存储类说明符
这是一个被我忽视了的细节。在官方文档中提到了:
auto或 (C++11 前)无说明符 - 自动存储期。- 这类对象的存储在外围代码块开始时分配,并在结束时解分配。未声明为
static、extern或thread_local的所有局部对象均拥有此存储期。
- 这类对象的存储在外围代码块开始时分配,并在结束时解分配。未声明为
register- 自动存储期,另提示编译器将此对象置于处理器的寄存器。(弃用) (C++17 前)static- 静态或线程存储期和内部链接。extern- 静态或线程存储期和外部链接。thread_local- 线程存储期。 (C++11 起)mutable- 不影响存储期或链接。解释见 const/volatile。
static, extern 和 thread_local 不必多说,这里主要关注第一个自动储存期。
什么是自动储存期?
我们知道,变量一般存在下面地方。
全局变量和静态变量:储存在静态存储区(比如BSS段和数据段)
常量:依赖于实现和上下文。一般来说,全局常量存储在静态储存区的数据段或代码段。局部常量储存在栈段。
局部变量:栈区。储存在动态存储区
new的变量:堆区。储存在动态存储区
但是注意,当有如下代码
1
2
3
4
int main(){
int* ptr = new int(5);
return 0;
}
ptr本身没有加储存类说明符,说明是自动存储期。我们查看上下文发现是在局部的变量。所以指针ptr自己在栈区。而new出来的东西在堆区。也就是栈上的指针指向了堆区的数据。
自动储存期指的是变量分配在哪是依靠上下文决定的。它并不一定在栈上。
举例子:
1
2
3
4
int main(){
Object obj; //什么意思?
return 0;
}
- 要回答这个问题,我们首先要理解这个语句是什么意思。这行语句的含义是,使对象
obj具有自动储存期的性质。所谓自动储存期,意思是这个对象的存储位置取决于其声明所在的上下文。
此时我们看到,这个语句出现在函数内部并且没有其他修饰符,那么它就在栈上创建对象。
如果这个语句不是在函数内部,而是作为一个类的成员变量,则取决于这个类的对象是如何分配的。考虑下面的代码:
1
2
3
4
5
6
7
8
class myClass{
public:
Object obj; //它在哪?
};
int main(){
myClass* ptr = new myClass;
return 0;
}
- 指针
ptr所指向的对象在堆上分配空间。但是因为Object obj;语句的含义是“变量具有自动存储期”。我们查看其上下文,发现包含ptr->obj的变量处于堆上。所以,ptr->obj也是在堆上创建的。
我们继续看下面的:
1
2
3
4
5
int main(){
Object *ptr;
ptr = new Object;
return 0;
}
Object *ptr;代表,指针ptr是自动存储的。查看上下文发现是在函数内部,所以ptr是栈上创建的。而下面一行语句则指出,这个指针所指向的对象是在堆上面分配的。如果这两行语句出现在一个函数内部,意味着当函数结束时,ptr会被销毁,但是它指向的对象不会。因此,如果不对指向的资源进行释放,会造成内存泄漏。因为那时堆上的这个地址的资源会变为不可达。
继续看下面的:
1
2
3
4
5
int main(){
Object obj;
Object* ptr = &obj;
return 0;
}
- 这里我们发现,
obj是自动储存期并且在栈上。ptr也是自动储存期,也在栈上。所以这个指针指向的对象也在栈上。所以不对其处理也不会导致泄漏问题。因为都是栈上的资源。
可重入函数 和 不可重入函数
在实时系统的设计中,经常会出现多个任务调用同一个函数的情况。如果有一个函数不幸被设计成为这样:不同任务调用这个函数时可能修改其他任务调用这个函数的数据,从而导致不可预料的后果。这样的函数是不安全的函数,也叫不可重入函数。
相反,肯定有一个安全的函数,这个安全的函数又叫可重入函数。那么什么是可重入函数呢?所谓可重入是指一个可以被多个任务调用的过程,任务在调用时不必担心数据是否会出错。
- 一个可重入的函数简单来说就是可以被中断的函数,也就是说,可以在这个函数执行的任何时刻中断它,转入OS调度下去执行另外一段代码,而返回控制时不会出现什么错误;而不可重入的函数由于使用了一些系统资源,比如全局变量区,中断向量表等,所以它如果被中断的话,可能会出现问题,这类函数是不能运行在多任务环境下的。
也可这样理解,重入即表示重复进入,首先它意味着这个函数可以被中断,其次意味着它除了使用自己栈上的变量以外不依赖于任何环境(包括 static),这样的函数就是purecode(纯代码)可重入,可以允许有该函数的多个副本在运行,由于它们使用的是分离的栈,所以不会互相干扰。如果确实需要访问全局变量(包括 static),一定要注意实施互斥手段。可重入函数在并行运行环境中非常重要,但是一般要为访问全局变量付出一些性能代价。
- 编写可重入函数时,若使用全局变量,则应通过关中断、信号量(即P、V操作)等手段对其加以保护。
例子:
假设 Exam 是 int 型全局变量,函数 Squre_Exam 返回 Exam 平方值。那么如下函数不具有可重入性。
1
2
3
4
5
6
7
8
int Exam = 0;
unsigned int example( int para )
{
unsigned int temp;
Exam = para; // (**)
temp = Square_Exam( );
return temp;
}
此函数若被多个进程调用的话,其结果可能是未知的,因为当(**)语句刚执行完后,另外一个使用本函数的进程可能正好被激活,那么当新激活的进程执行到此函数时,将使 Exam 赋与另一个不同的 para 值,所以当控制重新回到 temp = Square_Exam( ) 后,计算出的temp很可能不是预想中的结果。此函数应加锁。
1
2
3
4
5
6
7
8
9
10
int Exam = 0;
unsigned int example( int para )
{
unsigned int temp;
[申请信号量操作] //(1) 加锁
Exam = para;
temp = Square_Exam( );
[释放信号量操作] // 解锁
return temp;
}
可重入函数特点:
- 没有静态数据结构
- 不返回指向静态数据的指针
- 所有函数数据由函数的调用者提供
- 使用
auto变量,或通过全局变量的拷贝来保护全局变量 - 若必须访问全局变量,则利用互斥信号保护
- 不调用不可重入函数
- 在unix里面通常都有加上_r后缀的同名可重入函数版本。如果实在没有,不妨在可预见的发生错误的地方尝试加上保护锁同步机制等等
不可重入函数特点:
函数中使用了静态变量,无论是全局静态变量还是局部静态变量
- 函数返回静态变量
- 函数中调用了不可重入函数
- 如函数体内调用了
malloc()或者free()函数 或者printf()函数printf——–引用全局变量stdoutmalloc——–全局内存分配表free——–全局内存分配表
- 如函数体内调用了
- 函数体内调用了其他标准I/O函数
- 函数是singleton中的成员函数,而且使用了不属于线程独立存储的成员变量
满足下列条件的函数多数是不可重入(不安全)的:
函数体内使用了静态的数据结构;
函数体内调用了
malloc()或者free()函数;函数体内调用了标准 I/O 函数。
保证函数的可重入性的方法:
- 在写函数时候尽量使用局部变量(例如寄存器、堆栈中的变量);
- 对于要使用的全局变量要加以保护(如采取关中断、信号量等互斥方法),这样构成的函数就一定是一个可重入的函数。
可重入规则改写不可重入函数:
把一个不可重入函数变成可重入的唯一方法是用可重入规则来重写它。
可重入规则:
- 不要使用全局变量。如果必须使用记得用互斥信号量保护,因为别的代码很可能修改这些变量值
在和硬件发生交互的时候,切记执行类似
disinterrupt()之类的操作,就是关闭硬件中断。完成交互记得打开中断,在有些系列上,这叫做“进入/退出核心”或者用
OS_ENTER_KERNAL/ OS_EXIT_KERNAL来描述。- 不能调用任何不可重入的函数。
- 谨慎使用堆栈。最好先在使用前先
OS_ENTER_KERNAL。
总之,必须保证中断是安全的
委托构造函数
委托构造函数允许在同一个类中一个构造函数调用另外一个构造函数,可以在变量初始化时简化操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
class A {
public:
A(){}
A(int a):a_(a){}
A(int a, int b):a_(a), b_(b) {} // 好麻烦
A(int a, int b, int c): a_(a), b_(b), c_(c) {} // 好麻烦
int a_;
int b_;
int c_;
};
//下面是使用委托构造函数
class mod_A {
public:
mod_A(){}
mod_A(int a): a_(a) {
cout <<"1param" << endl;
}
mod_A(int a, int b) : mod_A(a) { //委托构造函数,注意使用后对其他成员不可再使用构造函数初始化列表初始化其他成员。
cout <<"2param" << endl;
b_ = b;
}
mod_A(int a, int b, int c) : mod_A(a, b) {
cout <<"3param" << endl;
c_ = c;
}
int a_;
int b_;
int c_;
};
int main(){
mod_A obj1(1);
mod_A obj2(1,2);
mod_A obj3(1,2,3);
return 0;
}
/*
obj1:
1param
obj2:
1param
2param
obj3:
1param
2param
3param
*/
注意。每一个构造函数函数体内的打印是必须等待构造函数初始化列表执行完毕后才能调用的。这个比较好理解。比如obj3为例。首先调用了第二个委派,然后调用第一个委派。第一个委派输出1param,然后执行完毕返回至第二个委派输出2param,然后执行完毕返回至第三个构造函数输出3param结束。
也可以逆序写:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
class mod_A {
public:
mod_A(){}
mod_A(int a): mod_A(a,0){ //委派到下面的
cout <<"1param" << endl;
}
mod_A(int a, int b):mod_A(a, b, 0){ //再委派到下面的
cout <<"2param" << endl;
}
mod_A(int a, int b, int c){
cout <<"3param" << endl;
a_ = a;
b_ = b;
c_ = c;
}
int a_;
int b_;
int c_;
};
int main(){
mod_A obj1(1);
mod_A obj2(1,2);
mod_A obj3(1,2,3);
}
/*
obj1:
3param
2param
1param
obj2:
3param
2param
obj3:
3param
*/
我们发现明明是正序调用但是为啥是逆序输出呢?也是因为在每一个构造函数函数体内的打印是必须等待构造函数初始化列表执行完毕后才能调用的。所以比如obj1为例,调用了第二个委派,然后调用第三个委派,输出3param,然后执行完毕返回至第二个委派输出2param,然后执行完毕返回至第一个委派输出param1
注意事项:
- 注意委托构造函数不能具有其他成员初始化表达式,成员初始化列表只能包含一个其它构造函数,不能再包含其它成员变量的初始化,且参数列表必须与构造函数匹配。也就是对其他成员不可使用构造函数初始化列表。我们不能在初始化列表中既初始化成员,又委托其他构造函数完成构造。
- 所以如果委托构造函数要给变量赋初值,初始化代码必须放在函数体中。如上面代码所示。
1
2
3
mod_A(){}
mod_A(int a): a_(a) {}
mod_A(int a, int b) : mod_A(a), b_(b) {} //错误。委托构造函数对其他成员不可使用构造函数初始化列表。
在构造函数较多的时候,我们可能拥有多个委托构造函数,而一些目标构造函数很可能也是委托构造函数,这样依赖,我们就可能在委托构造函数中形成链状的委托构造关系,形成委托坏(Delegation Cycle)。
如果在委托构造函数中使用try,可以捕获目标构造函数中抛出的异常。
继承构造函数
继承构造函数可以让派生类直接使用基类的构造函数,如果有一个派生类,我们希望派生类采用和基类一样的构造方式,可以直接使用基类的构造函数,而不是再重新写一遍构造函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class A {
public:
A(){}
A(int a): a_(a) {}
A(int a, int b) : A(a) { //委托构造
b_ = b;
}
A(int a, int b, int c) : A(a, b) { //委托构造
c_ = c;
}
int a_;
int b_;
int c_;
};
class B:public A{
public:
B() {}
B(int a) : A(a) {} // 好麻烦
B(int a, int b) : A(a, b) {} // 好麻烦
B(int a, int b, int c) : A(a, b, c) {} // 好麻烦
B(int a, int b, int c, int d) : A(a, b, c), d_(d) {} // 注意这不是委托构造,所以自己的成员可以放入初始化列表。
int d_;
};
//下面使用继承构造
class mod_B:public A{
public:
using A::A;
};
如果 using 声明指代了正在定义的类的某个直接基类的构造函数(例如 using Base::Base;),那么在初始化派生类时,该基类的所有构造函数(忽略成员访问)均对重载决议可见。
如果重载决议选择了继承的构造函数,那么如果它被用于构造相应基类的对象时可访问,它也是可访问的:引入它的 using 声明的可访问性被忽略。
如果在初始化这种派生类对象时重载决议选择了继承的构造函数之一,那么用这个继承的构造函数对从之继承该构造函数的
Base子对象进行初始化,而Derived的所有其他基类和成员,都如同以预置的默认构造函数一样进行初始化(如果提供默认成员初始化器就会使用它,否则进行默认初始化)。整个初始化被视作单个函数调用:继承的构造函数的各形参的初始化,按顺序早于派生类对象的任何基类或成员的初始化。
注意事项:
- 继承构造函数无法初始化派生类数据成员,继承构造函数的功能是初始化基类,对于派生类数据成员的初始化则无能为力。解决的办法主要有两个:
- 可以通过 =、{} 对非静态成员快速地就地初始化,以减少多个构造函数重复初始化变量的工作,注意初始化列表会覆盖就地初始化操作(这句话没有别的意思。就是如果一个元素既被就地初始化(如
int val = 10),又被置入初始化列表,则最后的元素的值会是初始化列表的值。非常直观好理解)。
1 2 3 4 5
class mod_B:public A{ public: using A::A; int _d = 10; };
- 新增派生类构造函数,使用构造函数初始化列表初始化
1 2 3 4 5 6
class mod_B:public A{ public: using A::A; mod_B(int a, int b, int c, int d): A(a, b, c), d_(d){} // 注意这不是委托构造,所以自己的成员可以放入初始化列表。 int d_; };
- 可以通过 =、{} 对非静态成员快速地就地初始化,以减少多个构造函数重复初始化变量的工作,注意初始化列表会覆盖就地初始化操作(这句话没有别的意思。就是如果一个元素既被就地初始化(如
- 构造函数拥有默认值会产生多个构造函数版本,且继承构造函数无法继承基类构造函数的默认参数,所以我们在使用有默认参数构造函数的基类时就必须要小心。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class A
{
public:
A(int a = 3, double b = 4):m_a(a), m_b(b){}
void display()
{
cout<<m_a<<" "<<m_b<<endl;
}
private:
int m_a;
double m_b;
};
class B:public A
{
public:
using A::A;
};
那么A中的构造函数会有下面几个版本:
1
2
3
4
A() //默认无参构造
A(int) //只输入一个值,第二个值采用默认值
A(int,double) //输入两个值,也就是忽视默认值
A(const A&) //拷贝构造。
那么B中对应的继承构造函数将会包含如下几个版本:
1
2
3
4
5
//同上
B()
B(int)
B(int,double)
B(const B&)
注意没有A(double) 或 B(double) 因为不可以第一个有默认值而第二个没有默认值。也就是从第一个有默认值后面的参数都必须有默认值。
- 多继承的情况下,继承构造函数会出现“冲突”的情况,因为多个基类中的部分构造函数可能导致派生类中的继承构造函数的函数名与参数相同,即函数签名。
=default 类的默认函数
我们有如下代码
1
2
3
4
5
6
7
8
9
10
11
12
13
class myobj{
public:
myobj() = default;
myobj(int a, int b){
cout <<"two" << endl;
}
};
int main(){
myobj(1,2);
myobj s; //注意这里
return 0;
}
如果此时我们只有第二个带参数的构造函数。如果我们执行一个新建一个对象但不提供参数,则编译器无法找到合适的构造函数。会报错。
只要我们有定义的构造函数,编译器无论如何都不会额外生成构造函数。
所以此时我们想执行myobj s应该怎么办?
