C++ template
此笔记应和杂记3的模板相关部分搭配查看。
第一章 函数模板
https://youtu.be/XN319NYEOcE
0.0 一些深度理解,必须提前知道
只有函数模板(function template), 没有模板函数(templated function)。类模板同理
函数(主)模板并不是函数。函数模板没有类似于函数的行为。类模板同理
- 函数主模板本身并不能调用。
- 我们表面上是调用了函数主模板,但是实际上是编译器推导出(或我们自己指定出)类型后,编译器将所有的
T替换为对应类型。然后合成出来的一个新的实例。这就是实例化。 - 所以,函数主模板本身从不是重载决议候选人(candidate)。候选人是编译器帮助我们替换了
T之后的实例化的函数。

https://youtu.be/NIDEjY5ywqU
- 编译器会通过函数的(主)模板,合成(synthesize)一个特化的函数声明(declaration)[其实是签名signature]。然后实例化(instantiate)这个函数的定义(definition)。
- 它会首先检验函数的调用,通过查看传入的参数或显式指定的参数获取类型。
- 然后替换所有的占位符
T - 最后我们得到了一个用于重载决议的候选对象,也就是个函数。
0.1 部分名词解析
- 我们知道编译器处理模板代码的时候会进行替换,也就是把每一个
T替换成传入的模板参数。这个过程被称之为模板的实例化( instantiation) - 一旦我们有了实例化的动作,我们就拥有了一个函数。这个函数被称之为特化(specialization)。在这个时候,
T已经被替换为对应类型。特化是特定于类型的。他们关心类型,现在不再是类型不可知得了。类模板也一样 - 特化过的类模板或函数模板,或说编译器已经通过类模板和函数模板合成出来的附带了特定类型的类或函数的行为和普通的类和函数是一致的。
- 但是我们依旧可以使用
<>来显式指定一个被关联到模板参数的、被进行了特殊替换的声明。比如这样:- 为了区分编译器帮助我们进行的特化,针对这种情况,我们称之为显式(全)特化(explicit specialization)
- 一般来讲,显式特化被认为是通用模板的一种特殊形式。
1
2
3
4
5
6
7
8
template<typename T1, typename T2> // 主模板
class MyClass {
//一些内容
};
template<> // 显式全特化。
class MyClass<std::string,float> {
//一些内容
};
- 如果在显式全特化后,仍需要添加一些模板参数,我们就称之为[显式]部分特化(偏特化)
1
2
3
4
5
6
7
8
template<typename T> // 偏特化
class MyClass<T,T> {
//一些内容
};
template<typename T> // 偏特化
class MyClass<bool,T> {
//一些内容
};
0.2 显式实例化(14.5),隐式实例化和特化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template<typename T>
void func(T a){
cout << a << endl;
}
template
void func<float>(float a); //2 显式实例化
template
void func<>(int a); //也可以
int main(){
func(10); //1 隐式实例化
func<int>(10); //也叫隐式实例化。没错,显式指明模板参数会导致隐式实例化。
return 0;
}
- 这个过程叫做隐式实例化。隐式实例化指的是函数或类模板被使用或调用的时候,由编译器帮助我们处理的过程。因为编译器帮助我们合成了这个函数的声明,实例化了函数的定义。这个
func(10)本身是一个特化的函数。 - 这个过程叫做显式实例化,也叫做外部实例化。显示实例化的意义在于在不发生函数调用的时候就已经将函数模板实例化,或者在不使用类模板的时候就已经将类模板实例化称之为模板显示实例化。这个
void func<float>(float a)函数本身也是一个特化的函数。- 显式实例化只需要写声明,不需要写定义。也就是我们通知编译器,直接根据这个声明,实例化这个函数定义。
- 无论是编译器帮助我们合成后实例化的,还是我们自己显式特化的,只要这个函数有了明确的类型要求,这就是一个特化的函数。(和函数模板相比)
- 显式特化在上一节。
- 显示实例化和显式特化的语法区别在于显式实例化的
template关键字后不加<>,显式特化的template关键词后要加<> - 当一个函数模板被定义在一个头文件中且被多个源文件包含时,每个包含该头文件的源文件都会产生模板的实例化。通常情况下,因为模板是内联的,这不会导致链接错误。然而,如果你显式地实例化了模板函数或者类模板,则可能会遇到链接问题。显式实例化告诉编译器在给定的翻译单元(通常是一个.cpp文件)中创建模板的具体实现。如果在多个源文件中进行了相同模板的显式实例化,那么链接器将报告重复定义错误。当然了, 如果使用了显式实例化, 则在其他需要用到该模板的地方需要使用外部模板声明.
1
extern template void func<int>(int a);
extern 模板声明用于防止模板在当前翻译单元中被实例化. 这种情况下, 该函数的调用不会导致模板在当前翻译单元中实例化, 因为已经在外部单元实例化过了.
什么时候用extern
通常来说, 我们知道模板 的声明和定义需要写在一起. 如果这样做, 我们最好在外部使用extern template减少文件大小. 原因是所有include了该头文件的翻译单元都会合成一份独立的函数模板, 最后在链接期间丢弃多余的符号. 比如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
// a.h
#pragma once
#include <iostream>
struct f {
template <typename T>
void ReallyBigFunction();
};
template<typename T>
void f::ReallyBigFunction(){
std::cout << "ReallyBigFunction" << std::endl;
}
// b.cpp
#include "a.h"
#include "iostream"
extern template void f::ReallyBigFunction<int>(); // 注意这里
void something1()
{
f o;
o.ReallyBigFunction<int>();
}
// c.cpp
#include "a.h"
#include "iostream"
void something2()
{
f o;
o.ReallyBigFunction<int>();
}
int main(){
}
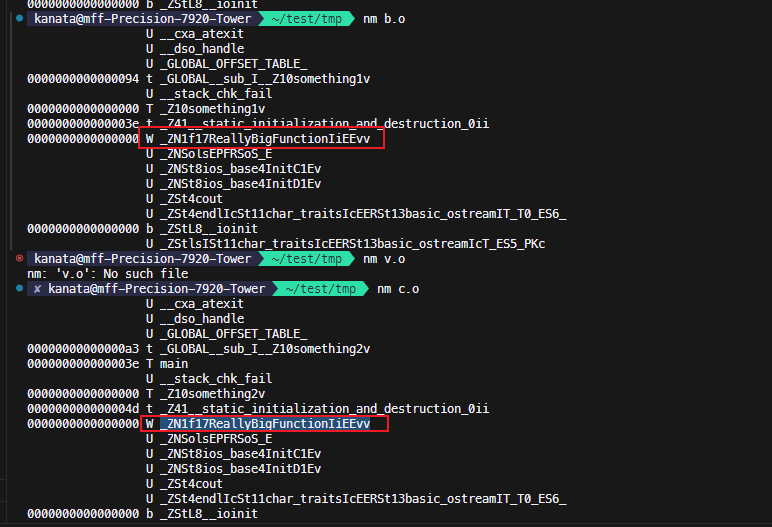
我们看到图片里, 如果我们在b.o不加extern, 那么b.o和 c.o都生成了同一个函数的符号.
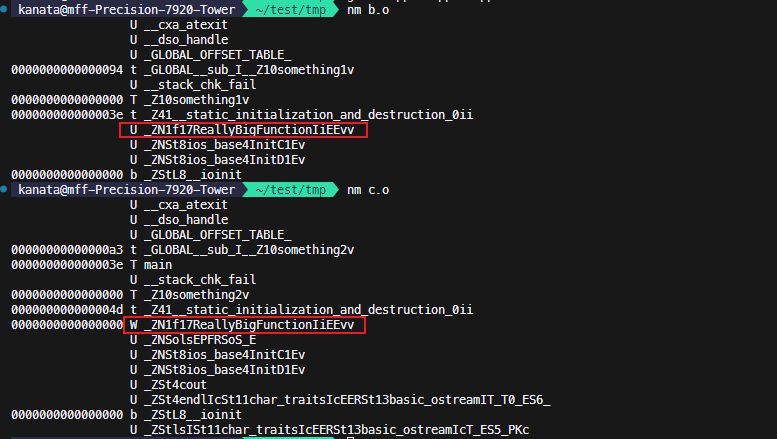
如果有extern, 则b.o里的符号变成了U 而c.o里保持不变.
然而如果我们用另一种写法, 也就是.h文件只包含模板声明, 模板定义在.cpp文件中, 同时在.cpp文件中显式实例化所需模板. 这样做的话, 其他文件就不需要使用extern.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// a.h
#pragma once
#include <iostream>
struct f {
template <typename T>
void ReallyBigFunction();
};
// a.cpp
#include "a.h"
#include <iostream>
template<typename T>
void f::ReallyBigFunction(){
std::cout << "ReallyBigFunction" << std::endl;
}
template void f::ReallyBigFunction<int>();
显示实例化和隐式实例化在类模板中的差异
隐式实例化的时候,编译器会合成尽可能少的成员,但是显式实例化会让类模板合成全部的成员。
然而,成员函数可以被单独地显式实例化。
https://youtu.be/XN319NYEOcE?t=3152
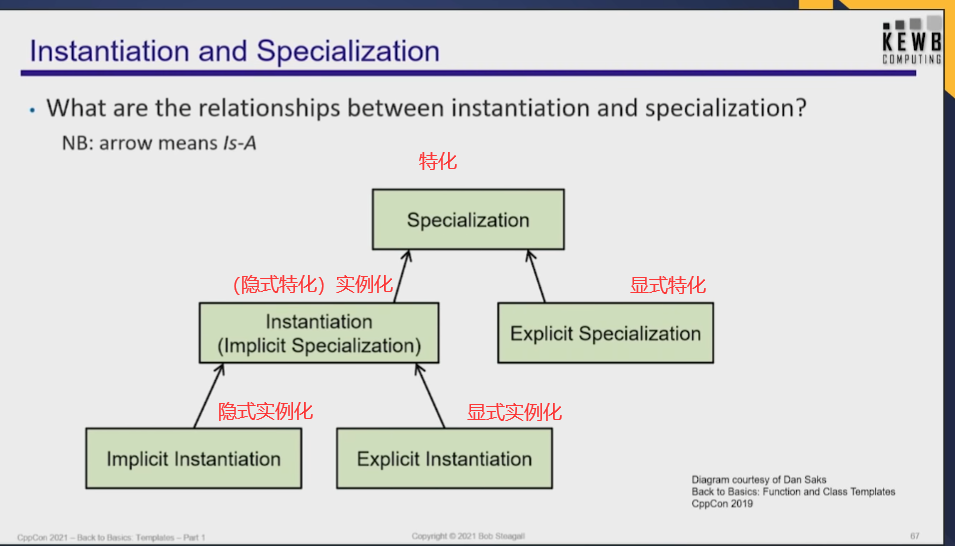
这里的实例化既代表了过程也代表了最后的实体
最后的总结就是:
- 我们可以通过显式实例化或隐式实例化的方式达成隐式特化的目标。(这一阶段就是编译器默认合成出来的函数或类)
- 同时我们也可以通过显式特化的方式来特化一个模板。(这个指的是通过显式指定类型来让编译器和成出函数或类)
0.3 声明和定义
我们在杂记当中已经解释了什么是声明和定义,这里针对上下文再次强化一下认知:
- “声明”将一个名称引入或者再次引入到一个 C++作用域内。引入的过程中可能会包含这个名称的一部分类别,但是一个有效的声明并不需要相关名称的太多细节。比如:
1
2
3
class C; // 类C的声明
void f(int p); // 函数f的声明
extern int v; // 变量v的声明。注意这里使用了extern
- 对于声明 ,如果其细节已知, 或者是需要申请相关变量的存储空间,那么声明就变成了定义。
- 对于 类类型的定义和函数定义,意味着需要提供一个包含在
{}中的主体,或者是对函数使用了=defaut/=delete。 - 对于变量,如果进行了初始化或者没有使用
extern,那么声明也会变成定义。下面是一些“定义”的例子:
- 对于 类类型的定义和函数定义,意味着需要提供一个包含在
1
2
3
4
5
6
class C {}; // 声明并定义 类C
void f(int p) { //声明并定义函数f
std::cout << p << ’\n’;
}
extern int v = 1; // 因为初始化了,所以这里也是声明并定义了变量v
int w; // 全局变量,就算没有初始化,由于没有使用extern,所以也是声明并定义变量w
- 如果一个类模板或者函数模板有包含在
{}中的主体的话,那么声明也会变成定义。所以
1
2
3
4
5
template<typename T>
void func (T); //这个是声明。
template<typename T>
class S {}; //这个是定义。
0.4 模板形参和模板实参
1
2
3
4
5
template<typename T1> // T1 是模板形参,形式上的参数。 parameter
class test;
int main(){
test<int> obj; //int 是模板实参,实际传入的参数。 argument
}
简单来讲可以说:模板参数是被模板实参初始化的。或者更准确的说:
- 模板参数是那些在模板定义或者声明中,出现在 template 关键字后面的尖括号中的名称。
- 模板实参是那些用来替换模板参数的内容。不同于模板参数,模板实参可以不只是名称。
0.5 模板名(template-name) 和 模板标识(template-id)
- 模板名,顾名思义就是模板的名字。如下面例子的
Demo就是模板名。 - 模板标识,是模板名和其参数列表。也就是整个
模板名<形参列表>是一个模板标识。下面的Demo<int>就是模板标识。
1
2
3
4
5
6
7
8
9
10
template <typename T>
struct Demo{
// ...
};
int main()
{
Demo <int> d; // Demo 是 template name, Demo<int> 是 template-id
// ...
