std::pmr 多态内存分配器
先回顾一下标准分配器
这一节最好搭配侯捷的标准STL内存分配器来看,这样可以很好帮助理解一些动作的行为。
分配器的核心就是四个步骤: 分配空间(allocate),构造对象(construct),析构对象(destruct),解分配空间(deallocate)。
标准内存分配器就提供了这四个函数。多态内存分配器也提供了这四个函数。
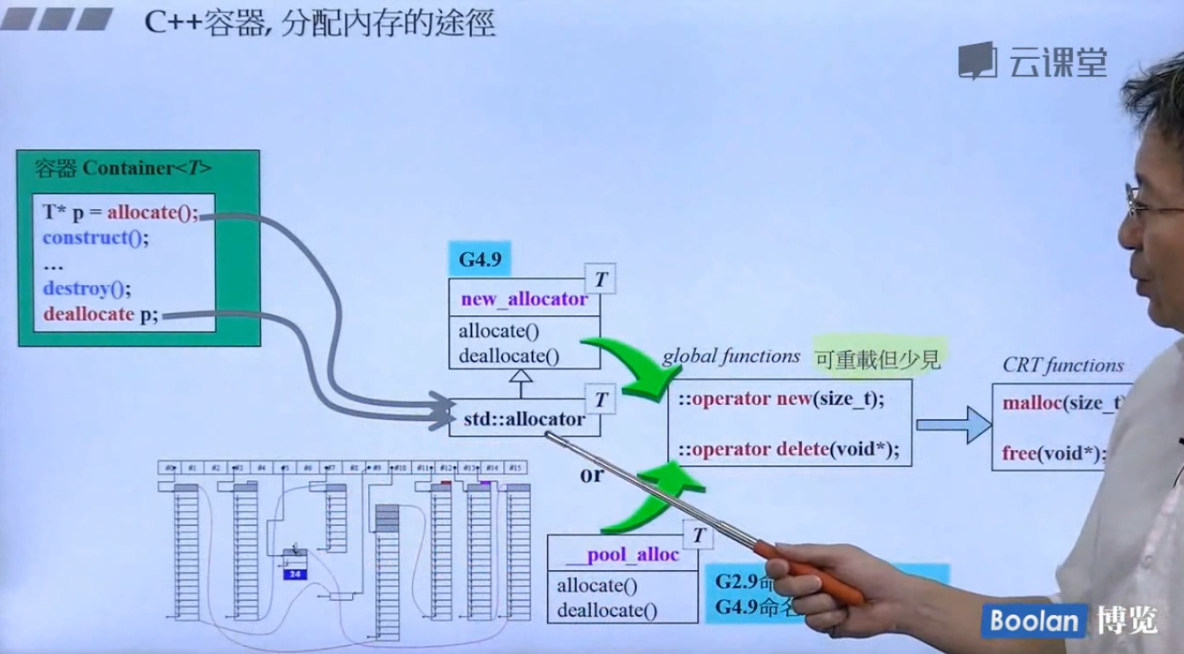
- 在标准分配器当中,
allocate和deallocate对应的全局的::operator new和::operator delete。construct和destruct对应的就是元素的构造和析构
为什么要有多态内存分配器
在没有多态内存分配器的时候,我们面临两个问题。
第一种情况是内存分配器的传播问题。
我们有一个独特的例子:

- 我们有一个
CustomString类,每一个对象接受一个allocator。我们现在有三个不同allocator的同类对象。注意此时对象类型均为CustomString。 - 然后我们放入
vector。在push_backx1和x2的时候没什么问题,使用了对应的分配器。但是如果我们在头部插入了x3,情况就不对了。 vector的头插逻辑是先在下一个可用位置分配一块内存,然后使用移动(拷贝)构造在新的位置构造出最后一个元素。然后再按照顺序把前面的元素搬移(拷贝)。在搬移(拷贝中),分配器是不会被拷贝(赋值)的。因为永远不该这么做,因为内存是已经被分配好了的,无法更改。- 所以这个时候有问题了。
x1用了alloc2,x3用了alloc1。瞬间混乱了起来。
我们真正想要的是这样的东西:
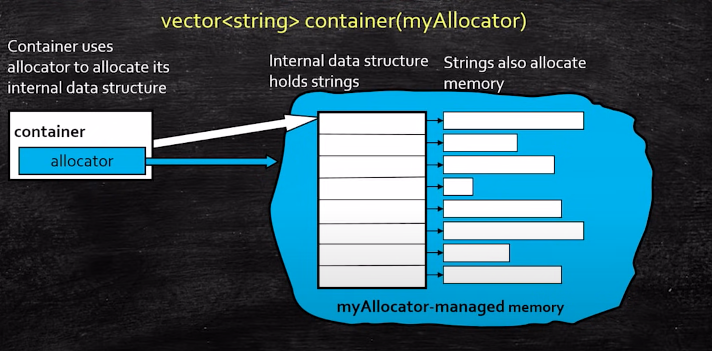
- 所以在C++17之前,我们有一个
std::scoped_allocator_adaptor。我们可以把自己的分配器使用它包装,它可以保证分配器的正确传播:
std::scoped_allocator_adaptor类模板是可用于多层容器( map 的 list 的 set 的 vector 等等)的分配器。它以外层分配器类型OuterAlloc与零或更多个内层分配器类型InnerAlloc...实例化。直接以scoped_allocator_adaptor构造的容器用OuterAlloc分配其元素,但若元素自身是容器,则它使用首个内存分配器。该容器的元素,若其自身是容器,则使用第二个内存分配器,以此类推。若容器的层级多于内层分配器的数量,则最内层分配器为所有进一步内嵌的容器再度使用。
第二个问题是内存分配器固有的问题:
针对默认内存分配器本身的性能有如下问题:
内存分配、回收慢。
内存分配可能有锁。
内存对齐无法控制。
分配位置无法控制。比如连续多次分配时,内存的定域性/局部性(locality)无法保证。
针对使用的参数方面有如下问题(尤其针对
std::allocator)allocator是模板签名的一部分。不同allocator的容器,无法混用。1 2 3 4
void func(const std::vector<int>&); // Default allocator //上面的vector签名是:std::vector<int, std::allocator<int>> std::vector<int, MyAlloc<int>> v(someAlloc); // 自定义分配器 func(v); // ERROR: v is a different type than std::vector<int>
- 二者签名不匹配。我们尽管可以使用模板,但是这会让后面所有的函数都是模板。
c++11以前,
allocator无状态;c++11以后,可以有状态,然而allocator类型复杂难用。allocator内存对齐无法控制,需要传入自定义allocator。以上三点、特别是第一点,造成STL无法成为软件接口(interface)的一部分。
难以将局部特种内存(比如共享内存),内存池用于STL容器。
多态内存分配器,内存资源和容器的关系
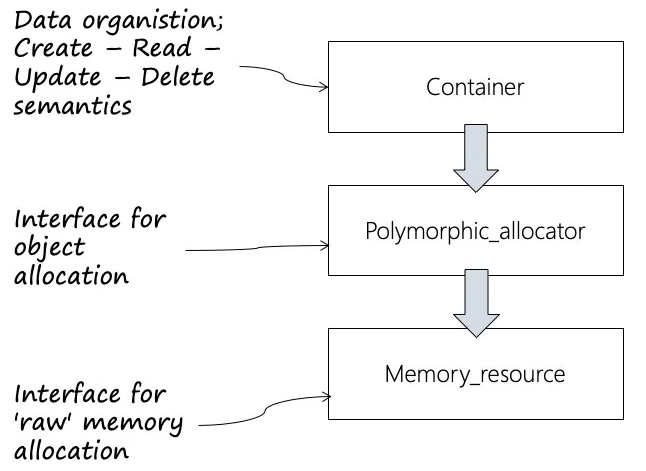
memory_resource是获得的原始内存,我们拿到了原始内存后,通过polymorphic_allocator分配器来进行分配。最后容器需要使用分配器来给元素分配内存。说白了,分配器从内存资源中获得资源,然后进行内存的再分配。polymorphic_allocator分配器是一层memory_resource的包装。
- 多态内存分配器作用域下的容器是
pmr::。其实就是别名模板。所以我们以vector为例:
1
2
3
4
namespace pmr {
template< class T >
using vector = std::vector<T, std::pmr::polymorphic_allocator<T>>;
}
由于多态内存分配器把内存资源的获取和分配分离开来,所以可以保证同一个元素哪怕底层内层资源不同,但是分配器的类型可以相同。
这部分的细节我们后面再细说。
再次解释一下多态内存分配器为什么解决了签名问题
重申一下,内存资源不是类模板。而是使用了继承。所以这一部分是动态多态。所以说内存资源类型是运行时确定的。在编译期间,所有pmr::vector<T>类型的容器都是同一个类型。分配器使用一个内存资源的指针在内部对内存资源进行管理。在上面的pmr::容器中,我们看到了多态内存分配器的模板参数是元素类型。然后我们容器已经构建完毕了。然后我们可以使用容器的构造函数传入分配器。这里用vector举例子:去查看文档 以第二个构造函数为例,就是接受一个分配器。
所以传入展开后会长这样:
1
std::vector<MyClass, std::pmr::polymorphic_allocator<MyClass> > vec = std::vector<MyClass, std::pmr::polymorphic_allocator<MyClass> >(allocator2);
我们可以看到所有的模板参数都是元素类型。分配器底层的内存资源并不影响分配器的类型。因为我们重申多态内存分配器把内存资源和分配分离开来了。所以针对同一元素类型的容器,可以使用不同类型的分配器。

内存资源 memory_resources
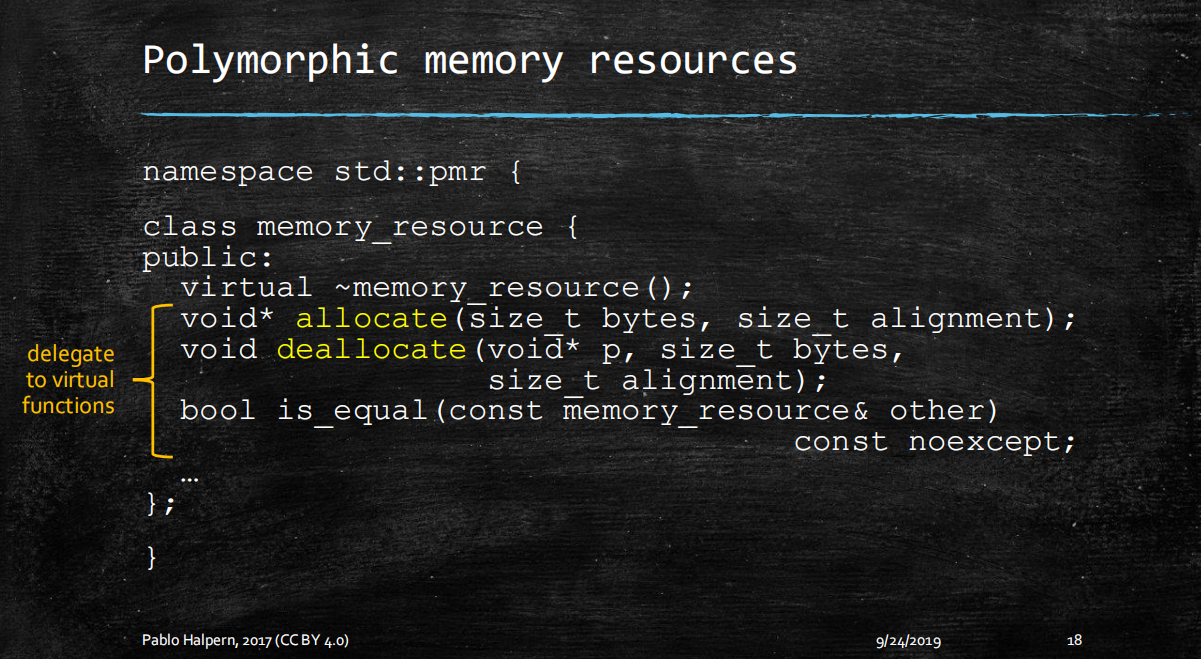
- 上图是一个抽象简化版的内存资源类。我们看到里面有allocate和deallocate。这两个是非虚函数。他们的分配动作是委托给私有虚成员函数
do_allocate和do_deallocate进行的。- 这里是模板方法模式的NVI(non-virtual-interface)技术。
memory_resource是一个抽象基类。STL给我们提供了内置的5种内存资源和一些工具函数。我们如果要自己实现自己的内存资源,也需要继承自此类。
类
std::pmr::memory_resource是抽象接口,针对封装内存资源类的无界集。
继承自
memory_resource的类需要实现的函数主要是四个do_allocate- 从自身内存中分配特定大小的内存。
- 具体定义会随之变化。比如从何处分配。
- 从自身内存中分配特定大小的内存。
do_deallocate- 从自身内存中解分配某一特定位置,特定大小的区块。
- 具体定义会随之变化。比如解分配到何处,是否真的解分配。
- 从自身内存中解分配某一特定位置,特定大小的区块。
is_equal- 比较两个内存资源是否相等。也就是从当前这个内存资源分配的内存是否可以通过另一个内存资源解分配。
release- 调用上游的deallocate来释放内存。将全部内存交还给上游内存分配器。
内存资源是可以成为链条的。这一点我们下面讲。
- 注意内存资源类不是类模板!!!
std::pmr::new_delete_resource
这是最基础的,也是默认的内存资源。它是从哪儿获取的原始内存呢?答案是从全局的::operator new
返回指向使用全局 operator new 与 operator delete 分配内存的
memory_resource的指针。
- allocate
- 因为这是默认的选项,所以非常自然地,内存的分配会使用
::operator new
- 因为这是默认的选项,所以非常自然地,内存的分配会使用
- deallocate
- 既然分配的都用默认的了,那么解分配也是会用到
::operator delete
- 既然分配的都用默认的了,那么解分配也是会用到
一般来说,上游分配器都是它。默认也是它。
std::pmr::monotonic_buffer_resource
- 这是一个比较特殊的资源。它特殊就特殊在我们可以使用栈内存做为内存资源。如使用
char buffer[1024]来获取一段栈内存做为原始内存。它是一种单调递增的资源。它仅在销毁资源时释放分配的内存。它的意图是提供非常快速的内存分配,在内存用于分配少量对象,并于之后一次释放的情况下。- 因为它的原理仅仅是推指针。所以分配速度非常快。属于一块线性内存。
- 构造函数
1
2
3
4
5
6
7
monotonic_buffer_resource(); //(1)
explicit monotonic_buffer_resource(std::pmr::memory_resource* upstream); //(2)
explicit monotonic_buffer_resource(std::size_t initial_size); //(3)
monotonic_buffer_resource(std::size_t initial_size, std::pmr::memory_resource* upstream); //(4)
monotonic_buffer_resource(void* buffer, std::size_t buffer_size); //(5)
monotonic_buffer_resource(void* buffer, std::size_t buffer_size, std::pmr::memory_resource* upstream);//(6)
monotonic_buffer_resource(const monotonic_buffer_resource&) = delete; //(7)
monotonic_buffer_resource能以初始缓冲区构造,若无初始缓冲,或缓冲用尽,则从构造时提供的上游分配器分配缓冲区。缓冲区的大小以几何级数增长。
比较常用的有1,2,5,6
第一个就是默认构造函数。默认构造函数会使用
std::pmr::get_default_resource返回的memory_resource当做上游分配器。第二个就是指定上游分配器。
- 第五个是提供一块给定内存
buffer,然后设置当前资源为buffer。buffer_size是下一块缓冲区的大小,然后使用std::pmr::get_default_resource返回的memory_resource当做上游分配器。- 当给定的内存用尽后,使用上游分配器进行内存分配。
第六个是提供一块给定内存
buffer,然后设置当前资源为buffer。buffer_size是下一块缓冲区的大小,并且指定上游分配器。- 当给定的内存用尽后,使用上游分配器进行内存分配。
do_allocate
若当前缓冲区有足够的未使用空间以适合一个拥有指定大小和对齐的块,则从当前缓冲区分配返回的块。
否则,此函数通过调用
upstream_resource()->allocate(n, m)分配新缓冲区,其中n不小于bytes与下个缓冲区大小的较大者,且m不小于alignment。它设置新缓冲区为当前缓冲区,以实现定义的增长因子(不必是整数)增加下个缓冲区大小,然后从新分配的缓冲区分配返回块。- 插一句话,这个时候就是使用
std::pmr::null_memory_resource的一个典型场景
do_deallocate
- 此函数无效应。!!!啥也不干!!!因为我们都说了它是单调递增的!!!直到销毁资源为止(对象析构或调用release)
release
通过上游 memory_resource 的
deallocate函数,按需要释放所有分配的内存。重设当前缓冲区及下个缓冲区大小为其构造时的初始值。内存被释放回上游资源,即使未对某些被分配块调用
deallocate。释放内存。注意,这是调用上游
deallocate解分配。解分配不代表调用内存中储存对象的析构函数。仅仅是把指针塞回给上游内存池。- 如果上游是
null_memory_resource,那就相当于啥也没干。同时,一般来说使用这种方式分配内存的时候,初始缓冲区一般是在栈上。如果在堆上,记得要手动回收提供的初始内存。因为这些内存资源不会帮助我们回收初始内存资源。所谓的:重设当前缓冲区及下个缓冲区大小为其构造时的初始值 的含义仅仅是把指针推回去。 - 内存被释放回上游资源,即使未对某些被分配块调用
deallocate。这句话每一个内存资源的release都有。我们下面再说。
- 如果上游是
源代码,来自
1 2 3 4 5 6 7 8 9 10 11 12 13 14
void monotonic_buffer_resource::release() { const size_t header_size = sizeof(__monotonic_buffer_header); __original_.__used_ = 0; while (__original_.__next_ != nullptr) { __monotonic_buffer_header *header = __original_.__next_; __monotonic_buffer_header *next_header = header->__next_; size_t aligned_capacity = header->__capacity_ + header_size; __res_->deallocate(header->__start_, aligned_capacity, header->__alignment_); //调用上游分配器的deallocate __original_.__next_ = next_header; } } //除了那一行以外其他的就是回推指针。
- 析构函数
- 调用
this->release()来解分配此资源拥有的所有内存。- 所以说针对这几种内存资源,压根没必要
release。因为已经应用了RAII特性。
- 所以说针对这几种内存资源,压根没必要
- 调用
测试
我们下面的测试是单纯的测试内存分配器。并没有结合容器。但是效果是一致的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
class MyClass {
public:
MyClass(int val = 0) : m_val(new int(val)) {
std::cout << "MyClass constructed with value: " << val << std::endl;
}
~MyClass() {
std::cout << "MyClass destroyed with value: " << *m_val << std::endl;
delete m_val;
}
private:
int* m_val;
};
int main() {
char buffer[1024]; //从栈获取原始内存
std::size_t buffer_size = sizeof(buffer);
cout << "original "<<&buffer << endl; //原始内存地址
{
std::pmr::monotonic_buffer_resource buffer_resource{buffer, buffer_size, std::pmr::null_memory_resource()};
//monotonic memory resource使用栈获取的资源做为初始资源,使用null_memory_resource当做上游分配器强调内存用尽后抛出bad_alloc而不是从默认分配器分配
std::pmr::polymorphic_allocator<MyClass> allocator{ &buffer_resource }; //初始化分配器
{
MyClass* t = allocator.allocate(1); //分配1个Myclass对象 8字节
cout << &t << endl; //获取指针地址
cout << "1st alloc place "<<&*t << endl; //获取当前分配地址
allocator.construct(t, 20); //在该地址构造元素
MyClass* tt = allocator.allocate(1); //再分配1个Myclass对象 8字节
cout << &tt << endl; //获取指针地址
cout << "2nd alloc place "<<&*tt << endl; //获取当前分配地址
allocator.construct(tt, 30); //在该地址构造元素
//------------如果不destroy会泄露。因为deallocate解分配并不会调用元素的析构函数---------
allocator.destroy(t); //析构元素
allocator.destroy(tt); //析构元素
//----------使用release重置内存,把首地址推回分配起始地址(原始内存首地址)
buffer_resource.release();
MyClass* ttt = allocator.allocate(1); //再次分配1个Myclass对象
cout << &ttt << endl;//获取指针地址
cout << "3rd alloc place "<<&*ttt << endl; //获取当前分配地址
allocator.construct(ttt, 40); //在该地址构造元素
allocator.destroy(ttt);
}
}
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
original 0x7ffe4ff6eb90 起始地址
0x7ffe4ff6eb30
1st alloc place 0x7ffe4ff6eb90 起始地址和第一次分配地址一致
MyClass constructed with value: 20
0x7ffe4ff6eb38
2nd alloc place 0x7ffe4ff6eb98 第二次分配在第一次分配上+8
MyClass constructed with value: 30
MyClass destroyed with value: 20
MyClass destroyed with value: 30
0x7ffe4ff6eb40
3rd alloc place 0x7ffe4ff6eb90 release后指针推回至原生内存起始位置。
MyClass constructed with value: 40
MyClass destroyed with value: 40
- 我们从上面的测试能看到
- 如果不
destroy会导致内存泄露。因为deallocate解分配并不会调用内存中元素的析构函数,仅仅是回推指针。 - 如果不需要重复使用内存,则无需手动调用
release。RAII特性会让buffer_resource内存资源在析构时自动调用release - 注意:我们是使用
allocator进行内存分配,对象构造和对象摧毁。
- 如果不
- 假设我们的初始内存是从堆中获取的,则必须要手动释放。因为分配器和内存资源并不保有底层原始内存
1
2
3
4
5
6
7
8
9
10
char* buffer = new char[1024]; //堆内存。
std::size_t buffer_size = 1024;
{
std::pmr::monotonic_buffer_resource buffer_resource{buffer, buffer_size, std::pmr::null_memory_resource()};
std::pmr::polymorphic_allocator<MyClass> allocator{ &buffer_resource };
{
//...