- 要么手写一个空构造函数 如
1
myobj(){}
- 要么使用
=default。
1
myobj() = default;
- 如果使用default指示的办法,可以产出比用户定义的无参构造函数性能更优的代码(毕竟是编译器干活)
- 还有一个作用可以让使用者一眼就看出这是一个合成版本的构造函数(相当于知道类的作者没干其他事情)
在用户没有提供构造函数,析构函数,拷贝构造函数,拷贝赋值函数,移动构造函数和移动赋值函数这六大类特殊函数的时候,编译器会提供默认版本。如果某一个函数被实现,则该函数的默认版本将不复存在。
=default是函数定义
=delete 弃置函数
果使用特殊语法
= delete ;取代函数体,那么该函数被定义为弃置的(deleted)。任何弃置函数的使用都是非良构的(程序无法编译)。这包含调用,包括显式(以函数调用运算符)及隐式(对弃置的重载运算符、特殊成员函数、分配函数等的调用),构成指向弃置函数的指针或成员指针,甚至是在不潜在求值的表达式中使用弃置函数。但是可以隐式 ODR 使用刚好被弃置的非纯虚成员函数。如果函数被重载,那么首先进行重载决议,且只有在选择了弃置函数时程序才非良构
函数的弃置定义必须是翻译单元中的首条声明:已经声明过的函数不能声明为弃置的:
- 和
=default不同,=delete可以用于任何函数。
先说结论:=delete修饰的弃置函数会参与重载决议。因为弃置函数修饰的是定义,也就是指示定义被删除。而符号需要被保留,因为所有查找和重载解析都发生在删除的定义被记录之前。同时,另一个原因是符合语义规则。比如下面这个例子
1
2
3
4
5
6
struct onlydouble {
onlydouble(int) = delete;
onlydouble(double){
cout<<"called double" << endl;
}
};
假设delete的含义是完全删除函数,则上面等同于下面:
1
2
3
4
5
struct onlydouble {
onlydouble(double){
cout<<"called double" << endl;
}
};
随后,我们这样的调用是合法的
1
2
int a = 200;
onlydouble obj(a);
但是从语义角度来说,我们不希望这样做。我们希望不接受int为入参。
所以说=delete的含义只是删除了定义,并不删除声明。所以说我们按照第一个例子调用的话是不合法的。因为找到了完全匹配的函数,此时重载决议已经结束。但是函数被声明为=delete,等于发现了函数是弃置的,非良构。这时候编译器就会发出提示,报错。
- 归根结底:
=delete的意思是“禁止使用”而不是“这个不存在”- 可以把
=delete理解为=disable
- 可以把
就像我们调用了一个声明拷贝构造为delete的类的拷贝构造函数时,报错提示的是调用了delete的函数,而非未定义的标识符。
=delete是函数定义。
https://stackoverflow.com/questions/14085620/why-do-c11-deleted-functions-participate-in-overload-resolution
https://zh.cppreference.com/w/cpp/language/function#.E7.94.B1.E7.94.A8.E6.88.B7.E6.8F.90.E4.BE.9B.E7.9A.84.E5.87.BD.E6.95.B0
https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2007/n2346.htm#delete
用户提供的函数
如果一个函数由用户声明且没有在它的首个声明被显式预置或显式弃置,那么它由用户提供。由用户提供的显式预置的函数(即在它的首个声明后被显式预置)在它被显式预置的地方定义;如果该函数被隐式定义为弃置的,那么程序非良构。需要为不断变化的代码库提供稳定的二进制接口的情况下,在函数的首个声明后再定义为预置可以保证执行效率,也能提供简明的定义。
- 注意,是首个声明被显式预置或显式弃置的时候,不是由用户提供的。三个要点:首个,显式预置或弃置,这时候不是用户提供的。,所以说
=default和=delete修饰的函数不一定是不是由用户提供的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// trivial 的所有特殊成员函数都分别在它们的首个声明处被显式预置,因此它们都不由用户提供
struct trivial
{
trivial() = default;
trivial(const trivial&) = default;
trivial(trivial&&) = default;
trivial& operator=(const trivial&) = default;
trivial& operator=(trivial&&) = default;
~trivial() = default;
};
struct nontrivial
{
nontrivial(); // 首个声明,此处并没有在它的首个声明被显式预置或显式弃置。所以它是用户提供的。
};
// 没有在首个声明处被显式预置,
// 因此该函数由用户提供并在此定义
nontrivial::nontrivial() = default;
用户声明的函数
只要写了声明就是用户声明的函数
用户定义的函数
就是函数不仅有声明还有定义。但是没找到这个词汇的专业解释。
编译期和运行期的思考
- 类是编译期的概念,也是“访问权限”、“成员数据”、“成员函数”这几个概念的“作用域”。
- 意思就是非法访问的报错是编译期就会出现问题。
- 而对象的作用域是运行期。它包括类的实例、引用和指针。
- 所以我们说类对象的虚函数表指针是运行期确定的。因为编译期间不会给对象分配内存(new是运行期的东西,静态的数据是编译期)。
- 编译期是指把你的源程序交给编译器编译的过程,最终目的是得到obj文件,链接后生成可执行文件(预处理、编译、汇编和连接)。运行期指的是你将可执行文件交给操作系统(输入文件名,回车)执行、直到程序执行结束。执行的目的是为了实现程序的功能 。
- 编译时不分配内存
- 编译期分配的内存,就比如静态,全局变量,全局常量。这是在编译的时候确定的。编译时分配内存”是指“编译时赋初值”,它只是形成一个文本,检查无错误,但是它并没有分配内存空间,而是类似一个占位符的检查,比如看看你在的位置对吗,这个位置该你占位嘛。记住,此时只是根据声明时的类型进行占位,到以后程序执行时分配内存才会正确。所以声明是给编译器看的
- 编译期内存错误,就是比如某个数据段DATA段或者CODE段等等,超过跑这个程序的目标机的存储器的限制。
- 比如一个全局数组
int array[100];由于他被分配在.data/.bss部分,所以编译器在编译期间决定将要把数组分配在该静态内存区域的某个地址。(当然,内存地址是虚拟地址。该程序假定它拥有自己的整个内存空间(例如从 0x00000000 到 0xFFFFFFFF)。这就是为什么编译器可以做出诸如“好的,数组将位于地址 0x00A33211”之类的假设。在运行时,地址由 MMU 和操作系统转换为实际/硬件地址。)随后,直到程序被装入内存运行时,这里的内存才会被真正分配。所谓的静态分配只是预先计算好的意思。但依旧需要运行时才能将其分配。至于堆对象,更是需要等到运行时调用CRT帮助我们从OS中获取内存。
- 运行时必分配内存
- 运行期分配内存,一开始程序会初始化一些全局对象(给上面的占位符分配内存),然后找到入口函数。之后用
new啊malloc()之类的函数,在堆上分配内存。 - 运行期内存错误,就是运行的时候发生的,比如申请不到内存,内存越界访问,等等。
- 运行期分配内存,一开始程序会初始化一些全局对象(给上面的占位符分配内存),然后找到入口函数。之后用
- 关于数组不能使用非常量做为大小来声明。
1
2
3
4
5
6
7
int main(){
int a = 10;
const int b = 10;
int arr[a]; //不行
int arr[b]; //可以
return 0;
}
- 为啥?因为尽管我们提到过一些可以在编译时分配内存的对象。但是他们并不能在编译时计算。可以在编译时计算的只有常量表达式。所以普通全局变量在这里也不能用。
- 常量表达式和
constexpr较为复杂。比如字面值是常量表达式。用常量表达式初始化的const对象也是常量表达式。或使用constexpr指明可以编译时计算。 - 同时,如
const int b = 10;他是局部const所以存储在栈段。但由于他是常量表达式,所以并不为其在栈上分配内存。所有下面用到b的地方都会被直接替换为10[详细说就是放入符号表。然后替换值]。直到有地方对b取地址了,才会在栈上为其分配一块内存。
https://www.yisu.com/zixun/609652.html
constexpr和const区别
constexpr不强制编译器进行constexpr优化。或者我们说,不合法的constexpr无法通过编译。
- 相同点:
const和consexpr都是用来定义常量的 - 不同点:
const声明的常量,初始值引用的对象不一定是一个常量;constexpr声明的常量,初始值一定是常量表达式。- 也就是说:
const并未区分出编译期常量和运行期常量。但是constexpr限定了编译期常量。const修饰的对象虽然必须声明时初始化,但是如果这个值是编译时可以确定,则在编译时初始化。如果是运行时才能确定,则在运行时初始化。
- 也就是说,为了解决
const关键字的双重语义问题,保留了const表示“只读”的语义,而将“常量”的语义划分给了新添加的constexpr关键字。即凡是表达“只读”语义的场景都使用const,表达“常量”语义的场景都使用constexpr。
- 也就是说:
所以,从以上信息我们可以再详细说说二者的区别
声明对象时使用 constexpr 说明符则同时蕴含 const。声明函数或静态成员变量 (C++17 起)时使用 constexpr 说明符则同时蕴含 inline。如果一个函数或函数模板的某个声明拥有 constexpr 说明符,那么它的所有声明都必须含有该说明符。
格外注意!!!在C++11中,声明非静态成员函数为constexpr则也包含const
针对对象:
const将对象声明为常量。这意味着保证一旦初始化,该对象的值就不会改变,并且编译器可以利用这一事实进行优化。它还有助于防止程序员编写修改初始化后不打算修改的对象的代码。‘constexpr意思是该对象适合在标准中称为常量表达式的地方使用。但请注意,constexpr不是唯一实现这个目的的方法。- constexpr 变量必须满足下列要求:
- 它的类型必须是字面类型。
- 比如
const int a = 20。这个没有声明为constexpr也可以,因为它等同于constexpr因为是字面值。
- 比如
- 它必须立即被初始化。
它的初始化包括所有隐式转换、构造函数调用等的全表达式必须是常量表达式
- 这句话额外针对的是自定义类型。我们可以针对内置类型使用如这样的方式直接使用constexpr
1
constexpr int a = 200;
但是自定义类型不可以 如
1 2 3 4 5 6 7 8 9
class myclass{ public: int a; int b; myclass(int l, int r):a(l),b(r){}; }; int main(){ constexpr sss(2,3); //不可以 }
- 这句话的意思就是如果有任何隐式转换或函数调用,则这些函数都必须满足常量表达式要求。也就是一个constexpr则全部必须constexpr。只能用constexpr函数去初始化constexpr变量。这种函数足够简单,以使得编译时就可以计算其结果。
- 所以如果想要使用constexpr修饰自定义类型,则构造函数必须也为constexpr函数 如这样:
1 2 3 4 5 6 7 8 9 10 11
class myclass{ public: int a; int b; constexpr myclass(int l, int r):a(l),b(r){}; //必须也是constexpr }; int main(){ constexpr myclass obj(2,3); //可以了 return 0; }
- constexpr修饰指针有特殊要求。
- 一个constexpr指针的初始值必须是
nullptr或者0,或者是存储在某个固定地址中的对象- 固定地址的意思是必须是全局/静态变量
1 2 3 4 5 6 7
int s = 100; int main(){ int ss = 100; constexpr int* b = &s;// OK constexpr int* bb = &ss; //不行。这不是固定地址对象。 return 0; }
- constexpr只对指针有效,与指针所指的对象无关。
1 2 3 4 5 6 7 8
int s = 100; int main(){ constexpr int* b = &s; int* const bb = &s; //上面的等于这个。也就是常量指针。 int sss = 200; b = &sss;//不允许。 return 0; }
- 一个constexpr指针的初始值必须是
- 它的类型必须是字面类型。
针对函数:
可以理解为constexpr修饰的其实是函数返回值。所以必须要入参满足constexpr,返回值也要满足constexpr,计算也要满足constexpr
const只能用于非静态成员函数,不能用于一般函数。它保证成员函数不会修改任何非静态数据成员(可变数据成员除外,无论如何都可以修改)。杂记2中详细解释过。constexpr可以与成员函数和非成员函数以及构造函数一起使用。constexpr函数必须满足如下要求- 它必须非虚
- 它的函数体不能是函数 try 块
- 对于构造函数,该类必须无虚基类
- 它的返回类型(如果存在)和每个参数都必须是字面值类型
- C++14前有如下要求:
- 函数体必须被弃置或预置,或只含有下列内容:
- 空语句(仅分号)
static_assert声明- 不定义类或枚举的
typedef声明及别名声明 using声明using指令- 恰好一条
return语句,当函数不是构造函数时。- 注:三目运算符是OK的。
- 函数体必须被弃置或预置,或只含有下列内容:
- C++14后,20前有如下要求
- 函数体必须不含:
goto语句- 拥有除
case和default之外的带有标签的语句 try块asm声明- 不进行初始化的变量定义
- 非字面类型的变量定义
- 静态或线程存储期变量的定义
- 注意:是
=default;或=delete;的函数体均不含任何上述内容。
- 也就是说14之后可以有
if这样的语句。
- 函数体必须不含:
- constexpr 构造函数
- 函数体不是
=delete;的 constexpr 构造函数必须满足下列额外要求: - 对于类或结构体的构造函数,每个子对象和每个非变体非静态数据成员必须被初始化。
- 如果类是联合体式的类,那么对于它的每个非空匿名联合体成员,必须恰好有一个变体成员被初始化
- 对于非空联合体的构造函数,恰好有一个非静态数据成员被初始化
- 每个被选用于初始化非静态成员和基类的构造函数必须是 constexpr 构造函数。
这一堆的意思是要么构造函数不能含有函数体也就是用初始化列表,要么每一个成员必须有默认值
- 函数体不是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class myclass{
public:
int a = 2; //必须有默认值
int b = 3; //必须有默认值
constexpr myclass(int l, int r){
a = l;
b = r;
};
};
//要不然就这样,用初始化列表
class myclass{
public:
int a;
int b;
constexpr myclass(int l, int r):a(l),b(r){}; //初始化列表
};
constexpr 析构函数
- 析构函数不能是
constexpr的,但能在常量表达式中隐式调用平凡析构函数。
- 析构函数不能是
针对模板
- 但由于模板中类型的不确定性,因此模板函数实例化后的函数是否符合常量表达式函数的要求也是不确定的。
- 针对这种情况下,C++11 标准规定,如果 constexpr 修饰的模板函数实例化结果不满足常量表达式函数的要求,则 constexpr 会被自动忽略,即该函数就等同于一个普通函数。
- 对于 constexpr 函数模板和类模板的 constexpr 函数成员,必须至少有一个特化满足上述要求。其他特化仍被认为是 constexpr 的,尽管常量表达式中不能出现这种函数的调用。
https://stackoverflow.com/questions/14116003/whats-the-difference-between-constexpr-and-const
https://blog.csdn.net/wangmj_hdu/article/details/119516148
https://blog.csdn.net/qq_22660775/article/details/89336997
https://yuhao0102.github.io/2020/09/14/cpp%E4%B8%ADconstexpr%E4%BD%9C%E7%94%A8/
ODR使用
较为复杂。但是简而言之的说:
- 一个对象在它的值被读取(除非它是编译时常量)或写入,或取它的地址,或者被引用绑定时,这个对象被 ODR 使用。
- 使用“所引用的对象在编译期未知”的引用时,这个引用被 ODR 使用。
- 一个函数在被调用或取它的地址时,被 ODR 使用。
如果一个对象、引用或函数被 ODR 使用,那么程序中必须有它的定义;否则通常会有链接时错误。
1
2
3
4
5
6
7
8
9
10
class myclass {
public:
static constexpr int s = 10;
};
const int myclass::s; // 外部定义
int main() {
std::cout << myclass::s << std::endl; // 非ODR使用
std::cout << *&myclass::s << std::endl; // ODR使用 取地址然后解引用 必须有定义
}
static constexpr (C++14/17)
先看代码,还是上面的代码
1
2
3
4
5
6
7
8
9
class myclass {
public:
static constexpr int s = 10;
};
int main() {
std::cout << myclass::s << std::endl; // 非ODR使用
std::cout << *&myclass::s << std::endl; // ODR使用 没有类外定义所以有未定义符号错误
}
如果 const 非 inline (C++17 起)静态数据成员或 constexpr 静态数据成员 (C++11 起)(C++17 前)被 ODR 使用,那么仍然需要命名空间作用域的定义,但它不能有初始化器。
由于constexpr从C++17开始变成了默认inline,所以可以不需要类外再次定义,可以编译通过
为什么inline之后就可以编译通过了?首先,因为类内静态数据成员的声明不是定义!!来自标准文档
所以通常静态数据成员需要类外定义。inline因为定义逐渐从优化变成了允许多次定义,可能导致违反ODR原则。所以C++17的时候,静态成员的类内初始化需要显式的inline。定义是为了给静态数据成员一个内存位置。从 C++17 开始,当你声明一个 inline 变量,包括静态数据成员,它会具有外部链接,但它可以在程序中的任何地方出现多次(正如 inline 函数)。编译器和链接器保证所有的定义都是相同的,并且在整个程序中只存在一个实例。
在技术层面上,当一个变量被声明为 inline 时,它告诉编译器和链接器允许变量在不同的编译单元(源文件)中多次定义,只要所有的定义都是相同的。此后,在链接阶段,不论这个变量在多少个编译单元中有定义,都会被视为同一个变量。这样就确保了即使对于 ODR 使用场景(例如取地址),也不会产生未定义符号错误,因为链接器能够正确地将所有引用解析到单一的定义上。
