静态成员变量属于整个类,而不属于某个对象,如果在类内初始化,会导致每个对象都包含该静态成员,这是矛盾的。
- 类的静态成员变量可以理解为加了作用域的全局变量。自然需要类外初始化。
**任何类内的内存分配函数必须要声明为静态函数 static **
- 静态成员函数即使在类对象不存在的情况下也能被调用,静态函数只要使用类名加范围解析运算符 :: 就可以访问。new对象时,对象还没有,设置成类非静态成员函数是没意思的,隐藏的this指针无从下手,所以要声明为static函数。
static成员变量类外实例化看起来可能非常诡异
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
template<typename T, typename ...Args>
struct test{ //类模板加嵌套类
struct innertest{
innertest(){
std::cout <<"inndertest constructor called\n";
}
inline void do_nothing()const { };
};
test(){
std::cout <<"test constructor called\n";
m_innertest.do_nothing();
}
static innertest m_innertest;
};
struct test_n{ //普通类加嵌套类
struct innertest_n{
innertest_n(){
std::cout <<"inndertest_n constructor called\n";
}
inline void do_nothing()const { };
};
test_n(){
std::cout <<"test_n constructor called\n";
m_innertest_n.do_nothing();
}
static innertest_n m_innertest_n;
};
struct normal{ //普通类
static int var;
};
template<typename T, typename ...Args>
typename test<T, Args...>::innertest test<T, Args...>::m_innertest; //类模板加嵌套类,得写两次模板参数。
/*因为格式是 类型名 作用域::变量名
前面的是类型名。后面的要先指定外层作用域(这时候就要加模板参数了)然后指定名字。所以看起来比较诡异。
*/
test_n::innertest_n test_n::m_innertest_n; //普通嵌套类。看起来比较正常。
int normal::var; //普通类。
整理static作用:
全局变量、静态全局变量和类的静态成员变量在main执行之前的静态初始化过程中分配内存并初始化
局部静态变量(一般为函数内的静态变量)在第一次使用时分配内存并初始化
- 修饰类成员函数:
- 该成员函数可以不通过对象调用,可以通过作用域运算符直接调用。
- 静态成员函数 只能访问或修改静态成员变量和函数, 不会访问或者修改任何对象非static数据成员。因为类的静态成员变量和函数在类加载的时候就会分配内存,而非static成员属于对象,在对象创建的时候才会分配内存。(没有this指针)
- static成员函数不能被
const,volatile修饰。且不可是虚函数
- 修饰类成员变量
- 该成员变量所有该类对象共享。相当于带作用域的全局变量。
- 注意类内局部变量不是类成员变量。
- 由于static变量不属于任何一个对象,因此不会在构造函数中赋值,初始值是静态区的默认值0,后面需要在类外赋初值
- 类中的变量可以被类和对象访问,初始值为0,可以在类外赋初始值。
- 类内static变量在类外初始化。可以通过 类名::变量名 访问,也可以通过 对象::变量名 访问
- 当
static const一起修饰时,可以在类中赋初始值
- 修饰全局变量
- 该变量和全局普通变量一样在全局数据区分配内存。但是静态全局变量作用域只在本文件。其他文件不可见。
- 修饰全局普通函数
- 全局静态函数 相对于普通函数,作用域只限制在本文件中;而普通的全局函数默认是extern的,其他源文件也可以访问。
- 修饰局部变量
它从声明(但是必须运行)起驻留在全局数据区,直到程序运行结束。但其作用域为局部作用域,当定义它的函数或语句块结束时,其作用域随之结束;
局部静态变量的生存周期是从声明(但是必须程序执行到该对象的声明处)起至程序结束。
同时局部静态变量只允许被初始化一次。
- 修饰类对象
- 普通对象可以通过extern跨文件访问,静态对象本文件访问
- 静态对象如果在函数内,执行的时候才会构造,在函数外,全局static类对象在main前构造。
外部链接性,内部链接性,无链接性
- 声明外部链接的变量的方法是在代码块外面声明它. 此变量是全局变量,多文件中亦可用.