}
https://zh.cppreference.com/w/cpp/language/templates
https://stackoverflow.com/questions/3796558/difference-between-template-name-and-template-id
- 当指出模板的模板标识 的时候,用模板实参替换模板参数的过程就是显式的,但是在很多情况这一替换则是隐式的(比如模板参数被其默认值替换的情况。一个基本原则是:任何模板实参都必须是在编译期可知的。就如接下来会澄清的,这一要求对降低模板运行期间的成本很有帮助。由于模板参数最终都会被编译期的值进行替换,它们也可以被用于编译期表达式。
0.6 不推导语境
因为比较分散,所以请在笔记内搜索关键词: 不推导语境
1.1.2 基本信息
在声明模板变量类型的时候,尽量使用typename而非class。尽管没有区别。
所有的模板类型参数都应该可以被推导或有默认值。不应该无法推导的模板参数,会导致错误。(个人推理)函数模板有两种类型的参数:
- 模板参数:位于函数模板名称的前面,在一对尖括号内部进行声明:
1
template <typename T> //T是模板参数
- 调用参数:位于函数模板名称之后,在一对圆括号内部进行声明:
1
T max (T const& a, T const& b) //a和b都是调用参数
- 一定要让函数模板的所有重载版本的声明都位于它们被调用的位置之前(一般都放在同一个头文件中)
1.1.3 二阶段检查。搭配深度探索对象模型里面的模板一起看。
- 模板的工作原理,并不是把模板编译成一个可以处理任何类型的单一实体;而是对于实例化模板参数的每种类型,都从模板产生(合成)出一个不同的实体。
在实例化模板的时候,如果模板参数类型不支持所有模板中用到的操作符,将会遇到编译期错误。
但是在定义的地方并没有遇到错误提示。这是因为模板是被分两步编译的。所以我们可以说:在实例化时,模板被编译了两次,分别发生在模板定义阶段(实例化之前),和模板实例化阶段(实例化期间)
- 在模板定义阶段,模板的检查并不包含类型参数的检查。只包含下面几个方面:
- 语法检查。比如少了分号。
- 使用了未定义的不依赖于模板参数的名称(类型名,函数名,……)。
- 未使用模板参数的
static assertions。 - 简而言之,就是先检查模板代码本身,查看语法是否正确;在这里会发现错误语法,如遗漏分号等。
- 在模板实例化阶段,为确保所有代码都是有效的,模板会再次被检查,尤其是那些依赖于类型参数的部分。
- 检查模板代码,查看是否所有的调用都有效。在这里会发现无效的调用,如该实例化类型不支持某些函数调用等。
举例:
1
2
3
4
5
6
7
8
template<typename T>
void foo(T t)
{
undeclared(); // 如果 undeclared()未定义,第一阶段就会报错,因为与模板参数无关
undeclared(t); //如果 undeclared(t)未定义,第二阶段会报错,因为与模板参数有关
static_assert(sizeof(int) > 10,"int too small"); // 与模板参数无关,总是报错
static_assert(sizeof(T) > 10, "T too small"); //与模板参数有关,只会在第二阶段报错
}
需要注意的是,有些编译器并不会执行第一阶段中的所有检查。因此如果模板没有被至少实例化一次的话,你可能一直都不会发现代码中的常规错误。
1.1.4 编译和链接
由于 C++中使用的是静态模板的机制,所以当使用函数模板,并且引发模板实例化的时候,编译器(在某时刻)需要查看模板的定义。这就不同于普通函数中编译和链接之间的区别,因为对于普通函数而言,只要有该函数的声明(不需要定义),就可以顺利通过编译。因为在这里需要的是定义,所以可以考虑在头文件内部实现每个模板以使编译器能够顺利的找到模板的定义。
- 假设我们有一个模板类的
.h和一个.cpp文件,还有一个使用了模板类的.cpp文件,这个文件include了.h文件而不是.cpp文件。首先头文件不编译。声明被拷贝至使用的文件。这时候我们使用了这个模板。由于C++是分离编译。所以在当前文件下没有问题,会留下函数符号让链接器去寻找。然后我们开始编译模板的.cpp文件。模板是二段式编译。也是由于是分离编译,但是在模板的.cpp中,我们只有函数定义但是没有使用函数。所以只会进行第一段也就是检查是否有错误。因为没有实例化所以根本不会进行第二段的编译。所以这时候我们使用的文件中就会有无法解析的外部符号了。 - 所以这个时候我们要么把
.h和.cpp文件放到一起写然后include.hpp文件, - 要么就在在使用文件中不
include.h而是include.cpp
1.2 函数模板参数类型推断
没啥特别要说的,注意两点:
- 一个是模板形参是万能引用
T&&的时候触发的引用折叠。 - 另一个是利用函数参数自动推导出的模板参数右值引用,只可能推导出左值引用或者基本类型。这点看下面的推导表格就能发现,
T永远不会被推导成&&。都是推导成非引用或左值引用版本,然后和T后附加的&或&&形成引用折叠- 注意是永远不会推导出而不是永远不会成为。这也说明了为什么
std::forward在一般情况下触发的都是左值版本,除非显式指明为右值引用如forward<int&&>(5)。参考杂记1
- 注意是永远不会推导出而不是永远不会成为。这也说明了为什么
1.2.1 函数模板参数类型推导中的类型转换
下文的A是实参类型,P是形参类型。
- 在类型推断的时候自动(隐式)的类型转换是受限制的。因为类型转换是重载决议做的事情,类型推断不负责。而且类型推导发生在重载决议前面。(所以如果它通过入参推导出来的类型和函数形参不匹配,就不行):
- 首先实参的引用属性被忽略(A 的引用属性被忽略.)
- 如果 形参是有 cv 限定的类型,那么推导时会忽略顶层 cv 限定符
- 如果调用参数是按引用传递的,任何类型转换都不被允许。通过模板类型参数 T 定义的两个参数,它们实参的类型必须完全一样。每个 T 都必须正确匹配。
- 如果形参是引用类型,那么用形参所引用的类型推导。
- 如果调用参数是按值传递的(形参是非引用的时候),那么只有退化(decay)这一类简单转换是被允许的:(和杂记里面的函数模板参数推导一样)
const和volatile限制符会被忽略 (实参 的 顶层 cv 限定符被忽略.)- raw array(原始数组) 和函数被转换为相应的指针类型。(如果 A 是数组或函数, P 是值时, 数组和函数退化为指针. )
- (隐藏,此处不相干,但还是放在这里。和杂记中的函数模板参数推导一样)如果 P 是无 cv 限定符的转发引用 (即 T&&), 且 A 是左值时, T 被推导为左值引用.
- 通过模板类型参数 T 定义的两个参数,它们实参的类型在退化(decay) 后也必须一样
- 总结就是如果P是引用类型则不退化。P不是引用类型则发生上面的退化。
通常而言,你必须指定最后一个不能被隐式推导的模板实参之前的所有实参类型。也就是我们必须显式指定所有模板参数的类型,直到某一个模板参数的类型可以被推断出来为止。
然而,模板的实参推导并不适合返回类型(可以把推导看成是重载解析的一部分–重载解析是一个不依赖于返回类型选择的过程,唯一的例外就是转型操作符成员的返回类型)。
这里搭配7.2看。
举个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
template<typename T>
struct typewrapper{
typewrapper(T args){
}
};
void foo(typewrapper<tmp> f){
std::puts(__PRETTY_FUNCTION__);
cout <<"called" << endl;
}
template<typename... T>
void foo0(typewrapper<T...> f){
std::puts(__PRETTY_FUNCTION__);
cout <<"called" << endl;
}
void foo1(function<void(int, int, int)>){
cout <<"called" << endl;
}
template<typename... Args>
void foo2(function<void(Args...)>){
cout <<"called" << endl;
}
template<typename... Args>
void foo3(Args... F ){
cout <<"called" << endl;
}
int main(){
foo(typewrapper<tmp>(tmp{}));
foo(tmp{});
foo0(typewrapper<tmp>(tmp{}));
foo0(tmp{}); //不行
foo1(function<void(int, int, int)>(callablefunc));
foo1(callablefunc);
foo2(function<void(int, int, int)>(callablefunc));
foo2(callablefunc); //不行
foo3(function<void(int, int, int)>(callablefunc));
foo3(callablefunc); //可以
}
为啥
foo0和foo2的第二个都不行呢?因为参数类型推导中有冲突。但是foo和foo1都是非模板函数,或者说,参数推导没有冲突。比如foo3。这样的都可以。- 因为,
foo0的参数类型涉及到推导的部分应该是typewrapper模板的模板参数类型。所以T会被推导为tmp类型。但是这个foo0函数的参数所要求的类型应该是typewrapper<T>类型,两者类型不匹配。- 也就是:
T类型被推导为tmp,所以函数要求形参为typewrapper<tmp>类型,但是传入的参数类型为tmp类型。
- 也就是:
- foo2同理。
foo2的参数类型涉及到推导的部分应该是std::function模板的模板参数类型。所以Args...会被推导为int, int, int类型。但是这个foo2函数的参数要求的类型应该是function<void(Args...)>类型,两者类型不匹配。- 也就是:
Args...类型被推导为int, int, int,所以函数要求形参为function<void(int, int, int)>类型,但是传入的参数类型为void(*)(int, int, int)类型。
- 也就是:
- 至于
foo3为什么可以,因为foo3的Args...可以被推导为任何可能的类型,不涉及到需要类型转换的部分。比如如果传入函数指针,则会被推导为void (*)(int, int, int)。如果传入std::function对象,则会被推导为std::function<void(int, int, int)>
- 因为,

注意区别显式指定模板实参类型(不推导)和显式全特化
显式全特化是替换定义。
显式指定模板的实参类型是这样:
1
2
3
4
5
6
7
8
9
template <typename T>
void func(T a, T b){
cout <<"success" << endl;
}
int main() {
long lng = 2000;
func<int>(lng, 2); //显式指定模板实参类型
}
- 我们显式指定模板实参类型就等于避免了参数类型推断。所以可以隐式转换了!
比如上面的函数
1
2
func(lng, 2);//不行。一个是long一个是int。但是只有一个T类型
func<int>(lng, 2); //可以。显式指定T为int,lng被隐式转换了。
1.2.2 对默认调用参数的类型推断
需要注意的是,类型推断并不适用于默认调用参数。例如:
1
2
3
4
5
6
7
8
9
template<typename T>
void func(T a = 12){
cout << "called" << endl;
}
int main(){
func(1); //OK 没问题 推导为int
func(); //编译器发出抱怨,甚至想骂人。
return 0;
}
为应对这一情况,你需要给模板类型参数也声明一个默认参数
1
2
3
4
5
6
7
8
template<typename T = int> //注意这里
void func(T a = 12){ //这里
cout << "called" << endl;
}
int main(){
func(); //OK
return 0;
}
注意,给定的模板默认参数应该和函数默认参数的类型一致。
1.3 多个模板参数
好像是废话,但是水还是蛮深的。我们一起看一下。
1
2
3
4
5
6
7
8
template<typename T1, typename T2>
T1 func(T1 a, T2 b){
return b < a ? a : b;
}
int main(){
auto ret = func(1,2.345);
return 0;
}
- 看上去就和我们想的一样,它可以接受两个不同类型的调用参数。但是如示例代码所示,这也导致了一个问题:
- 如果你使用其中一个类型参数的类型作为返回类型,不管是不是和调用者预期地一样,当应该返回另一个类型的值的时候,返回值会被做类型转换。这将导致返回值的具体类型和参数的传递顺序有关。
- 例子:如果传递
2.345和1给这个函数模板,返回值是double类型 的2.345,但是如果传递1和2.345,返回值却是int类型的2。因为我们固定返回较大的数字。但是返回值类型会被进行隐式转换。
所以我们有三个方法解决这个问题:
- 引入第三个模板参数作为返回类型。
- 让编译器找出返回类型。
- 将返回类型定义为两个参数类型的“公共类型。
1.3.1 做为返回类型的模板参数
我们还记得模板有两种参数:模板参数和调用参数。
- 当模板参数和调用参数之间没有必然的联系,且模板参数不能确定的时候,就要显式的指明模板参数。比如你可以引入第三个模板来指定函数模板的返回类型
1
2
3
4
template<typename RT, typename T1, typename T2>
RT func(T1 a, T2 b){
cout << "called" << endl;
}
- 但是模板类型推断不会考虑返回类型,而
RT又没有被用作调用参数的类型。因此RT不会被推导。这样就必须显式的指明模板参数的类型。比如:
1
2
3
4
5
6
7
8
template<typename RT, typename T1, typename T2>
RT func(T1 a, T2 b){
cout << "called" << endl;
}
int main(){
func<int>(1,2.345); //注意。后面两个可以省略。因为可以被推导。
return 0;
}
通常而言,我们必须显式指定所有模板参数的类型,直到某一个模板参数的类型可以被推断出来为止。
1.3.2 利用auto,decltype 和(可选的)尾置返回类型进行返回类型推导
C++14开始可以使用auto和decltype 搭配(可选的)尾置返回类型对返回值类型进行推导。
1
2
3
4
5
6
7
8
9
10
template<typename T1, typename T2> //不使用尾置返回类型
auto func(T1& a, T2& b){
return b < a? a: b;
}
template<typename T1, typename T2> //使用尾置返回类型
auto func(T1& a, T2& b) -> decltype(b<a? a:b){
return b < a? a: b;
}
- 在不使用尾置返回类型(trailing return type)的情况下将
auto用于返回类型,要求返回类型必须能够通过函数体中的返回语句推断出来。当然,这首先要求返回类型能够从函数体中推断出来。因此,必须要有这样可以用来推断返回类型的返回语句,而且多个返回语句之间的推断结果必须一致。 - 注意
decltype推导过程是在编译期完成的,并且不会真正计算表达式的值。 - 此处要注意可能返回值类型可能会被推导为引用类型。请查看下面的文章。
decltype过于复杂,可以看这里decltype详解
尾置返回类型的 auto
尾置返回类型的 auto是占位符,所以:
1
auto (*fp)() -> auto = f;
这个情况下,第一个auto仅仅是占位符,语法层面的表达。只有第二个auto才会进行类型推导。来自这里
1.3.3 利用std::common_type将返回类型声明为公共类型(common type)
就是获得两个类型的公共类型。
1.4 模板默认参数
- 可以在模板默认参数中使用
common_type或者是decay来获取默认值。比如
1
2
3
4
5
template<typename T1, typename T2, typename RT = std::decay_t<decltype(true ? T1() : T2())>>
//也可以这样typename RT = std::common_type_t<T1,T2>>
RT max (T1 a, T2 b){
return b < a ? a : b;
}
- 和函数默认值不同,在函数模板参数中,即使后面的模板参数没有默认值,我们依然可以让第一个模板参数有默认值。并且此时调用时可以不显式指定
<>
1
2
3
4
5
6
7
8
template<typename RT = int, typename T1, typename T2>
RT func(T1 a, T2 b){
return a;
}
int main(){
auto c = func(1,2.234); //并且此时调用时可以不显式指定<>
return 0;
}
1.5 函数模板重载和显式全特化
像普通函数一样,函数模板也是可以重载的。也就是说,你可以定义多个有相同函数名的函数,当实际调用的时候,由 C++编译器负责决定具体该调用哪一个函数。即使在不考虑模板的时候,这一决策过程也可能异常复杂。
和普通函数一样,函数模板可以被重载。不止可以被重载,还可以进行特化。但是函数模板只能全特化。
- 决议顺序:普通函数 > 主模板(未特化的模板) > 全特化版本。因为越特化的可能越是需要的
- 当两个都为模板版本,则调用更特化的模板函数
- 因为越特化的可能是越实际要求的。
- 决议顺序:普通函数 > 主模板(未特化的模板) > 全特化版本。因为越特化的可能越是需要的
- 如果函数名指名了某个函数模板,那么首先进行模板实参推导
- 如果它成功,那么将会生成一个单独的模板特化并添加到所要考虑的重载集合中。
- 这一步骤结合0中提到的,通过函数模板合成一个函数,然后添加进重载决议候选人集合中
- 如果集合中有多于一个函数与目标匹配,且至少一个函数是非模板,那么从考虑集合中去除模板特化。
- 这一步是普通函数优先于模板合成出的函数。
- 如果所有剩余候选者都是模板特化,那么当存在更特殊的模板特化时,移除较不特殊者。如果在各项移除之后还有多于一个候选者,那么程序非良构。
- 这一步是如果剩余的函数都是模板函数,那么最特化的优先。如果在这之后还是多个函数,则会有隐含问题。
关于重载决议和匹配,写在文末。
- 如果函数模板和普通函数都可以实现(同名的函数模板可以被实例化为与非模板函数具有相同类型的调用参数),在所有其它因素都相同的情况下,优先调用普通函数而不是从模板实例化出来的函数。
- 如果模板可以实例化出一个更匹配的函数,那么就会优先调用模板函数。(!!!!!!比如如果普通函数涉及到任何级别的类型转换的时候,如果模板能直接合成出一个完美匹配的函数模板,则此时会调用模板合成的函数!!!!!!)