https://stackoverflow.com/questions/46874055/why-is-inline-required-on-static-inline-variables
https://stackoverflow.com/questions/65222905/undefined-reference-error-to-static-constexpr-data-member
https://stackoverflow.com/questions/77764243/undefined-symbol-when-initializing-a-static-constexpr-home-made-string-variable
友元
之前一直懒得写,这次抽时间整理一下
友元可以是函数,也可以是类。友元核心意义是,我不属于你,但我成为了你。
- 也就是这个类的友元函数或者友元类可以像这个类的成员一样访问这个类的私有属性。
友元函数
- 友元函数是可以直接访问类的私有成员的非成员函数。它是定义在类外的普通函数,它不属于任何类,但需要在类的定义中加以声明,声明时只需在友元的名称前加上关键字
friend - 友元函数必须在类内声明。但是可以在类内或类外定义
- 友元函数和运算符重载参见杂记2
友元类
- 友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)
1
2
3
4
class A{
public:
friend class B;
};
- 经过以上说明后,类 B 的所有成员函数都是类 A 的友元函数,能存取类 A 的私有成员和保护成员。
友元声明以关键字 friend 开始,它只能出现在类定义中。因为友元不是授权类的成员,所以它不受其所在类的声明区域 public private 和 protected 的影响。通常我们选择把所有友元声明组织在一起并放在类头之后
友元不是类成员,但是它可以访问类中的私有成员。友元的作用在于提高程序的运行效率,但是,它破坏了类的封装性和隐藏性,使得非成员函数可以访问类的私有成员。不过,类的访问权限确实在某些应用场合显得有些呆板,从而容忍了友元这一特别语法现象
注意要点:
- 友元关系不能被继承。
- 友元关系是单向的,不具有交换性。若类 B 是类 A 的友元,类 A 不一定是类B的友元,要看在类中是否有相应的声明。
- 友元关系不具有传递性。若类 B 是类 A 的友元,类 C 是 B 的友元,类 C 不一定是 类 A 的友元,同样要看类中是否有相应的声明。也就是朋友的朋友也是朋友这句话在友元里不成立。
使用 ifdef 条件编译
- 在编译中使用
-D可以指定宏定义。- 在这里如果使用
g++ 12.15.cpp -DTEST1 -o 12.15则会定义TEST1宏,所以会编译上面的部分。最终输出10。否则会编译下面的部分,输出10.234
- 在这里如果使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#ifdef TEST1
#define mymacro int
#else
#define mymacro double
#endif
int main()
{
mymacro a = 10.234;
cout << a << endl;
return 0;
}
main函数前后和CRT
操作系统创建进程后,把控制权交给程序的入口函数
(gcc –e (_startEntryPoint)), 这个函数往往是运行时库的某个入口函数。glibc的入口函数是_start,msvc(vc6.0)是mainCRTStartup- 入口函数对运行库和程序运行环境进行初始化,包括堆,I/O,线程,全局变量构造(constructor)等。
- 调用MAIN函数,正式开始执行程序主体。
- 执行MAIN完毕,返回入口函数,进行清理工作,包括全局变量析构,堆销毁,关闭I/O等,然后进行系统调用结束进程
程序执行前装载器会把用户的参数和环境变量压入栈而不是放入寄存器。接着操作系统把控制权交给入口函数。
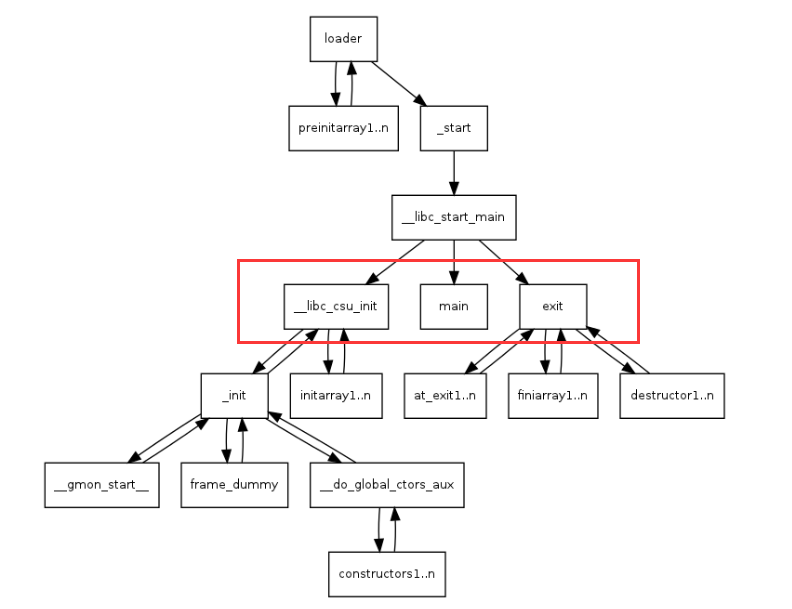
入口函数
_start中调用了_libc_start_main函数,_libc_start_main函数接受如下(仅列出一部分,更多的可以看高级C/C++编译技术3.4.2)传入参数:_libc_csu_init函数指针,__libc_csu_fini函数指针和rtld_fini函数指针下面是
__libc_start_main的部分细节。在
__libc_start_main中,我们会调用我们所谓的主函数main。但是在这之前还有许多工作要做。- 在我们调用
__libc_start_main函数之前,所有的参数如参数,环境变量等(argc,argv,envp)都要被准备好,并且传递给它。这些参数就是我们之前提到的会被压入栈中。 - 具体格式参考 System V ABI 3.4.1
![image-20230520224259609]()
__libc_csu_init函数是在main函数调用前调用的函数,全局和静态对象的构造函数就是在这个过程被执行的- 它会调用下面我们说的
_init()函数
- 它会调用下面我们说的
- 将
__libc_csu_fini通过__cxa_exit()注册到退出链表中 - 调用
main函数 __libc_csu_fini函数是在main调用后调用的函数,全局对象的析构就是在这个过程被执行的。- 它会调用下面我们说的
_finit()函数
- 它会调用下面我们说的
- 在我们调用
用户的参数:对应
int main(int argc,char *argv[])环境变量:系统公用数据,系统搜索路径等等。
初始化和OS版本相关的全局变量
- 初始化堆,每个进程都有属于自己的堆。它是一次性从系统中申请一块比较大的虚拟空间(
malloc分配的是虚拟页面,直到写入时才会映射到物理页),以后在进程中由库的堆管理算法来维护这个堆。当堆不够用时再继续申请一块大的虚拟空间继续分配。 可见,并非程序每次malloc都会系统调用(API调用比较耗时,涉及到用户态到内核态的上下文切换),效率比较高。这里契合了我们说的两种内存分配方式(mmap和brk)- 堆相关操作:
HeapCreate:创建一个堆,最终会调用virtualAlloc()系统API函数去创建堆。HeapAlloc:malloc会调用该函数HeapFree:free会调用该函数HeapDestroy:摧毁一个堆
- 堆相关操作:
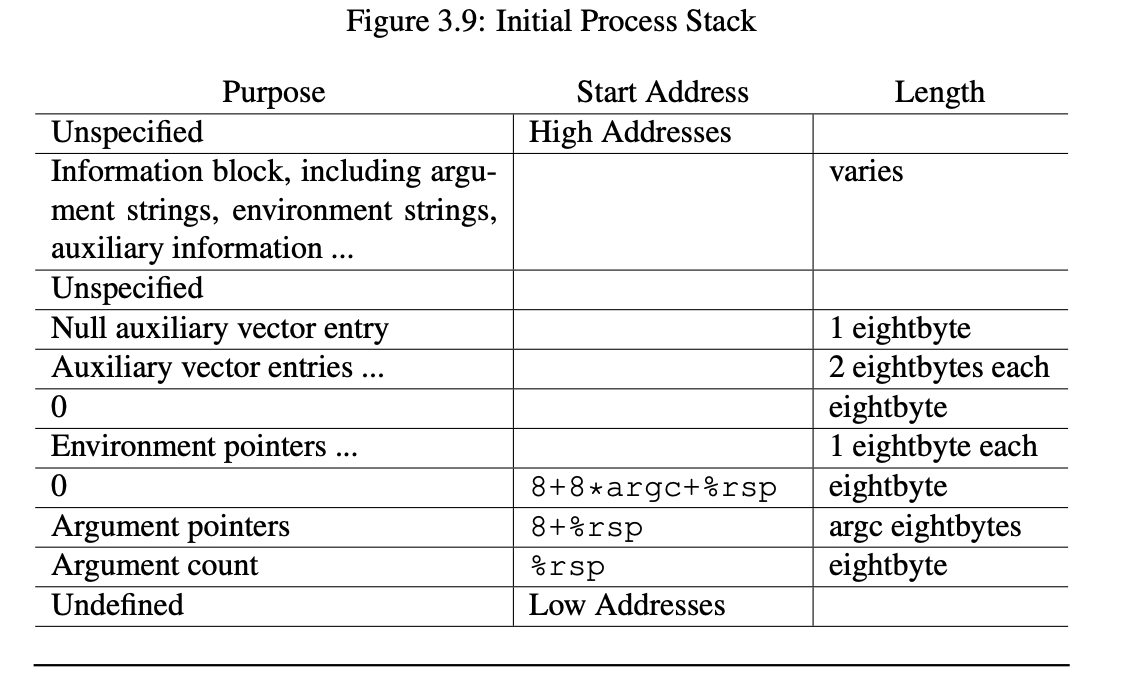
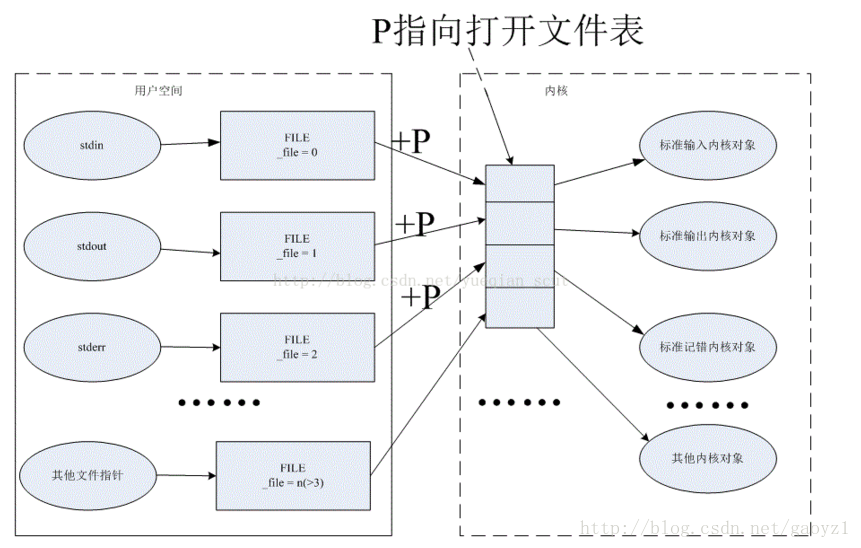
- I/O初始化,继承父进程打开文件表。可见,子进程是可以访问父进程打开的文件。如果父进程没有打开标准的输入输出,该进程会初始化标准输入输出。即初始化以下指针变量:
stdin,stdout,stderr.它们都是FILE类型指针。在linux和windows中,打开文件对应于操作一个内核对象,其处于内核态,因此用户态是不能直接操作该内核对象的。用户只能操作与内核对象相关联的FILE结构指针。对应关系是:
- 获取命令行参数和环境变量
- 初始化C库的一些数据
全局变量构造,如各个全局 类对象的构造函数调用和标记
__attribute__((constructor))属性的各个函数。它们都应该在进入main前进行调用。需要运行时库和C/C++编译器、链接器的配合才能实现这个功能。- 因为全局变量必须在main函数之前构造、必须在main函数之后析构,所以运行库在每个目标文件中引入了两个初始化相关的段
.init和.finit - 作为扩展,GCC 支持
__attribute__((constructor))可以使任意函数在main. 构造函数可以有一个可选的优先级__attribute__((constructor(N)))。- 从 0 到 100 的优先级保留用于实现(
-Wprio-ctor-dtor违反捕获),例如gcov使用__attribute__((destructor(100))). - 应用程序可以使用 101 到 65535。65535(
.init_array或.ctors,不带后缀)与 C++ 中非局部变量的动态初始化具有相同的优先级。
- 从 0 到 100 的优先级保留用于实现(
- 编译器编译某个
.cpp(翻译单元)时,会将所有的全局对象的构造函数指针作为一个整体放到.init段,把析构函数指针放到.finit段,然后在.ctors段放置.init段的地址(该地址即是该文件的各个构造函数的总入口)。- 最后我们会拥有两个函数
_init()和_finit()。这两个函数会先后于main函数执行 - 运行时库有一个库是
crtbegin.o,它使用-1定义了.ctors/.dtors,ctrend.o使用0定义了.ctors/.dtors。 - 用链接器进行连接:
ld crtbegin.o main.o crtend.o一定要按这种顺序,否则出错。链接后的.ELF文件是将以上各个翻译单元的.init/.finit/.ctors/.dtors等段分别合并。当然.data/.text段也会相应合并。
- 最后我们会拥有两个函数
- 对于每个编译单元(.cpp),GCC编译器会遍历其中所有的全局对象,生成两个特殊的函数,第一个特殊函数的作用就是调用本编译单元的所有全局对象的构造函数来对本编译单元里的所有全局对象进行初始化。第二个特殊函数的作用就是调用本编译单元的所有全局对象的析构函数来对本编译单元里的所有全局对象进行析构。它的调用顺序与调用构造函数的顺序刚好相反
- GCC在目标代码中生成了一个名为
_GLOBAL__I_Hw的函数,由这个函数负责本编译单元所有的全局/静态对象的构造和析构,它的代码可以表示为:
- GCC在目标代码中生成了一个名为
1 2 3 4 5 6
static void GLOBAL__I_Hw(void) { Hw::Hw(); // 构造对象 atexit(__tcf_1); // 一个神秘的函数叫做__tcf_1被注册到了exit //可能用的不是atexit,是__cxa_exit }
- 一旦一个目标文件里有这样的函数,编译器会在这个编译单元产生的目标文件(.o)的
.ctors段里放置一个指针,这个指针指向的便是GLOBAL__I_Hw。 - 全局变量构造时即是遍历
.ctors段的内容,从-1(crtbegin.o)开始,再到-1(crtend.o)结束,中间每四个字节即是各个翻译单元的构造入口函数指针,如果非0,即进行调用。- 在底层,在 ELF 平台上,初始化函数或构造函数以两种方案实现。旧版使用
.init/.ctors而新版使用.init_array.
![QQ截图20230101224120]()
![QQ截图20230101224127]()
为什么使用
.init_array和.fini_array- 开发人员注意到
.init/.ctors方案存在多个问题: - 碎片
_init化的功能丑陋且容易出错。.ctors里面的-1和0很难看。
.init并.ctors使用magic name而不是有意义的名字。- 所以
.init_array里面就是各个全局对象构造函数的函数指针。等于遍历数组即可而不用遍历段了。
- 在底层,在 ELF 平台上,初始化函数或构造函数以两种方案实现。旧版使用
- 因为全局变量必须在main函数之前构造、必须在main函数之后析构,所以运行库在每个目标文件中引入了两个初始化相关的段
注册析构函数
- 为了支持C++类的析构函数,和标记
attribute((deconstructor))属性的各个函数在main之后会被调用,而且是按构造的相反顺序进行调用,同样需要编译器和链接器以及运行时库的支持,原理跟构造相仿。只是为了逆序,使用了atexit()注册各个析构函数(上面提到过),注册时在链表头插入链接,main退出以后也从链表头开始获取链表函数,并进行调用。 - 我们上面提到了编译器生成的特殊函数。这个特殊函数大概这个样子
- 为了支持C++类的析构函数,和标记
1
2
3
4
5
6
7
static void __tcf_1(void) //这个名字由编译器生成
{
Hw.~Hw();
}
/*
这个函数负责析构Hw对象,由于在GLOBAL__I_Hw中我们通过atexit()注册了__tcf_1,而且通过atexit()注册的函数在进程退出时被调用的顺序满足先注册后调用的属性,与构造和析构的顺序完全符合,于是它就很自然被用于析构函数的实现了。
*/
执行函数主体。调用main函数执行,等待返回。在这里可以用到之前已经初始化的各种资源,如I/O, 堆申请释放等等
main函数返回后(局部变量在是在return后,exit前析构。因为_libc_start_main内部调用init,然后是main, 然后是exit。所以是main函数返回后,自然main里的局部变量全部出栈。exit函数进入前析构main的局部变量),调用exit函数。大概长这样1 2 3 4 5 6 7 8 9 10
void exit(int status) { while (__exit_funcs != NULL) { ... __exit_funcs = __exit_funcs->next; } ... _exit(status); }
__exit_funcs是存储由__cxa_atexit和atexit注册的(退出清理)函数的链表,这里的while循环遍历该链表并逐个调用这些注册的函数。可以明显看到,exit函数会在末尾调用_exit,这与OS描述“库函数exit内部调用系统调用_exit退出进程” 一致。而_exit实现由汇编实现,与平台相关。- 重申
__libc_csu_fini在退出链表中。
- 重申
- 释放堆
- 整个程序结束,那么分配给这个进程的所有资源都会被回收。堆空间自然不例外。这里哪管你用不用析构,连房子带地皮都给你扬了。所以不会内存泄漏。这里所谓的不会泄露并不是真的不泄漏,确实泄露了。但是,就算我没有delete,但是程序结束了。对系统无影响。
- 我们所说的内存泄漏是在程序的生命周期中发生的。比如我同样的程序变成了循环一万次,那么每一次new都不回收,这样就是内存泄露了。因为对我们有影响。
释放其他资源
- 调用
exit系统API退出进程
.init/.ctors/.init_array相关可以看这篇文章
atexit函数和__cxa_exit 函数
1
int atexit (void (*)(void))
atexit函数是一个特殊的函数,它是在正常程序退出时调用的函数,我们把他叫为登记函数
- 注意
atexit函数登记的函数必须是无参且无返回值的函数。也就是函数签名必须为void (*)(void)
⼀个进程可以登记多个终止处理函数,这些函数由exit⾃动调用, atexit函数可以登记这些函数。 exit调⽤终⽌处理函数的顺序和atexit登记的顺序相反(网上很多说造成顺序相反的原因是参数压栈造成的,参数的压栈是先进后出,和函数的栈帧相同),如果⼀个函数被多次登记,也会被多次调⽤。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void func1()
{
printf("The process is done...\n");
}
void func2()
{
printf("Clean up the processing\n");
}
void func3()
{
printf("Exit sucessful..\n");
}
int main(){
atexit(func1);
atexit(func2);
atexit(func3);
return 0;
}
/*
Exit sucessful..
Clean up the processing
The process is done...
*/
我们可以明显看到逆序输出。
atexit函数调用时机
以下函数的调用时程序异常或者正常终止:
- 进程终⽌的⽅式有8种,前5种为正常终⽌,后三种为异常终⽌:
- 从
main函数返回; - 调⽤
exit函数; - 调⽤
_exit或_Exit; - 最后⼀个线程从启动例程返回;
- 最后⼀个线程调⽤
pthread_exit; - 调⽤
abort函数; - 接到⼀个信号并终⽌;
- 最后⼀个线程对取消请求做出响应。
atexit函数和__cxa_atexit函数的区别
__cxa_atexit()不限于32个函数。__cxa_atexit()在程序退出前通过dlclose卸载动态库时,将调用动态库的静态析构函数。- 用户不应直接调用
__cxa_atexit()函数 - 当然了,一些标准库如glibc的
atexit直接使用了_cxa_atexit(1)
EXIT和return区别
EXIT
- 是系统层级的系统调用,指的是让进程退出。调用后会开始进行资源的清理和回收。
exit是一个函数
return
return是一个关键字,用于退出这个函数。(结束函数的执行)。也就是堆栈展开并销毁局部变量。
pthread_exit
1
noreturn void pthread_exit(void *retval);
所以使用pthread_exit可以维持子线程不退出的原因是,虽然主进程也是主线程,但是我只让主进程自己的线程退出,也就是不回收进程资源,相当于进程没有结束,子线程依旧可以执行。
使用
pthread_exit后,当进程中最后一个线程停止时(或有某个线程执行了exit(), abort()或终止函数时 (来自这里)), 整个进程通过调用exit而退出。所以,所有进程共享的资源会被释放。并且通过atexit注册的函数会被调用。来自这里- 有可能发生多个子线程中,主线程使用了
pthread_exit, 然后其中一个子线程可能在其他子线程结束之前调用了exit(),abort(),或其他终止函数。此时无论其他线程执行完毕与否,都会直接进行进程退出阶段。也就是如上面所说,所有进程共享的资源会被释放。并且通过atexit注册的函数会被调用。
- 有可能发生多个子线程中,主线程使用了
注意,
pthread_exit是有参数的。参数是个指针。这个参数的作用是可以把一些参数“塞到”这个指针中。相当于把一个调用pthread_exit函数的线程的返回值通过这个retval传出去。这样这个返回值可以被在同一个进程中的其他调用了pthread_join()的线程所使用。The
pthread_exit()function terminates the calling thread and returns a value viaretvalthat (if the thread is joinable) is available to another thread in the same process thatcallspthread_join(3).
exit与_exit 的区别
- 无论何时执行
return,都会析构局部变量,并弹栈。在main函数中执行return,会析构局部变量、弹栈,然后调用exit(包括了析构全局变量和local static变量的过程)。- 格外注意,
main中执行return会隐式调用exit
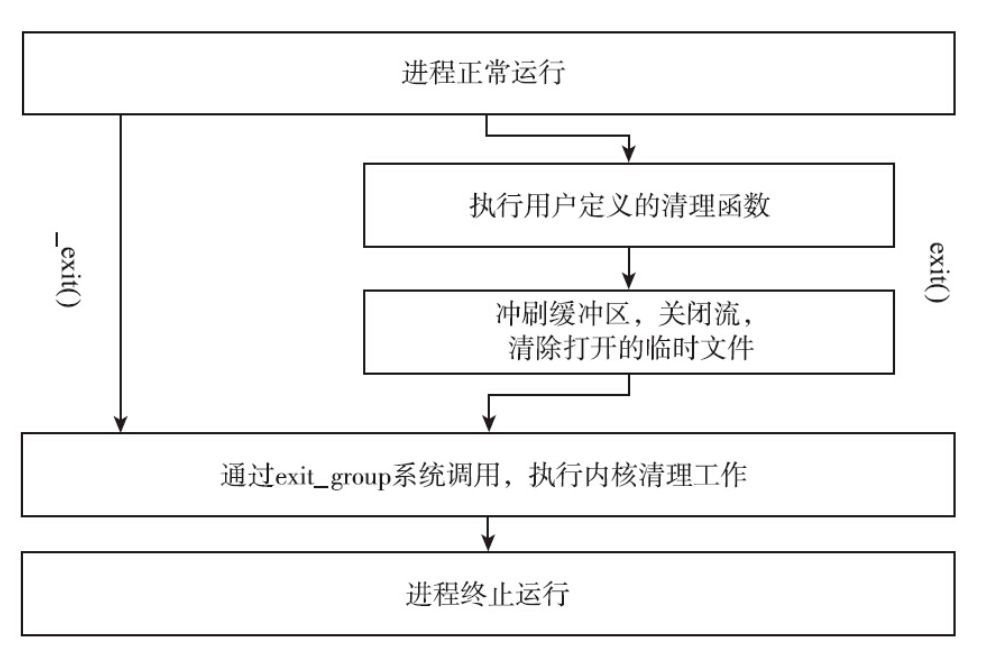
- 格外注意,
exit是C标准库的函数。_exit是系统调用。调用
exit时会析构全局变量和local static变量(不析构局部变量),刷新IO缓冲区,关闭文件描述符,调用atexit注册的函数(以注册时相反的顺序调用),但不弹栈。最后调用exit函数。直接调用
_exit不会析构任何变量,不会刷新IO缓冲区,不会执行任何通过atexit注册的函数,不弹栈,但会关闭文件描述符。- 因为系统调用非常暴力。直接把整个进程(状态机)直接给扬了
exit()和_exit()以及_Exit()函数的本质区别是一个是系统调用,一个是C库函数。也就是是否立即进入内核,_exit()以及_Exit()函数都是在调用后立即进入内核,而不会执行一些清理处理,但是exit()则会执行一些清理处理,这也是为什么会存在atexit()函数的原因,因为exit()函数需要执行清理处理,需要执行一系列的操作,这些终止处理函数实际上就是完成各种所谓的清除操作的实际执行体。_Exit()和_exit()相同。前者来自C99,后者来自POSIX
为什么 exit() 函数不是线程安全的?