- 声明内部链接的变量的方法是在代码块外面声明它并加上
static限定符. 此变量是全局变量,但仅在本文件中可用.static就是这样限定作用域在文件范围内的。因为static不在全局符号表。 - 声明无链接的变量的方法是在代码块里面声明它并加上
static限定符. 此变量是局部变量,但仅在本代码块中可用.
符号表(csapp7.5)
每个可重定位目标模块m都有一个符号表,它包含m定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
- 由模块
m定义并能被其他模块引用的全局符号。全局链接器符号对应于非静态的C函数和全局变量。 - 由其他模块定义并被模块
m引用的全局符号。这些符号称为外部符号,对应于在其他模块中定义的非静态C函数和全局变量。 - 只被模块
m定义和引用的局部符号。它们对应于带static属性的C函数和全局变量。这些符号在模块m中任何位置都可见,但是不能被其他模块引用。 - 认识到本地链接器符号和本地程序变量不同是很重要的。.symtab中的符号表不包含对应于本地非静态程序变量的任何符号。这些符号在运行时在栈中被管理,链接器对此类符号不感兴趣。(链接器对局部变量不感兴趣)
强符号 弱符号
在C语言中,编译器默认函数和初始化了的全局变量为强符号(Strong Symbol),未初始化的全局变量为弱符号(Weak Symbol)。
强符号之所以强,是因为它们拥有确切的数据,变量有值,函数有函数体;弱符号之所以弱,是因为它们还未被初始化,没有确切的数据。
链接器会按照如下的规则处理被多次定义的强符号和弱符号:
- 不允许强符号被多次定义,也即不同的目标文件中不能有同名的强符号;如果有多个强符号,那么链接器会报符号重复定义错误。
- 如果一个符号在某个目标文件中是强符号,在其他文件中是弱符号,那么选择强符号。
- 如果一个符号在所有的目标文件中都是弱符号,那么选择其中占用空间最大的一个。
链接器
链接器不仅仅去解析未定义的符号引用和替换符号地址,同时链接器还要完成程序中各目标文件的地址空间的组织,这涉及重定位工作。
- 也就是说,链接器负责安排我们看到的各个段的位置。如果你想的话,可以修改链接器脚本让链接器把不同代码段混着摆。
https://youtu.be/dOfucXtyEsU?t=1882
linux的链接器在使用动态链接库的时候是惰性查找。也就是只为你调用了的函数进行查找。
这样做的目的是加快启动时间。但是有一个问题,也就是第一次调用的时候会较慢,因为这时候这个地址是进行dll查找子程序的地址。之后再次调用的时候这个地址会被替换为函数真正地址。
所以在实时性较高的场景不应该使用动态链接库。或显式使用LD_BIND_NOW来指明立刻应用所有重定位并使用实际地址而不是通过解析器地址填充plt。
定义了两个vector,vector里面存的是类,是否可以直接使用memcpy去复制vector
答案是不能。
首先,vector容器本身只有3个指针(start指向当前第一个数据也就是迭代器的begin位置,finish指向当前最后一个数据也就是迭代器的end位置,end_of_storage指向的是数据存储区的末尾,也就是capacity。)。所以你sizeof(一个vector)得到的一定是3*8 = 24 (64位平台一个指针8字节)。所有的容器都有一个功能,就是帮你"new"一块内存,然后把东西放进去。我们说过,STL是拷贝进来,拷贝出去。那他拷贝的东西放在哪了?我们说的allocator分配子干什么了?答案是:它帮你从堆上分配了内存。因为他有做malloc动作。笨想都知道是从堆分配。栈一共就那么大,你说是吧?所以vector和原始数组不一样。vector对象的地址和数据地址不是连续的。因为vector储存数据的空间是通过malloc单独分配的。
好了,继续我们的话题。
所以假如有如下代码:
1
2
3
4
5
6
7
8
9
10
int main(){
vector<int> a1 = {1,2,3,4,5,6,7,8,9,10};
cout << sizeof(a1) << endl; //输出24
vector<int> test1;
memcpy(&test1, &test, sizeof(test)); //尝试使用memcpy拷贝。
for (auto t : test1) {
cout << t << endl;
}
return 0;
}
它可以部分运行,但是会有double free问题。
针对这行代码:memcpy(&test1, &test, sizeof(test)); 。我们之前提到过,vector自己只有三根指针。你sizeofvector是三根指针的大小,你对vector取地址,取到的不是vector数据的地址,仅仅是这个vector对象的地址。(再次重复一次vector对象只有三根指针)。