}
}
delete[] buffer; //回收内存
分析一下release过程。无论是析构还是手动调用release,都有两个步骤:第一步是调用上游的memory_resource 的 deallocate 函数。第二步是重设当前缓冲区及下个缓冲区大小为其构造时的初始值。当前我们上游是null_memory_resource,deallocate函数无效果。所以仅仅是把当前缓冲区及下个缓冲区大小为其构造时的初始值。(推回指针)
std::pmr::unsynchronized_pool_resource / std::pmr::synchronized_pool_resource
这是一种池化的内存资源:
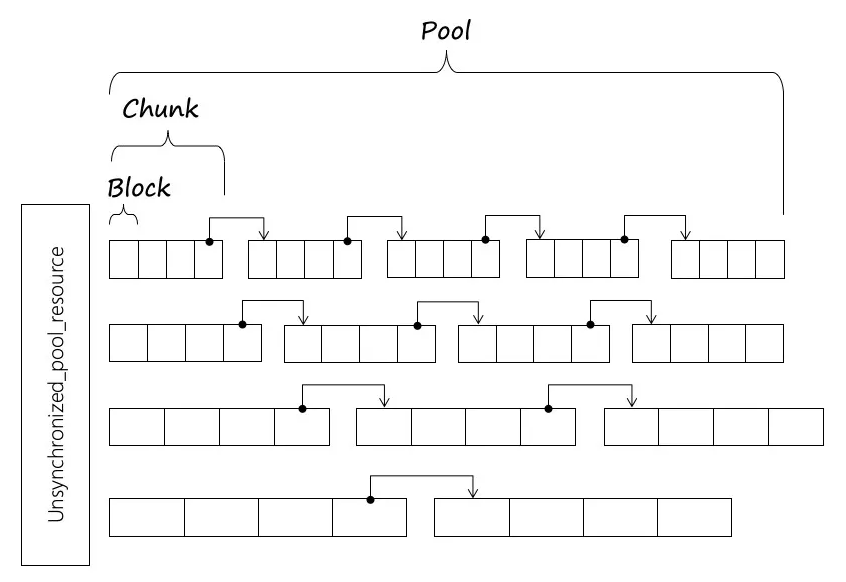
具体应该不用赘述。侯捷老师的课讲标准分配器的时候就提到过大概的样子。
- 这俩唯一的区别是一个线程安全,一个线程不安全。线程安全的性能贼差尽量别用。
- 它占有被分配内存并在析构时释放它,即使
deallocate未被对于某些被分配块调用。
- 这个释放是指调用
release。release中调用上游 memory_resource 的deallocate函数,释放所有此资源所占有的内存。- 它由供应不同块大小请求的池的汇集组成。每个池管理之后被分入一致大小的大块的汇集。
- 对
do_allocate的调用被派发到供应适应请求大小的最小块的池。- 在池中耗尽内存,会导致该池从上游分配器分配额外的内存大块,以填满池。获取的大块大小以几何级数增加。
- 请求超出最大的块大小的分配,由上游分配器直接供应。
- 最大的块大小和大块大小的最大值可通过传递
std::pmr::pool_options结构体给其构造函数调节。
- 构造函数
1
2
3
4
5
unsynchronized_pool_resource(); //(1)
explicit unsynchronized_pool_resource(std::pmr::memory_resource* upstream); //(2)
explicit unsynchronized_pool_resource(const std::pmr::pool_options& opts); //(3)
unsynchronized_pool_resource(const std::pmr::pool_options& opts,std::pmr::memory_resource* upstream); //(4)
unsynchronized_pool_resource(const unsynchronized_pool_resource&) = delete; //(5)
有没有发现这一组构造函数和monotonic_buffer_resource有个非常明显的差别?也就是我们不再有像monotonic_buffer_resource第5和第6个构造函数那种提供初始原始内存的构造函数了。也就是说这两个池化内存资源必须从上游分配器获取资源。
如果依旧想要从栈分配,则可以先使用栈分配monotonic_buffer_resource,然后让它成为当前池化内存的上游分配器。
第一个构造函数就是使用默认的池化选项和默认的上游分配器。
第二,三,四个分别指定上游分配器,池化选项和二者皆指定。
do_allocate
若为
bytes大小的块所选的池不足以满足来自其内部数据结构的请求,则调用上游 memory_resources 上的allocate()以获得内存。若请求的大小大于最大的池所能处理者,则通过调用上游 memory_resources 上的
allocate()分配内存。
do_deallocate
将在
p的内存返还到池。此操作是否或在何种场合下导致对上游 memory_resource 上的deallocate()调用是未指定的。- 在对池化资源使用
do_deallocate的时候一定要仅返回内存至内存池,而不是调用上游分配器的deallocate直接回收。一定要格外注意。但是这一点平时普通人不需要过多操心
release
需要时,通过调用上游 memory_resource 的
deallocate函数,释放所有此资源所占有的内存。即使未对某些被分配块调用
deallocate,资源也被返还给上游 memory_resource 。- 这就是
release和deallocate的最大区别。deallocate是返还内存到内存池。而release是释放(返还)整个内存池全部的内存至上游分配器。因为是调用上游分配器的deallocate。 - 不知道这玩意是只释放内存还是摧毁整个池。标准库没说
析构函数
通过调用
this->release()释放此资源所拥有的所有内存。- 和其他的一样。
我们捋一下针对池化内存release的可能情况
- 第一种情况:
- 如果
sync或unsync的上游分配器是monotonic,sync或unsync调用release会使上游的monotonic调用deallocate。但是monotonic的deallocate不做任何事情。所以分配出去的内存无法被monotonic回收。只能单调递增直到monotonic的release被调用
- 如果
- 第二种情况:
- 如果
sync或unsync的上游是new_delete_resource,则sync/unsync调用release会使得上游的new_delete_resource调用其deallocate,我们说过它的deallocate是全局::operator delete。
- 如果
在已经release的内存资源上再次调用allocate是否是UB?
标准库没有明确说明。例子如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
std::pmr::monotonic_buffer_resource buffer_resource{std::pmr::new_delete_resource()}; //最外层monotonic通过new_delete获取原始内存。
std::pmr::unsynchronized_pool_resource midlevel{&buffer_resource}; //第一层unsync池化
std::pmr::unsynchronized_pool_resource un_sync{&midlevel}; //第二层unsync 池化
std::pmr::polymorphic_allocator<MyClass> allocator{&un_sync};
{
MyClass* t = allocator.allocate(1);
cout << &t << endl;
cout << "1st alloc place "<<&*t << endl;
allocator.construct(t, 20);
MyClass* tt = allocator.allocate(1);
cout << &tt << endl;
cout << "2nd alloc place "<<&*tt << endl;
allocator.construct(tt, 30);
allocator.destroy(t);
allocator.destroy(tt);
un_sync.release(); //release内存资源。此行为会导致第一层unsync调用deallocate。回收已分配的内存到第一层unsync的内存池
MyClass* ttt = allocator.allocate(1); //第二层unsync再次allocate
cout << &ttt << endl;
cout << "3rd alloc place "<<&*ttt << endl;
allocator.construct(ttt, 40);
allocator.destroy(ttt);
}
1
2
3
4
5
6
7
8
9
10
11
12
13
0x7ffe69b80ed8
1st alloc place 0x559e13abbc00 //第一次分配
MyClass constructed with value: 20
0x7ffe69b80ee0
2nd alloc place 0x559e13abbc08 //第二次分配
MyClass constructed with value: 30
MyClass destroyed with value: 20
MyClass destroyed with value: 30
释放
0x7ffe69b80ee8
3rd alloc place 0x559e13abbc00 //第三次分配。地址同第一次。
MyClass constructed with value: 40
MyClass destroyed with value: 40
经过我的测试,似乎是会重建内存池。
已提问,目前无人回答
std::pmr::null_memory_resource
很多人很奇怪?为啥要弄个空的呢?答案很简单。我们提到了,内存资源可以成为链条。如果某一个分配资源不够了,我们不希望它去默认的上游分配器去获取内存,就可以把这个分配器做为那个分配器的上游分配器。
allocate
- 其
allocate()函数始终抛出 std::bad_alloc;
- 其
deallocate
- 其
deallocate()函数无效果;
- 其
分配器 allocator
我们提到过。分配器是一种对内存资源的包装
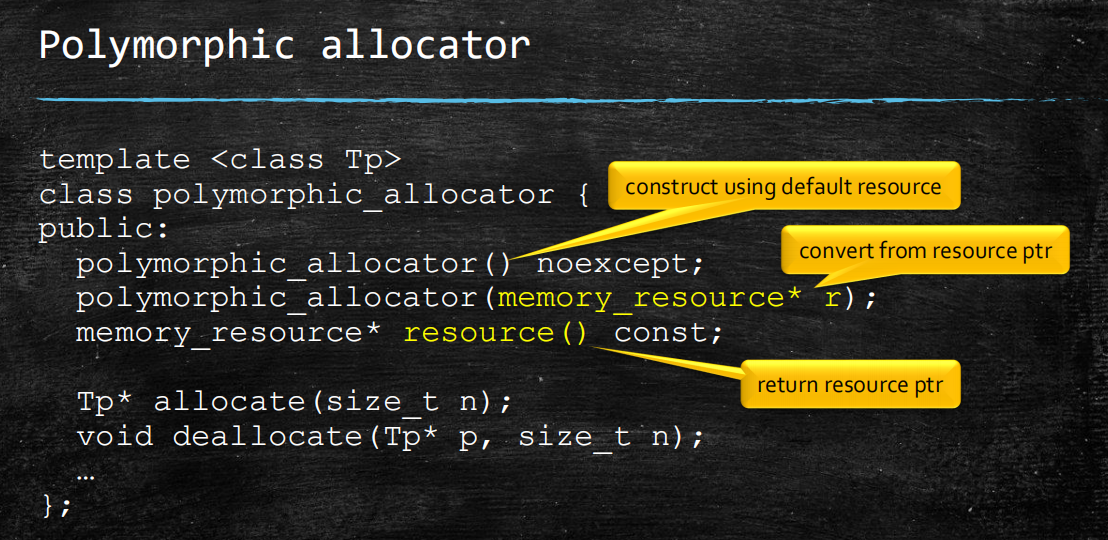

第二个转换构造函数非常有用。它的作用是我们可以直接把
memory_resource传入任何需要polymorphic_allocator的地方。比如直接传入pmr::容器。构造函数
1
2
3
4
5
polymorphic_allocator() noexcept; //(1)
polymorphic_allocator( const polymorphic_allocator& other ) = default; //(2)
template< class U >
polymorphic_allocator( const polymorphic_allocator<U>& other ) noexcept; //(3) 关键的构造函数模板。
polymorphic_allocator( memory_resource* r); //(4) 转换构造
第一个:默认构造函数会默认构造一个以默认值(通常为new_delete_resource)为内存资源的分配器
第二个:拷贝构造
第三个:构造函数模板。下面的模板参数以及正确转换全都靠它
第四个:是上文提到的转换构造。
allocate
用底层的 memory_resource 分配
n个T类型对象的存储。等价于
return static_cast<T*>(resource()->allocate(n * sizeof(T), alignof(T)));。由于我们提过,分配器是一种内存资源的wrapper。所以分配器调用的
allocate就相当于对内存资源调用allocate。- 格外要注意的是,内存资源返回的内存是
void*。而分配器返回的内存是对应类型的。
deallocate
解分配
p所指向的存储,它必须通过与*resource()比较等于的(相等的)std::pmr::memory_resourcex使用x.allocate(n * sizeof(T), alignof(T))分配。等价于
this->resource()->deallocate(p, n * sizeof(T), alignof(T));- 还是调用了底层内存资源的
deallocate
construct
这玩意有一堆重载。主要是看第一个:
1 2
template < class U, class... Args > void construct( U* p, Args&&... args ); //(1)
在
p所指的,分配但未初始化的存储上,以提供的构造函数参数构造一个对象。若对象自身拥有使用分配器的类型,或它是std::pair,则传递this->resource()给被构造的对象。以使用分配器构造的手段在
p所指示的未初始化内存位置,以*this为分配器创建给定类型U的对象。
说白了就如果提供了分配器,就使用提供的分配器构造。
destroy
销毁
p所指向的对象,如同以调用p->~U()- 所以我们强调了,
dellocate解分配不调用内存位置上元素的析构函数。摧毁元素和回收内存是两个独立动作。
polymorphic_allocator 的模板参数
有一些讲座说我们应该始终以std::byte为polymorphic_allocator 的模板参数。但是直觉来说,应该以元素类型为模板参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
class MyClass {
public:
MyClass(int val = 0) : m_val(new int(val)) {
std::cout << "MyClass constructed with value: " << val << std::endl;
}
~MyClass() {
std::cout << "MyClass destroyed with value: " << *m_val << std::endl;
delete m_val;
}
private:
int* m_val;
};
int main() {
char buffer[1024];
std::size_t buffer_size = 1024;
{
std::pmr::monotonic_buffer_resource buffer_resource{buffer, buffer_size, std::pmr::null_memory_resource()};
//monotonic内存资源从已分配栈内存做为初始资源。并使用null做为上游资源
std::pmr::polymorphic_allocator<MyClass> allocator{ &buffer_resource }; //版本1,分配器参数为元素类型:MyClass
std::pmr::polymorphic_allocator<byte> allocator{ &buffer_resource }; //版本2,分配器参数为byte。
{
std::pmr::vector<MyClass> vec(allocator); //使用分配器初始化pmr vector
vec.reserve(1);//预留一个空间
vec.emplace_back(1);//原地构造一个对象
}
}
return 0;
}
1
2
MyClass constructed with value: 1
MyClass destroyed with value: 1
- 注意关于monotonic内存资源和winkout的联系会在下一节讲。但是这里必须要提到一点,winkout和使用何种内存资源之间无任何联系。
两种分配器参数都可以正常工作。那么是什么原因呢?我们看一下这一行代码:
1
2
std::pmr::polymorphic_allocator<MyClass> allocator{ &buffer_resource };
std::pmr::vector<MyClass> vec(allocator); //此行展开
这一行代码展开后的样子是这样的:
1
std::vector<MyClass, std::pmr::polymorphic_allocator<MyClass>> vec = std::vector<MyClass, std::pmr::polymorphic_allocator<MyClass>>(allocator);
首先记住一点:allocator的模板参数一定会被推导为元素类型。因为别忘了上面提到的pmr是别名模板,元素类型是T,allocator的类型是根据T来的。
其次,我们发现如果分配器类型和元素类型一致,则顺利构造。左右两侧无区别。
但是如果我们换成byte呢?