主要原因 exit语义等同于从main 返回,会涉及到资源释放等相关流程,自然引入竞争问题
避免全局资源释放,使用quick_exit
另外直接列一下各种exit区别 https://learn.microsoft.com/en-us/previous-versions/6wdz5232(v=vs.140)
exit执行完整的 C 库终止过程,终止进程,并向主机环境提供提供的状态代码。_Exit执行最少的 C 库终止过程,终止进程,并向主机环境提供提供的状态代码。_exit执行最少的 C 库终止过程,终止进程,并向主机环境提供提供的状态代码。quick_exit执行快速 C 库终止过程,终止进程,并向主机环境提供提供的状态代码。_cexit执行完整的 C 库终止过程并返回给调用方。不终止进程。_c_exit执行最少的 C 库终止过程并返回给调用方。不终止进程。
例子和梳理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
void func(){
cout <<"start" << endl;
myobj a(20); //构建新对象
sleep(5); //睡眠5秒
cout << "end" << endl;
}
void func1()
{
printf("atexit registure func\n");
}
int main(){
atexit(func1); //注册退出时执行函数判断exit是否调用了
cout <<"main start" << endl;
thread th1(func); //新线程
th1.detach(); //使用detach
sleep(1);
cout <<"main end" << endl;
pthread_exit(NULL); //强制提前退出
return 0;
}
- 第一种情况,使用
join的时候,main主线程会等候子线程执行完毕,不多说。 - 第二种情况,使用
detach的时候,main主线程不会等候子线程执行完毕。由于已经分离,主线程无法取得子线程控制权。所以如果main主线程执行完毕,exit会被调用。这时候会强制停止整个进程。所以子线程并不一定能够执行完毕。 - 第三种情况,使用
pthread_exit。使用pthread_exit等于强制停止主线程。main在这种情况下,既是主进程又是主线程。所以使用pthread_exit等于退出了main主线程,但是进程还在,因为main结束后的exit没有被调用。此时由于exit没有被调用,所以会等候子线程执行完毕。使用pthread_exit后,在整个进程退出时,exit还是会被调用。等于此时main的exit被pthread_exit接管。原因在上面
参考资料
https://www.cnblogs.com/matex/articles/10807092.html
https://blog.csdn.net/yueqian_scut/article/details/24384941
https://blog.csdn.net/gaoyz1/article/details/78113069
https://zhuanlan.zhihu.com/p/430683541
https://www.youtube.com/watch?v=dOfucXtyEsU
https://kongkongk.github.io/2020/06/30/construction-and-destruction/
https://blog.csdn.net/qq_38600065/article/details/117370846
https://blog.csdn.net/pwl999/article/details/78219188
https://www.cnblogs.com/fortunely/p/15502849.html#111-%E5%85%A5%E5%8F%A3%E5%87%BD%E6%95%B0%E5%92%8C%E7%A8%8B%E5%BA%8F%E5%88%9D%E5%A7%8B%E5%8C%96
https://stackoverflow.com/questions/42912038/what-is-the-difference-between-cxa-atexit-and-atexit
https://blog.csdn.net/u012961585/article/details/103848484
http://originlee.com/2015/03/27/difference-between-return-and-exit-in-cxx/
https://luomuxiaoxiao.com/?p=516
https://blog.csdn.net/kongkongkkk/article/details/72861149
static_assert 静态断言 和 assert 动态断言
static_assert
static_assert静态断言,是C++关键字,作用是让编译器在编译时对常量表达时进行断言。如果通过,就不报错;如果不通过,就报错。
1
static_assert ( 布尔常量表达式 , 消息 )
- 编译器在遇到一个
static_assert语句时,通常立刻将其第一个参数作为常量表达式进行演算,但如果该常量表达式依赖于某些模板参数,则延迟到模板实例化时再进行演算,这就让检查模板参数成为了可能。 - 如果 布尔常量表达式 返回
true,那么该声明没有效果。否则将发布编译时错误,且当存在 消息时诊断消息中会包含其文本。
assert
assert是动态断言,是一个仿函数宏。assert是运行期的判断,并且会强制终止程序,一般要求只能用于debug版本中,是为了尽可能快的发现问题。assert是要从release版本中去掉。所以一般开发会重新定义assert宏。
- 动态断言会降低程序性能。增大运行时花费的空间和时间。
- 由于动态断言是运行期判断,所以如果断言不通过不影响编译。因为编译期不检查动态断言。
1
2
#include <assert.h>
void assert( int expression );
重复包含和前向声明 杂记3也有部分
- 在A.h头文件中包含B.h
在A.h头文件A类中声明一个B类的对象,可以是指针,也可以不是指针
- 在B.h头文件中用extern声明类A,然后在类B中声明一个A类的指针对象(必须是指针型)、
- 注意这个应用了前向声明的头文件不需要包含前向声明的类的头文件。
在A.cpp和B.cpp中都只需要包含A.h,B.cpp不需要包含B.h
- 然后在A.cpp和B.cpp中分别定义A类的对象和B类的对象。—可选
- 将它们的指针分别传给对方的对象。如果是在不同的文件,也可以是this传值,比如在A.cpp中,给B.cpp中的A类对象传递A的当前对象,b->a=this;然后B类中的a就可以调用A类的成员方法了。—-可选
- 最后就可以互相调用彼此的对象了。
- main里只包含A.h 因为A有完整的B。
- 个人理解,可以在头文件中使用前向声明,然后在源文件中include
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
//Project.h -----------A.h
#include <iostream>
#include <string>
#include <vector>
#include "Employee.h" //包含B.h (第一条)
using namespace std;
class Project{
public:
string name;
vector<Employee> peoples; //含有B的对象 (第二条)
Project() = default;
Project(const string& rhs):name(move(rhs)){};
void SetPeople(const Employee& people);
void printPeople();
};
//Employee.h -------- B.h
class Project; //前置声明A (第三条)这个文件使用了前向声明,前向声明的类的头文件不需要被当前文件包含。
class Employee{
public:
Project* m_proj; //包含A的指针 (第三条)
int ID;
Employee() = default;
Employee(int val):ID(val){};
void SetProj(Project* proj);
};
//Project.cpp ---------------A.cpp
#include "Project.h" //只包含 Project.h (第四条)
using namespace std;
void Project::SetPeople(const Employee& people){
peoples.emplace_back(people);
}
void Project::printPeople(){
for(auto& i:peoples){
cout << i.ID << endl;
}
}
//Employee.cpp ---------------B.cpp
#include "Project.h" //Employee.cpp 不包含 Employee.h 只包含 Project.h (第四条)
void Employee::SetProj(Project* proj){
m_proj = proj;
m_proj->SetPeople(*this);
}
//main.cpp
#include "Project.h" //只包含A.h即可(第八条)
using namespace std;
int main()
{
Project* myproj = new Project("first project");
Employee miku(1);
Employee luka(2);
miku.SetProj(myproj);
luka.SetProj(myproj);
myproj->printPeople();
delete myproj;
myproj = nullptr;
return 0;
}
std::type_info和type_id操作符
- 关于type_id操作符,如果当应用于多态类型的表达式时,typeid 表达式的求值可能涉及运行时开销(虚表查找),其他情况下 typeid 表达式都在编译时解决。
typeid操作符的返回结果是名为type_info的标准库类型的对象的const引用。C++并没有规定typeid实现标准,各个编译器可能实现方式不一样。
- 关于type_info对象,这个类的构造函数是private的,因此用户不能直接构造这样的对象,只能通过typeid()函数来获取这个对象。但是这个类对外提供了name(),operator==()等方法供用户使用
所以这样是不可以的
1
2
3
int a = 20;
type_info t1 = typeid(a);//错误
const type_info& t1 = typeid(a); //正确
有几个规则需要注意一下:
如果 类型 是引用类型,那么结果指代的
std::type_info对象表示被引用的类型的无 cv 限定版本- 如果 类型和 表达式 的类型具有 cv 限定,那么
typeid的结果会指代对应的无 cv 限定类型(即typeid(T) == typeid(const T))。- 如果是指针类型,这里表示忽略顶层CV,只保留底层CV。也就是不看指针本身,而是看指向的数据类型。
- 如果对处于构造和销毁过程中的对象(在构造函数或析构函数之内,包括构造函数的初始化器列表或默认成员初始化器)使用
typeid,那么此typeid指代的std::type_info对象表示正在构造或销毁的类,即便它不是最终派生类。- 很好理解。先构造父类,虚指针指向父类虚函数表,自然RTTI是父类。然后执行用户代码。然后构造子类,这时候虚指针才切换至子类,自然RTTI变为子类。然后执行用户代码。
- 在深入理解对象模型中我们反复强调:虚函数表指针的切换应该是在构造函数后,用户代码前。
先看一下基本类型的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
int main()
{
int a = 20;
const int b = 30;
int& c = a;
const int& d = a;
int* e = new int(5);
int* const f = new int(5);
const int* g = new int(6);
const int* const h = new int(6);
const type_info& t1 = typeid(a);
const type_info& t2 = typeid(b);
const type_info& t3 = typeid(c);
const type_info& t4 = typeid(d);
const type_info& t5 = typeid(e);
const type_info& t6 = typeid(f);
const type_info& t7 = typeid(g);
const type_info& t8 = typeid(h);
cout << t1.name() << endl; //int
cout << t2.name() << endl; //int
cout << t3.name() << endl; //int
cout << t4.name() << endl; //int
cout << t5.name() << endl; //int * __ptr64
cout << t6.name() << endl; //int * __ptr64
cout << t7.name() << endl; //int const * __ptr64
cout << t8.name() << endl; //int const * __ptr64
return 0;
}
- 我们看到。针对类型本身和引用是忽略CV限定的。
- 针对指针类型,只看其底层类型。也就是指针指向的数据类型。
- 无论指针本身是否是常量,如果指向的数据是常量则带
const。如果指向的数据不是常量则不带const
- 无论指针本身是否是常量,如果指向的数据是常量则带
看一看带多态的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
class Base {
public:
Base() {
}
virtual ~Base() {
}
virtual void func() {
}
};
class Derive :public Base {
public:
Derive() {
}
virtual ~Derive() {
}
virtual void func() {
}
};
int main()
{
Base b1;
Derive d1;
Base* bptr = new Base;
Derive* dptr = new Derive;
Base* p = new Derive;
const type_info& t1 = typeid(b1);
const type_info& t2 = typeid(d1);
const type_info& t3 = typeid(bptr);
const type_info& t4 = typeid(dptr);
const type_info& t5 = typeid(p);
const type_info& t6 = typeid(*bptr);
const type_info& t7 = typeid(*dptr);
const type_info& t8 = typeid(*p);
cout << t1.name() << endl; //class Base
cout << t2.name() << endl; //class Derive
cout << t3.name() << endl; //class Base * __ptr64
cout << t4.name() << endl; //class Derive * __ptr64
cout << t5.name() << endl; //class Base * __ptr64 注意这个
cout << t6.name() << endl; //class Base
cout << t7.name() << endl; //class Derive
cout << t8.name() << endl; //class Derive 注意这个
return 0;
}
首先注意必须有虚函数。虚函数是多态的必不可少的要求之一。也是因为RTTI信息在虚函数表内。
- 我们看到。针对多态的时候的
t3t4t5,类型依旧是对应的指针本身的类型。尤其是t5的类型依旧是父类指针类型。 - 我们如果想看指针真正指向的类型就需要对指针解引用。比如
t6t7t8。我们是对指针进行了解引用。所以这个时候尤其是t8可以看到其指向类型是子类。 - 注意:针对如果输入
typeid的参数多态类型的指针,而且是空指针并进行解引用,则会触发std::bad_typeid
异常
C++引入异常的原因是这样做可以让我们在构造函数中抛出异常。还有比如dynamic_cast传入引用时的报错。
析构函数不禁止但是极度不推荐抛出异常。原因见杂记2和effective c++条款08。
异常是一个非常难以掌握的特性。它的缺点是会增加开销(需要额外数据结构)和增加代码量。
基本语法:
1
2
3
4
5
try{
// 可能抛出异常的语句
}catch(exceptionType variable){
// 处理异常的语句
}
try和catch都是 C++ 中的关键字,后跟语句块,不能省略{ }。try 中包含可能会抛出异常的语句,一旦有异常抛出就会被后面的 catch 捕获。从 try 的意思可以看出,它只是“检测”语句块有没有异常,如果没有发生异常,它就“检测”不到。catch 是“抓住”的意思,用来捕获并处理 try 检测到的异常;如果 try 语句块没有检测到异常(没有异常抛出),那么就不会执行 catch 中的语句。
发生异常时必须将异常明确地抛出,try 才能检测到;如果不抛出来,即使有异常 try 也检测不到。所谓抛出异常,就是明确地告诉程序发生了什么错误。
- 异常一旦抛出,会立刻被 try 检测到,并且不会再执行异常点(异常发生位置)后面的语句。
- 检测到异常后程序的执行流会发生跳转,从异常点跳转到 catch 所在的位置,位于异常点之后的、并且在当前 try 块内的语句就都不会再执行了;即使 catch 语句成功地处理了错误,程序的执行流也不会再回退到异常点,所以这些语句永远都没有执行的机会了。
- 执行完 catch 块所包含的代码后,程序会继续执行 catch 块后面的代码,就恢复了正常的执行流。
throw关键字用来抛出一个异常,这个异常会被 try 检测到,进而被 catch 捕获。
throw和异常类型的介绍:
exceptionType是异常类型,它指明了当前的 catch 可以处理什么类型的异常;variable是一个变量,用来接收异常信息。当程序抛出异常时,会创建一份数据,这份数据包含了错误信息,程序员可以根据这些信息来判断到底出了什么问题,接下来怎么处理。
- 异常既然是一个对象,那么就应该有类型。C++ 规定,异常类型可以是
int、char、float、bool等基本类型,也可以是指针、数组、字符串、结构体、类等聚合类型。C++ 语言本身以及标准库中的函数抛出的异常,都是 exception 类或其子类的异常。也就是说,抛出异常时,会创建一个exception类或其子类的对象。 exceptionType variable和函数的形参非常类似,当异常发生后,会将异常数据传递给 variable 这个变量,这和函数传参的过程类似。当然,只有跟exceptionType类型匹配的异常数据才会被传递给variable,否则 catch 不会接收这份异常数据,也不会执行 catch 块中的语句。换句话说,catch 不会处理无法匹配的异常。- 我们可以将 catch 看做一个没有返回值的函数,当异常发生后 catch 会被调用,并且会接收实参(异常数据)。
- 但是 catch 和真正的函数调用又有区别:
- 真正的函数调用,形参和实参的类型必须要匹配,或者可以自动转换,否则在编译阶段就报错了。
- 而对于 catch,异常是在运行阶段产生的,它可以是任何类型,没法提前预测,所以不能在编译阶段判断类型是否正确,只能等到程序运行后,真的抛出异常了,再将异常类型和 catch 能处理的类型进行匹配,匹配成功的话就“调用”当前的 catch,否则就忽略当前的 catch。
- 调用函数时,程序的控制权最终还会返回到函数的调用处,但是当你抛出一个异常时,控制权永远不会回到抛出异常的地方。
- 异常对象其实是一个特殊对象。throw语句会依据异常抛出表达式来拷贝初始化(拷贝构造)异常对象。
- 这要求异常抛出表达式不能是一个不完全类型。并且可以进行拷贝初始化。这可能会调用右值表达式的移动构造函数。即使拷贝初始化选择了移动构造函数,从左值拷贝初始化仍必须为良式,且析构函数必须可访问
- 异常对象放在内存的特殊位置,该位置既不是栈也不是堆,在 window 上是放在线程信息块 TIB 中。或者是异常栈中。这个构造出来的新对象与本级的 try 所对应的 catch 语句进行类型匹配
- 由于异常对象在特殊位置,比如异常栈或TIB,所以保证最后销毁。
- 异常对象不同于函数的局部对象,局部对象在函数调用结束后就被自动销毁,而异常对象将驻留在所有可能被激活的 catch 语句都能访问到的内存空间中,也即上文所说的 TIB。当异常对象与 catch 语句成功匹配上后,在该 catch 语句的结束处被自动析构。
- 在函数中返回局部变量的引用或指针几乎肯定会造成错误,同样的道理,在 throw 语句中抛出局部变量的指针或引用也几乎是错误的行为。如果指针所指向的变量在执行 catch 语句时已经被销毁,对指针进行解引用将发生意想不到的后果。
- throw 出一个表达式时,该表达式的静态编译类型将决定异常对象的类型。也就是该对象的类型与throw语句中体现的静态类型相同。即只有子类对象中的父类部分会被抛出,抛出对象的类型也是父类类型(从实现上讲,是因为复制到“临时对象”的时候,使用的是throw语句中类型的(这里是父类的)复制构造函数)。
- 注意,这里分成两种情况。一种情况是throw的指针/引用是多态形式。如
Base* ptr = new Derived(); throw ptr;或Derived d; Base& ref = d; throw ref;- 假设匹配顺序正确,这时候会匹配成
Base。这就是所谓的静态类型。
- 假设匹配顺序正确,这时候会匹配成
- 但是如果你是直接
throw new Derived(),这样会正确匹配到Derived。因为这个时候并不发生多态。静态类型就是Derived - 如果值传递会发生切割。如果catch顺序不对的时候会造成提前匹配。
- 如果throw出来的是派生类引用或指针,如果catch顺序不对的时候且可以匹配至基类也会发生提前匹配。
- 虽然throw本身在匹配类型的时候会发生切割。但是throw的异常对象本身可以蕴含多态。也就是使用指针或引用可以实现多态。
- 注意,这里分成两种情况。一种情况是throw的指针/引用是多态形式。如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
//指针的切割
class Base{ };
class Derived: public Base{ };
int main(){
try{
Base* ptr = new Derived();
throw ptr;
cout<<"This statement will not be executed."<<endl;
}
catch(Derived*){
cout<<"Exception type: Derived"<<endl;
}
catch(Base*){
cout<<"Exception type: Base"<<endl;
}
return 0;
}
//这里抛base。因为ptr的静态类型是base
//引用的切割
class Base{ };