所以我们现在知道了,这行代码是把test的三根指针,浅拷贝给了test1。这时候,虽然test里面的三个指针和test1里面的三个指针地址不同(test和test1地址也不同),但是指针指向的数据是同一块。又因为我们后声明的test1,导致test1先被析构,test1里面三个指针指向的数据(vector里面存的数据)被释放(析构)。然后test又执行释放(析构)动作,但是数据(资源)已经被释放了,所以导致了双重释放问题。
注意这里的test1是栈变量。它是定义。所以不用使用构造函数分配空间。vector使用构造函数分配的空间是给储存的数据使用的。我们这里是浅拷贝指针给test1对象而不是储存数据,所以不会出错。
所以我们需要按照下面这么写:
1
2
3
4
5
6
7
8
9
int main(){
vector<int> test = {1,2,3,4,5,6,7,8,9,10};
cout << sizeof(test) << endl;
vector<int> test1(test.size()); //必须分配空间
memcpy(&test1[0], &test[0], sizeof(int) * test.size()); //必须取首地址,并且手动计算数据区大小
for (auto t : test1) {
cout << t << endl;
}
}
不要害怕,我们一点一点来看。
Q1: 为什么这时候test1必须要使用构造函数分配内存?
因为此时我们要复制的是数据本身。数据本身需要让vector来储存,所以必须让vector内部调用分配器帮我们从堆上面拿到用来储存数据的内存块。
Q2: 为什么test1和test要取首地址?
我们已经为test1分配了储存数据的内存。我们提到过,vector对象本身的地址和数据储存的地址是不连续的,是分开的。所以我们需要用这种方式获取他数据储存区的首地址。
Q3: 为什么需要手动计算
唔,这个问题可能不需要回答,但我还是回答一下。我们计算的是每一个int的大小(也就是原容器储存的对象大小)* 原容器储存了多少个对象(size()函数返回的不是容器占用了多少字节,而是容器储存了多少个对象)
定义,声明
变量类型
- 声明:是指出存储类型,并给存储单元指定名称。
- “把一个C++名称引入或者重新引入到你的程序” (来自C++ template A.2)
定义:是分配内存空间,还可为变量指定初始值。
- extern关键字:通过使用extern关键字声明变量名,而不是定义它。
要点1:声明不一定是定义
extern声明没有分配内存空间,所以不是定义;extern告诉编译器变量在其他地方定义了。
例如:extern int val; // 只是声明了变量val,并没有分配内存空间,所以不是定义。
要点2:定义也是声明
定义变量的时候,同时给变量指出了存储类型,并给变量的存储单元指定了名称,所以也是声明。
例如:int val;// 声明了变量val,也会分配内存空间,所以也是定义。
例如:vector<int> a;// 声明了vector容器 a, 也会分配vector对象的内存空间(提到过vector本身24字节)。所以也是定义。
要点3:extern关键字标识的才是声明,其余都是定义
例如: extern int val; // 声明 int val; // 定义
要点4:声明有指定初始值:如果指定了初始值,即使前面加了extern关键字,也是定义。
例如:extern int val = 1; // 定义
要点5: 一个变量的定义永远只能有一个,但是可以有多个声明。
函数类型
要点1:函数原型(又称函数声明):函数原型之于函数,相当于变量声明之于变量,只有函数头的就是函数原型。
例如: int function();
extern int function();
要点2 :函数定义:带有函数体的就是定义,
例如: int function() { return 0; }
注:
函数原型的返回值类型与函数定义必须相同。
函数原型的形参表的类型与顺序必须与函数定义相同,但是函数原型可以不写形参名称,即便写了形参名称也可以和原函数不一样。
空形参
- C语言中:
int func();// 表示可以有很多个参数int func(void);// 表示没有参数 - C++中,上述两行代码等价,且都表示没有参数。
- C语言中:
- 在函数被调用之前必须先有函数原型,函数定义可以放在调用函数的后面。
1 2 3
int func(); // 必须在调用函数的前面 int main() { int ret = func(); } int func() { return 0; } //可以在调用函数的后面
- 函数原型描述了函数接口,即函数如何与程序的其他部分交互。参数列表指出了何种信息将被传递给函数,函数类型指出了返回值的类型。
extern的主要作用是什么?