- 可以使用空模板参数列表
<>来强制调用函数模板 - 在模板参数推断时不允许自动类型转换,而常规函数是允许的。
当有多个特化的函数模板可以被匹配的时候,会有二义性导致报错。
- 函数模板显式全特化不能包含默认实参值。然而,对于被特化的模板所指定的任何默认实参,显式特化版本都可以应用这些默认实参值(其参数默认值会被保留)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template<typename T>
T f(T a, T b = 42)
{
cout <<"general" << endl;
cout << b << endl;
return b;
}
template<>
float f <float>(float a, float b = 42.2) // 错误
{
cout <<"special" << endl;
cout << b << endl;
return b;
}
template<>
double f <double>(double a, double b) // 可以
{
cout <<"special" << endl;
cout << b << endl;
return b;
}
f(4); //输出general 42
f(4.444); //输出special 42
- !!!注意,只有非模板和主模板重载参与重载决议。显式全特化并不是重载也从不参与重载决议,因此此时不受考虑。只有在重载决议选择最佳匹配的主函数模板后,才会考虑它的全特化版本以查看最佳匹配者。
- 因为显式全特化的函数模板没有独立名称。也就是不引入名称。因为它只是一个替换的定义,而不是一个替换的声明。
- 显式全特化不是重载。
1
2
3
4
5
6
7
8
template<class T>
void f(T); // #1:所有类型的重载
template<>
void f(int*); // #2:#1 的特化,针对指向 int 的指针
template<class T>
void f(T*); // #3:所有指针类型的重载
f(new int(1)); // 调用 #3,虽然 #1 的特化是完美匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
void test(int a, int b){
cout << "普通函数" << endl;
}
template <typename T>
void test(T a, T b){
cout << "模板函数" << endl;
}
template <typename T>
void test(T a, T b, T c){
cout << "重载的模板函数" << endl;
}
template<>
void test<int>(int a, int b, int c){
//void test(int a, int b, int c){ //可以去掉 <int>
cout <<"全特化" << endl;
}
int main(){
test(1,2); //输出普通函数
test<>(1,2); //使用空模板参数列表 输出模板函数
test(1.1,2.2,3.3); //输出重载的模板函数
test(1,2,3); //输出全特化
test<int>(1,2,3); //输出全特化
return 0;
}
- 为什么后两个都输出全特化?因为他们都是
int。多个候选者都为模板的时候,更特化的优先。- 目前只有两个模板可以接受三个参数。而此时
int可以匹配到下面的全特化版本,所以全特化版本优先。
- 目前只有两个模板可以接受三个参数。而此时
- 倒数第三个因为是
float。这样由于模板匹配的优先级大于类型转换。所以会被匹配到重载的模板函数。 - 通常而言,在重载模板的时候,要尽可能少地做改动。你应该只是改变模板参数的个数或者显式的指定某些模板参数。比如不要一会儿值传递一会儿引用传递。
- 函数的全特化是非常不好的设计。全特化提供的是一个替换的定义,而不是一个替换的声明。在调用函数模板的时点,该调用已经完全基于函数模板而完成解析了 [16.3.2]。所以:
- 无法在没有主模板的时候对函数模板进行全特化。
- 再次重申全特化的函数没有新的mangled的名字。也就是全特化函数没有独立名字。
- 类成员函数的全特化必须写在类外。
- 无法在没有主模板的时候对函数模板进行全特化。
- 如果是分文件编译,为了预防重定义导致的链接错误,必须把全特化的函数模板定义为
inline防止重定义。- 因为在链接器的眼里,函数模板在全特化之后和常规函数是一样的。
函数模板重载的例子
下面的重载都是合法的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
//允许参数顺序(因为类型顺序不同)不同
template<typename T1,typename T2>
void func(T1, T2){
}
template<typename T1,typename T2>
void func(T2, T1){
}
//允许返回值类型不同
template<typename T1>
int func1(T1){
}
template<typename T1>
char func1(T1){
}
//允许模板形参个数不同,允许函数形参个数不同
template<typename T1,typename T2>
void func2(T1, T2){
cout <<"2 typename" << endl;
}
template<typename T1>
void func2(T1, T1){
cout <<"1 typename " << endl;
}
template<typename T1>
void func2(T1){
cout <<"single param" << endl;
}
https://blog.csdn.net/qq_41453285/article/details/104447573
关于不要全特化函数和函数全特化的问题写在了最后面
所谓的类型转换和模板参数推导的关系
我们之前说过, 在模板参数推断时不允许自动类型转换,而常规函数是允许的。
1
2
3
4
5
6
7
8
9
template<typename T>
void func(T A, T B){
std::puts(__PRETTY_FUNCTION__);
}
int main(){
func(123.1, 2); //不可以
func<int>(123.1, 2); //可以
return 0;
}
但是为什么上面的第二种就可以呢?
关键在于 在模板参数推导时不允许隐式类型转换。也就是当推导T的过程中,如果发现类型不匹配,不允许在这个时候发生隐式类型转换(把参数换成其他类型)。原因之前提到过,也就是类型转换是重载决议负责的,而不是参数推导负责的。所以第一种不可以,因为推断的时候通过第一个参数推断出T是double,但是第二个参数推断出T是int,发生了冲突,而此时不可以把第二个参数类型隐式转为double。
为什么第二行可以呢?是因为我们指明了模板参数。这个时候相当于跳过了推导这一阶段,因为我们通过显式指定模板参数的方式隐式实例化了对应函数。然后进行重载决议的时候就可以进行类型转换了。所以:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
template<typename T>
struct typewrapper{
typewrapper(T args){
cout <<"const" << endl;
}
operator T(){
cout <<"converted" << endl;
return T();
}
};
class tmp{
public:
string _text;
tmp() = default;
tmp(string c): _text(c) {} //单参构造,可以看做转换构造
};
template<typename T>
void foo3(T A, T B){
std::puts(__PRETTY_FUNCTION__);
cout <<"called" << endl;
}
int main(){
foo3<typewrapper<tmp>>(typewrapper<tmp>{tmp{}}, tmp{}); //可以
foo3<tmp>(typewrapper<tmp>{tmp{}}, tmp{}); //可以
foo3(typewrapper<tmp>{tmp{}}, tmp{});//不行
}
所以我们如果没有指明模板参数,则根据推导规则,类型有冲突且不能通过隐式类型转换解决问题。但是前面两个我们指明了模板参数,跳过了推导这一过程,则直接进入重载决议这一阶段就可以进行类型转换。
第二章 类模板
- 类模板的声明:
1
2
3
4
5
6
7
类模板的声明:
template<typename T>
class Stack{
Stack(Stack<T> const &);
~Stack();
Stack<T> operator=(Stack<T> const &);
};
- 区分两种写法:类的类名
Stack、类的类型Stack<T>- 当在声明中需要使用类的类型时,你必须使用
Stack<T>(大部分情况) - 然而当使用类名而不是类的类型时,就应该只用
Stack(比如指定类的名称、构造和析构函数名)
- 当在声明中需要使用类的类型时,你必须使用
- 类模板可以偏特化也可以全特化。
- 注意,特化的部分我们塞进去的是实参argument。这部分非常关键
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
template<未被特化的部分>
class obj<特化的部分, 未被特化的部分>{
...
};
template<typename T1, typename T2>
class test{
T1 data1;
T2 data2;
};
//全特化
template<>
class test<int, float>{
int data1;
};
//偏特化
template<typename T2>
class test<int, T2>{
int data1;
};
- 注意,特化的类模板不能改变整体的模板形参数量。也就是在特化的时候,我们不可以改变特化的模板实参的数量
1
2
3
4
5
6
7
8
9
10
11
template<typename T1>
class test;
template<typename T1, typename T2> //这样做错误 ERROR。主模板只有一个形参。但是特化的时候我们塞进去了俩。不行。
class test<T1, T2>{//改变了特化的模板实参数量。错误
};
int main(){
test<int, double> obj
}
类模板调用顺序: 对主版本模板类、全特化类、偏特化类的调用优先级从高到低进行排序是:全特化类>偏特化类>主版本模板类。这样的优先级顺序对性能也是最好的。
- 只有那些被调用的成员函数,才会产生这些函数的实例化代码。对于类模板,成员函数只有在被使用的时候才会实例化。
- 因为在编译阶段,编译器无法确认模板的参数类型,所以无法创建模板类成员函数
- 显然,这样可以节省空间和时间;另一个好处是对于那些 未能提供所有 “ 成员函数中所有操作的类型“,你也可以使用该类型来实例化类模板,只要对那些 未能提供 “ 某些操作的” 成员函数,模板内部不使用就可以。而且现在的 C++标准要求编译器要尽可能的延迟实例化的时机。
静态成员的无条件实例化:如果类模板中含有静态成员,那么用来实例化的每种类型,都会实例化这些静态成员。
- 类模板不能被重载
2.6 多模板参数的偏特化
偏特化有多种形式。下面的几种都可以。但是注意约束:
- 类模板偏特化的形参参数个数是可以和主模板不一样的,它既可以多于主模板,也可以少于主模板。但是偏特化的实参必须与主模板对应的参数相匹配。——出自16.4章
- 非常重要!!在特化类模板的时候,可以改变特化版本的形参列表的参数数量。但是最终落实(传入/应用)到实参上面的时候,参数数量不可变。
- 此外,显式书写的模板实参数量与主模板的模板参数数量甚至也可能不同。尤其会在拥有默认模板实参或拥有可变模板时发生
- 偏特化的参数列表不能具有默认实参;作为替代,主类模板的默认实参会被使用。
- 偏特化的非类型实参要么是一个非依赖型值,要么是一个普通的非类型模板参数。它们不能是更加复杂的表达式,诸如
2*N(N是一个模板参数)。 - 偏特化的模板实参列表不应该与主模板的参数列表完全相同(忽略重命名)。
- 如果模板实参的某一个是包展开,那么它必须位于模板实参列表的最后。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
template<typename T1, typename T2>
class MyClass {
//主模板
};
template<typename T>
class MyClass<T,T> {
//两个参数同一个类型。
//注意这里不一定非得写T1 T1。类型具体叫什么没所谓
//特化模板的形参列表的参数数量可以变。但是实参列表的参数数量不可变。主模板是两个形参,我们就要传入两个实参。
};
template<typename T>
class MyClass<T,int> {
//第二个参数是int
};
template<typename T1, typename T2>
class MyClass<T1*,T2*> {
//两个参数为指针。
};
- 我们之前提到过特化的时候塞进去的是实参argument。塞进去的实参必须和主模板的形参数量匹配。为什么这么重要?我们理解一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
template<typename T1> //主模板只有一个形参
class test;
//----------VERSION 1---------------------
template<typename T1, typename... T2>
class test<T1, T2 ...>{ //实参数量不匹配
};
int main(){
test<int,float, double> obj;
}
//-----------VERSION 2----------------------
template<typename T1>
class test;
template<typename T1, typename... T2> //形参可以不同但是实参必须匹配
class test<T1(T2 ...)>{//实参匹配
};
int main(){
test<int(float, double)> obj; //实参和实参必须数量对应。
}
- 为啥version1不行,version2可以?