1
2
std::pmr::polymorphic_allocator<byte> allocator{ &buffer_resource };
std::pmr::vector<MyClass> vec(allocator); //此行展开
这一行展开后是这样的:
1
std::vector<MyClass, std::pmr::polymorphic_allocator<MyClass>> vec = std::vector<MyClass, std::pmr::polymorphic_allocator<MyClass>>(std::pmr::polymorphic_allocator<MyClass>(allocator));
再次重申,allocator的模板参数一定会被推导为元素类型。同时,右侧括号内传入的分配器发生了隐式类型转换。调用的正是我们在分配器中提到的第三个构造函数。
所以理论上讲,此时行为都是一致的。而分配器本身的构造并不会造成性能的过多损失。但是有一点要注意,隐式类型转换后,传入的分配器是那个转换后的临时对象。所以现在vector内部的分配器和外面传入的allocator其实是两个独立对象了。一定要注意。最好还是使用和元素一样类型的分配器。
我的提问
分配器种类,分配器绑定方式和析构的组合
目前为止,分配器绑定方式可以分为两种
- 类型参数(模板参数)
- 继承自抽象基类,比如:
![QQ截图20230309225735]()
注意这里不是继承自
std::allocator。一般也不应该这样做。原因见这里![QQ截图20230310032548]()


目前为止,分配器内存来源可以分为这么几种
- 默认全局分配器(std::allocator)
- 绑定方式一定是类型参数
- New_Delete_Allocator
- 和默认全局分配器原理一致,但是绑定方式一定是继承自抽象基类
- 多态内存资源
- 如
monotonic_buffer_resource,unsync/synchronized_pool_resource等
- 如
析构方式又可以分为两种:
- 常规析构
- wink-out
所以,一共我们可以得到这么多种搭配组合
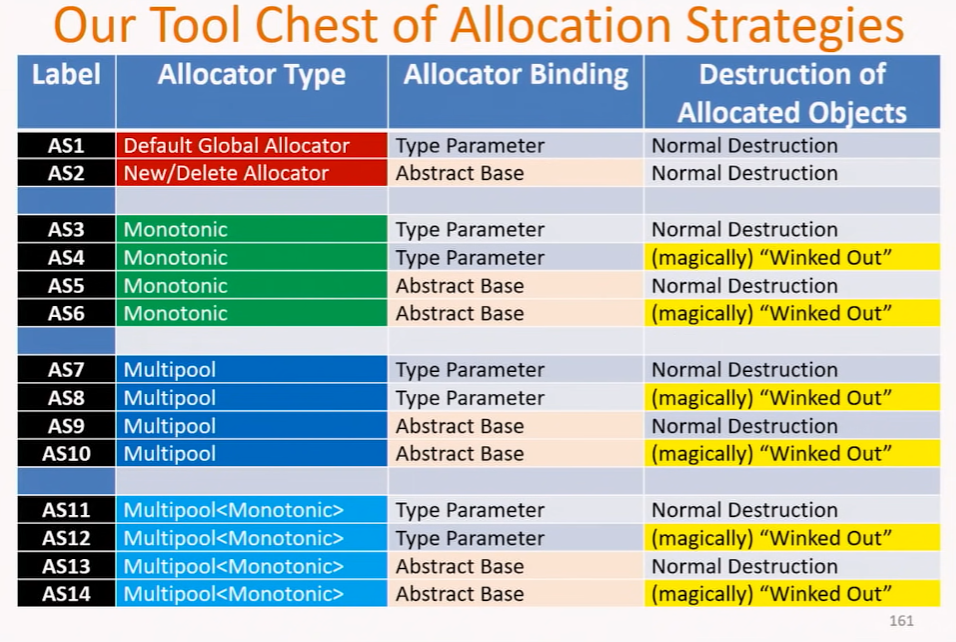
wink-out 和 常规析构
首先注意,wink-out适用于任何内存资源。我们还记得容器分配构造的四个步骤:分配空间,构造对象,析构对象,解分配空间。
wink-out就是不析构,直接解分配。所以使用wink-out的时候一定要注意,如果内存区域的元素是含有额外资源的,则不可以winkout。会导致内存泄漏。
- 我们看一下常规析构:

一切都很正常。标准的四个步骤。
- 我们再来看一下所谓的winked-out

核心意思就是我们不再需要析构和解分配两个步骤
不需要析构非常好理解,因为如果某些对象没有保有其他资源,也就是析构函数是trivial的时候,调用析构是没有意义的。所以可以不调用这些析构。
不需要deallocate如何理解呢?一般情况下,通常只针对monotonic_buffer_resource使用winkout。因为它的deallocate是无作用。只有在析构的时候才会把资源交还给上游分配器。当然了,标准库提供的所有内存资源都符合RAII特性,在析构的时候都会把内存交还给上游分配器。所以这里不使用deallocate也是可以的。一定要记住,所有解分配deallocate都不会调用元素的析构函数。所以要注意内存泄漏问题,使用这个技巧之前一定要清楚自己在做什么。
我们来看个特殊例子,因为有时候容易错误理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
int main() {
char buffer[1024];
std::size_t buffer_size = 1024;
{
std::pmr::monotonic_buffer_resource buffer_resource{buffer, buffer_size, std::pmr::null_memory_resource()};
//外层monotonic原始内存
std::pmr::polymorphic_allocator<MyClass> allocator{ &buffer_resource }; //分配器
{
std::pmr::vector<MyClass> t(allocator); //分配器传入pmr vector
t.reserve(1); //预留1个位置
t.emplace_back(20); //原地构造元素
}
}
return 0;
}
1
2
MyClass constructed with value: 20
MyClass destroyed with value: 20
奇怪?明明我们没有手动对内存资源进行操作,怎么会正确析构呢?因为这是pmr::vector帮助我们做的。因为它毕竟还是vector。还是会在vector被销毁的时候帮助我们对元素进行析构。
std::vector<T,Allocator>::~vector:调用元素的析构函数,然后解分配所用的存储。
自定义分配器的相等比较
参考来自这里
[
operator ==(a1, a2)] returns true only if the storage allocated by the allocatora1can be deallocated througha2. Establishes reflexive, symmetric, and transitive relationship. Does not throw exceptions.operator ==(a1, a2)仅当分配器a1分配的存储可以通过分配器a2释放时才返回 true。建立了自反、对称和传递关系。不抛出异常。
一般来说,如果两个分配器相等,那么在移动一个容器至另一个容器的时候可以直接交换指针,在第二个容器重用第一个容器的内存。如果分配器不相等,则必须要在第二个容器中重新分配内存,然后复制每一个元素,然后释放第一个容器。
针对如何实现内存资源,和如何实现使用多态内存分配器的容器,可以看看下面参考资料的内容
参考资料
CppCon 2017针对如何实现内存资源和自己的使用分配器的容器
CppCon 2019针对如何实现带有多态内存分配器的类和容器类
memory_source的LLVM源代码 和 LLVM最终源代码
反射
反射的核心目的是根据一个类名来生成对应的实例。也就是如何通过类名称字符串来生成类的对象。比如有一个类ClassA,那么如何通过类名称字符串ClassA创建类的对象呢?比如
1
2
3
4
5
6
7
8
9
10
11
12
class Person {
public:
virtual void show() = 0;
}
class Allen : public Person {
virtual void show() {
std::cout << "Hello, I'm Allen!" << std::endl;
}
}
std::string className = /*从配置文件中读取*/
Person *p = getNewInstance<Person>(className);
但是C++不像java或者C#一样提供这种机制。但是我们可以通过工厂模式+单例模式+映射器+宏来实现一个反射
一般来说,实现反射需要如下几个组件(步骤):
- 我们的业务代码,也就是需要被反射的类。这个类通常继承自一个反射基类如
ReflectObject。- 这个步骤的目的是为抽象对象工厂类
ObjectFactory提供统一的接口
- 这个步骤的目的是为抽象对象工厂类
- 一个抽象对象工厂类
ObjectFactory - 具体对象工厂类
- 一般情况下使用宏
- 反射器
- 通常情况下,反射器可以是单例。
- 反射器的核心是建立字符串(标识符)到回调函数的映射。然后通过一个容器储存。
- 在我们即将展示的例子中,这个回调函数是一个具体对象工厂的指针。然后我们会通过这个具体对象工厂来创建具体对象。
下面我们看代码
- 反射基类
ReflectObject。所有实现反射的类都需要继承自它。
1
2
3
4
class ReflectObject {
public:
virtual ~ReflectObject(){}
};
- 具体的被反射类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
class Person : public ReflectObject{
public:
Person(){
std::cout << "Person()" << std::endl;
}
virtual ~Person(){
std::cout << "~Person()" << std::endl;
}
virtual void show(){
std::cout << "Hello, I'm person" << std::endl;
}
};
class Miku : public Person{
public:
Miku(){
std::cout << "Miku()" << std::endl;
}
virtual ~Miku(){
std::cout << "~Miku()" << std::endl;
}
virtual void show(){
std::cout << "Hello, I'm Miku" << std::endl;
}
};
class Animal : public ReflectObject{
public:
Animal(){
std::cout << "Animal()" << std::endl;
}
virtual ~Animal(){
std::cout << "~Animal()" << std::endl;
}
virtual void bark(){
std::cout << "animal bark" << std::endl;
}
};
- 抽象对象工厂
ObjectFactory
1
2
3
4
5
6
class ObjectFactory {
public:
ObjectFactory(){ std::cout << "ObjectFactory()" << std::endl; }
virtual ~ObjectFactory(){ std::cout << "~ObjectFactory()" << std::endl; }
virtual ReflectObject* newInstance() = 0; //提供统一的纯虚函数,返回反射基类的指针。也就是说,所有的具体对象工厂类都要通过这个函数返回具体对象并被转化为反射基类的指针
};
- 反射器Reflector
- 此处我们以单例模式呈现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
class Reflector
{
public:
static Reflector& reflector(); //mayer’s单例模式经典方法
Reflector(const Reflector&) = delete; //禁止拷贝构造
Reflector& operator= (const Reflector&) = delete; //禁止拷贝赋值
void registerFactory(const std::string& className, ObjectFactory* function); //注册至映射map
ReflectObject* getNewInstance(const std::string& className); //在映射器内查找类名对应的对象工厂指针。然后通过该指针调用该对象工厂对应的创建实例的函数。此处是newInstance
private:
Reflector(); //私有构造
~Reflector(); //私有析构
std::map<std::string, ObjectFactory*> objectFactories; //映射map。key是类名,value是该类的对象工厂指针。
};
Reflector::Reflector(){
std::cout << "Reflector constructor" << std::endl;
}
Reflector::~Reflector(){
//析构函数中释放资源。在当前业务中,反射器的映射map负责保有所有的具体对象工厂指针。所以需要负责释放。
std::map<std::string, ObjectFactory*>::iterator it = objectFactories.begin();
for (; it != objectFactories.end();++it){
delete it->second;
}
objectFactories.clear();
}
void Reflector::registerFactory(const std::string& className, ObjectFactory *of){
//注册函数。首先在map中查找是否有对应的键值,如果没有则创建一个 名称-对象工厂指针 的映射
std::map<std::string, ObjectFactory*>::iterator it = objectFactories.find(className);
if (it != objectFactories.end()) {
std::cout << "该类已经存在" << std::endl;
}
else {
objectFactories[className] = of;
}
}
ReflectObject* Reflector::getNewInstance(const std::string& className){
//通过类名获取对象工厂的指针,然后调用对象工厂的创建具体实例的方法并返回。
std::map<std::string, ObjectFactory*>::iterator it = objectFactories.find(className);
if (it != objectFactories.end()) {
ObjectFactory *of = it->second;
return of->newInstance(); //如果找到了。那么调用这个对象工厂指针的创建具体实例的方法。
}
return NULL;
}
Reflector& Reflector::reflector() {
//经典的mayer‘s单例模式
std::cout <<"get reflector reference " << std::endl;
static Reflector reflector;
return reflector;
}
/*
这是个非常特殊的地方。我们有一个全局函数模板。外部调用的是这个函数。
这个函数是我们的反射器的包装。传入一个具体被映射类名字,同时将其做为模板参数。
该函数内部会先获取单例的反射器的实例,然后通过该实例调用内部的getNewInstance成员函数。
由于调用返回的是ReflectObject*指针,但是通常我们等号左侧调用的时候会是当前类型或者是实际父类,所以需要强转一下。
*/
template<typename T, typename... Args>
T* getNewInstance(const std::string& className) {
return static_cast<T*>(Reflector::reflector().getNewInstance(className));
}
- 具体对象工厂
1
2
3
4
5
6
7
8
9
class ObjectFactory_Miku: public ObjectFactory{ //继承自反射基类
public:
ObjectFactory_Miku(){
std::cout <<"ObjectFactory_Miku() " << std::endl;
}
ReflectObject* newInstance(){ //实现创建实例的接口。
return new Miku();
};
};
- 主函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int main(){
Reflector::reflector().registerFactory("Miku", new ObjectFactory_Miku());
Person *allen = getNewInstance<Miku>("Miku");
allen->show();
delete allen;
return 0;
}
/*
get reflector reference 获取反射器实例
Reflector constructor 反射器创建且只创建一次
ObjectFactory() new的对象工厂类的父类部分
ObjectFactory_Miku() new的对象工厂类子类部分
---以上是第一行的注册部分------
get reflector reference 第二行的getnewinstance内部调用的获取反射器实例。
Person() 反射器实例调用的getnewinstance找到的对象工厂指针调用的newInstance导致的Miku类的父类部分创建
Miku() //miku类本类创建
Hello, I'm Miku //show 业务代码
~Miku()
~Person()
~ObjectFactory()
*/
这时候我们发现,写对象工厂类和注册比较麻烦,我们可以用一个宏来实现
1
2
3
4
5
6
7
8
9
10
#define REFLECT(name)\
class ObjectFactory_##name : public ObjectFactory{\
public:\
ObjectFactory_##name(){ std::cout << "ObjectFactory_" << #name << "()" << std::endl; }\
virtual ~ObjectFactory_##name(){ std::cout << "~ObjectFactory_" << #name << "()" << std::endl; }\
ReflectObject* newInstance() {\
return new name(); \
}\
}; \
Reflector::reflector().registerFactory(#name, new ObjectFactory_##name());
宏的部分语法我们在杂记4中提到过,这里不赘述
这样我们可以直接REFLECT(Animal)就完成了创建对象工厂和注册
也可以考虑使用一个额外的类和全局对象的方式替换最后一行
1
2
3
4
5
6
7
class Register_##name{\
public:\
Register_##name(){\
Reflector::reflector().registerFactory(#name, new ObjectFactory_##name()); \
}\
};\
Register_##name register_##name;
我目前不清楚有什么好处,可能和链接有关?因为全局对象的构造函数在main前执行。
上面的代码我们梳理了最基本的反射原理和实现,参考自这里。现在有一个问题。如果我的类需要使用有参构造函数怎么办?可以使用可变模板参数。但是导致复杂非常多。我找到了Nebula的一种实现方式,参考自这里,我们一起分析一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
#include <string>
#include <iostream>
#include <typeinfo>
#include <memory>
#include <unordered_map>
#include <functional>
#include <cxxabi.h>
namespace neb{
class Actor{ //*理解为反射基类 reflectobject
public:
Actor(){std::cout << "Actor construct" << std::endl;}
virtual ~Actor(){};
virtual void Say()
{
std::cout << "Actor" << std::endl;
}
};
template<typename ...Targs>
class ActorFactory{ //*理解为反射器类。此处是单例模式
public:
//typedef Actor* (*ActorCreateFunction)();
//std::function< Actor*(Targs...args) > pp;
static ActorFactory* Instance(){ //! 线程不安全的单例模式。获取反射器指针。
std::cout << "static ActorFactory* Instance()" << std::endl;
if (nullptr == m_pActorFactory){
m_pActorFactory = new ActorFactory();
}
return(m_pActorFactory);
}
virtual ~ActorFactory(){};
//Lambda: static std::string ReadTypeName(const char * name)
//bool Regist(const std::string& strTypeName, ActorCreateFunction pFunc)
//bool Regist(const std::string& strTypeName, std::function<Actor*()> pFunc)
/*
&将“实例创建方法(对象工厂的CreateObject方法)”注册到ActorFactory,注册的同时赋予这个方法一个名字“类名”,后续可以通过“类名”获得该类的“实例创建方法”。
&这个实例创建方法实质上是个函数指针,在C++11里std::function的可读性比函数指针更好,所以用了std::function。
*/
bool Regist(const std::string& strTypeName, std::function<Actor*(Targs&&... args)> pFunc){
std::cout << "bool ActorFactory::Regist(const std::string& strTypeName, std::function<Actor*(Targs... args)> pFunc)" << std::endl;
if (nullptr == pFunc){
return(false);
}
std::string strRealTypeName = strTypeName;
//[&strTypeName, &strRealTypeName]{int iPos = strTypeName.rfind(' '); strRealTypeName = std::move(strTypeName.substr(iPos+1, strTypeName.length() - (iPos + 1)));};
bool bReg = m_mapCreateFunction.insert(std::make_pair(strRealTypeName, pFunc)).second; // 创建键值对
std::cout << "m_mapCreateFunction.size() =" << m_mapCreateFunction.size() << std::endl;
return(bReg);
}
//& 传入“类名”和参数创建类实例,方法内部通过“类名”从m_mapCreateFunction获得了对应的“实例创建方法(DynamicCreator的CreateObject方法)”完成实例创建操作。
Actor* Create(const std::string& strTypeName, Targs&&... args){
std::cout << "Actor* ActorFactory::Create(const std::string& strTypeName, Targs... args)" << std::endl;
auto iter = m_mapCreateFunction.find(strTypeName);
if (iter == m_mapCreateFunction.end()){
return(nullptr);
}
else{
//return(iter->second());