- 置于变量或者函数前: 表明该变量或者函数定义在别的文件中。(外部链接)
- 在变量或者函数之前加上
extern关键字表明这是一个声明, 其定义可能在其他文件处, 注意不能对变量进行初始化或者对函数进行定义, 否则表明这是一个定义而不是声明.
- 在变量或者函数之前加上
- extern”C”`: 让编译器以 C 语言的命名规则来查找函数
- extern “C”的主要作用就是为了能够正确实现C++代码调用其他C语言代码。加上extern “C”后,会指示编译器这部分代码按C语言的进行编译,而不是C++的。由于C++支持函数重载,因此编译器编译函数的过程中会将函数的参数类型也加到编译后的代码中,而不仅仅是函数名;而C语言并不支持函数重载,因此编译C语言代码的函数时不会带上函数的参数类型,一般只包括函数名。
如何令 const 对象可以在多个文件中共享
默认情况下, const 对象仅在本文件内有效, 我们可以通过 extern 关键字来使得 const 对象在多个文件中共享.
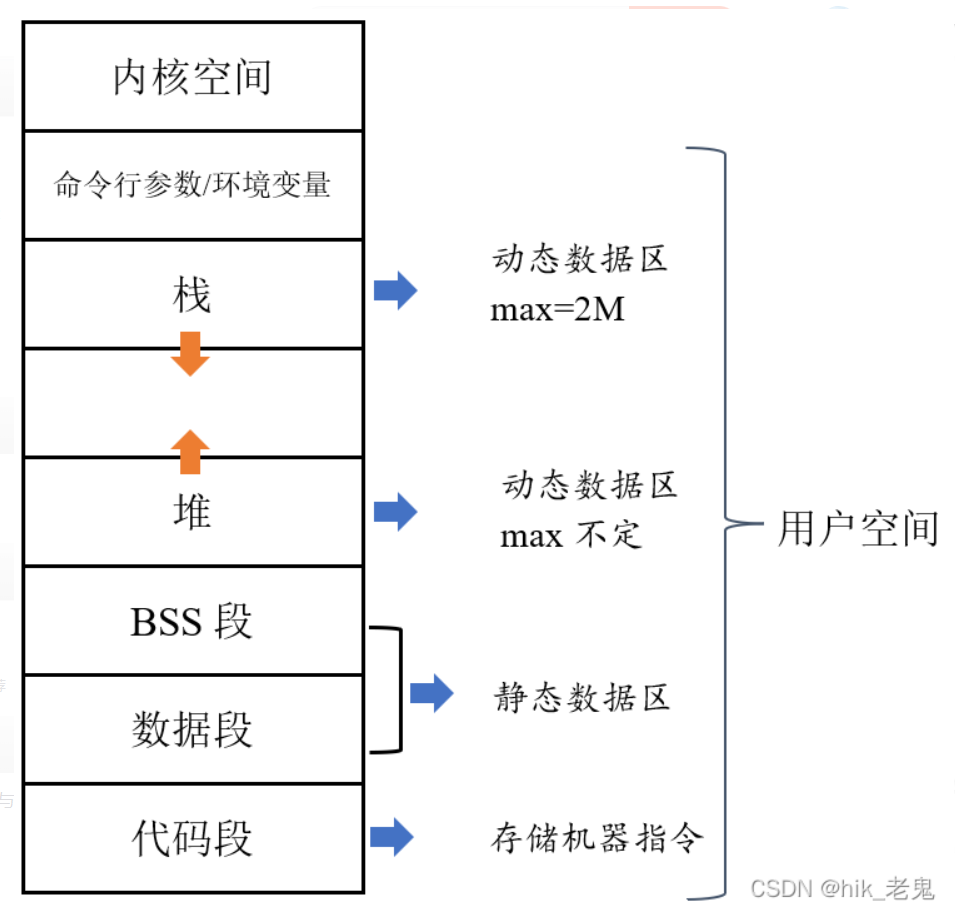
五(六)大内存区(代码段)
BSS段
(.bss):BSS段(bss segment)通常是指用来存放程序中未初始化的全局 和 静态变量 和 初始化为零值的全局 和 静态变量的一块内存区域。在程序开始时通常会被清零。BSS是英文Block Started by Symbol的简称。BSS段属于静态内存分配。- bss段不占用实际磁盘空间。只在段表中记录大小,在符号表中记录符号。当文件加载运行时,才分配空间以及初始化。
- 数据段
(.data):数据段(data segment)通常是指用来存放程序中已初始化为非零值的全局变量或者静态(全局)变量,全局常量数据的一块内存区域。数据段属于静态内存分配。[局部常量储存在栈段](.data)又可分为读写(RW)区域和只读(RO)区域。RO段保存常量所以也被称为.constdata虚函数表在这- 因为编译时可确定,且需要全局共享。
RW段则是普通非常量全局变量,静态变量就在其中
代码段
(.text):代码段(code segment/text segment)通常是指用来存放程序执行代码(汇编代码)的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。常量变量也有可能在不同的架构上被单独分出来。只要是函数,不管怎么样,统一都放在这里。(这里有一段代码帮助我们初始化BSS段的内容为0)这块内存是共享的,当有多个相同进程(Process)存在时,共用同一个text段。堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用
malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)低地址到高地址。堆里的数据可共享栈(stack):是用户存放程序临时创建的局部变量,存放函数调用相关的参数、局部变量的值,以及在任务切换的上下文信息。栈区是由操作系统分配和管理的区域。也就是说我们函数括弧