我们说了,特化的时候必须匹配主模板的模板形参数量。我们version 1塞进去了两个模板实参。这样发生了问题。
version2为啥可以?尽管我们特化的时候,针对这个特化的模板形参是两个。但是我们在实际传入实参的时候,T1 和 T2...被合成了一个函数类型T1(T2...)。这一整个打包起来会变成主模板眼中的T1。注意这是函数类型并非函数指针类型
- 所以说甚至可以对成员指针进行特化:
1
2
3
4
5
6
7
template<typename T>
class List {//主模板
};
template<typename T, typename C>
class Class<T* C::*> { //针对成员指针的特化。T* C::*在主模板眼里是它的整个T
};
- 为什么我们
main函数中的实例化也要写成int(float, double)的形式?因为实参和实参必须相匹配。举个最简单的例子:
1
2
3
4
5
6
7
8
template<typename T1, typename T2>
class MyClass {
//主模板
};
template<typename T>
class MyClass<T,T> {
};
这是我们提到的例子。我们实例化的时候应该怎么写?是不是应该写Myclass<int, int>这种形式的?不能写Myclass<int>对吧?
- 为啥我这么关心这个?因为这是
packaged_task和function的模板实现方式
1
2
3
4
5
6
7
8
9
template< class >
class packaged_task; //主模板
template< class R, class ...ArgTypes >
class packaged_task<R(ArgTypes...)>; //特化。
template< class >
class function; //主模板
template< class R, class... Args >
class function<R(Args...)>;//特化。
2.7 类模板默认参数
类模板自然可以有默认参数。比如很多STL的实现。下面是一个小例子
1
2
3
4
5
6
7
template<typename T1, typename T2 = int>
class obj{
public:
obj(T1 a, T2 b):val1(a), val2(b){};
T1 val1;
T2 val2;
};
2.8 类型别名 Aliases
一般来说,我们有两种方式可以给类型定义别名。using 和 typedef
typedef
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
template<typename T> class myobj{ public: myobj(T a):val(a){}; T val; }; typedef myobj<int> INTmyobj; typedef myobj<double> DOUBLEmyobj; int main(){ INTmyobj im(2); DOUBLEmyobj dm(2.345); cout << im.val << endl; cout << dm.val << endl; return 0; }
using
1
2
3
4
5
using usingINTmyobj = myobj<int>;
using usingDOUBLEmyobj = myobj<double>;
usingINTmyobj im(2);
usingDOUBLEmyobj dm(2.345);
2.8.1 别名模板 Alias Templates
注意。这里是typedef和using在别名方面唯一区别。这里只有using。typedef不可以。
比如我们不可以:
1
2
template<typename T>
typedef myobj<T> intobj;
但是可以:
1
2
3
4
template<typename T>
using intobj = myobj<T>;
intobj<int> myobj(2);
2.8.2 必须显式使用typename的情况
参看笔记STL2
2.9 类模板的类型推导
直到C++17,我们都必须显式指出所有类模板参数的类型。除非拥有默认值。
剩下的看书。
2.10 聚合类型的模板化
可以定义聚合类的类模板。关于聚合类,参考聚合初始化。
2.11 类模板成员函数或变量的类外实现[自己添加]
基本类代码
1
2
3
4
5
6
7
8
9
10
template<typename T>
class test{
public:
T val;
static T s_val;
void func(T val);
T func1();
void func2();
};
类静态成员变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<typename T>
T test<T>::s_val = 102;
int main(){
test<int> obj;
test<double> obj2;
cout << obj.s_val<< endl; //输出102
cout << obj2.s_val << endl; //输出102
obj2.s_val = 12345;
cout << obj.s_val<< endl; //输出102
cout << obj2.s_val << endl; //输出12345
return 0;
}
- 类静态成员变量在模板类中依旧遵循全类共享。但是注意这里是实例化后的全类共享。也就是
T为int的test和T为double的test是两种类类型。自然二者是独立开来的。因为会分别实例化代码。
类成员函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
template<typename T>
T test<T>::s_val = 102;
template<typename T>
void test<T>::func(T val){
cout <<"func" << endl;
}
template<typename T>
T test<T>::func1(){
cout <<"func1" << endl;
}
template<typename T>
void test<T>::func2(){
cout <<"func2" << endl;
}
- 可以看见,必须加模板头,且必须在指明类作用域的时候添加
T- 也就是不能
test::func必须是test<T>::func
- 也就是不能
第三章 非类型模板参数
杂记3有写。这里重新整理
3.1 类模板的非类型模板参数 - 3.2 函数模板的非类型模板参数
1
2
3
4
5
6
7
8
9
template<typename T>
void func(T obj){
//...
}
int main(){
func<int>(5);
return 0;
}
- 我们都知道模板参数一般都是类型。比如这里,
T就是int。是类型。当我们希望传入一个不是类型的参数的时候,比如如果我们有时候需要一些特殊情况, 例如想要传点奇怪东西的时候就可以使用非类型模板参数。
1
2
3
4
5
6
7
8
9
template<typename T, int MAXSIZE> //注意语法。这里非类型模板参数不再是typename了
void func1(T obj){
vector<T>a;
a.reserve(MAXSIZE);
cout << a.capacity() << endl;
a.push_back(obj);
cout << a[0] << endl; //干啥了不解释了 忽略即可
}
- 这里的
int MAXSIZE就是非类型模板参数。因为他不是类型,而是变量。
使用非类型模板参数是有限制的。通常它们只能是:
- 整型常量或字面值(包含枚举,或可隐式转换的比如
bool)(stringdouble都不可以。前者是类对象,后者是浮点数) - 指针类型
- 成员指针类型
- 对象/函数的左值引用
std::nullptr_t- 包含
auto或decltype(auto)的类型 [C++17后]- 这个比较常用在把无捕获的lambda当做非类型模板参数进行传入。[C++20后]
当传递对象的指针或者引用作为模板参数时,对象不能是字符串常量,临时变量或者数据成员以及其他子对象。由于C++17之前,C++每次版本更新都会放宽以上限制,因此还有一些针对不同版本的限制:
- C++11中,对象必须要有外部链接
- C++14中,对象必须是外部链接或者内部链接
所以:传入的s必须是常量。
1
2
3
const int s = 8; //必须是const
func1<int, s>(5);
func2<int, 4>(5); //或者直接传入字面值。
搭配类模板偏特化的小例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
template<typename T, bool option>
class myclass; //主模板不实现
template<typename T>
class myclass<T, true>{ //偏特化1,注意语法。T在这里依旧要写上。
public:
void func(){
cout <<"true one" << endl;
}
};
template<typename T>
class myclass<T, false>{ //偏特化2,注意语法。T在这里依旧要写上。
public:
void func(){
cout <<"false one" << endl;
}
};
int main(){
const bool myoption = true;
myclass<int, false> obj; //直接使用字面值
obj.func();
myclass<int, myoption> obj1; //或必须用const常量变量。
obj1.func();
return 0;
}
- 两者的非类型模板参数都可以指定默认值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template<typename T, int TS = 5> //注意语法。这里非类型模板参数不再是typename了
class myobj{
public:
myobj(T a):val(a){my_vec.reserve(TS);};
T val;
vector<T> my_vec;
};
template <typename T, int TS = 10> //注意语法。这里非类型模板参数不再是typename了
void func(T a){
vector<T> my_vec(TS);
cout <<"called" << endl;
cout << my_vec.capacity() << endl;
}
int main(){
myobj<int,8> instance(10);
cout << instance.my_vec.capacity() << endl;
//输出8
func<int, 9>(2);
//输出 called 9
return 0;
}
3.3 避免无效表达式
非类型模板参数可以是任何编译器表达式。比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
//函数模板
template <int size, bool judge> //注意表达式不写在这。
void func(){
cout << size << endl;
if(judge == true){
cout << "true" << endl;
}
else{
cout << "false" << endl;
}
}
//类模板
template <int size, bool judge>
class myobj{
public:
myobj(){
my_vec.reserve(size);
testfunc();
};
void testfunc(){
cout << my_vec.capacity() << endl;
if(judge == true){
cout << "true" << endl;
}
else{
cout << "false" << endl;
}
}
vector<int> my_vec;
};
int main(){
func<10, sizeof(int) == 4>(); //注意表达式写在这。写在实例化位置而非模板参数位置。
//输出true
func<10, (sizeof(int) > 4 )>(); //注意这里表达式要额外一组括号。
//输出false
myobj<10, sizeof(int) == 4> instance;
//输出10 true
myobj<10, (sizeof(int) > 4 )> instance1;
//输出10 false
return 0;
}
- 不过如果在表达式中使用了
operator >,就必须将相应表达式放在括号里面,否则>会被作为模板参数列表末尾的>,从而截断了参数列表
3.4 使用auto做为非模板类型参数 (C++17)
暂略。看书。
第四章 变参模板
编译期变参模板展开有四种方式:
- 函数的递归调用
std::initializer_listenable_if- 折叠表达式
4.1 函数的变参模板
- 基本定义
1
2
3
4
template <typename T, typename... Args> //注意这里的Args叫模板参数包
// 如果函数参数列表中一个参数的类型是一个模板参数包,
// 则此参数也是一个函数参数包
void func(const T& t, const Args&... rest); //这里的rest叫函数参数包
一定要注意区分开在模板头声明的模板参数包和函数头的函数参数包的区别。
注意,模板参数包只能接受同一个类型的参数。要么全是类型模板参数,要么全是非类型模板参数。要么全是模板类型模板参数。不能混用。这也是下面5.7匹配问题关于
array的问题 —– 12.3.4章节,12.2章节C++17之前的写法:因为没有折叠表达式。这种属于函数递归调用
- 当
...出现在变量名字左侧的时候,表示声明一个参数包。一个参数包可以绑定零个或多个参数。当...出现在变量名字右侧的时候,表明它会被展开(unpack)为独立的参数。出自这里- 包展开的场所查看这里
包展开的模式。
什么是模式?简要而言,模式就是看你省略号想要和什么东西组合在一起,也就是想要扩展什么。在包展开的场所中,以函数形参列表为例。我们可能看到两种样式的包展开:
1 2
do_something(func(args)...); //扩展为 do_something(func(var1), func(var2), func(var3));
1 2
do_something(func(args...)); //扩展为 do_something(func(var1, var2, var3));
格外注意第一种情况下,意味着
do_something函数有三个参数。然而这个括号里面的逗号并不是逗号运算符,所以三个func()函数的调用的求值顺序并不被保证。- 以上例子来自
我们看到了两种形式的包展开。所以所谓包展开的模式,也就是我们是想扩展的那个东西。一般来说,它会扩展它左侧的,和它贴在一起的那一个东西。例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
void func1(int a, int b, int c){ cout <<"func1" << endl; cout << a << b << c << endl; } int func2(int a){ cout <<"func2" << endl; cout << a << endl; return a; } template<typename... Args> void tfunc(Args... args){ func1(func2(args)...); //会被扩展为func1(func2(1), func2(3), func2(5)); cout <<"--------------" << endl; func1(args...); //会被扩展为func1(1,3,5); cout <<"--------------" << endl; (func2(args), ...); //这是折叠表达式, C++17 } int main(){ tfunc(1,3,5); return 0; } /* func2 5 func2 3 func2 1 func1 135 -------------- func1 135 -------------- func2 1 func2 3 func2 5 */
- 再次提示在这个
func1(func2(args)...);包展开中,函数调用的求职顺序不保证,这不是逗号运算符。所以GCC中的顺序是5 3 1,但是clang的顺序是1 3 5
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void print (){
//必须要有无参重载,否则会无限递归。也就是最后一次无参无法被调用。
//最后一次被解包后,参数包会为空。所以会调用无参函数。
}
template<typename T, typename... Args>
void print (T firstArg, Args... args)
{
cout << firstArg << endl; //print first argument
print(args...); // call print() for remaining arguments
}
int main()
{
print(1, 1000, "b23", 1.123, "HahaahaH", 42);
return 0;
}
- C++17之后的写法:有了折叠表达式
- 此处折叠表达式和逗号运算符语法会在下文补充。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template<typename T> //要有单参打印的重载。不然会无限调用。
void print(T t){
cout << t << endl;
}
template<typename... Args>
void print(Args... args){
(print(args), ...); //这里外部一定要加括号。注意语法。这里的,是逗号运算符。
}
int main()
{
print(1, 1000, "b23", 1.123, "HahaahaH", 42);
return 0;
}
- 多种变长参数模板可以同时存在 尽管直观看起来会有二义性
- 非变参模板比变参模板更特化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template<typename... Args>
void ttss(Args... args){
cout << "varidic" << endl;
}
template<typename T1, typename T2, typename T3, typename T4>
void ttss(T1 a, T2 b, T3 c, T4 d){
cout << "4 args" << endl;
}
int main()
{
ttss("a", "v", "f", 5);
return 0;
}
//输出4 args
搭配std::initializer_list
- 函数变长参数模板搭配搭配std::initializer_list。
- 这个函数会返回一个
T类型的vector,元素是args
- 这个函数会返回一个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
template<typename T, typename... Args>
vector<T> func(const Args&... args){
return {args...};
}
int main(){
auto vec = func<int>(1,2,3,4,5,6,7);
for(auto& i:vec){
cout << i << endl;
}
}
/*
输出:
1
2
3
4
5
6
7
*/
- 如果目的不是初始化一个容器而是打印列表,可以化简为:
1
2
3
4
5
6
template <typename... Args>
void FormatPrint(const Args&... args)
{
std::initializer_list<int>{ (std::cout << "[" << args << "]", 0)...};
std::cout << std::endl;
}
我们知道逗号表达式会计算每一个表达式然后只保留最后一个表达式的值。(a, b) 这个表达式的值就是 b,那么上述代码中(std::cout << "[" << args << "]", 0)这个表达式的值就是0,但是前面的每一个表达式都会被计算。逗号表达式保证其中的内容从左往右执行,args参数包会被逐步展开,表达式前的(void)是为了防止变量未使用的警告,运行过后我们就得到了一个N个元素为0的初始化列表,内容也被格式化输出了。
1
2
3
4
5
6
int main()
{
FormatPrint(1, 2, 3, 4);
FormatPrint("good", 2, "hello", 4, 110);
return 0;
}
- 当然了,把
initializer_list换成任何一个接受initializer_list的容器都可以。比如vector也可以
4.1.2 变参和非变参模板的重载
我们提到了多种变长参数模板可以同时存在 尽管直观看起来会有二义性。所以上面C++17前的写法可以写成这样子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
template<typename T>
void print (T arg){
cout << arg << endl;
}
template<typename T, typename... Args>
void print (T firstArg, Args... args)
{
print(firstArg); //注意这里。这里调用了无模板参数包的函数。单独打印这次解包出来的这一个变量。
print(args...); // call print() for remaining arguments
}
int main()
{
print(1, 1000, "b23", 1.123, "HahaahaH", 42);
return 0;
}
- 简单来说,当两个函数模板的区别只在于尾部的参数包的时候,会优先选择没有尾部参数包的那一个函数模板。
4.1.3 sizeof运算符在变长模板中的特殊应用。
沿用上面的例子,传递给 print() 的第一个参数之后,输出剩余两次参数的数量。对于模板参数包和函数参数包都可以使用 sizeof...。
1
2
3
4
5
6
7
8
template<typename T, typename... Args>
void print (T firstArg, Args... args)
{
print(firstArg);
cout << "remains"<<sizeof...(args) << endl; //函数参数包
cout << "remains"<<sizeof...(Args) << endl; //模板参数包
print(args...);
}
4.2 折叠表达式 (fold expression)
折叠表达式的展开过程并不是递归。更多的是类似于一种替换,一种编译时展开替换。个人理解。
折叠表达式分为四种:
左折:参数从左侧开始计算
- 一元左折叠
1 2 3
( ... 运算符 形参包 ) 会被拓展为 (((E1 运算符 E2) 运算符 ...) 运算符 EN)
- 二元左折叠
1 2 3
( 初值 运算符 ... 运算符 形参包 ) 会被拓展为 ((((初值 运算符 E1) 运算符 E2) 运算符 ...) 运算符 EN)
右折:参数从右侧开始计算
- 一元右折叠
1 2 3
( 形参包 运算符 ... ) 会被拓展为 (E1 运算符 (... 运算符 (EN-1 运算符 EN)))
- 二元右折叠
1 2 3
( 形参包 运算符 ... 运算符 初值 ) 会被拓展为 (E1 运算符 (... 运算符 (EN−1 运算符 (EN 运算符 初值))))
左折叠右折叠在有顺序要求的时候尤其重要。比如减法和除法。
注意左右不是指的是单个顺序颠倒。而是每一组顺序颠倒。
比如
((a+b)+c)变成右折并不是(a+(c+b))。而是(a+(b+c))
将一元折叠用于长度为零的包展开时,只能使用下列运算符:
逻辑与(&&)。空包的值是 true
逻辑或( )。空包的值是 false 逗号运算符(,)。空包的值是 void()
- 其他操作符为不合规。
在二元折叠中,两个运算符必须相同
- 不可以一加一减。
语法示范:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
//一元左折叠加法
template<typename... T>
auto foldSumLeft(T... s)
{
return (... + s); // ((s1+s2)+s3)...