return(iter->second(std::forward<Targs>(args)...)); //把参数完美转发至实例创建方法。
}
}
private:
ActorFactory(){std::cout << "ActorFactory construct" << std::endl;}; //私有构造,经典的单例模式
static ActorFactory<Targs...>* m_pActorFactory; //静态的单例的本类指针
std::unordered_map<std::string, std::function<Actor*(Targs&&...)> > m_mapCreateFunction; //存贮映射的数据结构。第二个std::function对象统一存储返回类型是Actor*,入参可变的函数。
};
template<typename ...Targs>
ActorFactory<Targs...>* ActorFactory<Targs...>::m_pActorFactory = nullptr; //静态的单例的本类指针的类外定义并初始化
template<typename T, typename ...Targs>
class DynamicCreator{ //*理解为对象工厂
/*
我们写自己的业务类的时候,不仅要继承自反射基类,也要继承自这个类。
继承自这个类的第一个参数就是我们的类名。会通过mangled方法获取到这个字符串
然后把这个字符串和这个类的CreateObject函数放进去
*/
public:
struct Register{
Register(){
std::cout << "DynamicCreator.Register construct" << std::endl;
std::puts(__PRETTY_FUNCTION__);
char* szDemangleName = nullptr;
std::string strTypeName; //这个就是类名
#ifdef __GNUC__
szDemangleName = abi::__cxa_demangle(typeid(T).name(), nullptr, nullptr, nullptr);
#else
//in this format?: szDemangleName = typeid(T).name();
szDemangleName = abi::__cxa_demangle(typeid(T).name(), nullptr, nullptr, nullptr);
#endif
if (nullptr != szDemangleName){
strTypeName = szDemangleName;
free(szDemangleName);
}
std::cout << strTypeName << std::endl;
ActorFactory<Targs...>::Instance()->Regist(strTypeName, CreateObject); //通过反射器类实例把类名和创建函数放进去。
}
inline void do_nothing()const { }; //!注意这个do_nothing。
};
DynamicCreator(){
std::puts(__PRETTY_FUNCTION__);
std::cout << "DynamicCreator construct" << std::endl;
m_oRegister.do_nothing(); //!这里的目的是使用一次我们嵌套类的static对象。这样的话编译器不会优化掉嵌套类静态对象的构造。尤其是分离编译的时候,可能会发生链接错误。
}
virtual ~DynamicCreator(){m_oRegister.do_nothing();}; //!这里我就不知道为什么了
static T* CreateObject(Targs&&... args){ //这个实例创建函数很有意思。别看它返回的是T*,但是由于我们所有的业务代码具体类都需要继承自反射基类。所以说T*是子类指针,而反射器存储的是Actor*父类指针。很自然的多态存储。
std::cout << "static Actor* DynamicCreator::CreateObject(Targs... args)" << std::endl;
return new T(std::forward<Targs>(args)...); //一旦调用这个函数,就执行这个new。把传进来的参数再次完美转发至对象类的构造函数。
}
virtual void Say(){
std::cout << "DynamicCreator say" << std::endl;
}
static Register m_oRegister; //这里必须要是静态的。注意这是静态成员变量,不是静态局部变量。因为我们把注册的过程放到了Register的构造函数中。细节下面再说。
};
template<typename T, typename ...Targs>
typename DynamicCreator<T, Targs...>::Register DynamicCreator<T, Targs...>::m_oRegister; //成员static变量的类外定义并默认初始化。这一行非常关键。注意这是静态成员变量,不是静态局部变量。
//下面开始是业务类。第一个是继承自反射基类,然后继承自对象工厂类。对象工厂类第一个模板参数是本类类型,然后依次是构造函数参数类型。
class Cmd: public Actor, public DynamicCreator<Cmd>{
public:
Cmd(){std::cout << "Create Cmd " << std::endl;}
virtual void Say(){
std::cout << "I am Cmd" << std::endl;
}
};
class Step: public Actor, DynamicCreator<Step, std::string, int>{
public:
Step(const std::string& strType, int iSeq){std::cout << "Create Step " << strType << " with seq " << iSeq << std::endl;}
virtual void Say(){
std::cout << "I am Step" << std::endl;
}
};
struct miku:public Actor, DynamicCreator<miku, int, int>{
miku(int x, int y){
std::cout <<"miku" << x << y << std::endl;
}
};
class Worker{
public:
template<typename ...Targs>
Actor* CreateActor(const std::string& strTypeName, Targs&&... args){
Actor* p = ActorFactory<Targs...>::Instance()->Create(strTypeName, std::forward<Targs>(args)...);
return(p);
}
};
}
int main()
{
neb::Worker W;
std::cout << "----------------------------------------------------------------------" << std::endl;
neb::Actor* p1 = W.CreateActor(std::string("neb::Cmd"));
p1->Say();
std::cout << "----------------------------------------------------------------------" << std::endl;
neb::Actor* p2 = W.CreateActor(std::string("neb::Step"), std::string("neb::Step"), 1002);
p2->Say();
std::cout << "----------------------------------------------------------------------" << std::endl;
neb::Actor* p3 = W.CreateActor(std::string("neb::miku"),2,3);
p3->Say();
return(0);
}
有一些具体的代码内容已经在注释说过了。我们一起看一下执行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
DynamicCreator.Register construct //静态成员变量类外定义导致的默认初始化。
neb::DynamicCreator<T, Targs>::Register::Register() [with T = neb::Cmd; Targs = {}] //为了好看打出来的
neb::Cmd //strTypeName也就是拿到的类名
static ActorFactory* Instance()//拿到ActorFactory的实例。因为ActorFactory也是单例模式。
ActorFactory construct //构造ActorFactory。因为不同的模板参数是不同的类。所以也是三次。
bool ActorFactory::Regist(const std::string& strTypeName, std::function<Actor*(Targs... args)> pFunc) //注册
m_mapCreateFunction.size() =1 //不知道干啥的。
DynamicCreator.Register construct
neb::DynamicCreator<T, Targs>::Register::Register() [with T = neb::Step; Targs = {std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, int}]
neb::Step
static ActorFactory* Instance()
ActorFactory construct
bool ActorFactory::Regist(const std::string& strTypeName, std::function<Actor*(Targs... args)> pFunc)
m_mapCreateFunction.size() =1
DynamicCreator.Register construct
neb::DynamicCreator<T, Targs>::Register::Register() [with T = neb::miku; Targs = {int, int}]
neb::miku
static ActorFactory* Instance()
ActorFactory construct
bool ActorFactory::Regist(const std::string& strTypeName, std::function<Actor*(Targs... args)> pFunc)
m_mapCreateFunction.size() =1
上面这一部分是在执行main的第一行代码前执行的。为什么是这个顺序?
首先,我们代码的这一行
1
2
template<typename T, typename ...Targs>
typename DynamicCreator<T, Targs...>::Register DynamicCreator<T, Targs...>::m_oRegister; //成员static变量的类外定义并且被默认初始化。这一行非常关键。注意这不是静态局部变量
非常重要。首先,业务代码有三个类模板。分别继承了不同模板参数的DynamicCreator类模板。所以我们有三个不同模板参数的DynamicCreator。所以三个不同的类都有自己的m_oRegister。同时,m_oRegister不是静态局部变量,是静态成员变量。生存周期不同。所以说,我们在类外部的这个对静态成员变量的定义导致了其被默认初始化。所以我们看到有三个DynamicCreator内部的Register的默认构造函数被调用。
在Register的默认构造函数中,我们获得到了不同的T。然后通过这个T,获得到了特殊处理的类名。随后,由于ActorFactory也是类模板,所以它也是三份。自然也有三份不同的m_pActorFactory,所以也有三个ActorFactory的构造函数被调用。然后我们拿到了ActorFactory的实例,调用它的Regist注册,传入类名和一个函数CreateObject。这个函数很特殊,是一个静态的成员函数。别看它返回的是T*,但是由于我们所有的业务代码具体类都需要继承自反射基类。所以说T*是子类指针,而反射器存储的是一个返回值为Actor*(父类指针)的std::function对象。很自然的多态存储。这个函数一旦被调用,就会new。把传进来的参数再次完美转发至对象类的构造函数。
好了,下面开始看执行部分。
由于我们已经获取到了ActorFactory的实例,所以这次在调用中不再构造。然后调用Create函数。传入类名和构造函数参数。在这个函数中寻找对应类名的实例创建方法,然后完美转发参数至这个函数。进入到映射器存储的对应类的实例创建方法也就是CreateObject函数,new一个对应的对象。
这时候,我们刚刚才开始创建对象。随后,这个对象的第一基类也就是反射基类被创建。然后第二基类,也就是对象工厂基类被创建。然后是对象的子类部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
----------------------------------------------------------------------
static ActorFactory* Instance() //获取实例。由于上面已经构造过ActorFactory了,所以直接拿就可以。
Actor* ActorFactory::Create(const std::string& strTypeName, Targs... args) //正式调用create
static Actor* DynamicCreator::CreateObject(Targs... args) //调用至映射器存储的对应类的CreateObject函数,new一个对应的对象
Actor construct //对应对象的反射基类部分
neb::DynamicCreator<T, Targs>::DynamicCreator() [with T = neb::Cmd; Targs = {}]//为了好看
DynamicCreator construct //对应对象的DynamicCreator基类部分。注意这个和上面的不同。这里是基类的构造。上面执行前的是内部嵌套类静态Register对象的初始化导致的。
Create Cmd //对象子类部分
I am Cmd
----------------------------------------------------------------------
static ActorFactory* Instance()
Actor* ActorFactory::Create(const std::string& strTypeName, Targs... args)
static Actor* DynamicCreator::CreateObject(Targs... args)
Actor construct
neb::DynamicCreator<T, Targs>::DynamicCreator() [with T = neb::Step; Targs = {std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >, int}]
DynamicCreator construct
Create Step neb::Step with seq 1002
I am Step
----------------------------------------------------------------------
static ActorFactory* Instance()
Actor* ActorFactory::Create(const std::string& strTypeName, Targs... args)
static Actor* DynamicCreator::CreateObject(Targs... args)
Actor construct
neb::DynamicCreator<T, Targs>::DynamicCreator() [with T = neb::miku; Targs = {int, int}]
DynamicCreator construct
miku23
Actor
编译期静态反射,来自这里,看不懂。
动态链接的使用经验
运行时动态链接
- 首先拥有动态库源文件,如
chn_lang.cpp
1
2
3
4
5
6
#include <iostream>
extern "C"{ //必须使用extern "C"
void print_cur_language(){
std::cout << "chinese" << std::endl;
}
}
- 编译源文件
1
g++ -c -fPIC chn_lang.cpp -o chn_lang.o
- 链接为动态链接库
1
g++ -shared chn_lang.o -o libchn_lang.so
- 编写主文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include <iostream>
#include <dlfcn.h>
int main() {
void* handle = dlopen("./libchn_lang.so", RTLD_LAZY);
if (!handle) {
std::cout << "Failed to load the library: " << dlerror() << std::endl;
return 1;
}
// 从动态链接库中获取函数指针
typedef void (*ExampleFunction)();
ExampleFunction exampleFunc = (ExampleFunction) dlsym(handle, "print_cur_language");
if (!exampleFunc) {
std::cout << "Failed to load the function: " << dlerror() << std::endl;
dlclose(handle);
return 1;
}
// 调用函数
exampleFunc();
// 关闭动态链接库
dlclose(handle);
}
- 编译主文件
- 使用
g++编译器时,使用-ldl选项是为了链接libdl库,该库提供了对动态链接库(.so文件)的动态加载和符号解析的支持。
- 使用
1
g++ main.cpp -ldl -o main
运行时动态链接的好处和坏处
好处是可以自由的加载和卸载所需的动态库。坏处是有些API,比如dlsym是采用字符串来进行符号查找,所以C++这种带mangling的就会很难受。一般会使用extern "C"来强制使用C风格的API,但是这样就不能使用函数重载了。
加载时动态链接
根据我目前的学习方式,由于dlsym是采用我们拿字符串来进行符号查找,所以C++这种带mangling的就会很难受。
- 首先拥有动态库源文件,如
chn_lang.cpp
1
2
3
4
5
6
#include <iostream>
extern "C"{ //如果此处使用了extern "C", 则后面的头文件也需要使用extern "C"注明
void print_cur_language(){
std::cout << "chinese" << std::endl;
}
}
- 编译源文件
1
g++ -c -fPIC chn_lang.cpp -o chn_lang.o
- 链接为动态链接库
1
g++ -shared chn_lang.o -o libchn_lang.so
- 编写头文件
1
2
3
4
5
#ifndef LANGUAGEHEADER_H
#define LANGUAGEHEADER_H
extern "C" void print_cur_language(); //因为我们上面使用了extern "C",所以这里也需要
#endif
- 编写主文件
1
2
3
4
5
#include <iostream>
#include "languageheader.h"
int main(){
print_cur_language();
}
编译主文件并链接至动态链接库
1 2 3
g++ main.cpp -l<library1> -l<library2> -o executable 如 g++ main.cpp -lchn_lang -o main
如果在使用
-l指定库文件名称的时候,我们的动态链接库不在标准路径,则需要配置环境变量并添加-L指定库文件的目录路径:1 2 3 4 5
export LD_LIBRARY_PATH=<path_to_library>:$LD_LIBRARY_PATH 如 export LD_LIBRARY_PATH=./:$LD_LIBRARY_PATH 然后 g++ main.cpp -L./ -lchn_lang -o main
采用
-l指定库文件名称会帮助我们把动态链接库的前缀lib和后缀.so补齐,所以此处不需要再添加。搜索路径可以是绝对路径或相对路径。如果是完整的绝对路径(例如
/path/to/library),则链接器将使用该路径作为库文件的准确位置。如果是相对路径(例如./libraries或../libs),则链接器将在当前工作目录下搜索库文件。![QQ截图20230619203556]()
如果我们的库文件的名称并不是标准化,如
lib___.so形式,则可以在-l命令后添加冒号:。然后放入库文件的全名附带后缀1
g++ main.cpp -L./ -l:somethingchn_lang.so -o main

如果此时我们有多个动态链接库文件,并且都有同名符号,则链接顺序和符号强度决定了具体调用的函数。比如:
1
2
g++ main2.cpp -L./ -lchn_lang -leng_lang -o main2
g++ main2.cpp -L./ -leng_lang -lchn_lang -o main2
第一种输出chinese而第二种输出english
具体的一些讨论可以参考这两篇文章:动态链接库的符号重名问题 和 强弱符号和强弱引用
有用的文章
标识符, 限定标识符,有限定名称查找,无限定名称查找和ADL 实参依赖查找
标识符
C++编译器将文件代码源文件解析后,将代码分解为identifier1、数值、运算符等,其中identifier是由非数字开头、任意字符数字和下划线组成的部分,其用来组成声明、表达式、name和qualified identifier。
在声明中identifier:
- 不能时语法关键字
- 不要以双下划线(
__)或者下划线(_)开头,以免和编译器或者标准库的内部声明冲突,可以参见17.6.4.3 [reserved.names]
identifier在表达式中除了表示一些简单的函数和对象外,还可以是:
- 函数写法的重载运算符名。比如
operator+oroperator new; - the name of an operator function, such as
operator+oroperator new; - 用户定义转换函数的名字,比如
operator bool; - 用户定义字面量运算符的名字 比如
operator "" _km; ~字符后随类名,如~MyClass;~字符后随decltype说明符,比如~decltype(str);- 模板名后随包含模板实参的角括号 比如
MyTemplate<int>; - 作用域解析操作符
::限定的标识符 例如std::stringor::tolower.