“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的后进先出的特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区。高地址到低地址。栈里放的都是局部变量,无法共享,函数结束时自动释放。这就是为什么全局和静态变量不在这里。[局部常量在这里]。栈属于静态内存分配内存映射段 (memory mapping segment ): 在栈的下面是内存映射段。在这里,内核将文件的内容直接映射到内存。任何应用程序都可以通过Linux的
mmap()系统调用或Windows中的CreateFileMapping()/MapViewOfFile()来进行这样的映射。内存映射是一种方便高效的文件I/O方式,所以它被用来加载动态库。还可以创建不对应任何文件的匿名内存映射,而是将其用于存放程序数据。在Linux中,如果使用malloc()申请一大块内存,C运行库将开辟一个这样的匿名映射,而不是开辟堆内存,这里的“大”意味着大于MMAP_THRESHOLD字节,默认为128 kb,可通过mallopt()调整。内存映射分为公有和私有,匿名和具名
私有映射 共享映射 特性 匿名映射 私有匿名映射 - 通常用于内存分配 共享匿名映射 - 通常用于(有关联)进程间通信 匿名映射没有对应的文件。这种映射的内存区域会被初始化成0。另一种看待匿名映射的角度(并且也接近于事实)是把它看成是一个内容总是被初始化为 0 的虚拟文件的映射。 文件映射 私有文件映射 - 通常用于加载动态库 共享文件映射 - 通常用于内存映射IO,(无关联)进程间通信。 内存映射区域有实体文件与之关联。mmap系统调用将普通文件的一部分内容直接映射到调用进程的虚拟地址空间。一旦完成映射,就可以通过在相应的内存区域中操作字节来访问文件内容。这种映射也被称为基于文件的映射。 - 私有匿名映射 (使用
mmap进行内存分配)- 当使用参数
fd=-1且flags=MAP_ANONYMOUS | MAP_PRIVATE时,创建的mmap映射是私有匿名映射。私有匿名映射最常见的用途是在 glibc 分配大块内存中,当需要的分配的内存大于MMAP_THREASHOLD(128KB)时,glibc会默认使用mmap代替brk来分配内存。
- 当使用参数
- 共享匿名映射 (父子进程间通信)
- 当使用参数
fd=-1且flags=MAP_ANONYMOUS | MAP_SHARED时,创建的mmap映射是共享匿名映射。共享匿名映射让相关进程共享一块内存区域,通常用于父子进程的之间通信。 - 创建共享匿名映射有如下两种方式:
fd=-1且flags= MAP_ANONYMOUS|MAP_SHARED。在这种情况下,do_mmap_pgoff()->mmap()函数最终调用shmem_zero_setup()来打开一个"/dev/zero"特殊的设备文件。- 直接打开
"/dev/zero"设备文件,然后使用这个文件描述符来创建mmap。
- 当使用参数
- 私有文件映射(加载动态链接库)
- 私有文件映射时 flags 的标志位被设置为
MAP_PRIVATE,那么就会创建私有文件映射。私有文件映射的最常用的场景是加载动态共享库。
- 私有文件映射时 flags 的标志位被设置为
- 共享文件映射 (读写文件,非亲属进程间通信)