}
//一元右折叠加法
template<typename... T>
auto foldSumRight(T... s)
{
return (s + ...); // (s1+...+(Sn-1 + sn)))...)
}
//一元左折叠减法
template<typename... T>
auto foldMinLeft(T... s)
{
return (... - s); // ((s1-s2)-s3)...
}
//一元右折叠减法
template<typename... T>
auto foldMinRight(T... s)
{
return (s - ...); // (s1-...-(Sn-1 - sn)))...)
}
int main(){
auto sumLeft = foldSumLeft(1,2,3,4,5,6,7); //((((((1+2)+3)+4)+5)+6)+7)
auto sumRight = foldSumRight(1,2,3,4,5,6,7);
cout << sumLeft << endl; //28
cout << sumRight << endl;//28
auto sumLeftmin = foldMinLeft(1,2,3); //((1-2)-3)
auto sumRightmin = foldMinRight(1,2,3);//(1-(2-3))
cout << sumLeft << endl; //-4
cout << sumRight << endl;//2
}
//二元左折
template <typename... T>
auto foldBinLeft(T... s)
{
//操作对象有两个,一个是888 初值,一个是ts形参包,
//初始值位于左边,所以为二元左折
return (888 + ... + s);
}
//二元右折
template <typename... T>
auto foldBinRight(T... s)
{
//操作对象有两个,一个是888 初值,一个是ts参包,
//初始值位于右边,所以为二元右折
return (s + ... + 888);
}
int main(){
auto binLeft = foldBinLeft(1,2,3); //894 (((888+1)+2)+3)
auto binRight = foldBinRight(1,2,3); //894 (1+(2+(3+888)))
cout << binLeft << endl;
cout << binRight << endl;
}
- 如果用作 初值 或 形参包的表达式在顶层具有优先级低于转型的运算符,那么它必须加括号:
- 此处仅用二元右折做个示范。注意此时两个操作符都是
+。所以合法。
1
2
3
4
5
6
template <typename... T>
auto foldBinRight(T... s)
{
return (s + ... + (888*2)); //可以
return (s + ... + 888*2); //不可以
}
序列点和逗号运算符在折叠表达式中的特殊性质
序列点的定义可以查一下文档。简单来说就是我们需要约束一个表达式的计算顺序。
我们上面提到了这个代码:
1
2
3
4
5
6
template<typename... Args>
void print(Args... args){
(print(args), ...); //这里外部一定要加括号。注意语法
(..., print(args));//??
}
我们发现第一行是右折叠。按理来说应该是逆序输出。但是为什么这里左折和右折效果一样?
这就是序列点和逗号运算符的特殊性。
- C++有强制规定:内建逗号运算符 , 的第一个(左)参数的每个值计算和副作用都按顺序早于第二个(右)参数的每个值计算和副作用。
- 也就是说,这里的左折叠和右折叠的优先级是低于逗号运算符的。所以说逗号运算符强制从左到右的运算顺序使得这里的左折和右折失效。产生了同等效果 。
- 所以,这里在展开后,依旧会从左至右进行运算。
- 再次重申:折叠表达式的展开过程并不是递归。
- 所以它展开后可以被化简看作:
1
print(1), print(1000), print("b23"),.....;
此部分参考:
https://stackoverflow.com/questions/46056268/order-of-evaluation-for-fold-expressions
https://stackoverflow.com/questions/59590426/variadic-template-argument-forwarding-uses-comma-operator
https://stackoverflow.com/questions/53330713/fold-expression-with-comma-operator-and-variadic-template-parameter-pack
https://stackoverflow.com/questions/45603533/how-does-folding-over-comma-work
4.3 变参模板的使用
之前关于常规模板参数的规则同样适用于变参模板参数。
- 比如,如果参数是按值传递的,那么其参数会按照正常理解被拷贝,类型也会退化(decay)。
- 如果是按引用传递的,那么参数会是实参的引用,并且类型不会退化
4.4 变参类模板和变参表达式
4.4.1 在变参中使用表达式
此处是针对4.2的一些扩展。也就是折叠表达式的一种应用。
我们可以将函数参数包参与到一些运算当中:
- 这里,我们把传入的每一个参数的数值都增加一倍
- 注意字面值是
const char*类型。
- 注意字面值是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template<typename T> //要有单参打印的重载。不然会无限调用。
void print(T t){
cout << t << endl;
}
template<typename... Args>
void print(Args... args){
(print(args), ...); //这里外部一定要加括号。注意语法。这里的,是逗号运算符。
}
template<typename... T>
void printDoubled (T const&... args)
{
print (args + args...);
}
int main(){
printDoubled(1, 2.3, string("abcde")); //输出 2 4.6 abcdeabcde。注意字面值是`const char*`类型。
//等于调用 print(1+1), print(2.3 + 2.3), print(string("abcde") + string("abcde"))
return 0;
}
- 如果只是想每一个都加1,那么后面的参数包位置则必须字面值和数字分开。
1
2
3
4
5
6
7
template<typename... T>
void printDoubled (T const&... args)
{
print(1 + args...); //要么这么写
print(args + 1 ...); //要么这么写。但是1和...必须分开。
print((args + 1)...); //要么这么写。多加个括号。
}
- 编译阶段的表达式同样可以像上面那样包含模板参数包。比如下面这个例子可以用来判断所有参数包中参数的类型是否相同
- 注意这里是函数模板的例子。函数模板可以自动推导类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<typename T1, typename... TN>
constexpr bool isSameType (T1, TN...)
{
return (std::is_same<T1,TN>::value && ...); // since C++17
}
int main(){
cout << isSameType(1,2,3,4) << endl; //输出1 true
//这一行会被扩展为 std::is_same<int,int>::value && std::is_same<int,int>::value && std::is_same<int,int>::value
cout << isSameType(1,2,"123",4) << endl; //输出0 false
//这一行会被扩展为 std::is_same<int,int>::value && std::is_same<int,const char*>::value && std::is_same<const char*,int>::value
cout << isSameType("abc", "abcde") << endl; //输出1 true 特别注意这里
return 0;
}
- 注意最后一个调用。这里因为是按值传递,所以发生了类型退化,统一被推导为
const char*。 - 否则类型将依次被推断为:
const char [3]和const char[5];- 所以如果
isSameType写成这个样子就不会退化,导致输出false constexpr bool isSameType (T1&, TN&...)- 这里参见函数模板参数推导规则。这里我们看到传入的是数组,然后模板函数的入参部分(不是模板参数部分)是引用了,所以这时候传入的参数不会退化。也就是里面的
T1和TN维持住了非退化类型。
- 这里参见函数模板参数推导规则。这里我们看到传入的是数组,然后模板函数的入参部分(不是模板参数部分)是引用了,所以这时候传入的参数不会退化。也就是里面的
- 所以如果
4.4.2 在变参中使用下标 (variadic indices)
这里看起来可能比较晦涩,但是是一个比较实用的功能。
- 假设我们有两个参数。第一个参数是一个容器,第二个参数是一个下标。我们想访问这个容器的这个下标的元素应该怎么做?
1
2
3
4
5
6
7
8
9
10
11
template<typename Container, typename Index>
void getItem(Container& container, Index idx){
cout << container[idx] << endl;
}
int main(){
//printDoubled(1, 2.3); //输出 2 4.6
vector<string> my_vec{"abc", "def", "ghi", "123", "456"};
getItem(my_vec, 3); //输出 123
return 0;
}
- 好的。那么我们如果想要把这个功能融入到变参里面呢?比如我想要拿出多个元素,怎么做呢?