class Derived: public Base{ };
int main(){
try{
Derived d;
Base& b = d;
throw b;
cout<<"This statement will not be executed."<<endl;
}
catch(Derived&){
cout<<"Exception type: Derived"<<endl;
}
catch(Base&){
cout<<"Exception type: Base"<<endl;
}
return 0;
}
//这里还是抛base。因为引用b的静态类型也是base
//正确匹配对象
class Base{ };
class Derived: public Base{ };
int main(){
try{
throw Derived();
cout<<"This statement will not be executed."<<endl;
}
catch(Derived){
cout<<"Exception type: Derived"<<endl;
}
catch(Base){
cout<<"Exception type: Base"<<endl;
}
return 0;
}
//正确匹配指针
class Base{ };
class Derived: public Base{ };
int main(){
try{
throw new Derived();
cout<<"This statement will not be executed."<<endl;
}
catch(Derived*){
cout<<"Exception type: Derived"<<endl;
}
catch(Base*){
cout<<"Exception type: Base"<<endl;
}
return 0;
}
//正确匹配引用
class Base{ };
class Derived: public Base{ };
int main(){
try{
throw Derived();
cout<<"This statement will not be executed."<<endl;
}
catch(Derived&){
cout<<"Exception type: Derived"<<endl;
}
catch(Base&){
cout<<"Exception type: Base"<<endl;
}
return 0;
}
多级catch
1
2
3
4
5
6
7
8
9
10
11
try{
//可能抛出异常的语句
}catch (exception_type_1 e){
//处理异常的语句
}catch (exception_type_2 e){
//处理异常的语句
}
//其他的catch
catch (exception_type_n e){
//处理异常的语句
}
当异常发生时,程序会按照从上到下的顺序,将异常类型和 catch 所能接收的类型逐个匹配。一旦找到类型匹配的 catch 就停止检索,并将异常交给当前的 catch 处理(其他的 catch 不会被执行)。如果这一层没有找到匹配该异常的语句,就会交给更外层的try-catch来处理。如果最终也没有找到匹配的 catch,就只能交给系统处理,终止程序的运行。
如果抛出的异常不能被捕获,则会调用
std::terminate异常处理匹配时,只可以进行有限的类型转换。
- 向上转型(子转父)
- 注意会有提前匹配和对象切割问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
//这版本**注意会有提前匹配问题。无论传递的是子类的对象还是指针都会提前匹配或对象切割** class Base{ }; class Derived: public Base{ }; int main(){ try{ throw Derived(); //抛出自己的异常类型,实际上是创建一个Derived类型的匿名对象. cout<<"This statement will not be executed."<<endl; } catch(Base){ cout<<"Exception type: Base"<<endl; } catch(Derived){ cout<<"Exception type: Derived"<<endl; } return 0; } /* 有的编译器会提示: exception of type ‘Derived’ will be caught by earlier handler for ‘Base’ 最后异常是被第一块捕获的。 */ //这个版本调换了顺序。无论throw的是父类/子类的对象/指针,都会被正确匹配至实际类型。 class Base{ }; class Derived: public Base{ }; int main(){ try{ throw new Derived(); cout<<"This statement will not be executed."<<endl; } catch(Derived*){ cout<<"Exception type: Derived"<<endl; } catch(Base*){ cout<<"Exception type: Base"<<endl; } return 0; }
const转换- 数组或函数指针转换
- 向上转型(子转父)
匹配上的未必是类型完全匹配那项,而在是最靠前的第一个匹配上的 catch 语句(最先匹配原则)。所以,派生类的处理代码 catch 语句应该放在基类的处理 catch 语句之前,否则先匹配上的总是参数类型为基类的 catch 语句,而能够精确匹配的 catch 语句却不能够被匹配上。
可以使用
catch(...)捕获所有异常。但是必须要放在最末尾,否则所有其后的块都不会被匹配。- 注意,在使用捕获所有异常的时候,不存在是使用值传递或引用传递。因为捕获所有异常等于什么都”做不了”。参数都没有名字,你无法访问异常对象。所以根本不存在值传递。或者说,使用捕获所有异常的时候,不会有任何异常对象本身被捕获。但是代码块会被调用。
栈回退/栈展开(stack unwind)
其实栈展开已经在前面说过,就是从异常抛出点一路向外层函数寻找匹配的 catch 语句的过程,寻找结束于某个匹配的 catch 语句或标准库函数 terminate。这里重点要说的是栈展开过程中对局部变量的销毁问题。我们知道,在函数调用结束时,函数的局部变量会被系统自动销毁,类似的,throw 可能会导致调用链上的语句块提前退出,此时,语句块中的局部变量将按照构成生成顺序的逆序,依次调用析构函数进行对象的销毁。
- 栈回退表这个数据结构会帮助编译器正确释放资源。
- 退栈的时候,栈上分配的东西(局部变量)都会被正确销毁。但是涉及到在堆上分配的资源则大概率会泄露。
异常对象的传递,尽量按值抛出,按引用传递(捕获)
我们说过异常对象是一个对象。我们可以自己设计它。但是具体传递当中有很多的要点。
- 异常对象可以通过引用传递。通过引用传递不仅可以实现多态,而且可以减少拷贝。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class A
{
public:
A() :a(0){ cout << "A默认构造函数" << endl; }
A(const A& rhs){ cout << "A拷贝构造函数" << endl; }
~A(){ cout << "A析构函数" << endl; }
private:
int a;
};
int main()
{
try
{
A a ;
throw a;
}
catch (A a) //注意这里
{
;
}
return 0;
}
/*
A默认构造函数
A拷贝构造函数
A析构函数
A拷贝构造函数
A析构函数
A析构函数
*/
- 第一次默认构造是
A a - 第一次拷贝构造是
throw a- 我们说过throw表达式是调用拷贝构造
- 第一次析构是析构掉对象
A a - 第二次拷贝构造是拷贝到catch块内的a
如果我们换成引用传递呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main()
{
try
{
A a ;
throw a;
}
catch (A& a) //注意这里
{
;
}
return 0;
}
/*
A默认构造函数
A拷贝构造函数
A析构函数
A析构函数
*/
- 第一次默认构造是对象
A a - 第一次拷贝构造是
throw a - 由于我们是引用传递,所以没有额外的拷贝构造。
我们提到过,throw表达式创建的对象是在TIB块内。所以可以离开作用域。
- 注意,这里我们是创建对象后拷贝使用
throw拷贝了一个对象。如果此时我们直接throw A()会直接构造因为有编译器优化。
如果 catch 子句的形参是引用类型,那么对它所做的任何更改都会反映到异常对象之中,且如果以 throw; 重抛这个异常,那么它可以被另一个处理块观测到。如果形参不是引用,那么任何对它的更改都是局域的,且它的生存期在处理块退出时结束。
- 所以尽可能使用引用传递。尤其是当重抛一个一样的异常的时候,使用值传递会导致多个副本。
try catch中的多态
虽然catch匹配本身不能发生多态,但是其对象本身可以发生多态。上一节我们提到了,使用引用可以实现多态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class Base{
public:
virtual void print(){
cout <<"base" << endl;
}
};
class Derived: public Base{
public:
virtual void print(){
cout <<"derived" << endl;
}
};
int main(){
try{
throw Derived(); //抛出自己的异常类型,实际上是创建一个Derived类型的匿名对象
cout<<"This statement will not be executed."<<endl;
}
catch(Base e){ //值传递。无法多态。
e.print(); //输出 base
}
return 0;
}
我们上面使用了值传递,则无法多态。如果使用引用或指针传递则可以多态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int main(){
try{
throw Derived(); //抛出自己的异常类型,实际上是创建一个Derived类型的匿名对象
cout<<"This statement will not be executed."<<endl;
}
catch(Base& e){ //引用传递 虽然匹配无法多态,但是e本身可以多态。
cout <<"catch base" << endl;
e.print(); //输出derive
}
catch(Derived& e){
cout <<"catch derived" << endl;
e.print();
}
return 0;
}
/*
catch base //这里还是发生了提前匹配。
derived //对象本身可以多态。
*/
如果try中进行了内存分配,一定要记得在catch中或catch后释放它
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int main()
{
try
{
A* a = new A;
throw a;
}
catch (A* a)
{
delete a; //如果不delete则会内存泄漏
}
//或者放在这里也可以。
return 0;
}
这里我们在try内分配了内存,然后throw会拷贝a这个指针(浅拷贝)。catch会接收这个指针。所以我们必须在外部正确释放。
如果是这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
int main()
{
try
{
A* a = new A;
throw *a; //啥情况???
}
catch (A a)
{
;
}
return 0;
}
/*
A默认构造函数
A拷贝构造函数
A拷贝构造函数
A析构函数
A析构函数
*/
这是非常极端的例子。
- 第一次构造是new A
- 第一次拷贝构造是 throw *a 我们拷贝了指针a指向的对象。这非常离谱。
- 这时候原始a指针指向的对象无法析构。内存泄漏
- 第二次的拷贝构造是把throw拷贝的对象拷贝出来到catch块的a中。
- 然后throw的对象和catch的对象析构。
re-throw
我们可以在catch块内再次使用空语句throw;来直接进行异常的再次抛出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
class myexcept{
public:
string msg;
myexcept(){
cout <<"--const except--" << endl;
}
myexcept(const myexcept& obj){
cout <<"--copy const except--" << endl;
}
myexcept(const string& s):msg(move(s)){
cout <<"--const except--" << endl;
};
void what(){
cout << msg << endl;
}
~myexcept(){
cout << "--desc except--" << endl;
}
};
void func(){
int errs = 0;
for(int i = 0; i < 10; i++){
try{
cout << "try" << endl;
throw myexcept("error occured");
}
catch (myexcept& e){
cout <<"re-throw" << endl;
e.msg = "too many err";
throw;
}
}
}
int main(){
try{
func();
}
catch(myexcept& e){
cout << "main" << endl;
e.what();
}
return 0;
}
/*
try
--const except-- 构造异常对象
没有拷贝构造是因为编译器优化。
re-throw 进入catch准备rethrow
main 进入main
too many err 信息已被修改
--desc except-- 异常对象销毁。
*/
- 我们之前提到过,使用引用传递异常对象可以进行修改。尤其是在进行re-throw的时候。
- 我们看到信息被修改了,并且没有额外拷贝开销。
re-throw可以达成一些特殊目的
- 比如这段代码的目的是,只要是偶数就抛出异常。但是异常抛出次数小于等于4次的时候可以让程序继续运行。一旦大于4次就重抛至外部,修改异常信息并停止运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
void func(){
int errs = 0;
for(int i = 0; i < 10; i++){
try{
cout <<"current is: " << i << endl;
if(i%2 == 0){
errs++;
throw runtime_error("error occured");//注意这里
}
}
catch (runtime_error& e){ //注意这里
cout <<"error: " << e.what() << endl;
if(errs >= 2){
e = runtime_error("too many errors"); //注意这里发生了赋值
throw e;
}
}
}
}
int main(){
try{
func();
}
catch(runtime_error& e){ //注意这里
cout << e.what() << endl;
}
return 0;
}
注意,我们这里throw的和catch的全部都是runtime_error对象而不是exception对象。
exception是runtime_error的父类。如果我们使用exception进行接受并且使用子类对象runtime_error进行赋值的话,则会发生切割。所以这里要格外注意。
构造函数和异常
- 构造函数中可以抛出异常,但是抛出的异常会导致该类析构函数无法被调用。因为被视为对象没有成功构造。会存在内存泄漏风险。
- 注意,不调用析构函数并不代表局部对象不会析构。该类蕴含的局部对象会析构。因为需要退栈。
- 也就是一定要注意本类析构函数的动作不会执行。如果本类的析构函数本来就不执行什么,那么久不会出现问题。但是如果本类析构需要进行资源清理,则会出现问题。
- 退栈的时候,栈上分配的东西(局部变量)都会被正确销毁。但是涉及到在堆上分配的资源则大概率会泄露。
- !!!!!如果委托构造函数在非委托构造函数成功完成后以异常退出,那么就会调用此对象的析构函数。!!!!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
class A{
public:
A(){
cout <<"A const" << endl;
}
~A(){
cout <<"A dest" << endl;
}
};
class B{
public:
B(){
cout <<"B const" << endl;
}
~B(){
cout <<"B dest" << endl;
}
};
class myobj{
public:
A a;
B b;
myobj(){
cout <<"myobj const" << endl;
throw runtime_error("runtime error"); //构造函数中抛出异常。
}
~myobj(){
cout << "myobj dest" << endl;
}
};
class myobj2 {
public:
A a;
B b;
myobj2() { cout << "myobj2 const" << endl; }
myobj2(int x) : myobj2() {
cout << "myobj2 int const" << endl;
throw runtime_error("runtime error"); // 委托构造函数中抛出异常。
}
~myobj2() { cout << "myobj2 dest" << endl; }
};
int main(){
try{
myobj a;
}
catch(exception& e){
cout <<"error catched" << endl;
}
return 0;
}
/*
A const
B const
myobj const
B dest
A dest
error catched
注意! 本类析构没有正确调用。
*/
我们发现析构函数确实没有被调用。杂记2也提到了:
构造函数中可以抛出异常,但是抛出的异常会导致析构函数无法被调用。因为被视为对象没有成功构造。会存在内存泄漏风险
但是本类蕴含的A和B对象被正确析构了。
异常和委托构造
如果委托构造函数在非委托构造函数成功完成后以异常退出,那么就会调用此对象的析构函数。
看下这个小测试
1
2
3
4
5
6
7
8
9
10
11
12
13
try {
myobj2 b;
} catch (exception& e) {
cout << "myobj2 error catched" << endl;
}
/*
A const
B const
myobj2 const
myobj2 dest // 注意 myobj2的析构函数正确调用
B dest
A dest
*/
还是上面的代码。如果是委托构造中抛出异常,则该类析构可以正常调用。出自标准文档的except.ctor。 我理解是因为委托构造中使用的非委托构造结束的一刻,对象就被视为构造完毕了。所以是合理的。
构造函数异常导致的内存泄漏
假设我们有如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
class A{
public:
A(){
cout <<"A const" << endl;
}
~A(){
cout <<"A dest" << endl;
}
};
class B{
public:
B(){
cout <<"B const" << endl;
}
~B(){
cout <<"B dest" << endl;
}
};
class myobj{
public:
A* ptra;
B* ptrb;
myobj(){
ptra = new A(); //分配资源
ptrb = new B();
throw runtime_error("runtime error"); //抛出异常
}
~myobj(){
cout << "myobj dest" << endl;
delete ptra; //释放资源
delete ptrb;
}
};
int main(){
try{
myobj a;
}
catch(exception& e){
cout <<"error catched" << endl;
}
return 0;
}
/*
输出
A const
B const
error catched
*/
我们发现内存泄露了。原因和上一节提到的一样。所以如果在析构函数中抛出异常则必须要妥善处理。
解决方案:
- 在构造函数内也使用try catch捕获所有异常并重新抛出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
class myobj{
public:
A* ptra;
B* ptrb;
myobj(){
try{
ptra = new A();
ptrb = new B();
throw runtime_error("runtime error");
}
catch(...){ //捕获所有异常
delete ptra;
delete ptrb;
cout << "inner catched" << endl;
throw; //重抛
}
}
~myobj(){
cout << "myobj dest" << endl;
delete ptra;
delete ptrb;
}
};
int main(){
try{
myobj a;
}
catch(exception& e){
cout <<"error catched" << endl;
}
return 0;
}
- 或使用RAII如智能指针包裹
A/B对象。此时无需在构造函数内继续使用try-catch
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class myobj{
public:
shared_ptr<A> ptra;
shared_ptr<B> ptrb;
myobj(){
ptra = make_shared<A>(); //智能指针
ptrb = make_shared<B>(); //智能指针
throw runtime_error("runtime error");
}
~myobj(){
cout << "myobj dest" << endl;
}
};
int main(){
try{
myobj a;
}
catch(exception& e){
cout <<"error catched" << endl;
}
return 0;
}
再次注意。构造函数中的内存泄漏针对的是本类的内存泄漏。也就是try中分配的内存需要catch中释放。
如果抛出异常的构造函数的类没有在try中分配什么东西,那就不会泄露。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
struct ExceptionObject
{
int a;
ExceptionObject()
{
throw "an exception";
}
};
int main()
{
ExceptionObject* ptr = nullptr;
try
{
ptr = new ExceptionObject(); //该new在构建对象的时候发现异常,则取消构造。并且调用delete释放。
}
catch(...)
{
//delete or not delete ptr?