- 创建文件映射时 flags 的标志位被设置为
MAP_SHARED,那么就会创建共享文件映射。如果prot参数指定了PROT_WRITE,那么打开文件需要制定O_RDWR标志位。 - 共享文件映射通常有如下场景:
- 读写文件:
- 把文件内容映射到进程地址空间,同时对映射的内容做了修改,内核的回写机制(writeback)最终会把修改的内容同步到磁盘中。
- 进程间通信:
- 进程之间的进程地址空间相互隔离,一个进程不能访问到另外一个进程的地址空间。如果多个进程都同时映射到一个相同的文件,就实现了多进程间的共享内存的通信。如果一个进程对映射内容做了修改,那么另外的进程是可以看到的。
- 读写文件:
- 创建文件映射时 flags 的标志位被设置为
栈的效率更高,因为栈是连续的,能更有效利用缓存。而且压栈和出栈都有对应机器指令。
https://blog.csdn.net/blunt1991/article/details/14005995
面试题:
基本变量存在哪里,创建类的对象时是存在堆上的吗?栈上能不能保存类对象,如果栈上能存,那类里的指针变量也是存在栈里的吗?
答:不用new创建类对象的时候在栈上。栈可以保存类对象。如果栈上能存,类里的指针变量本身也是在栈里面的。指向的数据如果是new出来的那就是在堆上
几种存储类型在内存中,分别被分配在哪一段存储空间。
auto存储类型:auto只能用来标识局部变量的存储类型,对于局部变量,auto是默认的存储类型,不需要显示的指定。因此,auto标识的变量存储在栈区中。extern存储类型:extern用来声明在当前文件中引用在当前项目中的其它文件中定义的全局变量。- 如果全局变量未被初始化,那么将被存在BBS区中,且在编译时,自动将其值赋值为0
- 如果已经被初始化,那么就被存在数据区中。
register存储类型:声明为register的变量在由内存调入到CPU寄存器后,则常驻在CPU的寄存器中,因此访问register变量将在很大程度上提高效率,因为省去了变量由内存调入到寄存器过程中的好几个指令周期。在C++中,例如while(i--){};对变量i有频繁的操作,编译器会将其存储在寄存器中。static存储类型:被声明为静态类型的变量,无论是全局的还是局部的,都存储在数据区中,其生命周期为整个程序- 如果是静态局部变量,其作用域为一对
{}内。 - 如果是静态全局变量,其作用域为当前文件。
- 静态变量如果没有被初始化,则自动初始化为0。静态变量只能够初始化一次。
- 如果是静态局部变量,其作用域为一对
- 字符串常量:字符串常量存储在数据区中,其生存期为整个程序运行时间,但作用域为当前文件。
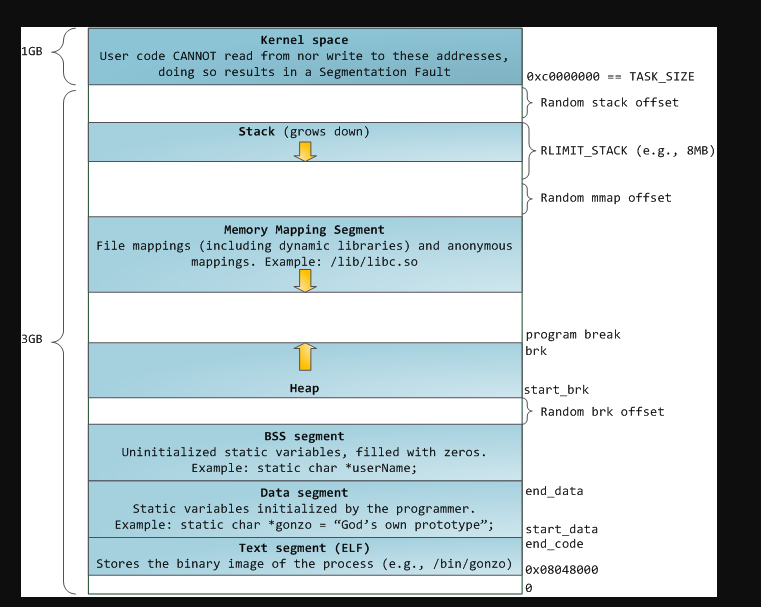
不同的段会被分配到不同的页面,不同的页面会有不同的读写或执行权限
常量区进一步解释和常量折叠
c++ 中,一个 const 不是必需创建内存空间,而在 c 中,一个 const 总是需要一块内存空间。
常量分为全局常量和局部常量
- 全局常量:
- 是否要为
const全局变量 分配内存空间,取决于这个全局常量的用途,如果是充当着一个值替换(将一个变量名替换为一个值),那么就不分配内存空间,不过当对这个全局常量取地址或者使用extern时,会分配内存,存储在只读数据段,是不能修改的。因为全局变量在内存中的位置与全局常量一样,只不过没有 read only 属性,因此在这里也就一并提了,全局常量同样被分配到数据段上,但是可以修改。