- 注意这里我们参数包为下标,而不是容器。
- 非常方便。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
template<typename T> //要有单参打印的重载。不然会无限调用。
void print(T t){
cout << t << endl;
}
template<typename... Args>
void print(Args... args){
(print(args), ...); //这里外部一定要加括号。注意语法。这里的,是逗号运算符。
}
//--------------------------上面是之前我们一直在用的print模板,这里也放一个方便查看---------------------
template<typename Container, typename... Index> //模板参数包
void getMultipleItem(Container& container, Index... idx){//函数参数包
print(container[idx]...); //参数包
}
int main(){
vector<string> my_vec{"abc", "def", "ghi", "123", "456"};
getMultipleItem(my_vec, 1,2,3,4);
//输出def ghi 123 456
return 0;
}
getMultipleItem(my_vec, 1,2,3,4);相当于调用了:print(my_vec[1], my_vec[2], my_vec[3], my_vec[4]);
同时我们也可以将非类型模板参数声明成参数包:
1
2
3
4
5
6
7
8
9
10
template<int... Idx, typename Container> //细节1
void getMultipleItem(Container& container){ //细节2
print(container[Idx]...);
}
int main(){
vector<string> my_vec{"abc", "def", "ghi", "123", "456"};
getMultipleItem<1,2,3,4>(my_vec); //细节3
//输出def ghi 123 456
return 0;
}
- 首先,非类型模板参数不是类型,是变量。所以无需传入函数参数。只需在模板参数中传入(细节1,2)
- 细节3,这里既然是模板参数而非函数参数,所以这里要用
<>传入模板参数
4.4.3 在类模板中使用可变参数(变参类模板)
等25和26章
4.4.4 变参推断指引
看书
4.4.5 变参基类
等26章
第五章 基础技巧
5.1 typename关键字
看STL2
5.2 零初始化
此处同时参考笔记 聚合初始化
- 模板中依旧遵循和非模板相同的初始化规则,比如:
1
2
3
4
template <typename T>
void func(){
T x; //如果T是内置类型,则模板实例化后,x为脏数据,也就是未确定值。
}
- 如果想要强制其初始化为0,则应该使用值初始化。关于值初始化依旧参考聚合初始化笔记。
1
2
3
4
template <typename T>
void func(){
T x{}; //如果T是内置类型,则模板实例化后,x为0值。
}
一些之前的知识回顾
- 在 C++11 之前,确保一个对象得到显示初始化的方式是
1
T x = T();
- [这一条可以参考杂记的拷贝初始化和杂记2的explicit] 由于这是一种拷贝初始化,所以在 C++17 之前,只有在与拷贝初始化对应的构造函数没有被声明为 explicit 的时候,这一方式才有效(目前也依然被支持)
- [强制拷贝省略技术可以参考杂记3的复制省略技术] 从 C++17 开始,由于强制拷贝省略(mandatory copy elision)的使用,这一限制被解除,因此在 C++17 之后以上两种方式都有效。不过对于用花括号初始化的情况,如果没有可用的默认构造函数,它还可以使用列表初始化构造函数(initializer-listconstructor)
继续话题
为确保类模板中类型被参数化了的成员得到适当的初始化,可以定义一个默认的构造函数并在其中对相应成员做初始化:
1
2
3
4
5
6
7
template<typename T>
class MyClass {
private:
T x;
public:
MyClass() : x{} {} //确保当T为内置类型时,x值为0。注意第一个花括号为值初始化。第二个花括号是构造函数的函数体。
};
- c++11之前的语法:
1
MyClass() : x() {}
- 从C++11开始,针对非静态成员和非默认参数部分,则也可以用这种方法。
1
2
3
4
5
template<typename T>
class MyClass {
private:
T x {}; // 使用值初始化,确保当T为内置类型时,x值为0。
};
- 如果针对默认参数这样使用,则会报错。
1
2
3
4
template<typename T>
void foo(T p{}){
//错误
}
- 这样可以:
1
2
3
4
template<typename T>
void foo(T p = T{}){
//正确。但如果C++11之前的话必须把T{}换成T()
}
5.3 使用this
- 这里应参考 深度探索c++对象模型笔记中的7.1
- 简而言之,当在模板类中使用定义于基类中的、依赖于模板参数的成员时,应当用
this->或者如Base<T>::这样显式指定作用域来使用它
5.4 正确处理传入模板的裸数组或字符串常量
当向模板传递裸数组或者字符串常量时,需要格外注意以下内容:
如果参数是按引用传递的,那么参数类型不会退化(decay)。
- 也就是说当传递
hello作为参数时,模板类型会被推断为const char[6]。这样当向模板传递长度不同的裸数组或者字符串常量时就可能遇到问题,因为它们对应的模板类型不一样。
- 也就是说当传递
只有当按值传递参数时,模板类型才会退化(decay)
- 这样字符串常量会被推断为
const char*。
- 这样字符串常量会被推断为
关于具体选用按照值传递还是引用传递,可以看第七章。
不过我们可以单独处理一下裸数组或者是字符串常量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
template<typename T, int N, int M>
bool func (T(&a)[N], T(&b)[M]){
cout << N << endl; //输出3
cout << M << endl; //输出7
for (int i = 0; i<N && i<M; ++i){
if (a[i]<b[i]){
return true;
}
if (b[i]<a[i]){
return false;
}
}
return N < M;
}
int main(){
int x[] = {1,2,3};
int y[] = {1,2,3,4,5,6,7};
func(x,y);
return 0;
}
在上面的代码中,func中的T会被实例化为int,N会被实例化为3,M会被实例化为7。
同样适用于字符串常量。如果我们调用
1
func("abc", "abcde");
则func中的T会被实例化为const char,N会被实例化为4,M会被实例化为6。这里多了1是因为有字符串结束符。
5.5 成员模板
我们知道,写在尖括号<>内部的是模板参数,也就是类型信息。所以stack<int> 和 stack<float>理论上不可以相互赋值。因为没有合适的转换方式。但是我们可以重载 类内的operator=来实现这个不同类型间的相互赋值。比如stack<float>赋值给stack<int>。
具体实现还是看书比较好。
5.5.1 成员模板的特化
我们也可以给成员函数添加模板。同时成员函数模板也可以被全特化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
class getInt{
public:
float val;
getInt(float a): val(a){};
template<typename T = int> //成员函数模板。此处模拟一个返回int
T get() const{
return val;
}
};
template<> //全特化,此处模拟返回string。这里有细节
inline string getInt::get<string>() const{ //注意这里的inline
return to_string(val);
}
int main(){
getInt myobj(12.345);
auto t = myobj.get();
cout << t << endl; //12
auto t1 = myobj.get<string>(); //12.345000
cout << t1 << endl;
return 0;
}
- 第一个细节:c++不允许成员函数模板在类内全特化(显式特化)。必须写在类外。
- 第二个细节:如果分离编译,则此处全特化版本函数必须inline,否则会重定义。
5.5.2 特殊成员函数的模板 和 泛型lambda
如果能够通过特殊成员函数 拷贝或者 移动对象,那么相应的特殊成员函数(拷贝构造函数以及 移动 构造函数)也将可以被模板化。
和前面定义的赋值运算符类似,构造函数也可以是模板。但是需要注意的是,构造函数模板或者赋值运算符模板不会取代预定义的构造函数(此处尤指拷贝构造和移动构造)和赋值运算符(此处尤指拷贝赋值和移动赋值)。成员函数模板不会被算作用来 拷贝或移动 对象的特殊成员函数。在上面的例子中,如果在相同类型的 stack 之间相互赋值,调用的依然是默认赋值运算符。
- 这句话有毛病,省略了几个词。经过我的多方咨询,这句话的意思是:构造函数模板就算发现参数推导匹配,也不会为我们生成拷贝构造/拷贝赋值/移动构造和移动赋值。这几个函数必须是预定义的而不能是从模板实例化的。也就是说,就算模板实例化的函数长得表面和那四个函数一样,实例化出的函数也不会被认为是特殊成员函数。—-同时参考effective modern C++ 条款26
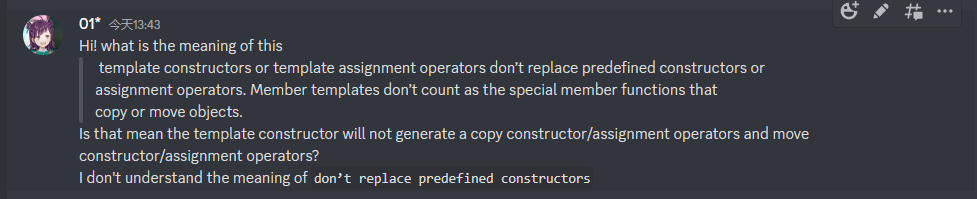

- 这种行为既有好处也有坏处:
- 某些情况下,对于某些调用,构造函数模板或者赋值运算符模板可能比预定义的拷贝或移动 构造函数或者赋值运算符更匹配,虽然这些特殊成员函数模板可能原本只打算用于在不同类型的某一个类之间做初始化。详情请参见 6.2 节。
- 想要对拷贝或移动构造函数进行模板化并不是一件容易的事情,比如该如何限制其存在的场景。详情请参见 6.4 节。
泛型lambda [c++14]:
1
2
3
auto lambda = [](auto x, auto y){
return x+y;
}
在这里,我们创建了一个泛型lambda。这个lambda可以接受任意的x和y,只要x和y可以相加,这段代码就没问题。
它的匿名类可能会像这样:
1
2
3
4
5
6
7
8
9
class SomeCompilerSpecificName {
public:
SomeCompilerSpecificName(); // constructor only callable bycompiler
template<typename T1, typename T2> //函数模板
auto operator() (T1 x, T2 y) const {
return x + y;
}
};
这个部分在std::visit中有用到。节选自这里
int main()
{
std::vector<var_t> vec = {10, 15l, 1.5, "hello"};
for (auto&& v: vec)
{
// 1. void 探访器,仅为它的副作用而调用
std::visit([](auto&& arg){ std::cout << arg; }, v);
// 2. 返回值的探访器,演示返回另一变体的常见惯用法
var_t w = std::visit([](auto&& arg) -> var_t { return arg + arg; }, v);
// 3. 类型匹配探访器:以不同方式处理每个类型的 lambda
std::cout << "。翻倍后,变体持有";
// 这一部分就是泛型lambda。
std::visit([](auto&& arg)
{
using T = std::decay_t<decltype(arg)>;
if constexpr (std::is_same_v<T, int>)
std::cout << "值为 " << arg << " 的 int\n";
else if constexpr (std::is_same_v<T, long>)
std::cout << "值为 " << arg << " 的 long\n";
else if constexpr (std::is_same_v<T, double>)
std::cout << "值为 " << arg << " 的 double\n";
else if constexpr (std::is_same_v<T, std::string>)
std::cout << "值为 " << std::quoted(arg) << " 的 std::string\n";
else
static_assert(false, "探访器无法穷尽类型!");
}, w);
}
for (auto&& v: vec)
{
// 4. 另一种类型匹配探访器:有三个重载的 operator() 的类
// 注:此情况下 '(auto arg)' 模板 operator() 将绑定到 'int' 与 'long',
// 但它不存在时 '(double arg)' operator() *也会* 绑定到 'int' 与 'long',
// 因为两者均可隐式转换到 double。使用此形式时应留心以正确处理隐式转换。
// 这一部分可以查看 笔记尾的《继承自可变参数包》一节
std::visit(overloaded{
[](auto arg) { std::cout << arg << ' '; },
[](double arg) { std::cout << std::fixed << arg << ' '; },
[](const std::string& arg) { std::cout << std::quoted(arg) << ' '; },
}, v);
}
}
5.5.3 template 关键字 (如 .template , ::template, ->template)
template关键字是用来消除待决名的歧义的. 观察下面的代码:
1
2
3
4
template<class T>
int f(T& x) {
return x.template convert<3>(pi);
}
如果没有template, 则
1
return x.convert<3>(pi);
可能被理解为
1
return ((x.convert) < 3) > (pi);
- 所以使用template来显式说明convert不是一个数据成员, 而是一个模板函数. 下面把标准照抄一遍.
使用 template 的规则
当成员模板特化的名字出现在一个后缀表达式中的.或->之后, 或者出现一个限定标识中的嵌套的名字修饰符之后(就是::), 并且后缀表达式或限定标识显示依赖于一个模板参数时, 成员模板名字必须加template关键字作为前缀, 否则该名字就被假定为一个非模板的名字.
如果后缀表达式或者限定标识不是出现在一个模板的作用域时, 成员模板的名字就不应该加上template关键字作为前缀.
必须使用template的场合
在通过“.”,“->”,“::”限定的依赖名访问成员模板之前, template关键字必不可少.
1
2
3
4
5
6
7
8
9
template<class T>
void f(T& x, T& y) {
int n = x.template convert<int>();
int m = y->template convert<int>();
}
template<class T> struct other;
template<class T>
struct dirived : other <T>::template base<int> {};
禁止使用template的场合
禁止用在模板之外的任何地方, 包括显式(完全)模板特化. 禁止用在using声明中.
5.6 变量模板
5.6.1 普通变量模板
在C++14之后,我们可以对变量使用模板。
1
2
3
4
5
6
template<typename T>
T my_val = 20.1234;
int main(){
cout << my_val<int> << endl; //20
cout << my_val<double> << endl; //20.1234
}
- 注意,和其它几种模板类似,这个定义最好不要出现在函数内部或者块作用域内部。不可在
main函数内。 - 变量模板可以有默认参数。
1
2
3
4
5
6
template<typename T = double> //默认参数
T my_val = 20.1234;
int main(){
cout << my_val<int> << endl; //20
cout << my_val<> << endl; //20.1234
}
- 在使用变量模板的时候,必须显式指明它的类型。如果直接使用变量会报错。
1
cout << my_val << endl; //错误
- 同样可以用非类型参数对变量模板进行参数化,也可以将非类型参数用于参数器的初始化。
5.6.2 成员变量模板
虽然不知道有啥用,但是还是整理一下。
假如我们有如下类模板:
1
2
3
4
5
6
template<typename T>
class myobj{
public:
static const int val = 1000; //static 和 const一起修饰变量可以在类内赋初值
};
如果我们不用成员变量模板,类外想访问的话比较麻烦:
1
2
3
4
5
int out_val = myobj<int>::val;
int main(){
cout << out_val << endl;
return 0;
}
如果我们采用成员变量模板,则可以这样使用:
1
2
3
4
5
6
7
8
9
template <typename T>
int out_val_T = myobj<T>::val; //成员变量模板
int out_val1 = out_val_T<int>; //直接使用
int main(){
cout << out_val1 << endl;
return 0;
}
5.7 模板模板参数
我们有过非类型模板参数,意思就是模板参数并不指定类型。
所以这里的模板模板参数的意思就是让模板的参数也是模板。
模板的模板参数的经典应用是在某些自定义指定储存容器类型的时候不指定元素类型。
比如,在我们不用模板模板参数的时候,指定stack可能需要这么写
1
Stack<int, std::vector<int>> vStack; //integer Stack that uses a vector
如果使用模板模板参数,我们就可以这么写:
1
Stack<int, std::vector> vStack; //intege stack that uses a vector
函数模板和变量模板没有模板模板参数、
最基本的举例
1
2
3
4
5
template<template<typename T> class container, typename T1, typename T2> // 最基本的举例
class test{
container<T1> a1;
container<T2> a2;
};
- 茴字的三种写法, 都可以
1
2
3
template <typename T, template <typename> class Container>
template <typename T, template <class> class Container>
template <typename T, template <typename> typename Container>
- 更好的理解的写法:
1
template <typename T, template <typename T1> typename Container>
- 在上面的例子里面,我们用不到模板模板参数里面的占位符,所以也可以忽略不写。
模板模板参数期待的是模板名,而不是具体类型
一定要注意模板模板参数到底期待的是什么。
1
2
3
4
5
6
7
8
9
10
11
12
13
template <typename T1, typename T2>
struct S{
};
template <template <typename, typename> typename T1>
struct A{
T1<int, double> obj; //可以在类内通过模板名T1这样实例化。
};
int main(){
A<S> obj1; //模板模板参数期待的是一个模板名。
A<S<int, double> obj2; //错误,不能这样指定,这是具体类型了。
}
在模板声明体内,此形参(我们的例子是T1)的名字是一个模板名(且需要实参以实例化)。
模板模板参数的语义
我们反复强调,模板模板参数的意义是让模板参数本身也成为模板,同时模板模板参数期待的是模板名而不是类型名。
所以:
1
2
3
4
5
6
7
8
9
10
11
12
13
template <typename T1, typename T2>
struct S{
};
template <typename T, template <typename, typename> typename T1 = S>
struct A{ //这里模板模板参数的默认值必须是一个模板名,不可以是S<T,int>这样的具体类型名
T1<T, double> obj; //可以在类内通过模板名T1这样实例化。
};
int main(){
A<int, S> obj1; //模板模板参数期待的是一个模板名。
}
如果换成非模板模板参数的写法,则应该是这个样子:
1
2
3
4
5
6
7
8
9
10
11
12
template <typename T1, typename T2>
struct S{
};
template <typename T, typename T1 = S<T, double>>
struct A{ //非模板模板参数的写法
T1 obj;
};
int main(){
A<int> obj1;
}
模板模板参数的匹配问题
- 我们的第一个例子使用模板模板参数 [C++14]:
1
2
3
4
5
6
7
8
9
10
11
template <typename T, template <typename Elem, typename = std::allocator<Elem>> typename Container = std::vector>
class Stack {
public:
Container<T> elems; // container<T>会默认调用对应的容器的默认分配器
};
int main(){
Stack<int, deque> sss; //一个stack,实现基于deque类,储存int类型数据
Stack<int> ssss; //一个stack,使用默认值实现基于vector类,储存int类型数据
}
- 上面的这段代码,是基于C++14的。我们有一个默认值。但是为什么我们显式指明了分配器?因为在C++17之前,模板模板参数必须和实际参数的模板参数匹配。因为
vector和deque有两个模板参数,第一个是元素类型,第二个是分配器。虽然分配器有默认参数,但是默认参数也要被匹配。所以如果不写分配器就会出现缺少参数的情况
所以如果到了C++17,我们就可以这么写。去掉分配器:
1
template <typename T, template <typename> typename Container = std::vector>
但是这个时候会有个问题,也就是此时这样做会让stack模板强制要求容器模板支持第二个参数。但是比如std::Array就不支持第二个参数。因为它的第二个参数是非类型模板参数。所以这样写就不行。
1
Stack<int, array> sss;
- 所以如果在C++17前,我们不想指定分配器怎么办?方法一,使用别名模板。这时候别名模板的分配器会支持默认值。
- 如果我们想使用array,只需要别名模板就可以。注意array的第二个参数必须给。因为没有默认值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template <typename T>
using deq = deque<T>; //要不然用别名模板也算是显式指定容器元素类型和分配器。
template <typename T>
using arr = array<T, 10>; //注意array的第二个参数必须给。因为没有默认值。
template <typename T, template <typename> typename Container>
class Stack {
public:
Container<T> elems; // container<T>会默认调用对应的容器的默认分配器
};
int main(){
Stack<int, deq> sss; //一个stack,实现基于deque类,储存int类型数据
Stack<int, arr> ssss; //一个stack,实现基于array类,储存int类型数据
}
- 方法二,使用可变参数模板在一定程度上简化写法。但是这里array依旧不可以。因为模板参数包只能匹配相同种类的模板参数。但是array的第一个是类型模板参数,而第二个是非类型模板参数。所以想要用array依旧需要用别名模板。 —12.3.4章节
1
2
3
4
5
6
7
8
9
10
template <typename T, template <typename ...> class Container> //使用可变参数模板简化后的方式 注意array不可以 array的第二个参数是非类型模板参数
class Stack {
public:
Container<T> elems; // container<T>会默认调用对应的容器的默认分配器
};
int main(){
Stack<int,deque> ss; //一个stack,实现基于deque类,储存int类型数据
}
最后,我们梳理一下那一大堆模板头的含义:
1
2
3
4
5
6
↓container类的默认参数的类型。因为没用到可以忽略 ↓ container类的默认参数。可以不写
template <typename T, template <typename U, typename Alloc = allocator<U>> class Container = deque>
↑这个T意思是储存T类型数据 ↑这个Alloc是contain类的默认方法的U类型的分配器。因为没用到可以忽略
//上面这样做会让stack模板强制要求容器模板支持第二个参数
template <typename T, template <typename ...> class Container> //使用可变参数模板简化后的方式
template <typename T, template <typename, typename> class Container> //不能这么写,下面container<T>会少一个参数,但是你上面必须写俩必须写分配.