}
return 0;
}
上面的漏了吗? 没漏。因为ExceptionObject没有手动分配内存。我们下面看到的try里面的new在构建ExceptionObject对象的时候发现异常就会把自己的new释放。编译器会帮助我们。
如果初始化因抛出异常而终止(例如来自构造函数),那么 new 表达式在已经分配了任何存储的情况下会调用适当的解分配函数
这个解分配只解分配自己。
但是下面的漏了吗?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
struct ExceptionObject
{
int* a;
ExceptionObject(){
a = new int(10); //漏了
throw "an exception";
}
};
int main()
{
ExceptionObject* ptr = nullptr;
try{
ptr = new ExceptionObject();
}
catch(...){
//delete or not delete ptr?
}
return 0;
}
漏了。因为我们ExceptionObject有手动分配内存。ExceptionObject的析构不会调用。这时候就会出现泄漏

new在遇到异常的时候只会解分配自己分配的内存。ExceptionObject里面的那个指针分配的内存并不是这个new分配的。所以它不负责。
一个自定义异常对象的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
class myExcept{ //异常对象
public:
enum m_errtype{NO_ERR, LENGTH_ERR, VALID_ERR, BOTH_ERR}; //枚举类,更加美观
myExcept():m_ERRTYPE(NO_ERR){}; //默认构造函数,无异常
myExcept(int x):m_ERRTYPE(LENGTH_ERR), length(x){}; //构造函数1:目的是实现第1种异常对象的构造
myExcept(bool x):m_ERRTYPE(VALID_ERR), valid(x){}; //构造函数2:目的是实现第2种异常对象的构造
myExcept(int x,bool y):m_ERRTYPE(BOTH_ERR), length(x), valid(y){}; //构造函数3:目的是实现第3种异常对象的构造
void what() const{ //what函数模拟标准库exception类对象。这个函数会打印本类的具体错误。
if(m_ERRTYPE == LENGTH_ERR){
cout <<" EXCEPTION!! exceed length size: " << length << endl;
}
else if(m_ERRTYPE == VALID_ERR){
cout <<" EXCEPTION!! not valid state: " << valid << endl;
}
else if(m_ERRTYPE == BOTH_ERR){
cout <<" EXCEPTION!! exceed length: "<< length <<" and not valid state: " << valid << endl;
}
}
private:
m_errtype m_ERRTYPE; //错误类型
int length; // 具体资源状态。用于显示具体错误。
bool valid; // 具体资源状态。用于显示具体错误。
};
class myobj{
public:
int length;
bool valid;
myobj() = default;
myobj(int x, bool y):length(x), valid(y){
cout << "myobj constructed" << endl;
}
void test_func(int x, bool y){
cout << "test func" << endl;
if(x < 10 && y == false){
throw myExcept(x,y);
}
else if(y == false){
throw myExcept(y);
}
else if(x < 10){
throw myExcept(x);
}
}
~myobj(){
cout <<"myobj destructed" << endl;
}
};
int main(){
myobj obj(1,true);
try{
obj.test_func(0, true); //调用时刻。
}
catch(myExcept& e){
e.what();
}
cout <<"main continued" << endl;
return 0;
}
/*
第一种 obj.test_func(0, true);
myobj constructed
test func
EXCEPTION!! exceed length size: 0
main continued
myobj destructed
剩下的不举例了。
*/
函数try块 function-try-block
这个东西在构造函数使用初始化列表的情况下偶尔有用。它主要是把构造函数初始化列表中和函数体中的异常区别开来。
在进入任何构造函数上的函数 try 块的 catch 子句前,所有完整构造的成员和基类都会被销毁。
规则都一样。但是有一点不同:
- 在(构造)函数
catch块中:就算我们不显式的throw,编译器也会隐式安插throw。默认是重抛。所以在最外层依旧要再次处理这个异常。
它长这个样子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
class A{
public:
int val;
A(){
cout <<"A const" << endl;
}
A(int x):val(x){
cout <<"A const" << endl;
}
~A(){
cout <<"A dest" << endl;
}
};
class B{
public:
int val;
B(){
cout <<"B const" << endl;
}
B(int x):val(x){
cout <<"B const err" << endl;
throw runtime_error("ERR"); //b的构造函数抛一个异常。
}
~B(){
cout <<"B dest" << endl;
}
};
class myobj{
public:
A a;
B b;
myobj(int x, int y) try: a(x), b(y){ //try在这里。在初始化列表前。
cout<<"myobj const" << endl;
}
catch(runtime_error& e){ //后面紧跟catch
// cout << e.what() << endl;
// throw;
//这里就算不throw也会隐式安插throw
//进入这个块之前,A会被析构。
}
~myobj(){
cout << "myobj dest" << endl;
}
};
int main(){
try{
myobj a(1,2); //由于myobj构造函数一定会再次重抛异常到外面。所以这里必须再次用try catch接一下。
}
catch(runtime_error& e){
cout << e.what() << endl;
}
}
noexcept
noexcept指明了函数不会抛出异常。这样做可以提升性能,因为编译期不会去思考栈展开的问题。但是有很多点需要注意:
只有异常说明不同的函数不能重载(与返回类型相似,异常说明是函数类型的一部分,但不是函数签名的一部分)(C++17 起)
- 如果虚函数不会抛出,那么它每个覆盖的函数的所有声明(包括定义)都必须不抛出,除非覆盖函数被定义为
delete- 也就是父类虚函数声明抛出异常,子类的虚函数重写的时候也必须声明抛出异常。
- 不会抛出的函数允许调用有可能会抛出的函数。每当抛出异常且对处理块的查找遇到了不会抛出的函数的最外层块时,就调用函数
std::terminate- 也就是函数自己不抛异常,但是不代表它们内部的调用不会抛出异常,并且编译器不会提供调用者与被调用者的
noexcept一致性检查。 - 当一个声明为
noexcept的函数抛出异常时,程序会被终止并调用std::terminate();
- 也就是函数自己不抛异常,但是不代表它们内部的调用不会抛出异常,并且编译器不会提供调用者与被调用者的
- 绝大多数情况下,析构函数会被编译器隐式添加
noexcept。- 如果希望析构函数抛出异常,必须显式使用
noexcept(false)指明
- 如果希望析构函数抛出异常,必须显式使用
- 函数指针及该指针所指的函数最好具有一致的异常说明。
- 在
typedef或类型别名中则不能出现noexcept。 - 在成员函数中,
noexcept说明符需要跟在const及引用限定符之后,而在final、override或纯虚函数的=0之前。
什么时候建议使用noexcept
以下指的是如果这些实现不抛出异常的话。
- 移动构造和移动赋值
- 尤其针对
vector而言。想要触发vector使用存储元素类型对应的移动构造时,则对应元素类型的移动构造必须声明为noexcept- 为什么?我们想一下:如果在扩容元素时出现异常怎么办?
- 当我们使用拷贝构造时:
- 申请新空间时出现异常:旧vector还是保持原有状态,抛出的异常交由用户自己处理。
- copy元素时出现异常:所有已经被copy的元素利用元素的析构函数释放,已经分配的空间释放掉,抛出的异常交由用户自己处理。
- 这样看起来比较不错。但是并没有移动。利用
move的交换类资源所有权的特性,使用vector扩容效率大大提高,但是当发生异常时怎么办?- 原有容器的状态已经被破坏,有部分元素的资源已经被偷走。若要恢复会极大增加代码的复杂性和不可预测性。所以只有当vector中元素的
move constructor是noexcept时,vector扩容才会采取move方式来提高性能。
- 原有容器的状态已经被破坏,有部分元素的资源已经被偷走。若要恢复会极大增加代码的复杂性和不可预测性。所以只有当vector中元素的
- 尤其针对
- swap
- 简单的函数。 例如获取类成员变量,类成员变量的简单运算等。
noexcept()的小技巧。
我们知道不会抛出的函数允许调用有可能会抛出的函数。但是这是有问题的。那么我们又没有办法让编译器帮我们做决定呢?
我们可以这样:
1
2
3
4
5
6
void test(int x){
//...
}
int sum(int x, int y) noexcept(noexcept(test(x))){
//...
}
noexcept(test(x))传入了一个我们希望检查是否noexcept的函数和其参数。编译器会在编译时检查这一点并根据结果为函数添加说明符。
https://www.cnblogs.com/RioTian/p/15115387.html
https://zhuanlan.zhihu.com/p/222167649
https://songlee24.github.io/2015/01/12/cpp-exception-in-constructor/
https://blog.csdn.net/liang19890820/article/details/120662921
https://blog.csdn.net/weixin_50640987/article/details/124406222
http://baiy.cn/doc/cpp/inside_exception.htm
https://developer.aliyun.com/article/75525
https://zhuanlan.zhihu.com/p/406894769
lambda
我个人不太喜欢lambda。可读性感觉很一般。但是感觉大家都在用,那么在这里再次整理一下lambda。
另外一点是lambda和closure的关系。lambda表达式被用来创建closure类型。 来自这里
lambda 表达式是纯右值表达式,它的类型是独有的无名非联合体非聚合体类类型,被称为闭包类型,它(对于 实参依赖查找 而言)声明于含有该 lambda 表达式的最小块作用域、类作用域或命名空间作用域。
基本语法:
1
2
3
[capture](parameters) mutable可选 throw()可选 ->returntype
{statement
}
[capture]:捕捉列表。捕捉列表总是出现在Lambda函数的开始处。- 在捕捉列表里面的参数我们称之为behavior parameter行为参数。
[]也是Lambda引出符。编译器根据该引出符判断接下来的代码是否是Lambda函数。捕捉列表能够捕捉上下文中的变量以供Lambda函数使用。- 如果把lambda当做容器的自定义排序或比较的函数对象使用,则一般都不用捕捉参数。捕捉参数可以理解为上下文所需要的内容。如果一个lambda只需要对传入的参数进行修改或访问,则不需要捕捉变量。如果需要lambda上下文中的变量,才需要进行捕捉。
- 捕获列表里面的变量将成为lambda这个匿名类的成员变量。根据捕捉方式决定其是否可以改变。
- 默认情况下,捕获列表内的变量不可修改。如要修改,必须给lambda表达式增添mutable关键字。
- 捕获列表内的变量如果按照值捕获,对其的修改不会影响外部变量。因为捕获列表内的变量成为匿名类的局部变量。并且是按照值拷贝的
- 捕获列表内的变量如果按照引用捕获,对其的修改则会影响外部变量。
(parameters):参数列表。与普通函数的参数列表一致。如果不需要参数传递,则可以连同括号“()”一起省略;- 参数列表里面的参数我们称之为call parameter调用参数。
mutable:mutable修饰符。默认情况下,Lambda函数总是一个const函数,mutable可以取消其常量性。在使用该修饰符时,参数列表不可省略(即使参数为空);- 注意,这个mutable针对的是捕获列表里面值传递的变量。而非函数入参。且引用传入的时候默认是可以修改的,可以不添加mutable
->return-type:返回类型。用追踪返回类型形式声明函数的返回类型。我们可以在不需要返回值的时候也可以连同符号->一起省略。此外,在返回类型明确的情况下,也可以省略该部分,让编译器对返回类型进行推导;{statement}:函数体。内容与普通函数一样,不过除了可以使用参数之外,还可以使用所有捕获的变量。
与普通函数最大的区别是,除了可以使用参数以外,Lambda函数还可以通过捕获列表访问一些上下文中的数据。具体地,捕捉列表描述了上下文中哪些数据可以被Lambda使用,以及使用方式(以值传递的方式或引用传递的方式)。语法上,在[]包括起来的是捕捉列表,捕捉列表由多个捕捉项组成,并以逗号分隔。捕捉列表有以下几种形式:
[]空表示不捕获[=]表示值传递方式捕获所有父作用域的变量(包括this)- 用值传递的捕捉方式时,类中会添加相应类型的非静态数据成员。运行的时候会用复制的值去拷贝初始化成员变量
[&]表示引用传递方式捕获所有父作用域的变量(包括this)[var]表示只以值传递方式捕获特定变量var[&var]表示只引用传递捕获特定变量var[=, &var]默认以值捕获所有变量,但是var是例外,通过引用捕获[&, var]默认以引用捕获所有变量,但是var是例外,通过值捕获[this]表示只以值传递方式捕获当前的this指针- 这里指的是复制指针。所以是值传递指针,但由于是指针,所以也是引用捕获当前对象。这里格外注意悬垂引用问题
[*this]:通过传值方式捕获当前对象 。也就是拷贝对象(C++17起)
上面提到了一个父作用域,也就是包含Lambda函数的语句块,说通俗点就是包含Lambda的“{}”代码块。上面的捕捉列表还可以进行组合,例如:
[=,&a,&b]表示以引用传递的方式捕捉变量a和b,以值传递方式捕捉其它所有变量;[&,a,this]表示以值传递的方式捕捉变量a和this,引用传递方式捕捉其它所有变量。 不过值得注意的是,捕捉列表不允许变量重复传递。例如:[=,a]这里已经以值传递方式捕捉了所有变量,但是重复捕捉a了,会报错的;[&,&this]这里&已经以引用传递方式捕捉了所有变量,再捕捉this也是一种重复。
针对匿名lambda,可以直接在其表达式结尾额外添加一组括号表示函数调用:
1
[](){cout <<"hello world" << endl;}(); //注意结尾额外的一组括号
- 按值捕获一个变量后,如果在lambda表达式后方修改这个变量,不会影响到lambda内这个变量的值。也就是lambda表达式之前这个变量是什么,他在lambda表达式中表现的就是什么。这个变量后续的行为和lambda表达式无关。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int main(){
int val = 0;
auto f = [val]() mutable{ //mutable是必须要写的。否则不可修改val
cout << "val:" << val << endl; //0
val++;
cout << "val:" << val << endl; //1
};
cout << val << endl; //0
val = 28;
cout << val << endl;//28
f();
cout << val << endl;//28
}
//针对这个例子,每一次f()的调用影响的都是lambda内部的val变量
为什么val=28没有改变外部的值?同时lambda内部的修改值没有影响到外面?
lambda是一个匿名类,(也就是匿名的函数对象)。捕获的变量会变成这个匿名类的类成员变量。如果按照引用捕获那么这个成员变量就是个引用。自然你在外部修改也会影响里面的值。正因为如此,如果按照值来捕获,在创建这个lambda表达式的那一刻,被按照值捕获的变量会被在这个匿名类内创建(拷贝)并按照它在这一行之前的那个值来进行附初值。
因为lambda的类型是匿名类,编译器认为每个lambda表达式都不同,哪怕定义完全一样其匿名类名也会不一样,所以lambda表达式只能用auto类型。
lambda的默认构造函数和赋值操作默认是delete的。也就是说,lambda类型非可默认构造(C++20前)但是,它有浅拷贝构造函数可被调用。而使用
decltype提取未计算的lambda表达式的类型是不允许的,但是,decltype提取已计算的的lambda表达式是可以的。1 2 3 4
auto g = [](int x){return x;} decltype(g) another = g; //可以,已计算的lambda decltype(auto g = [](int x){return x;}) another = g; //不可以。未计算的lambda
lambda没有默认构造,没有拷贝赋值。有隐式生成的拷贝构造和移动构造。
lambda还有合成的用户定义转换函数。它的作用是返回一个函数指针。这个函数指针指向内部合成的静态成员函数(严格来说是public, 非虚,非explicit且const noexcept), 这个转换函数返回一个指向具有 C++ 语言连接的函数指针,调用该函数的效果与在默认构造的lambda类型实例上调用lambda类型的函数调用运算符
operator()的效果相同。- 最后一句话,我们可以理解为这个函数内部会调用本类的函数调用运算符
operator()。虽然事实并非如此,但是效果一致。 - !!!只有在捕获列表为空的时候才会合成此用户定义转换函数。!!!!