限定标识符
qualified identifier(限定标识符)是由域解析符::标识与class名、枚举类名、namespace或者decltype表达式限定的一类identifier。
比如:
std::string::npos::tolower::std::coutboost::signals2::connection
名称
name是指下面的一个实体或标签:
- 一个标识符
identifier - 操作符函数 (
operator+,operator new); - 用户定义的转换函数 (
operator bool); - 用户定义的字面值转换符 (
operator "" _km); - 模板 id (
name<arg, arg>). goto语句指向的label
当编译器遇到一个未知的name时,会进行name lookup2,例如,当编译std::cout << std::endl;时:
- 因为
std左侧没有::进行限定,则对std进行unqualified name lookup,发现其是一个声明在头文件<iostream>中的namespace - 因为
cout左侧有::进行限定且其限定的域为一个namespace,则对cout进行qualified name lookup,发现其是一个声明在namespace std中的变量 - 因为
endl左侧有::进行限定且其限定的域为一个namespace,则对endl进行qualified name lookup,发现其是一个声明在namespace std中的函数模板 <<没有限定且为一个函数,对<<进行argument-dependent lookup,发现其是一个声明在namespace std中的函数模板声明
其主要规则是,如果目标是一个qualified identifier(限定标识符),进行Qualified name lookup3,否则进行Unqualified name lookup4,对于函数还可能进行Argument-dependent lookup5
有限定名称查找 Qualified name lookup
当遇到未知的
qualified identifier(限定标识符)时,会去其对应的限定符区域内进行查找,比如命名空间、类作用域、枚举空间等。
1
2
3
4
5
std::cout << 1; // 解析"cout"时,去命名空间std中进行查找
struct A {
typedef int type;
};
A::type a; // 解析"type"时,去A类作用域中查找
如果
::左侧没有限定符,则去全局命名空间进行查找,这样就避免了被本地声明遮盖的情况:
1
2
3
4
5
6
#include <iostream>
int main() {
struct std {};
std::cout << "fail\n"; // Error: unqualified lookup for 'std' finds the struct
::std::cout << "ok\n"; // OK: ::std finds the namespace std
}
当然,在解析
::右手侧的name之前需要先解析::左手侧的name(除非使用了decltype表达式或者::左侧为空)。至于带::的name查找时qualified name lookup还是unqualified name lookup,取决于::左侧的name。当::左侧name为namespace、class、枚举、实例化的模板时,为qualified name lookup。
1
2
3
4
5
6
7
8
9
10
struct A {
static int n;
};
int A::n = 0;
int main() {
int A;
A::n = 42; // OK: 对"A"进行"unqualified lookup"时,忽略了本地变量A
A b; // 错误: 对"A"进行"unqualified lookup"会指向本地变量A
struct A b; // A 前面需要增加tag "struct" 进行限定,以避免被本地变量A遮盖
}
qualified name用于声明时,当同在一个声明中的unqualified name需要进行unqualified lookup时,在qualified name对应的类作用域、命名空间进行查找。不在同一个声明中的unqualified name,不会受到这个影响。同时也不受声明类型的影响。
上面这一段话比较难描述,需要结合一个例子来理解:
1
2
3
4
5
6
7
8
9
10
11
12
13
class X {};
constexpr int number = 100;
struct C {
class X {};
static const int number = 50;
static X arr[number];
};
X C::arr[number],
brr[number]; // 错误: "X"经过`unqualified name`解析为`::X`与`C::arr`对应的`C::X`不同。
C::X C::arr[number], brr[number]; // OK: `C::arr`的长度为50,`brr`的长度为100
// `C::arr[number]`中的`number`受同一个声明中的"qualified name"`C::arr`
// 的影响,回去类作用域`C`中查找,得到`C::number`,也就是50。而`brr[number]`
// 与`C::arr[number]`不是同一个声明,则不受这种影响,得到`::number`,也就是100
如果
::后随字符~再跟着一个标识符(也就是说指定了析构函数或伪析构函数),那么该标识符将在与::左边的名字相同的作用域中查找。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct C {
typedef int I;
};
typedef int I1, I2;
extern int *p, *q;
struct A {
~A();
};
typedef A AB;
int main() {
p->C::I::~I(); // 解析`~I()`时,使用`C::I`这个`name`相同的域`C::`,则找到了`C::I`
q->I1::~I2(); // 解析`~I2()`时,使用`::I1`这个`name`相同的域,则找到了`::I2`
AB x;
x.AB::~AB(); // ~ 之后的名字 AB 在 :: 前面的 AB 的同一个作用域中查找
// 也就是说从当前的作用域中查找,因此查找结果是 ::AB
}
当
::左侧为枚举类时,则::右侧的name必须属于这个枚举类,否则为ill-formed
qualified name lookup还可以被用来调用被隐藏的方法,这种调用方式不会调用虚函数:
1
2
3
4
5
6
7
8
9
10
11
12
struct B {
virtual void foo();
};
struct D : B {
void foo() override;
};
int main() {
D x;
B &b = x;
b.foo(); // calls D::foo (virtual dispatch)
b.B::foo(); // calls B::foo (static dispatch)
}
模板参数进行解析时,从当前域进行解析
1
2
3
4
5
6
namespace N {
template <typename T>
struct foo {};
struct X {};
} // namespace N
N::foo<X> x; // 错误:"X"被解析为"::X",而不是"N::X"
对一个
namespace N进行qualified name lookup时,首先考虑namespace N内的声明和inline namespace members。如果没有匹配的,其次考虑using-directives导入到namespace N中的声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
int x;
namespace Y {
void f(float);
void h(int);
} // namespace Y
namespace Z {
void h(double);
} // namespace Z
namespace A {
using namespace Y;
void f(int);
void g(int);
int i;
} // namespace A
namespace B {
using namespace Z;
void f(char);
int i;
} // namespace B
namespace AB {
using namespace A;
using namespace B;
void g();
} // namespace AB
void h() {
AB::g(); // 首先考虑"AB::g",则不再对namespace A、B进行查找
AB::f(1); // 首先在namespace AB中查找,未匹配,然后到namespace A、B中查找,查找到"A::f"和"B::f",
// 有匹配,则不再对namespace Y进行查找。然后在"A::f"和"B::f"中间选择了"A::f(int)"。
AB::x++; // 首先在namespace AB中查找,未匹配。然后到namespace A、B中查找,未匹配。
// 然后到namespace Y、Z中查找,未匹配。然后报错。
AB::i++; // 首先在namespace AB中查找,未匹配。然后到namespace A、B中查找,匹配到"A::i"和"B::i"
// 存在冲突,报错。
AB::h(16.8); // 首先在namespace AB中查找,未匹配。然后到namespace A、B中查找,未匹配。
// 然后到namespace Y、Z中查找,匹配到"Y::h"和"Z::h",选择"Z::h(double)"
}
在
namespace中进行qualified name lookup时,允许通过不同途径匹配到相同的类型
namespace A {
int a;
} // namespace A
namespace B {
using namespace A;
} // namespace B
namespace D {
using A::a;
} // namespace D
namespace BD {
using namespace B;
using namespace D;
} // namespace BD
void g() {
BD::a++; // 首先在 namespace BD 中查找,未匹配。然后到 namespace B、D中查找,未匹配。
// 再下面,namespace B、D都同时指向了 namespace A,则在 namespace A 中匹
// 配到 A::a,选择 "A::a"
}
无限定名称查找
unqualified name只要指那些左侧没有::域符号限定的name。在搜索时,在相关命名空间、using引入的命名空间等域进行,直到找到一个匹配的类型则停止。
当遇到一个未知的unqualified name时,会从当前文件域、命名空间开始查找,具体情形比较简单。下面列出一些需要特殊注意的点:
一个变量的定义在其命名空间
X外时且定义语句中引用了unqualified name,解析这个unqualified name时,首先从变量命名空间X开始查找。有点类似ADL,但是注意区别。
1
2
3
4
5
6
7
8
namespace X {
extern int x; // 声明,不是定义
int n = 1; // 在解析x的定义时,其引用了unqualified name “n”,先从其定义域"X"开始搜索,首先发现 n=1
}; // namespace X
int n = 2; // 如果X::n不存在时,则匹配::n,否则被遮盖。
int X::x = n; // X::x的定义式,X::x的定义在其命名空间"X"外,且引用了unqualified name “n”,
// 在解析"n"时,匹配X::n,则X::x为1
当在命名空间外定义一个
非成员函数时,如果函数内引用了unqualified name时,解析这个unqualified name时,依次搜索其函数定义之前的:本地代码块、代码块外层定义变量、函数定义之前的命名空间、函数定义之前的外层命名空间、函数定义之前的全局域,直到找到一个匹配的name,在函数定义之后的相关域不在搜索范围内。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
namespace A {
namespace N {
void f();
int i = 3; // 3: 查找"命名空间",如果将①②注释掉,这句定义存在,则"i"的定义匹配此处,则i=3
} // namespace N
int i = 4; // 4: 查找"外层命名空间",如果将①②③注释掉,这句定义存在,则"i"的定义匹配此处,则i=4
} // namespace A
int i = 5; // 5: 查找"全局域",如果将①②③④注释掉,这句定义存在,则"i"的定义匹配此处,则i=5
// 在命名空间外定义了一个非成员函数f(),这个例子的注释需要按照序号来看。
void A::N::f() {
int i = 2; // 2: 其次查找"外层代码块",如果将①注释掉,这句定义存在,则"i"的定义匹配此处,则i=2
{
int i = 1; // 1: 首先查找“本地代码块”,如果这句定义存在,则"i"的定义匹配此处,则i=1
std::cout << i; // 0: 在代码块中引用了unqualified name "i",则需要查找"i"的定义
}
}
// int i; // 如果将5移动到f()定义之后则不参与"i"的查找
namespace A {
namespace N {
// int i; // 如果将3移动到f()定义之后则不参与"i"的查找
}
} // namespace A
对于在类的定义中所使用的
unqualified name,当出现于除了在成员函数体、成员函数的默认实参、成员函数的异常规定、默认成员初始化器、契约条件 (C++20 起)或者嵌套类的定义(包括嵌套类从之派生的基类的名字)以外的任何位置时,要在下列作用域中查找:
- 类体之中直到这次使用点之前的部分以及其基类的整个类体
- 基类的整个类体,找不到声明时,递归到基类的基类中
- 当这个类是嵌套类时,其外围类体中直到这个类的声明之前的部分以及外围类的基类的整个类体
- 当这个类是局部类或局部类的嵌套类时,定义了这个类的块作用域中直到其定义点之前的部分
- 当这个类是命名空间的成员,或者命名空间成员类的嵌套类,或者命名空间成员函数的局部类时,查找这个命名空间作用域中直到这个类、其外围类或函数的定义之前的部分。若所查找的是由友元声明所引入的名字:这种情况下仅考虑其最内层的外围命名空间,否则的话,对外围命名空间的查找将照常持续直到全局作用域。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
namespace M {
// const int i = 1; // 找不到这个
class B {
// const const int i = 3; // 找到了第三个(但之后会被访问检查所拒绝)
};
} // namespace M
// const int i = 5; // 找到了第五个
namespace N {
// const int i = 4; // 找到了第四个
class Y : public M::B {
// static const int i = 2; // 找到了第二个
class X {
// static const int i = 1; // 找到了第一个
int a[i]; // use of i
// static const int i = 1; // 找不到这个
};
// static const int i = 2; // 找不到这个
};
// const int i = 4; // 找不到这个
} // namespace N
// const int i = 5; // 找不到这个
当在类作用域外定义一个
成员函数时,如果函数内引用了unqualified name时,解析这个unqualified name时,依次搜索其函数定义之前的:本地代码块、代码块外层定义变量、类作用域、基类作用域、函数定义之前的命名空间、函数定义之前的外层命名空间、函数定义之前的全局域,直到找到一个匹配的name,在函数定义之后的相关域不在搜索范围内。注意跟上面非成员函数的区别。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
class B {
int i; // 4: 如果1 2 3不存在,”i“匹配此处
};
namespace M {
int i; // 6: 如果1 2 3 4 5不存在,”i“匹配此处
namespace N {
int i; // 5: 如果1 2 3 4不存在,”i“匹配此处
class X : public B {
int i; // 3: 如果1 2不存在,”i“匹配此处
void f(); // 0: class X中声明了一个函数f()
// int i; // 将3移动到这里也OK,类成员的可见性受声明的位置的影响。
};
// int i; // 5移动到这里也可以,跟f()实现代码的位置有关,与f()声明的位置无关
} // namespace N
} // namespace M
int i; // 7: 如果1 2 3 4 5 6 7不存在,”i“匹配此处
// 定义class X中声明的函数f()
void M::N::X::f() {
int i; // 2: 如果2不存在,”i“匹配此处
{
int i; // 2: 如果2存在,”i“首先匹配此处
i = 16;
}
// int i; // 如果这句存在,1 2都不存在,也不会匹配此处,因为其出现在调用i的代码块之后
}
namespace M {
namespace N {
// int i; // 5移动到这里不匹配,其出现在f()实现代码之后
}
} // namespace M
虚继承的优先性,这个概念用定义来讲非常麻烦,简单来讲就是:如果一个类A由类B派生而来、类B虚继承自类C,则在类A中进行非限定查找时,类B中的符号会隐藏遮盖掉类C中的name,如果类A还通过其他非虚继承的方式继承了类C,则类B不会隐蔽遮盖类C中的相同name,发生歧义错误。
struct X {
void f();
};
struct B1 : virtual X {
void f();
};
struct B2 : virtual X {};
struct D : B1, B2 {
void foo() {
X::f(); // OK,调用了 X::f(有限定查找)
f(); // OK,调用了 B1::f(无限定查找)
/*
C++98 规则:B1::f 隐藏 X::f,因此即便从 D 通过 B2 可以访问到 X::f,它也不能从 D 中的名字查找所找到。
C++11 规则:在 D 中对 f 的查找集合并未找到任何东西,继续处理其基类。 在 B1 中对 f 的查找集合找到了 B1::f,并且完成查找合并时替换了空集,此时在 C 中 对 f 的查找集合包含 B1 中的 B1::f。在 B2 中对 f 的查找集合并未找到任何东西,继续处理其基类。在 X 中对 f 的查找找到了 X::f合并时替换了空集,此时在 B2 中对 f 的查找集合包含 X 中的 X::f。当向 C 中合并时发现在 B2 的查找集合中的每个子对象(X)都是已经合并的各个子对象(B1)的基类,因此 B2 的集合被丢弃。C 剩下来的就是在 B1 中所找到的 B1::f (如果使用 struct D : B2, B1,则最后的合并将会替换掉。C 此时已经合并的 X 中的 X::f,因为已经加入到 C 中的每个子对象(就是 X)都是新集合(B1)中的至少一个子对象的基类,其最终结果是一样的:C 的查找集合只包含在 B1 中找到的 B1::f)
*/
}
};
#include <iostream>
struct X {
void f() { std::cout << "X::f()" << std::endl; }
};
struct B1 : virtual X {
void f() { std::cout << "B1::f()" << std::endl; }
};
struct B2 : X {};
struct D : B1, B2 {
void foo() {
X::f(); // OK,调用了 X::f(有限定查找)
f(); // 由于D还通过B2的渠道非虚继承了X,则X::f()不会被B1::f()遮盖掉,所以此处发生歧义错误。
};
};
struct V {
int v;
};
struct A {
int a;
static int s;
enum { e };
};
struct B : A, virtual V {};
struct C : A, virtual V {};
struct D : B, C {};
void f(D &pd) {
++pd.v; // OK:只有一个 v,因为只有一个虚基类子对象
++pd.s; // OK:只有一个静态的 A::s,即便在 B 和 C 中都找到了它
int i = pd.e; // OK:只有一个枚举符 A::e,即便在 B 和 C 中都找到了它
++pd.a; // 错误,有歧义:B 中的 A::a 和 C 中的 A::a
}
类的静态成员定义时,如果引用了
unqualified name,其查找过程与类成员函数中unqualified name的查找顺序相同
1
2
3
4
5
6
struct X {
static int x;
static const int n = 1;
};
int n = 2;
int X::x = n; // 找到了 X::n,将 X::x 设置为 1 而不是 2
当一个类的友元函数被定义在类作用域内部时,该友元函数中引用的
unqualified name的查找顺序与该类的成员函数中的unqualified name的查找顺序相同。当类的友元函数被定义在类作用域外部时,该友元函数中引用的unqualified name的查找顺序与其所在命名空间的其他函数中的unqualified name的查找顺序相同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int i = 3; // 3: 当1 2不存在时,f1中的"i"匹配此处
// 3: 当1 2不存在时,f2中的"i"也不会匹配此处
struct X {
static const int i = 2; // 2: 当这句定义存在时,1不存在时,f1中的"i"匹配此处
// 2: 当1不存在时,f2中的"i"也不会匹配此处
friend void f1(int x)
{
int i; // 1: 当这句定义存在时,f1中的"i"匹配此处
i = x; // 0: 友元函数f1(int)被定义在类X作用域内部时,"i"的查找顺序与X的成员函数查找顺序相同
}
friend int f2();
// static const int i = 2; // ②移动到此处也OK
};
void f2(int x) {
int i; // 1: 当这句定义存在时,f2中的"i"匹配此处
i = x; // 0: 友元函数f2(int)被定义在类X作用域外部时,"i"的查找顺序f2(int)所在命名空间的普通函数的查找顺序相同
}
当一个类A的成员函数被声明为类B的友元,且该声明中包含
unqualified name,则对unqualified name进行查找时:
- 如果
unqualified name不是任何模板的参数,则首先去类作用域A中进行查找- 如果在类作用域A中未匹配或者其实模板参数,则去类作用域B中进行查找
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 这个类的成员函数被作为友元
struct A {
typedef int AT;
void f1(AT);
void f2(float);
template <class T>
void f3();
};
// 这个类授予友元关系
struct B {
typedef char AT;
typedef float BT;
friend void A::f1(AT); // 对 "AT" 的查找时,先到类作用域A中进行查找,匹配"A::AT"
friend void A::f2(BT); // 对 "BT" 的查找时,先到类作用域A中进行查找,未匹配,
// 再去类作用域B中查找,匹配"B::BT"
friend void
A::f3<AT>(); // 对 "AT" 的查找时,"AT"是模板参数,则直接去类作用域B中查找,匹配"B::AT"
};
unqualified name被当做函数默认参数时,查找其定义时,首先考虑同一函数声明中的形参:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class X {
int a, b, i, j;
public:
const int &r;
X(int i)
: r(a), // 将 X::r 初始化为指代 X::a
b(i), // 将 X::b 初始化为形参 i 的值
i(i), // 将 X::i 初始化为形参 i 的值
j(this->i) // 将 X::j 初始化为 X::i 的值
{}
}
int a;
int f(int a, int b = a); // 错误:对 a 的查找找到了形参 a,而不是 ::a
// 但在默认实参中不允许使用形参
在枚举类定义时,
unqualified name的查找首先考虑当前枚举类的作用域
1
2
3
4
5
6
const int RED = 7;
enum class color {
RED,
GREEN = RED + 2, // RED 找到了 color::RED ,而不是 ::RED ,因此 GREEN = 2
BLUE = ::RED + 4 // 通过 qualified name lookup 找到 ::RED , BLUE = 11
};
在”try-catch”语句中,
unqualified name的查找跟函数体内引用的unqualified name查找一样。平行的代码块内的定义不可见。
1
2
3
4
5
6
7
8
9
10
11
int n = 3; // 3
int f(int n = 2) { // 2
try {
int n = -1; // 不会匹配到该处
} catch (...) {
// int n = 1; // 1: 加入此处存在,则匹配该处
assert(n == 2); // 0: n 按1 2 3的顺序进行依次查找,匹配f的参数n,即2
throw;
}
return 0;
}
对于在表达式中所使用的重载运算符(比如在
a+b中使用的 operator+),其查找规则和对在如operator+(a,b)这样的显式函数调用表达式中所使用的运算符是有所不同的:当处理表达式时要分别进行两次查找:对非成员的运算符重载,也对成员运算符重载(对于同时允许两种形式的运算符)。然后将这两个集合和在重载解析所述内建的运算符重载以平等的方式合并到一起。而当使用显式函数调用语法时(如operator+(a,b)),则进行常规的unqualified name lookup:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
struct A {};
void operator+(A, A); // 用户定义的非成员 operator+
struct B {
void operator+(B); // 用户定义的成员 operator+
void f();
};
A a;
void B::f() // B 的成员函数定义
{
operator+(a, a); // 错误:在成员函数中的常规名字查找
// 找到了 B 的作用域中的 operator+ 的声明
// 并于此停下,而不会达到全局作用域