- 是否要为
1
2
const int a = 10;
int arr[a]; //这里的a就不分配内存,因为只是充当值替换。
PS:未初始化 或 初始化为0 的全局变量(包括全局常量)被分配在 .bss 段上,已初始化 的被分配在 数据段 上。
- 局部常量
- 对于基础数据类型,也就是
const int a = 10这种,编译器会把它放到符号表中,不分配内存,当对其取地址时,会在栈段分配内存。 - 对于基础数据类型,如果用一个变量初始化 局部常量,如果
const int a = b,那么也是会给a在栈段分配内存。 - 对于自定数据类型,比如类对象,那么也会在栈段分配内存。
- 对于基础数据类型,也就是
常量折叠
https://www.cnblogs.com/stemon/p/4406824.html
1
2
3
4
5
6
7
8
9
#define PI 3.14
int main()
{
const int r = 10;
int p = PI;//这里在预编译阶段产生宏替换,PI直接替换为3.14,其实就是int p = 3.14
int len = 2 * r;//这里会发生常量折叠,也就是说常量r的引用会替换成它对应的值,相当于int len = 2 * 10;
return 0;
}
- 如上述代码中所述,常量折叠表面上的效果和宏替换是一样的,只是,“效果上是一样的”,而两者真正的区别在于,宏是字符常量,在预编译阶段的宏替换完成后,该宏名字会消失,所有对宏如PI的引用已经全部被替换为它所对应的值,编译器当然没有必要再维护这个符号。
- 而常量折叠发生的情况是,对常量的引用全部替换为该常量如r的值,但是,常量名r并不会消失,编译器会把他放入到符号表中,同时,如果后面有对其取地址,则会为该变量分配空间,栈空间或者全局空间。既然放到了符号表中,就意味着可以找到这个变量的地址。如果只单纯的替换,则不需要分配空间。
符号表不是一张表,是一系列表的统称,这里的const常量,会把这个常量的名字、类型、内存地址、值都放到常量表中。符号表还有一个变量表,这个表放变量的名字、类型、内存地址,但是没有放变量的值。
常量折叠说的是,在编译阶段,对该变量进行值替换,同时,如果后面有对其取地址,则该常量拥有自己的内存空间,并非像宏定义一样不分配空间。但是如果只单纯的替换,则不需要分配空间。
口诀
- 内核权限高,所以是高地址部分(3-4)。用户权限低,所以是低地址部分(0-3)
- 栈是系统给的,内核是高地址所以栈也是高地址,高—>低
- 堆是程序员在代码写的,所以是贴着代码段。因为代码是第一个要有的东西,所以代码段在低地址也就是最开始。所以堆贴着代码这块所以是低地址,低->高
指针指向的数据不一定在堆上,也可能在栈上。需要看指向的对象是不是new出来的
1
2
3
int a = 10;
int* aptr = &a; //这时候指针指向的数据在栈上
int* bptr = new int(10); //这时候指针指向的数据在堆上
栈的大小 此处是用户栈
windows进程栈一般是1MB