- 因此我们可以把lambda传入一个只接受函数指针的C函数。如
atexit
- 最后一句话,我们可以理解为这个函数内部会调用本类的函数调用运算符
所以我们是值传递。在lambda创建的那一刻。val已经被拷贝构造至匿名类内了。所以对类内的修改作用域只在lambda内部。自然不会影响外部。
具体例子就是这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
//具体的类函数实现就是构造函数文件内的。这里不复制粘贴了。
int main(){
myobj val (20);
auto f = [val]() mutable{ //值传递
};
}
/*
const
copy const //val被拷贝构造至lambda内。
dest
dest
*/
int main(){
myobj val (20);
auto f = [&val]() mutable{ //引用传递
};
}
/*
const //引用传递不会发生拷贝。
dest
*/
也就是说基本情况下,一个lambda的匿名类大概长这样。所以必须要显式使用mutable让其表示可以修改。
1
2
3
4
5
6
7
class Closure{
public:
ReturnType operator()(params) const{
//具体内容
}
};
https://www.jianshu.com/p/d686ad9de817
lambda的大小
我们说过lambda是匿名类,并且它会根据捕获的参数和使用的是引用捕获还是值捕获来使用对应的方式初始化匿名类内对应的成员。所以它的大小是因情况而异,取决于捕获的参数。
1
2
3
4
5
6
7
8
9
10
char a1[20];
char b1[300];
auto f = [a1](){}; //值捕获大小为20的数组
auto f1 = [&a1](){}; //引用捕获大小为20的数组
auto f2 = [b1](){}; //值捕获大小为300的数组
auto f3 = [&b1](){}; //引用捕获大小为300的数组
cout << sizeof(f) << endl; //20
cout << sizeof(f1) << endl; //8
cout << sizeof(f2) << endl;//300
cout << sizeof(f3) << endl;//8
所以这个lambda的大小会发生变化。
注意引用捕获导致的悬垂引用
1
2
3
4
std::function<int(int)> add_x(int x)
{
return [&](int a) { return x + a; };
}
因为参数x仅是一个局部变量,函数调用后就被销毁,但是返回的lambda表达式却引用了该变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template <typename Func, typename... Args>
std::function<void()> addTask(Func &&f, Args&&... args){
std::function<void()> func = [&](){ //注意这里是按照引用捕获了,有潜在bug
f(std::forward<Args>(args)...);
};
return func;
}
void fuck1(int a){
std::cout << a << std::endl;
}
void fuck2(int a, const std::string& b, double c){
std::cout << a << b << c << std::endl;
}
int main(){
std::vector<std::function<void()>> vecs;
int input = 10;
vecs.push_back(addTask(fuck1, 10)); //注意这里是右值。
vecs.push_back(addTask(fuck2, 10, "abcde", 6.678));
vecs[0]();
vecs[1]();
}
我们的目的是使用std::function来包装一个任意多参数的无返回值的函数。上面的实现是错误的。因为我们一直是用右值引用把函数和参数传入addTask函数,然后lambda又使用引用捕获了参数。这里会非常危险。如果像addTask(fuck1, 10)这样使用,这个10会在当前行返回后失效。那么lambda捕获的对10的引用也会失效。当然如果能保证这个10一直有效,则没有问题。但问题就在于如何保证10一直有效。所以我们可以使用值传递。或者是使用std::bind完成我们的目的。这也就是为什么std::bind一直默认是拷贝传入。
其他资料
- 在这里观看Nicolai Josuttis在CppCon 2021中对lambda的详细介绍。
- 使用lambda的原因之一是更容易被编译器处理为内联,性能更好。关于这一点,查看这里
- lambda和内联,查看这里
关于lambda和智能指针/移动捕获(通用捕获)相关内容查看智能指针章节。
注意,这个方法也可以用在当你想声明一个在lambda内部使用的变量时(理解为闭包类型的成员变量)
一些搭配容器的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
int main(){
int x = 100;
auto cmp = [](const Person& a, const Person& b){return (a.id < b.id);
};
set<Person, decltype(cmp)> my_set(cmp); //set的自定义比较。利用decltype。必须传入构造函数。
my_set.emplace(3,1);
my_set.emplace(1,2);
my_set.emplace(2,2);
for(auto& i:my_set){
cout << i.id << " " << i.day << endl;
}
vector<Person> my_vec;
my_vec.emplace_back(3,1);
my_vec.emplace_back(1,2);
my_vec.emplace_back(2,2);
sort(my_vec.begin(), my_vec.end(), [](const Person& a, const Person& b){return a.id < b.id;}); //sort的自定义排序
for(auto& i:my_vec){
cout << i.id << " " << i.day << endl;
}
return 0;
}
注意,在把lambda当做自定义比较器传入
set容器中的时候,不仅要在模板处指定类型,也要放入set的构造函数中。因为我们说过了。lambda没有默认构造函数和赋值操作。如果不把lambda作为参数传入进去的话,
set的默认无参构造函数会调用lambda的无参构造函数。但是lambda没有无参构造函数。所以会报错。我们必须要把lambda传入这样可以调用set的另一种有参构造函数。另一种有参构造:
1 2 3 4 5 6 7
set(); //具体实现: set() : _Mybase(key_compare()) {} //直接构造函数对象。但是lambda没有默认构造。 explicit set( const Compare& comp, const Allocator& alloc = Allocator() ); //具体实现: explicit set(const key_compare& _Pred) : _Mybase(_Pred) {} //对函数对象进行拷贝。
为什么说lambda是一个非常方便的在运行时定义函数的功能
假设我们需要查找容器内小于特定数值的元素,如果使用bind,则会像是这样:
1
2
3
4
5
6
7
8
9
bool less_certain(int val, int elem){
return elem < val;
}
int main(){
vector<int>a{1,2,3,4,5,6,7};
int val = 7;
int num = count_if(a.begin(), a.end(), bind(less_certain, val, std::placeholders::_1));
cout << num << endl;
}
在杂记3中讨论过,能用lambda就不要用bind。所以可以像这样使用。我们可以让lambda的功能依靠运行时参数
1
2
3
4
5
6
7
8
int main(){
vector<int>a{1,2,3,4,5,6,7};
int val = 7;
int num = count_if(a.begin(), a.end(), [val](int elem){
return elem < val;
});
cout << num << endl;
}
泛型lambda在模板笔记
模板lambda (C++20才正式合法)
泛型lambda其实是不显式指定模板形参的情况。而模板lambda是显示指定模板形参的情况
1
2
3
4
5
6
7
8
9
10
auto lambda = [](auto x) {
// x 可以是任意类型,编译器会为每种调用生成对应的函数体
return x + 1;
}; // 泛型lambda
auto lambda = []<typename T>(T x) {
// 这里可以在 lambda 中显式使用 T
return x + 1;
};// 模板lambda
一些用法、提示和注意事项
1
2
3
4
5
6
7
8
9
10
11
12
13
14
int main() {
auto closure = []<typename T>(T x) {
return [=] { std::cout << "Inner lambda prints: " << x << "\n"; };
};
auto closure2 = closure.template operator()<int>(10);
auto same_as_closure2 = closure(10); // 和 closure2作用一致
auto closure3 = ([]<typename T>(T x) {
return [=] { std::cout << "Inner lambda prints: " << x << "\n"; };
}).template operator()<int>(10);
closure2();
same_as_closure2();
closure3();
}
我们知道lambda是有重载了operator()的类。所以我们既可以直接lambda(input)调用,也可以lambda.operator(input)调用。当有模板的时候,必须要显示使用lambda.template operator(input)来告诉编译器我们在这里要传递显式的模板参数。
所以此处,closure2和same_as_closure2是等价的。那么啥时候会有区别呢?那就是我们无法推导出模板形参类型的时候。假设这个情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
auto closure4 = []<auto Fn>(int input) -> std::function<void(int)> {
return [input](int x) -> void {
cout << "input:" << input << endl;
cout << "x: " << x << endl;
Fn(input + x);
};
};
auto closure5 = closure4.template operator()<[](int t) { cout << t << endl; }>(2);
// auto same_as_closure5 = closure4(2);
closure5(20);
/*
input:2
x: 20
22
*/
- 模板笔记中强调了,非类型模板参数不能用
typename,是一个具体的类型或者是auto、decltype(auto) - 此处用了
std::function做替代因为带捕获的无法转换为函数指针
我们如何理解这个呢? closure4返回了一个接受一个int作为入参的std::function对象,而closure4的形参也是int。所以说closure5接受的就是closure4返回的std::functoin对象。所以closure5的入参20是x。而closure5后面的实参2是closure4的形参。所以input是2.
此处我们故意模拟了必须要显示指定operator()的模板参数的情况。其实closure5形式上等价于same_as_closure5
在这个成员级guard中用到了此技法。
lambda在关键变量中的应用
在看吐槽微信扫描二维码出现bug的源码视频的时候学到了一个好用的小技巧。
首先就是不要重复创建变量
1
2
3
4
void func(int count){
int count2 = count; //不要重复创建变量
//.....
}
这样做非常不好,有损语义。因为你不好说count和count2有什么联系或者区别,这时候可以使用引用创建一个别名
1
2
3
4
void func(int count){
int& count2 = count; //不要重复创建变量
//.....
}
这时候有问题了,如果我想要的不是别名,而是一种修改过的值呢?比如:
1
count2 = 2 * count;
这种语义下,单纯的别名就不太好用了。因为我们希望无论count何时何地被修改。count2永远是2* count。也就是这个语义永远成立。
那么我们可以考虑使用lambda把单纯的变量变成函数,比如:
1
2
3
4
5
6
7
8
9
10
void func(int count){
auto count2 = [&]{return 2* count;}; //使用lambda
cout << count2() << endl; //注意,这样使用就需要函数调用了 这里是40
count = 200;
cout << count2() << endl; //这里是400
}
int main(){
func(20);
return 0;
}
这样就满足了我们想要的语义。
所以这里有一个技巧,也就是当某一个变量可以被某几个变量计算出来,并且重复计算代价比较低(重复计算的代价比单纯的计算后储存高不了多少的时候),可以把变量换成lambda函数,让它在调用时计算。这样比较减少重复代码。
lambda和一元加法
在这篇文章中,我们发现yyjson中有一段关于lambda的奇怪用法
1
2
3
4
5
using alc_size_t = std::uint16_t;
alc.malloc = +[](void *ctx, size_t size_native) noexcept -> void * { ... };
alc.realloc = +[](void *ctx, void *ptr, size_t old_size_native, size_t size_native) noexcept -> void * { ... };
alc.free = +[](void *ctx, void *ptr) noexcept -> void { ... };
为啥lambda前面要跟着个加法?
在cppreference关于算术运算符的介绍中,我们看到了内建一元加法的作用:
于内建一元加运算符,表达式 必须是算术、无作用域枚举或指针类型的纯右值。如果表达式 具有整数或无作用域枚举类型,那么对它实施整数提升。结果的类型是(可能为提升后的)表达式 的类型。
内建的提升操作的结果是表达式 的值。如果操作数为提升后的整数或指针类型的纯右值,则内建的一元加运算为无操作。否则,整数提升或左值到右值、数组到指针、函数到指针或用户定义转换会更改操作数的类型或值类别。例如在一元加表达式中 char 会被转换为 int ,而非泛型且无捕获的 lambda 表达式会被转换为函数指针(C++11 起)。
其实核心就是使用一元加法触发一下lambda到函数指针的隐式类型转换。多说一句,一元加法的唯一作用就是进行类型转换。
函数指针和函数对象的性能差异。(依靠编译器实现)
在很多情况下,比如针对容器或算法使用特定的排序要求、我们可能会传递一个函数对象或函数指针。
函数对象类型可以是:
- 函数指针类型
- 重载了
operator()的 类类型(有时被称为仿函数),这其中包含 lambda 函数 - 包含一个可以产生一个函数指针或者函数引用的转换函数的 类类型。
出自 C++模板第二版 – 11.1
这样的类型对应的值被称之为函数对象。
如果一个回调是通过函数指针实施的,那么性能较差。因为函数指针是通过地址调用的函数。该地址在编译时可能不可见。所以编译器较难优化(比如施加inline)
如果是通过函数对象实施,由于对象是固定的。对象位置在编译时可知。所以编译器可以针对其进行优化。
当然了,如果我们需要在运行时动态替换某些需要传入的回调,那么还是得使用函数指针。
C中的变长原始数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct test{
int val;
char c;
int arr[0]; //使用0来进行数组占位。分配一个首地址
};
int main(){
test* T = (test*)malloc(sizeof(test) + sizeof(int) * 40); //给结构用malloc分配大小。大小为结构体长度+你想给数组分配多大。这里分了40个int长度也就是对应int a[40]
T->val = 5;
T->c = 'a';
T->arr[30] = 5;
cout << T->arr[30] << endl;
free(T); //因为是用的malloc来分配内存所以使用free释放
return 0;
}
注意,零长数组本身不占用内存空间。它只是首地址。
请记住。原始数组名称本身并不是指针。我们说的是原始数组的名称是数组首元素的地址
- 一定要区分指针和地址的区别。地址可以隐式转换成指针而已。
- 也就是说若
array是一个原始数组,则以下关系为真:
1
array = &array[0];
https://www.eet-china.com/mp/a55099.html
https://www.51cto.com/article/277404.html
副作用和序列点 和 求值顺序
副作用
表达式有两种功能:
每个表达式都产生一个值( value )
同时可能包含副作用( side effect )。
访问(读或写)
volatile泛左值所指代的对象,修改(写入)对象,调用库 I/O 函数,或调用任何做出这些操作的函数都是副作用副作用的其中一点是指改变了某些变量的值。 如:
20这个表达式的值是
20。它没有副作用,因为它没有改变任何变量的值。- ` x=5`
这个表达式的值是
5。它有一个副作用,因为它改变了变量x的值。- ` x=y++`
这个表达示有两个副作用,因为改变了两个变量的值。
x=x++- 这个表达式也有两个副作用,因为变量
x的值发生了两次改变。
序列点 (C++11前)
顺序点的意思是在一系列步骤中的一个“结算”的点,语言要求这一时刻的求值和副作用全部完成,才能进入下面的部分。在C/C++中只有以下几种存在顺序点:
分号(每一个完整表达式结尾)
未重载的逗号运算符的左操作数赋值之后(即
,处)注意逗号运算符有时候需要加括号来避免歧义
1 2
int a = funca(), funcb(), funcc(); //不行,只调用了funca int a = (funca(), funcb(), funcc()); //加了括号可以。
未重载的
||运算符的左操作数赋值之后(即||处)未重载的
&&运算符的左操作数赋值之后(即&&处)三元运算符
? :的左操作数赋值之后(即?处)在函数所有参数赋值之后但在函数第一条语句执行之前。(调用函数时,所有的函数实参的求值后有个序列点。发生于函数体内任何表达式或语句的执行前)
在函数返回值已拷贝给调用者之后但在该函数之外的代码执行之前。(对函数的返回值进行复制后,并在函数外任何表达式执行前有一个序列点)
每个基类和成员初始化之后
在每一个完整的变量声明处有一个顺序点,例如
int i, j;中逗号和分号处分别有一个顺序点for循环控制条件中的两个分号处各有一个顺序点。
对于任意一个顺序点,它之前的所有副作用都已经完成,它之后的所有副作用都尚未发生。
在两个顺序点之间,子表达式求值和副作用的顺序是不同步的。如果代码的结果与求值和副作用发生顺序相关,称这样的代码有不确定的行为(unspecified behavior).而且,假如期间对一个内建类型执行一次以上的写操作,则是未定义行为. 即:标准规定,在两个序列点之间,一个对象所保存的值最多只能被修改一次。
也就是说:任意两个顺序点之间的副作用的发生顺序都是未定义的.如:
1
a() + b() + c();
这个表达式有一个序列点,也就是结尾的分号处。
由于 operator+ 的从左到右结合性被分析成 (a() + b()) + c(),但在运行时可以首先、最后或者在 a() 和 b() 之间对 c() 求值:
按顺序早于(C++11/17起)
包括这个回答
我们可以精简出一些规则:
The following expressions are evaluated in the order a, then b:
a.ba->ba->*ba(b1, b2, b3) // b1, b2, b3 - in any orderb @= a // '@' means any operatora[b]a << ba >> b
注意,a(b1, b2, b3) 这种函数调用表达式里面的顺序依旧是未指定的。比如foo(s(), g(), h()) 里面 s(), g(),和 h()的调用顺序是未指定的。
可变参数宏
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
void test(int a, ...){ //第一个参数表明后面一共有几个参数。
va_list args; //定义一个可变参数列表
va_start(args, a); //初始化可变参数列表
for(; a > 0; a--){
cout << va_arg(args, int) << endl; //使用va_arg访问下一个可变参数函数参数。第二个参数是传入参数类型
}
va_end(args); //释放args
}
int main(){
test(4,10,9,8,7);
return 0;
/*
输出:
10
9
8
7
*/
}
/*
注意C语言里的printf就是这个效果。
C自带的printf函数是根据第一个参数format的占位符解析出后面的变参个数和类型,
通过va_arg迭代去获取变参再填充到占位符上输出。
*/
可变参数宏可以让我们给一个函数增添变参特性。在C++中可以使用initializer list完成这件事
https://blog.csdn.net/qq_35280514/article/details/51637920
https://xie.infoq.cn/article/4e927ec51b5a364f51e2ac944
宏的三个特殊符号 #, ## , #@
#define ToString(x) #x- 意思是给
x加双引号。比如 char str = ToString(123132);就成了str="123132";
- 意思是给
#define Conn(x,y) x##y- 意思是
x连接y int n = Conn(123,456);结果就是n=123456;char* str = Conn("asdf", "adf");结果就是str = "asdfadf";- 当可变参数宏
__VA_ARGS__`为空的时候, 这样使用可以让编译器去除前面的多余逗号##__VA_ARGS__- 可以查看项目相关的笔记. 里面写过
- 意思是
#define ToChar(x) #@x- 意思是给
x加上单引号,结果返回是一个const char char a = ToChar(1);结果就是a='1';
- 意思是给
decltype
C++ 规范中,对于 decltype 类型推导规则的定义如下:
1
decltype(expr)
若expr是一个没有带括号的标记符表达式(如局部变量名、命名空间作用域变量、函数参数等)或者类成员访问表达式(注意,静态数据成员按规则2.2推导),那么的decltype(expr)就是expr所命名的实体的类型(声明型别)。此外,如果expr是一个被重载的函数,则会导致编译错误。
否则:
- 若 expr 的值类别为 将亡值 ,则
decltype产生T&&;- 若 expr 的值类别为 左值 ,则
decltype产生T&;- 若 expr 的值类别为 纯右值 ,则
decltype产生T。
- 对于纯右值而言,只有类类型可以保留cv限定符,其它类型则会丢失cv限定。
如果 表达式 是返回类类型纯右值的函数调用,或是右操作数为这种函数调用的逗号表达式,那么不会对该纯右值引入临时量。
也就是若表达式是 纯右值 ,则不从该纯右值 物质化 临时对象:这种纯右值无结果对象。
说人话就是类型名+
()等于调用类的默认构造生成匿名临时对象,这个临时对象的类型自然是类类型。临时对象又是纯右值。所以就是你这个表达式是返回类类型纯右值的函数调用。注意如果对象的名字带有括号,则它被当做通常的 左值 表达式,从而
decltype(x)和decltype((x))通常是不同的类型。
- 表达式:表达式由一个或多个运算对象组成,对表达式求值将得到结果。字面值和变量是最简单的表达式,其结果就是字面值和变量的值。
- 标记符表达式:即除去关键字、字面量等编译器所需要使用的标记之外的程序员自定义的标记(token)都是标记符。而单个标记符对应的表达式就是标记符表达式。如
int arr[4];那么arr是一个标记符表达式,arr[3],arr[3]+0等都不是标记符表达式。 - 上述“expr所命名的实体的类型”和“expr的类型”是不完全相同的两个概念。在类成员访问表达式(如