a + a; // OK:成员查找找到了 B::operator+,非成员查找
// 找到了 ::operator+(A,A),重载决议选中了 ::operator+(A,A)
}
注入类名
在一个类作用域中,当前类的名称被当做公开的成员名一样对待 也就是说一个类的名字会以unqualified-name的形式,被注入到该类的作用域内。
因此我们在类(类模板)的作用域内可以通过unqualified-name的形式来指代该类。然而,qualified-name的形式则不可以用来指代该类,因为这种形式被用来指代构造函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
int X;
struct X {
void f() {
X* p; // OK : X
// 指代注入类名,在"X"的作用域中,"X"被当做公开成员,注意体会这个"公开成员的含义"
::X* q; // 错误:在全局作用域"::"中,"struct X"被"int X"遮盖
}
};
//-------------------------另外一个例子---------------------
int32_t C;
class C {
private:
int64_t i;
public:
static size_t f() {
static_assert(sizeof(C) == sizeof(int64_t));
return sizeof(C); // C is injeceted as an `unqualified-name`
// into the class scope
}
static void g() {
auto p = &::C; // '::C' refers to the global variable if it
// is qualified with '::'
static_assert(std::is_same_v<decltype(p), int32_t*>);
}
static void k() {
// auto p = &C::C;
// error: taking address of constructor 'constexpr C::C(C&&)'
}
};
auto f() -> size_t {
static_assert(sizeof(C) == sizeof(int32_t));
return sizeof(C); // f in not in the C class scope, thus 'C'
// refers to the global variable 'int32_t C'
}
在类继承的过程中,受到继承限制的控制
1
2
3
4
5
6
7
8
9
10
11
12
13
namespace detail {
struct A {};
struct B {};
}; // namespace detail
struct C : public detail::B, private detail::A {};
struct D : public C {
A* a0; // 错误:注入类名 A 受到“private”的修饰,变为非公开成员,不可访问
detail::A* a1; // OK:不使用注入类名
B* b0; // OK:通过注入类名
detail::B* b1; // OK:不使用注入类名
};
在类模板中,类似普通类情形一样,可以被注入,当做模板名或者类型名。有下列3个情形之一时,注入的名称被当做当前模板名:
- 它后面紧跟随
<符号(模板实例化标识)- 它被当做一个模板模板参数(
template template parameter)- 它是友元类模板声明的详细类型指定符中的最后标识符。 此外其他情形,会被当做一个实际类类型被注入,其类型为该类模板实例化后的类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// 注意体会这个例子
template <template <class, class> class>
struct A;
template <class T1, class T2>
struct X {
X<T1, T2>* p; // X后跟随"<",则X被当做模板 template<class, class> struct X 对待
// 同理,此处改为 X<int, int> *p 也是成立的,因为X是一个模板
using a =
A<X>; // X被当做模板A的模板模板参数,则X被当做模板 template<class, class> struct X 对待
template <class U1, class U2>
friend class
X; // X被当友元模板类的标识符,则X被当做模板 template<class, class> struct X 对待,即::X
// 此处含义为,当模板X实例化后,X<T1,T2>拥有友元X<U1,U2>,X<U1,U2>可以被实例化为多个类型
X* q; // 此处为以上三种情形之外,X被当做了一个实例化的类型名,其类型为X<T1,T2>。
// 当X<T1,T2>被实例为X<int,int>时,q的类型为`X<int,int> *`
// 当X<T1,T2>被实例为X<double,double>时,q的类型为`X<double,double> *`
};
ADL实参依赖查找
ADL主要适用于对unqualified-name的函数进行的名字查找。查找对象是一个在进行函数调用或者运算符调用的非成员函数。换句话说,ADL依据函数调用中的实参的数据类型查找未限定(unqualified)的函数名(或者函数模板名)。
哪些不触发ADL
如果通常的未限定(unqualified)名字查找所产生的候选集包括下述情形,则不会启动依赖于实参的名字查找(ADL查找不会进行):
1.类成员声明(此种情形仅指普通的类成员函数,不指类成员运算符函数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
#include <iostream>
namespace xx {
struct XA {};
void foo(XA &a) { std::cout << "xx::foo" << std::endl; }
}; // namespace xx
namespace yy {
void test() {
xx::XA xa;
foo(xa); // 在这里,可以通过ADL来找到xx::foo
}
struct YA {
int foo;
static void test() {
xx::XA xa;
foo(xa); // 在这里,由于通过unqualified name lookup找到了
// 成员变量int foo,所以不会进行ADL,因此会出错
}
};
} // namespace yy
2.块作用域内的函数的声明,不含(using-declaration)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#include <iostream>
namespace xx {
struct XA {};
void foo(XA &a) { std::cout << "xx::foo" << std::endl; }
}; // namespace xx
namespace zz {
void foo(int a) { std::cout << "zz::foo" << std::endl; }
} // namespace zz
namespace yy {
void foo(int a); // 1
void test0() {
xx::XA xa;
foo(xa); // 此处正常进行ADL,不受到外部声明1的影响 因为1不在块作用域内
}
void test1() {
using zz::foo; // 2
xx::XA xa;
foo(xa); // 此处正常进行ADL,不受声明2的影响 因为2使用了using declaration
}
void test2() {
void foo(int); // 3
xx::XA xa;
foo(xa); // ERROR 此处由于该块作用域内中有不含using的声明,则不会进行ADL,所以会报错
}
} // namespace yy
3.任何不是函数或者函数模板的声明(例如函数对象或者另一个变量其名字与被查询的函数名字冲突)
注意,这个是CPO的要点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
namespace xx {
struct XA {};
void foo(XA &a) { std::cout << "xx::foo" << std::endl; }
}; // namespace xx
namespace zz {
struct foo_callable {
void operator()(xx::XA) const {
std::cout << "zz::foo functor called for xx::XA" << std::endl;
}
};
foo_callable foo{}; // 全局可用的CPO实例
}
namespace yy {
void foo(int a);
void test0() {
xx::XA xa;
foo(xa); // 一切正常
}
void test1() {
using zz::foo; // 由于该处声明,引入的是一个函数对象,则1处不会进行ADL,而是直接调用zz::foo
// 去掉这个这正常调用xx::foo
xx::XA xa;
foo(xa); // 1
}
} // namespace yy
int main() {
yy::test1();
return 0;
}
4.当调用的函数被括号包围时
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <iostream>
namespace xx {
struct XA {};
void foo(XA &a) { std::cout << "xx::foo" << std::endl; }
}; // namespace xx
namespace yy {
void test0() {
xx::XA xa;
foo(xa); // OK,此处进行ADL
(foo)(xa); // ERROR,由于foo被括号包围,故不进行ADL,这条规则在文档中没有提及,
// 不知道应该被归属于哪一条,所以单独拿出来。
}
} // namespace yy
ADL的查找范围
函数调用表达式的每个实参的类型用于确定命名空间与类的相关集合(associated set of namespaces and classes)并用于函数名字查找(这句话的意思简而言之就是ADL查找的集合范围如何确定):
1.基本类型(fundamental type)实参的命名空间与类的相关集合为空。
这个的意思是,当参数的类型是基本类型时(例如 int, char, double 等),ADL 的处理方式如下:
- 基本类型的命名空间和类集合为空:
- 当 ADL 处理一个基本类型(如
int)的参数时,它不会将任何命名空间或类添加到与该类型相关联的查找集合中。基本类型不属于任何用户定义的命名空间或类,因此它们的关联命名空间和类集合为空。
- 当 ADL 处理一个基本类型(如
- ADL 对基本类型不起作用:
- 由于基本类型没有相关的命名空间或类,因此 ADL 不会基于这些类型查找到任何附加的函数定义。换句话说,当函数参数是基本类型时,ADL 不会帮助找到在某个特定命名空间中定义的函数。
1
如果参数的命名空间为空,将其添加到查找集合内,但是查找时,会直接跳过空集。
2.类类型(class type,指struct,class,union类型),相关集合包括
- 类类型自身;
- 该类型的所有的直接或间接基类;
- 如果类类型 T 是另一个类 G 的成员(嵌套类型),则那个包含了类类型 T 的类 G;
- 该类类型的所有相关类的最内层外围命名空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <iostream>
namespace ADL {
struct A;
struct Base {
friend void func2(const A &a) { std::cout << "2.2" << std::endl; }
};
struct A : public Base {
friend void func1(A a) { std::cout << "2.1" << std::endl; }
struct B {};
friend void func3(B b) { std::cout << "2.3" << std::endl; }
};
void func4(A a) { std::cout << "2.4" << std::endl; }
}; // namespace ADL
int main() {
ADL::A a;
ADL::A::B b;
func1(a); // 2.1
func2(a); // 2.2
func3(b); // 2.3
func4(a); // 2.4
}
3.如果实参是类模板特化后得到的类型,在上述规则外,还检验下列规则,并添加其关联类与命名空间到集合:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <iostream>
namespace xx {
enum XType {
XTypeA,
XTypeB,
XTypeC,
};
void foo(XType x) { std::cout << "foo 4" << std::endl; }
struct A {
enum AType {
ATypeA,
ATypeB,
};
friend void foo1(AType x) { std::cout << "foo 41" << std::endl; }
};
} // namespace xx
namespace yy {
void test0() { foo(xx::XTypeA); } // ADL
void test1() { foo1(xx::A::ATypeA); } // ADL
} // namespace yy
5.如果实参是类型 T 的指针或者是类型 T 的数组的指针,则检验类型 T 并添加其类与命名空间的关联集到集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <iostream>
namespace xx {
struct A {
friend void foo1(A* x) { std::cout << "foo 6.1.1" << std::endl; }
friend void foo2(A x[]) { std::cout << "foo 6.1.2" << std::endl; }
};
void foo3(A* a) { std::cout << "foo 6.2.1" << std::endl; }
void foo4(A x[]) { std::cout << "foo 6.2.2" << std::endl; }
} // namespace xx
namespace yy {
void test0() {
xx::A* a;
xx::A aa[2];
foo1(a); // ADL
foo2(aa); // ADL
foo3(a); // ADL
foo4(aa); // ADL
}
} // namespace yy
6.如果实参是函数类型,那么检验函数参数类型与函数返回值类型,并添加其类与命名空间的关联集到集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <iostream>
namespace xx {
struct A {};
void func1(A& a) {}
A func2() { return {}; }
void lookup1(void (*f)(A&)) { std::cout << "xx:lookup1" << std::endl; }
void lookup2(A (*f)()) { std::cout << "xx:lookup2" << std::endl; }
} // namespace xx
namespace yy {
void test0() {
lookup1(xx::func1); // ok
lookup2(xx::func2); // ok
}
} // namespace yy
7.如果实参是类 X 的成员函数 F 的指针类型参数,那么该成员函数的形参类型、该成员函数返回值的类型、该成员函数所属类 X 的相关集合都被加入到关联集到集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
#include <iostream>
namespace x {
struct B;
} // namespace x
namespace xx {
struct A {
x::B* f() { return nullptr; }
void ff(x::B&) {}
};
} // namespace xx
namespace x {
struct B {
friend void lookup1(B* (xx::A::*f)()) { std::cout << "xx::lookup1" << std::endl; }
};
template <typename T>
void lookup2(T t) {
std::cout << "xx::lookup2" << std::endl;
}
} // namespace x
namespace yy {
void test0() {
lookup1(&xx::A::f); // ok
lookup1(
nullptr); // failed,因为这条规则标明的是实参,此处实参是nullptr,则不会查找到对应的lookup1
lookup2(&xx::A::ff); // ok
}
} // namespace yy
8.如果实参是类 X 的数据成员 T 的指针类型参数,那么该成员类型、该数据成员所属类 X 的相关集合都被加入到关联集到集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <iostream>
namespace xx {
struct A {
int num = 0;
};
void lookup1(int A::*) { std::cout << "x::lookup1" << std::endl; }
} // namespace xx
namespace yy {
void test0() { lookup1(&xx::A::num); } // ok
} // namespace yy
int main() { yy::test0(); }
9.若参数是重载函数集的取址表达式(或对函数模板)的名称,则检验重载集中的每个元素,并添加其类与命名空间的关联集到集合。 1. 另外,若重载集为模板 id (带模板实参的模板名),则检验其所有类型模板实参与模板模板实参(但不含非类型模板实参),并添加其类与命名空间的关联集到集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
namespace xx {
struct A {
int num = 0;
};
void lookup1(void (*)()) { std::cout << "x::lookup1" << std::endl; }
} // namespace xx
namespace yy {
void f() {}; // ①
void f(xx::A*) {}; // ②
void test0() { lookup1(&f); } // ok,由于重载f②的存在,namespace xx也被加入到ADL的集合中
} // namespace yy
int main() { yy::test0(); }
10.如果相关集合中的任何命名空间是内联命名空间(inline namespace), 则添加其外围命名空间到关联集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
namespace adl {
inline namespace inner {
struct A {};
} // namespace inner
void func(const inner::A &a) { std::cout << "enclosed namespace added." << std::endl; }
} // namespace adl
int main() {
adl::inner::A a;
func(a); // 因为 adl::inner 为 inline namespace,则将其最内存外围 namespace adl
// 到查找关联集合中,则可以查找到 adl::func
}
11.如果相关集合中的一个命名空间直接包含了内联命名空间,则内联命名空间被增加到相关集合中。
1
2
3
4
5
6
7
8
9
10
11
12
13
#include <iostream>
namespace adl {
struct A {};
inline namespace inner {
void func(const A &a) { std::cout << "inline namespace added." << std::endl; }
} // namespace inner
} // namespace adl
int main() {
adl::A a;
func(a); // namespace adl中包含 inline namespace adl::inner,
// 则将 adl::inner 添加到查找关联集合中,则可以查找到 adl::inner::func
}
12.在确定命名空间与类的关联集后,为了进一步的 ADL 处理,忽略此集中所有于类中找到的声明,除了命名空间作用域的友元函数及函数模板,陈述于后述点2。以下列特殊规则,合并普通无限定查找找到的声明集合,与在 ADL 所生成关联集的所有元素中找到的声明集合:
- 忽略关联命名空间中的 using 指令
- 声明于关联类中的命名空间作用域友元函数(及函数模板)通过 ADL 可见,即使它们通过普通查找不可见。
- 忽略函数与函数模板外的所有名称(与变量不冲突)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <iostream>
namespace xx {
struct A;
}// namespace xx
namespace x {
void f(xx::A *) { std::cout << "x::f" << std::endl; }
} // namespace x
namespace xx {
using namespace x; // 1
struct A {};
} // namespace xx
namespace yy {
void test0() {
xx::A *a;
f(a); // not ok, ADL时忽略1处using指令
}
} // namespace yy
int main() { yy::test0(); }
通过 ADL 查找到的
name会和前面unqualified name普通查找到的合并到一起进行选择,如果存在歧义,会报错。
ADL的核心是: 在调用函数的时候,只要有一个参数的类型属于函数所在的命名空间,那么调用的时候就不用加命名空间前缀
1
2
3
4
5
6
7
8
9
10
11
12
13
14
namespace A
{
struct Empty {};
void foo(int);
void bar(Empty, int);
}
void func()
{
A::foo(2); // 必须这么调用,foo(2)找不到A里面的foo
foo(A::Empty{}, 1); // 因为第一参数的类型在A中,foo前面不用再加前缀
std::cout << 1;
// 等价于operator<< (std::cout, 1)
// 由于ADL,可以找到std中的std::operator<< (std::ostream&, int)
}
CPO 定制点对象
我们在ADL中的不触发ADL的第三点中提到了CPO的关键要素。CPO本质上,就是一个能够正确解决复杂定制问题的functor对象。为了解决这个问题,我们需要屏蔽掉ADL调用。也就是说,我们把ADL的两步式(先using引入,再非限定调用)放到了定制点对象内部进行。而在外部我们并不使用ADL。
- 它能够在编译期对于简单的无限定调用,根据实参的不同情况进行判断,并转发到正确的实现;
- 它能够检查实参与ADL重载(若存在)是否符合语法要求,并在需要的时候报错。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
struct special{};
namespace mystd{
template<typename T>
void foo(T t) {
std::cout << "foo(T)" << std::endl;
}
}
namespace yb {
struct myclass {};
void foo(myclass s) { std::cout << "yb::foo" << std::endl; }
} // namespace yb
namespace xx {
struct XA {};
void foo(XA &a) { std::cout << "xx::foo" << std::endl; }
} // namespace xx
namespace yy {
void foo(int a) { std::cout << "yy::foo" << std::endl; }
void test0() {
xx::XA xa;
foo(xa); // 一切正常
}
namespace zz {
struct foo_callable {
template <typename... Args>
void operator()(Args &&...args) const {
// using xx::foo;
// using yb::foo;
// using yy::foo;
// 不用任何的using。因为我们传入的参数的namespace里都有一个叫foo的。所以正常ADL会找到的。
using mystd::foo; // 这个using是模拟swap例子里的using。
// 使用这个using的原因是mystd里面没有special这个成员。所以ADL也找不到。
std::cout << "zz::foo" << std::endl;
foo(std::forward<Args>(args)...); // 正常ADL
}
};
foo_callable foo{}; // 全局可用的CPO实例
} // namespace zz
void test1() {
using zz::foo; // 由于该处声明,引入的是一个函数对象,则1处不会进行ADL,而是直接调用zz::foo
xx::XA xa;
yb::myclass s;
foo(xa); // 1
foo(s); // 2
foo(10); // 3
foo(special{}); // 4
}
} // namespace yy
int main() {
yy::test1();
return 0;
}
参考资料
整理C++的三种名称查找方式
| 查找类型 | 触发形式 | 搜索范围 | 适用场景 |
|---|---|---|---|
| 限定名称查找 Qualified | a::b::x | 仅 :: 左侧指定作用域 | 精确控制符号来源 |
| 非限定名称查找 Unqualified | x | 由内向外逐层作用域 | 局部变量、类成员、全局量 |
| 参数依赖查找 (ADL) | func(arg) | 常规作用域 + 参数类型命名空间 | 函数调用(尤其运算符) |
来自参考
不要重新打开std空间并且往里塞东西
比如如何正确的特化std::hash
不要这样
1
2
3
4
5
6
7
8
struct Widget {};
namespace std { // Danger!