Linux进程栈一般是8MB
我们上面那张图的一整个方框是一个进程地址空间。里面的栈就是进程的栈大小。是动态调整(推指针)的但是最大是8MB。
线程因为属于进程,所以线程栈是在进程地址空间的堆和栈中间的mmap内存映射段(因为比较大所以调用mmap函数后从mmap段拿出来)拿出来的。但是线程栈一旦创建之后大小就不能变了。很好理解,因为mmap调用的时候需要确定大小,调用之后内存空间固定,不能动态扩缩容。
又因为是线程栈是从进程栈拿出来的,所以线程栈的大小和进程栈是有联系的。
进程和线程的栈分别是多大呢?首先从我们熟悉的ulimit -s说起,熟悉linux的人都应该知道通过ulimit -s可以修改栈的大小,除此之外还有getrlimit/setrlimit两个函数:
1
2
3
int getrlimit(int resource, struct rlimit *rlim);
int setrlimit(int resource, const struct rlimit *rlim);
这两个函数当第一个参数传入RLIMIT_STACK时,可以设置和获取栈的大小,其作用和ulimit -s是一样的,只是单位不同,ulimit -s的单位是kB,而这两个函数的单位是B(字节),详细使用方法请参考man手册。 最后还有线程的pthread_attr_setstacksize/pthread_attr_getstacksize。 使用setrlimit和使用ulimit -s设置栈大小效果相同,这两种方式都是针对进程栈大小设置,只不过前者只真对当前进程,后者针对当前shell; 而线程栈大小的关系就相对比较复杂点,前文说过线程大小是静态的,是在创建时就确定了的,当然如果使用pthread_attr_setstacksize可以在创建线程时指定线程栈大小,但如果不指定线程栈的话其默认大小是什么情况呢?想要了解线程栈的大小就要看glibc的线程创建函数,具体就是pthread_create->__pthread_create_2_1->allocate_stack。具体代码还是比较复杂的,这里简化为一个伪代码:
1
2
3
4
5
6
7
8
limit = getlimit(RLIMIT_STACK)
if (limit == RLIMIT_INFINITY)
thread.rlimit = ARCH_STACK_DEFAULT_SIZE //2M
else if thread.rlimit < PTHREAD_STACK_MIN //16k
thread.rlimit = PTHREAD_STACK_MIN
可以看出,线程默认栈大小和进程栈大小的关系:
- 如果ulimit(setrlimit)设置大小大于16k,则线程栈默认大小由ulimit(setrlimit)决定;
- 如果ulimit(setrlimit)设置大小小于16k,则线程栈默认大小为16;
- 如果ulimit(setrlimit)设置大小为无限制,则线程栈默认大小为2M;
所以我们如果使用ulimit设置进程栈大小是无限大其实栈大小反而相对比较小,这是为什么呢?前面我们已经讲过线程栈和进程栈的位置不同,线程栈是进程使用mmap开辟出来的。,并且不会动态增加,所以不可能设置一个无限大小的线程栈。