模板模板参数还可以做什么?—继承自类模板
当我们需要继承自一个类模板的时候,可以使用模板模板参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template <typename T1, typename T2>
struct S{
void func(){
std::puts(__PRETTY_FUNCTION__);
cout <<"called" << endl;
}
};
template <typename T, typename T1, template<typename, typename > typename T2> //T2是模板模板参数,接受一个模板名
struct A: T2<T, T1>{//继承自T2类,T和T1是实例化T2所必需的模板参数
};
int main(){
A<int, double, S> obj;
obj.func();
}
第六章 enable_if
目前,类模板无法应用这个东西。针对于类模板,enable_if只能起到一种static_assert的作用。由于类和类模板不能重载,所以自然不存在候选集这个东西。也不存在SFINAE。enable_if在应用中的感觉是一种调整候选集的作用。
在函数模板中,enable_if起到的作用是活用了SFINAE的特性。
https://stackoverflow.com/questions/48045559/how-do-i-declare-sfinae-class
https://stackoverflow.com/questions/16972684/how-to-use-enable-if-for-restricting-a-whole-class
6.2 特殊成员函数模板 (笔记这里尤其指构造函数模板)
特殊成员函数也可以是模板,比如构造函数,但是有时候这可能会带来令人意外的结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class Person
{
private:
string name;
public:
// constructor for passed initial name:
explicit Person(const string& n) : name(n) { //构造函数。注意这里不是拷贝构造。参数不是person
cout << "此处是拷贝字符串进来 " << name << endl;
}
explicit Person(string&& n) : name(move(n)) { //构造函数。注意这里不是移动构造。参数不是person
//里面的move是为了给字符串自己转为右值。触发string的移动
cout << "此处是移动字符串进来 " << name << endl;
}
// copy and move constructor:
Person (const Person& p) : name(p.name) { //拷贝构造
cout << "此处是拷贝person对象进来 " << name << endl;
}
Person (Person&& p) : name(move(p.name)) { //移动构造
cout << "此处是移动person对象进来 " << name << endl;
//里面的move是为了给传入对象自己的string转为右值。然后触发string的移动
}
};
int main(){
string names = "miku";
Person p1(names); //拷贝字符串
Person p2("miku");//"miku"是字面值,虽然字符串字面值是左值,但是现在它是个临时对象。所以会触发移动。这里是移动字符串。
Person p3(p1); //拷贝对象
Person p4(move(p1));//移动对象。这个move是转换p1为右值调用person的移动。
}
一切都看起来不错。我们注意到针对使用string来构造person对象的时候,我们写了两个函数。一个针对左值string,一个针对右值string。下面我们尝试使用一下万能引用+完美转发来把两个函数合到一起。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class Person
{
private:
string name;
public:
template <typename T>
explicit Person(T&& n) : name(forward<T>(n)) {
cout << "万能引用+forward兼顾左值和右值。" << name << endl;
}
// copy and move constructor:
Person (Person const& p) : name(p.name) { //没有变化
cout << "此处是拷贝person对象进来 " << name << endl;
}
Person (Person&& p) : name(move(p.name)) { //没有变化
cout << "此处是移动person对象进来 " << name << endl;
}
};
好的,让我们测试一下
1
2
3
4
5
int main(){
string names = "miku";
Person p1(names); //万能引用+forward兼顾左值和右值。
Person p2("miku");//万能引用+forward兼顾左值和右值。
}
真不错,一切都看起来如我们所愿。针对左值和右值的string类,成功匹配到了万能引用的构造函数。
注意这里在构建 p2 的时候并不会创建一个临时的 string 对象:T的类型不会退化,因为万能引用也是引用。所以T会被推断为const char[4]。但是将 forward<T>用于指针参数没有太大意义。成员 name 将会被一个以null 结尾的字符串构造。
但是,当试图调用拷贝构造的时候,会遇到错误:
1
Person p3(p1); //拷贝对象
但是调用移动构造却没有问题:
1
Person p4(move(p1));//移动对象。输出此处是移动person对象进来
而且使用一个const Person对象来(触发拷贝构造来)初始化也没问题
1
2
3
const Person cp1("miku");
Person cp2(cp1); //注意是使用const对象初始化,而不是自己是const对象
//输出:此处是拷贝person对象进来
那么原因是什么呢?问题出现在重载决议。
- 首先我们知道两点:
- 如果函数模板可以实例化出一个比普通函数更完美的函数,那么会优先使用模板。只有所有情况都相同的时候,才会优先使用普通函数(1.5)
- 在重载决议的图当中,我们看到了
qualification conversion是第三档。
所以在这个时候,编译器发现通过构造函数模板实例化的函数会比拷贝构造更匹配:
1
2
template<typename T>
Person(T&& n)
在这里,T会被替换成Person&
去杂记看函数模板推导。这里传入的参数是
Person,函数形参是T&&, 则模板参数T会被推导为T&。随后引用折叠会变成函数形参为Person&
这明显比 const Person&更好,因为使用这个的话还需要进行qualification conversion
但是问题在这里,我们的构造函数里面怎么写的?
1
name(forward<T>(n));
我们是尝试用n去初始化name。但是name是string,n是Person。你能用一个Person对象初始化string对象吗?肯定不行,这啥玩意呀。
- 所以这时候,如果我们额外提供一个非
const的拷贝构造,那么没有问题
1
2
3
4
5
6
Person (Person& p) : name(p.name) { //非const的拷贝构造
cout << "此处是拷贝person对象进来, 非const的拷贝构造" << name << endl;
}
string names = "miku";
Person p1(names); //拷贝字符串
Person p3(p1); //输出:此处是拷贝person对象进来, 非const的拷贝构造
但是这样做不够优雅,我们6.3会讲一些关于enable_if的知识。然后我们在6.4会介绍如何搭配enable_if来禁用一些模板
- 无法为构造函数显式指定模板参数类型。
1
Person<int> f = Person<int>();
如上是不可以的。因为int被视为是Person的模板参数类型而不是其构造函数的模板参数类型。构造函数的模板参数类型只能通过型别推导。这也是为什么模板构造函数非常适合搭配完美转发进行使用。
6.3 使用enable_if
enable_if可以让我们在某些编译期条件下忽略掉函数模板。
比如,如果函数模板func的定义如下:
1
2
3
4
template<typename T>
typename std::enable_if<(sizeof(T) > 4)>::type func() {
//一些内容
}
这一模板定义会在 sizeof(T) > 4 不成立的时候被忽略掉。如果 sizeof(T) > 4 成立,函数模板会展开成:
1
2
3
4
template<typename T>
void func() {
//一些内容
}
在enable_if拥有第二个模板参数的时候,如果满足第一个参数的表达式,就会扩展成第二个模板参数。
1
2
3
4
template<typename T>
typename std::enable_if<(sizeof(T) > 4, MyType)>::type func() {
//一些内容
}
那么在 sizeof(T) > 4时,enable_if 会被扩展成其第二个模板参数。因此如果与 T 对应的模板参数被推断为 MyType,而且其 size 大于 4,那么其等效于:MyType func();
也就是说 std::enable_if<>是一种类型萃取(type trait),它会根据一个作为其(第一个)模板参数的编译期表达式决定其行为:
- 如果这个表达式结果为 true,它的 type 成员会返回一个类型:
- 如果没有第二个模板参数,返回类型是
void。 - 否则,返回类型是其第二个参数的类型。
- 如果没有第二个模板参数,返回类型是
如果表达式结果 false,则其成员类型是未定义的。根据模板的一个叫做 SFINAE(substitute failure is not an error,替换失败不是错误的规则,这会导致包含
std::enable_if<>表达式的函数模板被忽略掉。- 简而言之,意思就是,前面的表达式为真,后面的类型定义才有意义。
简单看一下原型
1
2
3
4
5
6
7
template <bool, typename T=void>
struct enable_if {
};
template <typename T>
struct enable_if<true, T> { ///< 第一个模板参数为 true
using type = T; ///< type 才有定义
};
一般三种用法:
- 控制函数返回类型
- 校验函数模板参数类型
- 类型偏特化
这里就随便写个控制函数返回类型的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template<int stat> //这里是非模板类型参数。上面提到了。注意一下
typename enable_if<stat == 1, bool>::type checkstate(){
cout <<"type is bool" << endl;
return true;
}
template<int stat>
typename enable_if<stat == 0, int>::type checkstate(){
cout <<"type is int" << endl;
return 5;
}
template<bool stat> //bool也可以。隐式转换为整型了,但是必须要常量。
typename enable_if<stat == true, int>::type checkstate1(){
cout <<"type is int" << endl;
return 5;
}
int main(){
const int myobj = 1; //必须是const
checkstate<myobj>(); //输出"type is bool"
checkstate<0>(); //输出"type is int"
return 0;
}
- 注意事项:在C++14前,不使用
enable_if_t的时候,返回类型前必须加typename来告知enable_if::type是个类型。还有就是非模板类型参数的限制。
到了c++14,我们可以使用enable_if_t来简化这一部分。我们无需在后面指定::type,自然同时也无需在前面使用typename。如这样:
1
2
3
4
5
6
7
template <int stat>
enable_if_t<stat == 1, bool> anotherCheck(){ //没有::type 也没有typename
cout <<"type is bool" << endl;
return true;
}
anotherCheck<1>();//一样使用
anotherCheck<0>(); //绝对不可以。就算有SFINAE,那是告诉你匹配不对的时候继续找,不报错。但是这里我们没写stat = 0情况,自然无论如何都找不到,重载决议找不到函数,调用一定会失败。所以报错。
给enable_if 添加一个额外的带默认值的参数
- 我们也可以给
enable_if_t的第二个参数加上一个默认参数。但是长得会和之前的不太一样。之前我们是直接把整个enable_if_t或者是typename enable_if::type当成函数返回值。
1
2
3
4
5
6
template<typename T, typename = std::enable_if_t<(sizeof(T) > 4)>>
T foo(T a) {
cout << a << endl;
return a;
}
foo<double>(20.123);//没问题
- 当然了,也可以使用非类型模板参数,像是这样:
1
2
3
4
5
template <int value, typename = enable_if_t<value == 2>>
void myfunc(){
cout <<"2" << endl;
}
myfunc<2>();//也没问题
- 有一点需要澄清。这里的模板头如何解释?