E1.E2或E1->E2)中,expr所命名的实体的类型即为E2的“声明类型”,而expr的类型指整个表达式E1.E2求值结果的类型。- 如果E2为静态数据成员,表达式
E1.E2的结果始终是左值。decltype(E1.E2)按规则2.2而不是规则1推导。 - 如果E2是个引用类型(如
T&或T&&),decltype(E1.E2)指E2实体的声明类型(T&或T&&)。而整个表达式E1.E2结果则为T类型的左值,即代表E2引用所指的对象或函数。 - 若E2为非引用类型:当E1为左值时,E1.E2整个表达式为左值。而如果E1为右值,则整个表达式为右值类型。(E2为静态数据成员例外,见1的说明)。
- 如果E2为静态数据成员,表达式
- 字符串字面值常量是个const的左值(可以取地址),采用规则2.2推导。而非字符串字面值常量则是个右值,采用规则2.3推导。
- 对于类型为T的左值表达式,decltype总是得出T&类型
decltype 有两种表达方法:
- 有括号:
decltype((expr))- 有括号的表达方法,语意是简单而统一的:它站在表达式类别的角度求类型。
- 原本不是表达式的类型,加上括号后立刻变为表达式类型。主要针对是变量名和函数名。
- 有括号传入变量名推导出的类型是这个变量左值引用类型。因为变量名作为表达式是左值。左值按照规则产生左值引用类型。
- 无括号:
decltype(expr)- 无括号和有括号只在针对传入变量名和函数名的时候有区别。
- 无括号传入变量名推导出的类型就是这个变量的类型。
注意。一个表达式的结果不是左值就是右值(包括将亡值)。然而一个变量名称本身也是一个表达式。无括号的情况下,除了一种例外,其它情况下,都与有括号场景一致。这个例外就是对于变量(包括常量)名字的直接求类型。这种情况,会返回变量被定义时的类型。然而给变量再包一层括号,这个变量的名字会变成表达式。
也就是
1
2
3
4
int a = 10;
a; //表达式
decltype(a); //a被当做变量。类型类型推导为int
decltype((a));//a被当做表达式。表达式a是左值,所以类型推导为int&
额外注意作用于函数名会得到函数类型,不会自动转换成指针。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
struct sr{
};
int func(){
}
int& anotherfunc(){
}
int func_with_arg(int a, int b){
}
int main() {
sr obj;
cout << is_same_v<decltype(func), int(void)> << endl; //这个是变量。是函数本身。所以是函数类型。注意不是函数指针类型。
cout << is_same_v<decltype(&func), int(*)(void)> << endl; //这个是变量。是取函数地址。所以是函数指针类型。
cout << is_same_v<decltype(func()), int> << endl; //这是表达式。值传递的返回值是临时对象,纯右值推导为变量类型
cout << is_same_v<decltype(sr()), sr> << endl; //sr()是表达式。类匿名临时对象,纯右值。纯右值推导为变量类型
cout << is_same_v<decltype(anotherfunc()), int&> << endl; //这是表达式。引用返回的是左值。左值推导为引用类型
cout << is_same_v<decltype(obj), sr> << endl; //这是变量。直接作用于变量是变量类型
cout << is_same_v<decltype(move(obj)), sr&&> << endl;//这是表达式。move返回右值引用,表达式返回将亡值。将亡值是右值引用类型
//----加括号部分------
cout << is_same_v<decltype((func)), int(&)(void)> << endl; //注意,加了括号后变成表达式类型。具名函数也算左值,返回引用类型。所以是函数引用。
cout << is_same_v<decltype((func())), int> << endl; //加了括号没区别
cout << is_same_v<decltype((sr())), sr> << endl; //加了括号没区别
cout << is_same_v<decltype((anotherfunc())), int&> << endl; //加了括号没区别
cout << is_same_v<decltype((obj)), sr&> << endl; //这是表达式因为给变量多了一层括号。这个表达式是左值。因为具名变量本身是左值。左值推导为引用类型
cout << is_same_v<decltype((move(obj))), sr&&> << endl;//加了括号没区别
//-------需要强调的部分-------
cout << is_same_v<decltype(func_with_arg), int(int,int)> << endl;//这是推导函数类型
cout << is_same_v<decltype(func_with_arg(int{}, int{})), int> << endl;//函数带了括号是表达式。这是推导函数调用的返回值类型
cout << is_same_v<decltype(func_with_arg(3,4)), int> << endl;//和上面一样
cout << is_same_v<decltype(func_with_arg(int,int)), int> << endl;//不行。func_with_arg(int,int)不是有效表达式
cout << is_same_v<decltype(func_with_arg(declval<int>(),declval<int>())), int> << endl;//使用declval。但是是脱裤子放屁
int s = 100;
cout << is_same<decltype(2), int>::value << endl; // 字面值纯右值,推导为T
cout << is_same<decltype(s), int>::value << endl; //变量名不加括号,推导为其声明类型。此处就是T
cout << is_same<decltype((s)), int&>::value << endl; //变量名加了括号是表达式。是左值。此处推导为T&
cout << is_same<decltype(move(s)), int&&>::value << endl;//move过后变成将亡值,推导为T&&
}
- 注意需要强调的部分。函数加括号就是表达式。就是函数调用。推导函数调用类型就等于推导函数返回值类型。
- 注意推导函数调用的时候,如果有参数必须放一个参数而不是一个类型。比如倒数第二行,
func_with_arg(int,int)并不是有效的表达式,你见过这么调用的函数?就算decltype不求值,但是必须语句合法。- 所以你既可以放一个参数进去,也可以用
{}初始化临时对象。但是不能()因为会被当做函数声明。 - 也可以像最后一行,用declval。但是在这里是脱裤子放屁
- 所以你既可以放一个参数进去,也可以用
https://stackoverflow.com/questions/19200513/function-pointer-vs-function-reference
https://stackoverflow.com/questions/36517596/decltype-parenthesis-syntax-for-a-lvalue
https://modern-cpp.readthedocs.io/zh_CN/latest/decltype.html
https://blog.csdn.net/u014609638/article/details/106987131
https://www.cnblogs.com/5iedu/p/11222078.html
关于decltype成员函数类型
1
2
3
4
5
6
7
8
9
10
11
12
struct A {
void func_const() const{
}
void func_nonconst(){
}
void test(){
cout << is_same_v< decltype(&A::func_nonconst), void(A::*)(void)> << endl; //这是求函数指针类型
cout << is_same_v< decltype(declval<A>().func_nonconst()), void> << endl; //这是求函数返回值类型
}
};
- 第一个,
&A::func_nonconst并不调用函数,它获取一个成员函数地址,可以隐式转换为成员函数指针。所以此时类型比较的是成员函数指针类型而非成员函数类型。所以是void(A::*)(void)而不是void(void) - 第二个,
declval目的是求函数返回值类型。所以必须要有函数调用。最后必须是func_nonconst()
关于decltype的不求值语境
decltype推导过程是在编译期完成的,并且不会真正计算表达式的值。
decltype不产生代码,对于表达式的要求只需要一个声明,不需要定义。也就是只需要一个名字。所以你可以这样:
1
2
3
4
int test(); //压根没定义
int main(){
cout << is_same<int, decltype(test())>::value << endl;//true
}
- 虽然decltype并不求值,但是其中涉及到的临时对象的“创建”和”销毁“都是受到语义限制的。也就是仍然受到创建和销毁临时所需的任何函数(包括构造函数)的可访问性的限制。
- 换句话说,其不会生成临时对象,但是也应遵守所有语义限制,就好像临时对象已创建并随后被销毁一样。这包括可访问性 以及它是否被删除,比如造函数和析构函数。
- https://stackoverflow.com/questions/25663642/why-can-i-use-private-default-constructor-in-decltype
- 此处有疑问。在标准文档N4835的6.7.7一节中,这样描述:
Even when the creation of the temporary object is unevaluated (7.2), all the semantic restrictions shall be respected as if the temporary object had been created and later destroyed. [Note: This includes accessibility (11.9) and whether it is deleted, for the constructor selected and for the destructor. However, in the special case of the operand of a decltype-specifier (7.6.1.2), no temporary is introduced, so the foregoing does not apply to such a prvalue. — end note]
这句话说的由于在 decltype 说明符操作数的特殊情况下,没有引入临时值,因此上述内容不适用于此类 prvalue。但是我们来测试一次
1
2
3
4
5
6
7
struct A {
A() = delete;
int foo();
};
int main(){
decltype(A().foo()); //我们先忽略掉如果decltype合法后提示的 does not declare anything 错误
}
为什么这里会提示不合法:use of deleted function ‘A::A()’
这里要区分不求值和是否合法。非静态成员函数必须通过一个对象或指向对象的指针调用。就算我们这里没有引入临时值,此时不求值,但是必须要通过对象调用。没有对象无法调用。不合法。同时,在标准库文档有这样的一句话:
如果使用特殊语法 = delete 取代函数体,那么该函数被定义为弃置的(deleted)。任何弃置函数的使用都是非良构的(程序无法编译)。这包含调用,包括显式(以函数调用运算符)及隐式(对弃置的重载运算符、特殊成员函数、分配函数等的调用),构成指向弃置函数的指针或成员指针,甚至是在不潜在求值的表达式中使用弃置函数。但是可以隐式 ODR 使用刚好被弃置的非纯虚成员函数。
所以在不潜在求值的表达式中使用弃置函数并不合法。
如果我们换成private呢?其就受到了前面提到的可见性限制。
不过我们如何理解最后一句话呢?其实文档提到的是这个例子:
1
2
3
4
5
6
7
8
struct A {
A() = delete;
};
A testfunc(); //注意这里
int main(){
decltype(testfunc()); //我们忽略掉does not declare anything 错误
}
这里我们有一个返回A的全局函数。全局函数直接调用是合法的。所以完全可以调用。此时函数的返回值是个临时对象,符合prvalue要求。此时表达式合法。这时候,就算A的构造函数是delete或private,都会成功。因为结合起来应该是说,创建临时对象的过程在decltype语境里是无视delete和可见性限制的。但是其调用方式必须合法。也就是说它不关心decltype里面那个函数创建的对象的过程。
关于decltype其他的雷点
查看这篇文章的Problems of automatic type deduction一节
还有O‘Dwyer的这篇文章
对指针解引用,返回的是对象的引用

- 这是想当然的。不然你没办法解引用后赋值,如
*ptr = 200; - 我们在EFFSTL中提到了对迭代器解引用返回的是引用。
- 同时在vptr当中提到了解引用指针的多态性。
逐位拷贝 memcpy ,可平凡复制 TriviallyCopyable 和 可平凡重定位 TriviallyRelocatable
在C++中,我们把传统C风格的数据类型叫做POD(Plain Old Data)对象,即一种古老的纯数据,C的所有对象都是POD。一般来说,POD对象应该满足如下特性:其二进制内容是可以随意复制的,无论在什么地方,只要其二进制内容存在,我们就能准确无误地还原POD对象。正是由于这个原因,对于任何POD对象,我们都可以放心大胆地使用memset(),memcpy(),memcmp()等函数对对象的内存数据进行操作。
下列类型统称为可平凡复制类型:
- 标量类型
- 可平凡复制类类型
- 上述类型的数组
- 这些类型的有 cv 限定版本
什么东西不是POD类型?C++的对象大概率并不是一个POD,我们无法像在C中那样获得该对象直观简洁的内存模型。对于POD对象,我们可以通过对象的基地址和数据成员的偏移地址获得数据成员的地址。但是C++标准并未对非POD对象的内存布局做任何定义,对于不同的编译器,其对象布局是不同的。而在C语言中,对象布局仅仅会受到底层硬件系统差异的影响。针对非POD对象,其序列化会遇到一定的障碍:由于对象的不同部分可能存在于不同的地方,因为无法直接复制,只能通过手工加工序列化操作代码来处理对象数据。
最简单的来说,类的特殊成员函数如拷贝构造,拷贝赋值,移动构造,移动赋值和析构函数会为我们隐式添加很多操作。尤其是含有多态的时候。我们在vptr部分详细讲述了。子类对象给父类对象赋值的时候会产生切割。vptr不会被复制, 会隐式的在拷贝构造或拷贝赋值中对其进行调整。但是,memcpy却会完完整整的把二进制级别信息拷贝进来。所以不会针对如vptr进行调整。这时候如果针对非POD类型进行memcpy操作,再调用函数就会爆炸。
当然了,如果子类给子类memcpy,父类给父类进行memcpy,不会发生问题。因为不涉及对如vptr等东西进行隐式调整。
一般来说,只要是我们在语义上和行为上允许不调用析构函数,也就是析构函数不做什么事情的时候,它就是可平凡复制的,可以使用memcpy。来自
在上面的讲座中提到了TriviallyRelocatable可平凡重定位的。它是一个仍然在草案中的特性。重定位就相当于移动+调用原对象的析构函数。因为移动后,被移动的对象的资源虽然移走了,但是对象本身还在,依旧需要调用析构函数。这样就是需要访问两次对象。一次移动和一次析构。而重定义相当于在移动后立即调用对象的析构。也就是只需要访问一次。
可平凡重定位就相当于只需要移动而不需要调用析构函数。因为析构函数不做什么。
对于一个对象
R,如果“移动它然后立即销毁原始对象”的操作等同于memcpy,我们可以说R是可平凡重定位的。
最经典的例子就是当std::unique_ptr的内容被移动后的时候。因为它下面就是个原始指针。这时候当我们把资源移走后,如果我们使用std::move触发移动构造函数,则当前unique_ptr下面的原始指针一定会被置空。所以这个时候调用析构函数是无副作用的。所以它完全可以被省略掉。这个时候可以把处在这个状态下的unique_ptr当做可平凡重定位的。但是,不应该在std::unique_ptr上面施加如此复杂的判断逻辑。所以我们这个时候可以使用memcpy来直接拷贝整个std::unique_ptr对象(相当于把move+析构函数的这一套操作换为memcpy,也就是有意识的浅拷贝)。当然,我们不能销毁被拷贝的std::unique_ptr。因为一旦销毁了,就会调用析构函数,就会导致资源释放而出现问题。
注入类名 (injected-class-name)
- 注入类名是在类的作用域内该类自身的名字。
- 在类作用域中,当前类的名字被当做它如同是一个公开成员名一样;这被称为注入类名(injected-class-name)。该名字的声明点紧跟类定义的开花括号之后。
- 类模板中,注入类名能用作指代当前模板的模板名,或指代当前实例化的类名。
1
2
3
4
5
6
7
int X;
struct X {
void f() {
X* p; // OK:X 指代注入类名也就是本类名字。
::X* q; // 错误:名称查找找到变量名,它隐藏了本类名字。
}
};
- 与其他成员类似,注入类名可被继承,但是依旧受可见性制约。在私有或受保护继承的场合,可能导致某个间接基类的注入类名在派生类中最后变得不可访问。
1
2
3
4
5
6
struct A {};
struct B : private A {};
struct C : public B {
A* p; // 错误:注入类名 A 不可访问
::A* q; // OK:不使用注入类名
};
其他的太繁琐了。
局部类 local class
我不知道这玩意有啥用。它就是一个在函数里面的类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
struct base{
virtual void func(){
cout <<"b" << endl;
}
};
base* test(){
struct innerclass:base{ //局部类 继承自base
int val = 200;
void func(){
cout <<"inner" << endl;
}
};
return new innerclass;
}
int main(){
base* ptr = test(); //可以
ptr->func(); //可以
//innerclass obj; 不可以,不可见。
}
- 局部类有很多很多的限制:
- 必须在类内实现所有成员函数,不可以拿到类外(函数不可嵌套定义)
- 局部类只能访问外层作用域定义的类型,静态变量以及枚举成员或全局变量。如果局部类定义在某个函数的内部,那么该函数的普通局部变量不能被该局部类使用。
- 类内不可以含有静态数据成员,但可以含有静态函数成员。(reason:静态数据成员要求在类外进行初始化,在程序运行之前完成,并且用(::) 来指明所从属的类名,显然不能实现)
- 不能从外部初始化局部类对象。
- 所以我们如果不提供方法返回局部类的某个变量,则外部无法访问。
- 局部类的特性是可以被当做final。因为外界无法继承一个隐藏在函数内的class。
代理函数 surrogate call function
这个东西在模板11.1.1当中我们提到过。我们先举个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
template <typename Fcn1, typename Fcn2>
struct Surrogate {
Surrogate(Fcn1 *f1, Fcn2 *f2) : f1_(f1), f2_(f2) {}
operator Fcn1*(){
cout << "Fcn1*" << endl;
//Surrogate<Fcn1, Fcn2>::operator Fcn1() [with Fcn1 = void (*)(int); Fcn2 = void (*)(double)]
return f1_;
}
operator Fcn2*(){
cout << "Fcn2*" << endl;
return f2_;
}
Fcn1 *f1_;
Fcn2 *f2_;
};
void foo (int i){
cout <<"foo" << i << endl;
}
void bar (double i){
cout <<"bar" << i << endl;
}
int main (){
Surrogate<void(int), void(double)> callable(foo, bar); //注意当前版本是假设传入函数类型。我们也可以换成传入函数指针类型的
callable(10); // calls foo
//static_cast<void (*)(int)>(callable.operator void (*)(int)())(10);
callable(10.1); // calls bar
//static_cast<void (*)(double)>(callable.operator void (*)(double)())(10.1);
return 0;
}
我们发现我们首先传入了两个函数。然后类型显式指定为函数类型。然后使用两个函数指针去接受这两个函数。
然后定义了两个用户定义转换函数。一个会转换成第一个函数的函数指针类型,一个会转换成第二个函数指针类型。
那么在调用的时候,为什么可以调用呢?
我们不管注释掉的两行里面的static_cast,我们发现是因为我们在对callable进行一个函数调用,也就是实施了函数调用表达式。所以编译器会去寻找可调用对象,比如函数指针,函数,或者是带有operator()的东西。然后发现虽然callable不是这些东西,但是可以转换成其中之一,也就是函数指针。因为根据重载解析规则,这两个用户定义转换函数也被重载解析考虑在内(来自有点看不懂的标准文档)。同时这个时候因为给定的参数是int,根据重载解析规则,两次调用会选择对应的版本。
标准文档翻译:
如果函数调用语法中的后缀表达式
E计算出的是类型为cv T的类对象,则候选函数集中至少包括T的函数调用运算符。T的函数调用运算符是在T的作用域中搜索名称operator()的结果。此外,对于在
T中声明的形式为
operator conversion-type-id () cv-qualifier-seq opt ref-qualifier opt noexcept-specifier opt attribute-specifier-seq opt;的非显式转换函数,其中可选的
cv-qualifier-seq是与cv相同的cv限定符或更高的cv限定符,而conversion-type-id表示类型“返回R的(P1,...,Pn)函数的指针”,或类型“返回R的(P1,...,Pn)函数的引用”,或类型“指向返回R的(P1,...,Pn)函数的指针的引用”,还将考虑具有唯一名称(如下)call-function的代理函数
R call-function ( conversion-type-id F, P1 a1, ..., Pn an) { return F(a1, ..., an); }同样,对于
T的基类中声明的每个非显式转换函数,如果该函数没有被T中的另一个介于该函数和T之间的声明隐藏,则也将向候选函数集中添加代理调用函数。提交到重载解析的参数列表包括函数调用语法中的实参表达式,在其前面是隐含的对象参数(
E)。【注1】:在将调用与函数调用运算符进行比较时,隐含的对象参数将与函数调用运算符的对象参数进行比较。在将调用与代理调用函数进行比较时,隐含的对象参数将与代理调用函数的第一个参数进行比较。
函数指针类型的版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
template <typename Fcn1, typename Fcn2>
struct Surrogate {
Surrogate(Fcn1 f1, Fcn2 f2) : f1_(f1), f2_(f2) {}
operator Fcn1(){
cout << "Fcn1*" << endl;
return f1_;
}
operator Fcn2(){
cout << "Fcn2*" << endl;
return f2_;
}
Fcn1 f1_;
Fcn2 f2_;
};
void foo (int i){
cout <<"foo" << i << endl;
}
void bar (double i){
cout <<"bar" << i << endl;
}
int main (){
Surrogate<void(*)(int), void(*)(double)> callable(foo, bar);
callable(10); // calls foo
callable(10.1); // calls bar
return 0;
}