template<>
struct hash<Widget> {
size_t operator()(const Widget&) const;
};
}
要这样
1
2
3
4
5
6
struct Widget {};
template<>
struct std::hash<Widget> {
size_t operator()(const Widget&) const;
};
参考这里
翻译单元
在C++中,翻译单元指的是编译器处理的最小独立单元,通常对应一个源文件(.cpp或.c文件)以及其包含的所有头文件。具体来说,一个翻译单元包括以下内容:
- 源代码文件自身的内容
- 源代码文件中
#include的所有头文件(Header Files)的内容,这些头文件在预处理阶段会被展开替换到源文件中 - 宏定义(Macro Definitions)以及其他预处理器指令产生的文本替换
在编译过程中,每个源代码文件都会形成一个独立的翻译单元,编译器对每个翻译单元独立进行词法分析、语法分析、语义分析等编译步骤,最后生成对应的.o(对象文件)或.obj(在Windows系统中)。链接器随后会把这些独立的翻译单元链接起来,形成可执行文件或库文件。
std::string 的不同编译器实现和比较
https://devblogs.microsoft.com/oldnewthing/20240510-00/?p=109742Y3MOtw0Q:1716181180316&q=cpp+weekly&spell=1&sa=X&ved=2ahUKEwiLy_2MuZuGAxXha_UHHet8BmoQBSgAegQICBAB&biw=1920&bih=919&dpr=1
TCMalloc
http://blog.gerryyang.com/linux%20performance/2022/08/07/tcmalloc-in-action.html
std::optional (C++17)
可选返回值的一个类型。要么有值要么没值。就是一个和bool一起打包的包装器
一个大概示例
1
2
3
4
5
6
7
8
template <typename T>
class optional
{
bool _initialized;
std::aligned_storage_t<sizeof(T), alignof(T)> _storage;
public:
// operations
};
初始化及简单实用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//初始化为空
std::optional<int> emptyInt;
std::optional<double> emptyDouble = std::nullopt;
//直接用有效值初始化
std::optional<int> intOpt{10};
std::optional intOptDeduced{10.0}; // auto deduced
//使用make_optional
auto doubleOpt = std::make_optional(10.0);
auto complexOpt = std::make_optional<std::complex<double>>(3.0, 4.0);
//使用in_place 后文会提到
std::optional<std::complex<double>> complexOpt{std::in_place, 3.0, 4.0};
std::optional<std::vector<int>> vectorOpt{std::in_place, {1, 2, 3}};
//使用其它optional对象构造
auto optCopied = vectorOpt;
简单使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
std::optional<int> find_index(const std::vector<int>& data, int value) {
auto iter = std::find(data.begin(), data.end(), value);
if (iter != data.end()) {
return std::distance(data.begin(), iter);
}
return std::nullopt; // 注意这个 也可以直接返回{}
// std::nullopt 是 std::nullopt_t 类型的常量,用于指示 optional 不含值。
}
int main() {
vector<int> myvec{1, 2, 3, 4, 5};
auto s = find_index(myvec, 3);
auto ss = find_index(myvec, 6);
if (s) { // 判断是否有值方法1
cout << s.value() << endl; // 获取值方法1
cout << *s << endl; // 获取值方法2
}
if (s.has_value()) { // 判断是否有值方法2
cout << s.value() << endl;
cout << *s << endl;
}
}
optional 对象在下列条件下含值:
- 对象被以
T类型的值或另一含值 的optional初始化/赋值。
对象在下列条件下不含值:
- 对象被默认初始化。
- 对象被以 std::nullopt_t 类型的值或不含值 的
optional对象初始化/赋值。 - 调用了成员函数 reset()。
部分成员函数
- emplace()
- 原位构造
- 如果之前已含值,则先销毁再构造
- 原位构造
- reset()
- 销毁值。
- swap()
- 交换值
- 如果交换一个空值,则销毁原有值
比较大小
对于定义了<,>,==操作符的类型,保存他们的optional对象也可以比较大小。如optional<int>之间比较大小和直接比较int数值的大小是一样的。比较特殊的是std::nullopt,在比较大小时,它总小于存储有效值的optional对象。
1
2
3
4
5
6
7
8
9
10
std::optional<int> int1(1);
std::optional<int> int2(10);
std::optional<int> int3;
std::cout << std::boolalpha;
std::cout << (int1 < int2) << std::endl; // true
std::cout << (int2 > int1) << std::endl; // true
std::cout << (int3 == std::nullopt) << std::endl; // true
std::cout << (int3 < int1) << std::endl; // true
为什么需要make_optional 和std::in_place
首先我们需要注意一点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
class myclass {
public:
myclass() : mInt(100) {}
int mInt;
};
class myclass2 {
public:
myclass2(int x, int y) : mInt(x+y) {
cout << "constructor" << endl;
}
myclass2(const myclass2& x) : mInt(x.mInt) {
cout << "copy constructor" << endl;
}
myclass2(myclass2&& x) : mInt(x.mInt) {
cout << "move constructor" << endl;
}
int mInt;
};
class myclass3 {
public:
myclass3(int x) : mInt(x) {
cout << "constructor" << endl;
}
myclass3(const myclass3& x) : mInt(x.mInt) {
cout << "copy constructor" << endl;
}
myclass3(myclass3&& x) : mInt(x.mInt) {
cout << "move constructor" << endl;
}
int mInt;
};
int main() {
std::optional<myclass> sample;
std::optional<myclass> sample2{};
cout << boolalpha;
cout << sample.has_value() << endl; // false
cout << sample2.has_value() << endl;// false
}
注意,在这个情况下,这两种方法得到的结果都只是空的optional对象,而不是包含默认构造值的对象。
所以此时, 我们可以这么写:
1
std::optional<myclass> sample3{myclass()};
这种方法是可以工作的,我们将得到包含默认myclass对象的optional对象。但是在上面的代码中,将先构造出一个myclass的临时对象,然后临时对象被移入optional存储的对象中,带来了额外的开销。在这种情况下,我们就可以使用std::in_place_t / std::make_optional来“原地”构造optional底层存储的对象。
1
2
3
4
5
6
std::optional<myclass> sample4{std::in_place};
cout << sample4.has_value() << endl; // true
cout << sample4->mInt << endl; // 100
std::optional<myclass> sample5(std::make_optional<myclass>());
cout << sample5.has_value() << endl;// true
cout << sample5->mInt << endl; // 100
我们再继续看例子,
1
2
3
4
5
6
7
std::optional<myclass2> sample6{std::in_place, 1,3}; //1 OK
std::optional<myclass2> sample7{1, 3}; //2 不OK
std::optional<myclass2> sample81; //3 OK 但是有拷贝
std::optional<myclass3> sample9{std::in_place, 1}; //4 OK
std::optional<myclass3> sample10{1}; //5 OK
| 构造函数 | 编号 | 版本起 |
|---|---|---|
| constexpr optional() noexcept; constexpr optional( std::nullopt_t]) noexcept; | (1) | (C++17 起) |
| constexpr optional( const optional& other ); | (2) | (C++17 起) |
| constexpr optional( optional&& other ) noexcept(/* 见下文 */); | (3) | (C++17 起) |
| (4) | ||
| template < class U > optional( const optional& other ); | (C++17 起) (C++20 前) (条件性 explicit) | |
| template < class U > constexpr optional( const optional& other ); | (C++20 起) (条件性 explicit) | |
| (5) | ||
| template < class U > optional( optional&& other ); | (C++17 起) (C++20 前) (条件性 explicit) | |
| template < class U > constexpr optional( optional&& other ); | (C++20 起) (条件性 explicit) | |
| template< class… Args > constexpr explicit optional( std::in_place_t, Args&&… args ); | (6) | (C++17 起) |
| template< class U, class… Args > constexpr explicit optional( std::in_place_t, std::initializer_list ilist, Args&&... args ); | (7) | (C++17 起) |
| template < class U = T > constexpr optional( U&& value ); | (8) | (C++17 起) (条件性 explicit) |
第一个可以的原因是使用了std::in_place标签,匹配到了第6个构造函数
第二个不可以的原因是std::optional没有一个支持不带标签的同时是多参数的构造函数。
第三个可以的原因是因为额外加了花括号初始化,先初始化成myclass2对象然后拷贝,匹配的是第8个构造函数
第四个可以的原因是使用了标签。匹配到了第六个构造函数
第五个可以的原因是因为是单参数,所以匹配到了第八个构造函数。
所以, 针对不可拷贝或移动的对象,就必须使用in_place了
总结
核心来讲,有三个作用:
- 区分到底是用
optional<T>的默认构造函数还是T的默认构造函数。 - 允许原地构造需要多个入参的对象。
- 让不可拷贝或移动的对象也可以使用
optional
std::inplace在 std::any , std::variant等中亦有同样作用
所以如下代码
1
2
3
4
5
6
7
8
std::optional<myobj> maybe(bool n){
if(n){
return std::nullopt;
}
// return myobj(10); // 一次构造+一次移动+一次析构 性能差
return std::optional<myobj>(10); //直接转发给optional,多参可以make_optional/in_place 性能好
}
第二种写法性能更好。来自这里
关于为什么需要nullopt
https://stackoverflow.com/questions/62933403/why-do-we-need-stdnullopt
部分参考:
https://blog.csdn.net/hhdshg/article/details/103433781
如何往optional里面放入不可构造、不可移动、不可拷贝的对象?
https://devblogs.microsoft.com/oldnewthing/20241115-00/?p=110527
https://github.com/wanghenshui/cppweeklynews/blob/dev/posts/173.md
有点复杂但又不那么复杂。
optional移出元素需要注意的点
假设我有这种代码:
1
2
3
4
5
6
7
8
9
10
myobj do_something() {
std::optional<myobj> opt{2};
cout << "--" << endl;
return *opt; // 和opt.value()一样。不过现在会拷贝
}
myobj do_something2() {
std::optional<myobj> opt{2};
cout << "--" << endl;
return std::move(opt.value());
}
do_something会拷贝。假设myobj很大,又有不必要开销。我们自然会想要do_something2的方法,利用移动。但是我们到底应该移动什么?移动optional里面的value还是移动optional本身?
假设这种情况:
1
2
3
4
5
6
7
8
9
10
11
12
void dummy(myobj obj) { cout << "dummy" << endl; }
void do_something3(bool input) {
std::optional<myobj> opt{2};
if (input) {
dummy(std::move(opt.value())); // opt.value,也就是myobj本身是垃圾值了
}
cout << boolalpha << opt.has_value() << endl; // opt含值
// 过了很久,插入一堆其他逻辑
if (input) {
dummy(std::move(opt.value())); // 出问题了,move了两次
}
}
我们这时候移动的是optional包裹的值。请注意。第一次移动后,optional包裹的值可能是垃圾无效值。但是optional本身是含值的,所以我们就算判断has_value也无法解决这个问题。所以我们真正要做的应该是move这个optional本身。然后move后进行reset。
为什么optional不能像unique_ptr支持移动后自动重置状态?
std::any
any就是一个包装任意类型的包装器
std::any的libstdc++和msvc的内部实现细节差异挺大的。但是换汤不换药。
- msvc的代码分析在这里
- libstdc++的源码在这里
- any_cast为什么可以不用RTTI在这里
- 其实说白了就是构造的时候有一个对应类型的manager。每个manager有个静态的函数模板。每一个类型自然有自己的独有一份合成的函数示例。然后比较类型的时候只需要比较函数地址就可以了。因为如果类型相同,则对应的manager函数的地址也相同。如果没有或者是不同的话自然就炸了。
std::tuple的实现解析
https://mcyoung.xyz/2022/07/13/tuples-the-hard-way/
tuple 的 make_tuple 和 构造函数的一个细微区别
关于make_tuple可以查看EFF_STL章节
1
2
3
4
5
6
int a{1};
float b{2.3};
double c{3.2};
std::string d {"abc"};
auto t = std::tuple{a, b, c, d}; //c++17后可以不指定类模板参数
auto t2 = std::make_tuple(a, b, c, d);
上面的代码就是在基本情况下使用构造函数和makr_tuple的基本语法。我们来看下较为复杂的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
template <typename T>
void func(T a) {
cout << __PRETTY_FUNCTION__ << endl;
}
int main() {
int a{1};
float b{2.3};
double c{3.2};
std::string d{"hello"};
auto t = std::tuple{std::ref(a), std::ref(b), std::cref(c), std::cref(d)}; //c++17后可以不指定类模板参数
auto t2 = std::make_tuple(std::ref(a), std::ref(b), std::cref(c), std::cref(d));
func(t);
func(t2);
}
/*
void func(T) [with T = std::tuple<std::reference_wrapper<int>, std::reference_wrapper<float>, std::reference_wrapper<const double>, std::reference_wrapper<const std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > > >]
void func(T) [with T = std::tuple<int&, float&, const double&, const std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >&>]
*/
我们注意到,使用普通的构造函数时,tuple里 std::ref/cref的类型没有变化。也就是每一个元素都是std::reference_wrapper类型。
但是在使用make_tuple的时候,tuple里的元素类型被脱去了,也就是”退化”成了对应底层类型的引用或const引用类型。我们可以看下源代码
我们可以看到,make_tuple会对参数的reference_wrapper类型进行脱去。
资料来自这篇文章的 Errors in object lifetime: tuples that shoot at your feet 章节
C++中如何避免page fault来降低延迟
https://johnnysswlab.com/latency-sensitive-application-and-the-memory-subsystem-part-2-memory-management-mechanisms
协程
让enum class支持位运算
让枚举支持位运算组合,就像传统c的用法那样,但是枚举类是强类型,转换很不方便,怎么办?实现operator |
比如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
#include <type_traits>
// Define a templatized struct to contain a bool constexpr that controls
// when the operators get generated.
template <typename E>
struct FEnableBitmaskOperators {
static constexpr bool enable = false;
};
// This operator is only defined in the candidate set for a given type if the
// std::enable_if_t below evaluates to true, otherwise it is dropped.
template <typename E>
typename std::enable_if_t<FEnableBitmaskOperators<E>::enable, E> operator|(
E Lhs, E Rhs) {
return static_cast<E>(static_cast<std::underlying_type_t<E>>(Lhs) |
static_cast<std::underlying_type_t<E>>(Rhs));
}
// Rest of the operators...
With the following usage:
enum class ERenderPass : uint8_t {
...
};
// Specialize the struct to enable the operators for our enum.
template <>
struct FEnableBitmaskOperators<ERenderPass> {
static constexpr bool enable = true;
};
// Works!
ERenderPass Primary = ERenderPass::Geometry | ERenderPass::Lighting;
实际上valkan cpp就是这么干的
1
2
3
4
template <typename BitType, typename std::enable_if<FlagTraits<BitType>::isBitmask, bool>::type = true>
VULKAN_HPP_INLINE VULKAN_HPP_CONSTEXPR Flags<BitType> operator|( BitType lhs, BitType rhs ) VULKAN_HPP_NOEXCEPT {
return Flags<BitType>( lhs ) | rhs;
}
ranges 和 view
把ranges理解为一段区间的抽象。比如容器的两个迭代器范围内。所以vector、list都可以被称为range。因为它满足range的要求。
ranges的end一般叫sentinel哨位。原因是它的类型不一定必须和begin迭代器类型一致。因为sentinel不一定是迭代器。
range自带的算法一般是立即求值的。但是view不同。view(范围适配器)是惰性求值的。我们可以把view理解为惰性求值的规则管线。在迭代实际发生时才会进行计算。view是一种特殊的、轻量级的range。
|可以组成管线的原因是重载了operator |
| 特性 | range | view |
|---|---|---|
| 是否是概念 | ✅ 是 | ✅ 是 |
| 是否可以遍历 | ✅ 可以 | ✅ 可以 |
| 是否拥有数据 | 可能有 | ❌ 通常没有(或只是引用) |
| 是否惰性计算 | ❌ 一般是立即 | ✅ 是惰性的 |
| 是否轻量级 | 不一定 | ✅ 是 |
| 能否组合管道 | ❌(要借助 ranges) | ✅ 完美支持管道 . |
- 所有的 view 是 range
- 但不是所有的 range 是 view
- view 是你能用
|管道连接的东西(懒惰组合) - range 更像是 “你能遍历的容器或结构”的大集合
LLVM的dense map解析
https://zhuanlan.zhihu.com/p/669307116
讲的非常好
C++ ABI的真正理解
https://zhuanlan.zhihu.com/p/692886292
ASIO 的使用技巧
https://mmoemulator.com/p/going-super-sonic-with-asio/#skippable-preamble
GCC的代码模型
https://eli.thegreenplace.net/2012/01/03/understanding-the-x64-code-models
CMAKE杂记
普通库就是编译+链接,对象库只编译不链接,接口库不编译不链接。
接口库的作用:
当您在 CMake 中创建一个 INTERFACE 库并为其设置一些属性(如编译器选项、定义或包含目录),然后其他目标链接到这个 INTERFACE 库时,这些属性就会自动应用到链接到它的所有目标。
在您提到的情况中,假设有一个 some_header.hpp 被多个 .cpp 文件包含,在 CMake 中使用 INTERFACE 库可以确保每次编译这些 .cpp 文件时都使用相同的编译器选项。这种方式简化了管理编译选项的复杂性,因为您只需要在一个地方指定这些选项,而它们就会自动应用到所有依赖的目标上。
下面是一个具体示例:
Step 1: 创建一个 INTERFACE 库,并设置属性。
1
2
3
add_library(some_interface_lib INTERFACE)
target_include_directories(some_interface_lib INTERFACE ${CMAKE_CURRENT_SOURCE_DIR}/include)
target_compile_definitions(some_interface_lib INTERFACE SOME_DEFINE=1)
Step 2: 确保你的目标链接到这个 INTERFACE 库。
1
2
3
4
5
add_executable(some_executable main.cpp)
target_link_libraries(some_executable PRIVATE some_interface_lib)
add_library(some_other_lib some_other_source.cpp)
target_link_libraries(some_other_lib PUBLIC some_interface_lib)
在上面的例子中,无论是 some_executable 还是 some_other_lib,任何时候它们的编译单元包含了 some_header.hpp,都会自动应用 some_interface_lib 的属性,即添加了 ${CMAKE_CURRENT_SOURCE_DIR}/include 到包含路径,以及定义了预处理器宏 SOME_DEFINE=1。
通过这种方式,CMake 保证了构建系统的一致性和易于维护,同时避免了在多个地方重复相同的编译配置。
接口库示例
1
2
3
4
5
add_library(test_interface INTERFACE) // 创建一个名为 test_interface 的接口库
// 这里没有指定源文件,因为接口库不生成二进制文件;它只用来携带相关的编译器和链接器选项。
target_include_directories(test_interface INTERFACE ${CMAKE_CURRENT_LIST_DIR}/include) // 为test_interface 添加包含目录
// 这使得任何链接到 test_interface 的目标都会在编译时包含 ${CMAKE_CURRENT_LIST_DIR}/include 目录。
// 比如如果某一个其他的目标使用target_link_libraries命令来链接test_interface, 那么这个目标也会包含${CMAKE_CURRENT_LIST_DIR}/include 目录
这就是为什么header-only非常适合使用interface库。因为header-only没有源文件,自然不会有目标文件。当我的某个目标是一个header-only的库的时候,设置为接口库就相当于让每一个包含了这个header-only的库都自动使用同一份目录和编译选项(如有)
其他参考文章
memset 不可用于显式清除内存数据
若
memset所修改的对象在其生存期的剩余部分不再被访问,则此函数可以被优化掉(在如同规则下)(例如 gcc 漏洞 8537)。为此,此函数不能用于擦洗内存(例如以零填充存储密码的数组)。对
memset_explicit和memset_s禁止此优化:保证进行内存写。
这个bug来自PPSSPP代码报告这里的N18
1
2
3
4
5
6
7
8
9
10
11
12
void sha1_hmac( unsigned char *key, int keylen,
unsigned char *input, int ilen,
unsigned char output[20] )
{
sha1_context ctx;
sha1_hmac_starts( &ctx, key, keylen );
sha1_hmac_update( &ctx, input, ilen );
sha1_hmac_finish( &ctx, output );
memset( &ctx, 0, sizeof( sha1_context ) ); // <<!
}
因为memset 存在Dead Store Elimination,所以这个memset可能会被优化掉,导致内存数据并没有被清除
std::launder
什么是launder
launder和const、编译器的常量传播之间的神秘关系 查看Const and optimizations一节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <new>
#include <iostream>
struct A { int x = 1; };
struct B { int y = 42; };
int main() {
alignas(B) char buffer[sizeof(B)]; //必须和B对齐不然炸了
A* a = new (buffer) A;
std::cout << a->x << "\n";
// 用 placement new 在同一块内存构造另一个类型
B* b = new (buffer) B;
// 直接访问 b->y 是 **未定义行为**!
// 因为优化器认为这块内存“本来是 A”,没有新对象被构造
std::cout << std::launder(b)->y << "\n"; // 正确做法
}
这个东西的核心就是刷新编译器的“类型视角”:告诉它这里是新构造出来的对象,也就是强制编译器 重新加载指针指向对象;可以查看标准文档的 17.6.5[ptr.launder]
range based for loop的临时范围初始化器的雷
查看这里和这里。弄清楚何时会导致引用绑定的临时对象失效。以及在这里的Errors in object lifetime: lifetime extension章节看一下临时对象的生命周期被临时范围初始化器错误的延长
以及这里的Errors in object lifetime: a fly in the syntactic sugar (range-based for)一章看范围for循环的生命周期问题。
其实说白了核心是一点:
总而言之,临时量的生存期不能以进一步“传递”来延续:从绑定了该临时量的引用或数据成员初始化的第二引用不影响临时量的生存期。
范围初始化器可以抽象看成是这样的形式:
1
2
3
4
5
6
7
8
9
10
11
/*
属性(可选) for ( 初始化语句(可选) 项声明 : 范围初始化器 ) 语句
*/
{
auto&& /* range */ = 范围初始化器;
for (auto /* begin */ = /* 首表达式 */, /* end */ = /* 尾表达式 */;
/* begin */ != /* end */; ++/* begin */){
项声明 = */* begin */;
语句
}
}
假设我们有这种代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
struct Point {
int x;
int y;
};
struct Shape {
public:
using VertexList = std::vector<Point>;
explicit Shape(VertexList v) : vertexes(std::move(v)) {}
const VertexList& Vertexes() const { // 1 返回const&
return vertexes;
}
VertexList vertexes;
};
Shape MakeShape() {
return Shape { Shape::VertexList{ {1,0}, {0,1}, {0,0}, {1,1} } };
}
int main() {
for (auto v : MakeShape().Vertexes()) { // 2 注意这种范围初始化器初始方式
std::cout << v.x << " " << v.y << "\n";
}
std::cout << " " << std::endl;
for (auto v : MakeShape().vertexes) { // 3 注意这种范围初始化器初始方式
std::cout << v.x << " " << v.y << "\n";
}
}
/*
7363 0
-1948417267 -1125936379
0 0
1 1
1 0
0 1
0 0
1 1
*/
我们注意到方法2输出垃圾值。方法3是OK的 这就是雷点。
我们已经知道了,临时量的生存期不能以进一步“传递”来延续:从绑定了该临时量的引用或数据成员初始化的第二引用不影响临时量的生存期。我们手动“扩展一下”这个范围循环
1
2
auto&& /* range */ = MakeShape().Vertexes(); // 方法2
auto&& /* range */ = MakeShape().vertexes; // 方法3
我们已经发现端倪。方法2的Vertexes()函数调用返回的临时对象已经绑定到了函数返回值的const &虽然后续被绑定到了auto&& 但是无法被二次延长。方法3当中没有方法2那种函数返回值从中作梗,所以正确的被auto&&延长了生命周期。
如何避免这个雷
- 记得对任何const类型的函数进行rvalue限定的重载
- 针对范围for循环的范围初始化器,一定仅使用变量本身或者它的成员变量。
- C++20后使用新语法
- 如果有机会,使用
std::ranges::for_each
浮点数的各种判断是否为0
算术运算溢出相关的未定义行为
https://pvs-studio.com/en/blog/posts/cpp/1136/
C++中,f(x) 有多少种可能?
https://biowpn.github.io/bioweapon/2024/11/12/what-does-f-x-mean.html 强烈建议看一下
Proxy库
- https://redhand.com.cn/2025/01/02/proxy-convension/
ECS模式的数据结构设计
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
#include <vector>
#include <cassert>
template<typename T>
class DenseSparseArray {
public:
// 插入元素(假设 entity 是唯一标识)
void insert(uint32_t entity, const T& value) {
if (entity >= sparse.size()) {
sparse.resize(entity + 1, -1); // -1 表示无效索引
}
if (sparse[entity] == -1) {
sparse[entity] = dense.size();
dense.push_back({entity, value});
}
}
// 删除元素
void erase(uint32_t entity) {
if (contains(entity)) {
size_t dense_idx = sparse[entity];
auto& last = dense.back();
// 将要删除的元素与最后一个元素交换
std::swap(dense[dense_idx], last);
sparse[last.entity] = dense_idx;
dense.pop_back();
sparse[entity] = -1;
}
}
// 访问元素
T& operator[](uint32_t entity) {
assert(contains(entity));
return dense[sparse[entity]].value;
}
// 判断是否存在
bool contains(uint32_t entity) const {
return entity < sparse.size() && sparse[entity] != -1;
}
// 迭代器支持
auto begin() { return dense.begin(); }
auto end() { return dense.end(); }
private:
struct Element {
uint32_t entity;
T value;
};
std::vector<int> sparse; // 稀疏数组(存储索引)
std::vector<Element> dense; // 密集数组(实际数据)
};
enseSparseArray<int> arr;
arr.insert(100, 42); // 插入 entity=100
arr.insert(200, 77); // 插入 entity=200
std::cout << arr[100]; // 输出 42
arr.erase(100); // 删除 entity=100
for (auto& elem : arr) { // 遍历所有有效元素
std::cout << elem.entity << ": " << elem.value << "\n";
}
匿名联合体
在folly中,有这样一段代码
1
2
3
4
5
6
7
8
9
10
11
12
template <typename T>
class ResultHolder {
protected:
ResultHolder() {}
~ResultHolder() {}
// Using a separate base class allows us to control the placement of result_,
// making sure that it's in the same cache line as the vtable pointer and the
// callback_ (assuming it's small enough).
union {
Try<T> result_;
};
};
这个类里面的union叫做匿名联合体。为啥要把result用union包一下?目的是防止T类型没有默认构造函数导致编译错误。因为匿名联合体内的成员不会被默认初始化。
https://zh.cppreference.com/w/cpp/language/default_initialization
在默认初始化章节中提到了。
包括标准库文档的11.9.3[class.base.init]节:
- otherwise, if the entity is an anonymous union or a variant member (11.5.2), no initialization is performed;
同时。如果一个类包含了一个匿名联合体,则这个匿名联合体不会被初始化
https://zh.cppreference.com/w/cpp/language/constructor
在开始执行组成构造函数体的复合语句之前,所有直接基类、虚基类和非静态数据成员的初始化均已结束。这些对象的非默认初始化只能在成员初始化器列表指定。对于不能默认初始化的基类,和不能以默认初始化或以其默认成员初始化器(如果有)(C++11 起)初始化的非静态数据成员,例如引用和 const 限定的类型的成员,必须指定成员初始化器。(注意,类模板实例化的非静态数据成员的默认成员初始化器,当成员类型或初始化器待决时可能是无效的。)(C++11 起)对没有成员初始化器或默认成员初始化器(C++11 起)的匿名联合体或变体成员不进行初始化。
一定要区分联合体和匿名联合体
1
2
3
4
5
6
7
8
9
10
11
template <typename T>
class ResultHolder {
public:
union {
T result_;
}; // 匿名联合体
union s{
T result_;
} // 联合体 但是这里只有声明没有定义
s s_; //定义 但是报错。因为不是匿名联合体依旧会被尝试初始化
};
我们可以看一个简化版的最小实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
#include <iostream>
#include <new> // for placement new
struct A {
int x;
A() = delete; // 禁止默认构造
A(int v) : x(v) { std::cout << "A(" << v << ") constructed\n"; }
~A() { std::cout << "A destroyed\n"; }
};
// folly 风格的 ResultHolder
template <typename T>
class ResultHolder {
public:
ResultHolder() {} // 允许默认构造,但不会初始化 result_
~ResultHolder() {
// 不能换成
// result_.~T();
// 因为我们不能确保T被构造过。生命周期管理需要对称,T是手动构造就必须手动析构。
} // 允许默认析构,但需要手动析构 result_
// 使用 匿名union 避免默认构造,同时不提供额外的默认构造函数
union {
T result_;
};
// T result_; // 如果用这种就会报错
};
int main() {
// 由于 result_ 没有默认构造,需要手动构造
ResultHolder<A> holder;
new (&holder.result_) A(42); // 使用 placement new 构造 A
std::cout << "A.x = " << holder.result_.x << "\n";
// 手动调用析构,否则会产生未定义行为
holder.result_.~A();
return 0;
}
thread local 线程存储期的性能瓶颈
https://yosefk.com/blog/cxx-thread-local-storage-performance.html 这篇文章详细介绍了TLS (thread local storage)对象的性能瓶颈。说白了:
tls对象在有类/构造函数维护 + fpic共享库需要额外调用__tls_get_addr 成为性能瓶颈
优化指南
- TLS对象尽可能合并
- 不要为TLS写构造函数
- 为频繁访问的对象使用__attribute__((visibility(“hidden”)))
- 为关键变量使用__attribute__((tls_model(“initial-exec”)))
- 如果不是共享库,不要使用fpic (静态库链接到二进制,可以去掉)
- 考虑使用编译器加速 比如-mtls-dialect=gnu2
- 使用pthread key分配+自定义pthread_getspecifc绕过
设计几种迭代器
https://johnfarrier.com/7-interesting-and-powerful-uses-for-c-iterators/?utm_source=rss&utm_medium=rss&utm_campaign=7-interesting-and-powerful-uses-for-c-iterators
个人理解里面有几种还是很有意思的。比如:
无限序列迭代器,适用于生成一些数字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include <iostream>
#include <iterator>
class fibonacci_iterator {
long long a = 0, b = 1;
public:
using iterator_category = std::input_iterator_tag;
using value_type = long long;
using difference_type = std::ptrdiff_t;
using pointer = const long long*;
using reference = const long long&;
fibonacci_iterator& operator++() {
// 注意这里写的是前置自增
long long temp = a;
a = b;
b += temp;
return *this;
}
long long operator*() const { return a; }
// Always true for infinite sequences
bool operator!=(const fibonacci_iterator&) const { return true; }
};
int main() {
auto it = fibonacci_iterator();
for (int i = 0; i < 10; ++i, ++it) { // 前置自增
std::cout << *it << " ";
}
}
类似于transform作用的迭代器适配器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
#include <iostream>
#include <vector>
#include <iterator>
#include <algorithm>
template <typename Iter, typename Func>
class transform_iterator {
Iter it;
Func func;
public:
using iterator_category = std::input_iterator_tag;
using value_type = typename std::result_of<Func(
typename std::iterator_traits<Iter>::value_type)>::type; // 萃取一下函数调用的返回类型
using difference_type = std::ptrdiff_t;
using pointer = value_type*;
using reference = value_type;
transform_iterator(Iter iter, Func f) : it(iter), func(f) {}
transform_iterator& operator++() {
// 还是,前置自增
++it;
return *this;
}
reference operator*() const {
// 注意 这重载的是解引用操作符。不是乘法。乘法是二元,解引用是一元。
// 这里的目的是搭配一些STL库的算法。比如copy是解引用赋值。
// 返回reference类型的原因是解引用操作符希望返回一个引用,这样才能被赋值。
return func(*it);
}
bool operator!=(const transform_iterator& other) const { return it != other.it; }
};
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5};
std::vector<int> squares{};
auto square = [](int x) { return x * x; };
auto begin = transform_iterator(numbers.begin(), square);
auto end = transform_iterator(numbers.end(), square);
std::copy(begin, end,
std::back_inserter(
squares)); // 用back inserter往里面插。因为一开始没初始化,所以直接给迭代器
for (auto i : squares) {
std::cout << i << std::endl;
}
}
就地过滤迭代器 in-place filter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#include <iostream>
#include <vector>
class filtering_iterator {
using vec_it = std::vector<int>::iterator; // 简化实现。实际上应该使用模板参数
vec_it current, end;
int threshold;
public:
filtering_iterator(vec_it begin, vec_it end, int th) : current(begin), end(end), threshold(th) {
advance();
}
filtering_iterator& operator++() {
current = current == end ? end : current + 1; // 如果是end就返回end,不然就+1
advance();
return *this;
}
int operator*() const { return *current; }
bool operator!=(const filtering_iterator& other) const { return current != other.current; }
private:
void advance() {
while (current != end && *current < threshold) {
current = current + 1; // 跳过小于阈值的元素
// 这里用 != 而不是 <是因为只有随机迭代器支持关系性比较
// 另外只能+1,不然迭代器失效就炸了。如果要+n的话需要再套一个while
}
}
};
int main() {
std::vector<int> data = {1, 5, 2, 8, 3, 10, 4};
int threshold = 9;
std::cout << "Filtered values: ";
for (filtering_iterator it(data.begin(), data.end(), threshold);
it != filtering_iterator(data.end(), data.end(), threshold); ++it) {
// 注意一点,我们用迭代器一般都是在for循环语句内现场创建,而不是在外面创建再传进去
std::cout << *it << " ";
}
}