我们这里的第二个typename是一个独立的模板参数,仅仅是没有加名字。因为我们没有使用到它。所以如果你愿意,你也可以这样写
1
template <int value, typename whatever = enable_if_t<value == 2>>
我们知道了如果enable_if_t的第一个表达式为真,则这里是通过的。又由于在当下这个例子,我们是非类型模板参数而且enable_if_t没有给第二个参数,所以函数返回值就是void。
如果表达式为假,则会走SFINAE这一套。此处不会编译。针对当下的例子,如果没有做不等于2的条件的处理,则会报错找不到对应的函数。
但是这时候有个问题了,如果针对第一个函数,我们想让sizeof(T) < 4也成为一个模板怎么办?我们可能会直接这么写:
1
2
3
4
5
6
7
8
9
10
template<typename T, typename = std::enable_if<(sizeof(T) > 4)>>
T foo(T a) {
cout << ">4" << endl;
return a;
}
template<typename T, typename = std::enable_if<(sizeof(T) <= 4)>> //错误,重定义了。
T foo(T a) {
cout << "<=4" << endl;
return a;
}
这样是错误的,提示重定义了。为什么?
enable_if 导致的的函数模板重定义问题
我们知道了,enable_if 第二个参数的默认值是void(也就是表达式为真的时候,没有指定第二个参数就默认值是void)
所以当如果前面表达式为真的时候,这个函数会被展开成这个样子
1
2
3
4
5
6
7
8
template<typename T, typename = std::enable_if_t<(sizeof(T) > 4)>>
void func() {
}
//展开后:
template<typename T, typename = void>
void func() {
}
所以如果我们还有一个<=4,当也为真的时候,那这个整个模板头的参数就都一样了。
函数模板参数的默认值的不同并不足以区分两个函数模板是重载关系。官方是这么说的:
常见错误是声明二个函数模板,而它们仅于其默认模板实参相异。这是无效的,因为这些函数声明被当做同一函数模板的再声明(默认模板实参不为函数模板等价所考虑)。
所以。上面的代码。在编译器看来是这样的:
1
2
3
4
template<typename T, typename>
T foo(T a);
template<typename T, typename>
T foo(T a);
这就很明显是重定义了。因为我们只有第二个模板参数的默认值是不同的。但是默认值不在签名范围内。就好比不能通过默认值不同重载不同函数一样。
一个详细例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<typename T,
typename = typename std::enable_if<std::is_same<int, T>::value>::type>
void g() { }
template<typename T,
typename = typename std::enable_if<std::is_same<double, T>::value>::type>
void g() { }
template<typename T,
typename std::enable_if<std::is_same<int, T>::value>::type* = nullptr>
void f() { }
template<typename T,
typename std::enable_if<std::is_same<double, T>::value>::type* = nullptr>
void f() { }
在
g()中 我们发现只有模板参数的默认值是依赖名,只有默认值依赖于前一个参数T,但是默认值又不算做签名考虑在内,所以一定会冲突。在
f()中,我们发现第二个模板参数本身就是依赖名,因为里面的T是依赖于第一个参数T的。所以就成功区分了。
那么我们如何解决这个问题呢?我们可以让第二个参数本身不同即可。
我们所谓的“让参数本身不同”的方法之一就是这个办法。另一种办法是20.3.2提到的添加一个额外的带默认值的模板参数。
我们刚说过,上面那种的模板类型区分不开:template<typename, typename> 。那么我们应该这么写:
1
2
3
4
typename<typename T, std::enable_if_t<condition>* whatever = nullptr>
//或老版本的
typename<typename T, typename std::enable_if<condition>::type* whatever = nullptr>
//老版本依旧必须有typename,为了告知type是个类型
在这里,编译器看到的模板类型是这样的:template<typename, X*>。这里的X*的类型依赖于第一个参数的类型。所以此时足以区分
这里的whatever可以去掉。因为我们函数内并不使用它。
详细例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
template <typename T1, enable_if_t<(sizeof(T1) > 4)>* whatever = nullptr> //带t的新版
T1 functions(T1 a){
cout << a << endl;
cout <<" <=4" << endl;
return a;
}
template <typename T1, enable_if_t<(sizeof(T1) <= 4)>* whatever = nullptr>
T1 functions(T1 a){
cout << a << endl;
cout <<" <=4" << endl;
return a;
}
template <typename T1, typename enable_if<(sizeof(T1) > 4)>::type* whatever = nullptr> //不带t的老版
T1 functions(T1 a){
cout << a << endl;
cout <<" > 4" << endl;
return a;
}
template <typename T1, typename enable_if<(sizeof(T1) <= 4)>::type* whatever = nullptr>
T1 functions(T1 a){
cout << a << endl;
cout <<" <= 4" << endl;
return a;
}
functions<double>(10.123);
functions<int>(10);
//模板参数和非类型模板参数混用:
template <typename T, int T1, enable_if_t<(T1 > 4)>* whatever = nullptr>
T functions(T a){
cout << a << endl;
cout <<" > 4" << endl;
return a;
}
template <typename T, int T1, enable_if_t<(T1 <= 4)>* whatever = nullptr>
T functions(T a){
cout << a << endl;
cout <<" <= 4" << endl;
return a;
}
functions<double, 8>(10.123);
functions<string, 2>("12345");
当然了,这时候我们也可以使用using别名模板来让代码看起来更加简单。
https://stackoverflow.com/questions/52083873/c-sfinae-enable-if-t-in-member-function-how-to-disambiguate
https://stackoverflow.com/questions/31500426/why-does-enable-if-t-in-template-arguments-complains-about-redefinitions
6.4 使用enable_if 禁用某些模板
我们在6.2当中介绍了一个例子,在6.3当中学习了一下enable_if,这里我们就针对6.2当中的例子进行优化。
- 6.2中我们想解决的问题是:如果传入的参数不能被转换为string,则不要使用其构造函数模板。
- 我们在6.2当中解决问题的方式是添加一个非
const的拷贝构造。我们在这里不这样做,而是使用enable_if在某些条件下禁用构造函数模板。
- 我们在6.2当中解决问题的方式是添加一个非
也就是当传递的模板参数的类型不正确的时候(比如不是 std::string或者可以转换成 std::string 的类型),禁用如下构造函数模板:
1
2
template<typename T>
Person(T&& n)
所以我们搭配is_convertiable<FROM, TO>来进行使用(此处看下面讲解)
1
2
template <typename T, typename = std::enable_if_t<std::is_convertible_v<T,std::string>>>
Person(T&& n)
如果T可以被转换为string,则这个定义会被扩展为:
1
2
template<typename T, typename = void>
Person(T&& n);
否则这个函数模板会被忽略。
- 所以现在代码是这个样子 [c++17]:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class Person
{
private:
string name;
public:
template <typename T, typename = std::enable_if_t<std::is_convertible_v<T,std::string>>>
explicit Person(T&& n) : name(forward<T>(n)) {
cout << "万能引用+forward兼顾左值和右值。" << name << endl;
}
Person (Person const& p) : name(p.name) { //没有变化
cout << "此处是拷贝person对象进来 " << name << endl;
}
Person (Person&& p) : name(move(p.name)) { //没有变化
cout << "此处是移动person对象进来 " << name << endl;
}
};
int main(){
string names = "miku";
Person p1(names); //拷贝字符串 输出万能引用+forward兼顾左值和右值。
Person p3(p1); //拷贝对象 输出此处是拷贝person对象进来。
}
当然此处也可以使用别名模板简化,比如
1
using EnableIfString = std::enable_if_t<std::is_convertible_v<T,std::string>>;
一切皆大欢喜!
- 由于c++14没有给产生一个值的类型萃取定义带
_v的别名,所以得这么写:
1
template <typename T, typename = std::enable_if_t<std::is_convertible<T,std::string>::value>>
- 由于c++11没有给产生一个类型的类型萃取定义带
_t的别名,所以得这么写:
1
template <typename T, typename = typename std::enable_if<std::is_convertible<T,std::string>::value>::type>
以上都可以使用别名模板。
6.5 禁用某些特殊成员函数
- 注意我们不能通过使用
enable_if<>来禁用 拷贝或移动 构造函数以及其赋值函数。这是因为成员函数模板不会被算作拷贝构造或移动构造函数(依然会生成其默认版本),而且在需要使用这些函数的地方,相应的成员函数模板会被忽略掉。
所以就算我们有这样的类模板:
1
2
3
4
5
6
7
class C {
public:
template<typename T>
C (T const&) {
std::cout << "tmpl copy constructor\n";
}
};
- 在需要拷贝构造的时候,依然会调用到编译器合成的拷贝构造。
- 删掉拷贝构造函数也不行,因为这样在需要拷贝构造函数的地方会报错说该函数被删除了。
如果你硬要弄成模板的话,这么做:定义一个接受 const volatile 的 拷贝构造函数并将其标示为delete。这样做编译器就不会再隐式合成一个接受 const 参数的拷贝构造函数。在此基础上,可以定义一个构造函数模板,对于 non-volatile 的类型,它会优选被选择(相较于已删除的 copy 构造函数)注意这里是定义一个构造函数模板而不是拷贝构造函数模板。具体分析在最后“特殊成员函数能否是函数模板
- 这个东西叫做使用模板构造函数替代拷贝构造函数。这样做是极度不推荐的!!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
class C{
public:
int val;
C() = default;
C(int a):val(a){};
C(const volatile C&) = delete;
template<typename T>
C(const T&){ //这是构造函数模板不是拷贝构造函数模板。
cout <<"template" << endl;
}
};
int main(){
C obj1(10);
C obj2(obj1); //template
}
- 注意,构造函数除外。
6.6 关于对整个类使用enable if
目前,类模板无法应用这个东西。针对于类模板,enable_if只能起到一种static_assert的作用。由于类和类模板不能重载,所以自然不存在候选集这个东西。也不存在SFINAE。enable_if在应用中的感觉是一种调整候选集的作用。
在函数模板中,enable_if起到的作用是活用了SFINAE的特性。
如果硬要做static_assert是什么样的?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template<typename T, typename = void> //主模板。注意这里。必须有默认值。但是类型需要判断一下
struct test{
};
template<typename T>
struct test<T, typename std::enable_if<(sizeof(T) <= 1)>::type>{ //偏特化。
void func(){
cout << "called" << endl;
}
};
//template<typename T> 不可这么写
// struct test<T, typename std::enable_if<(sizeof(T) <= 1)>::type>{
// void func(){
// cout << "called" << endl;
// }
// };
- 第一点。必须采用偏特化的形式。而且因为类模板没有重载所以不能写最下面那一组。只能要么主模板,要么一个偏特化版本。
- 第二点:主模板的第二个对应了enable_if的模板参数必须有默认值为 为什么?
- 首先,我们主模板有了两个模板参数。我们如果没有默认值,则调用的时候比如
test<int> objs1;此时我们只显式指定了一个模板参数。类模板没法自动推导参数,那么第二个参数是空白的。编译不通过。 - 其次,因为一旦enable_if的要求我们不能满足,在这里enable_if我们没有第二个参数,所以这个type会是void。
- 首先,我们主模板有了两个模板参数。我们如果没有默认值,则调用的时候比如
- 第三点:为什么默认值这里用了void,别的可以不?
- 我们要把默认值理解为:虽然我们不需要显式指定,但是它依旧存在。什么意思?
假设我们现在把上面的默认值换为了double。现在是这样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
template<typename T, typename = double>
struct test{
void func(){
cout << "default" << endl;
}
};
template<typename T>
struct test<T, typename std::enable_if<(sizeof(T) <= 1)>::type>{
void func(){
cout << "called" << endl;
}
};
int main() {
test<char> objs1;
objs1.func(); //输出default
test<int> objs2;
objs2.func(); //还是输出default
}
为什么两个都是default?
我们思考一下刚才说的:我们要把默认值理解为:虽然我们不需要显式指定,但是它依旧存在。
我们显式补齐参数类型来看一下:
1
2
3
4
test<char, double> objs1;
objs1.func();
test<int, double> objs2;
objs2.func();
因为我们提到了:在这里enable_if我们没有第二个参数,所以这个type会是void。
- 所以针对
objs1,编译时发现第二个条件满足,所以此时模板参数的第二个参数会是void。
但是我们的默认值是double。相当于我们传入了<char, double>。但是偏特化版本实例化出来的是<char, void>。我们发现明显是默认版本符合参数要求。所以一定会调用default。
- 此时针对
obj2,编译时发现第二个条件不满足,但是发现主模板匹配。则匹配主模板。
此时,如果我们显式的使用<char, void>,则可以正确满足条件。
1
test<char, void> objs3; // called
这个时候,我们显式指定的值会覆盖掉默认值。此时第二个参数是void。而针对于偏特化版本enable_if推断的第二个参数也是void。此时明显偏特化版本符合。所以这时候会调用偏特化。
所以按理说,如果我们把特化版本的enable_if,让他的第二个参数和主模板的类型默认值相等,这样做就可以。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template<typename T, typename = double>
struct test{
void func(){
cout << "default" << endl;
}
};
template<typename T>
struct test<T, typename std::enable_if<(sizeof(T) <= 1), double>::type>{ //第二个参数和默认值相等
void func(){
cout << "called" << endl;
}
};
test<char> objs1;
objs1.func();
test<int> objs2;
objs2.func();
此时针对
obj1, 编译时发现第二个条件满足,且有第二个参数。所以此时模板参数的第二个参数会是double。- 又因为默认值是
double,但是类模板的调用顺序是 全特化类>偏特化类>主模板类。这个时候主模板和偏特化类都符合,则优先调用偏特化类。
- 又因为默认值是
此时针对
obj2,编译时发现第二个条件不满足,但是发现主模板匹配。则匹配主模板。
https://stackoverflow.com/questions/48045559/how-do-i-declare-sfinae-class
https://stackoverflow.com/questions/16972684/how-to-use-enable-if-for-restricting-a-whole-class
https://stackoverflow.com/questions/75154649/why-when-use-enable-if-in-class-tempalte-have-to-set-the-second-parameters-defa/75154785?noredirect=1#comment132622904_75154785
第七章 到底是按值传递还是按引用传递?
一般来说,我们在使用引用传递的时候,会有三种情况。
虽然已经是老生常谈,但是这里还是写一下做一下recall。下面的X指的是具体类型。
按照常量左值引用传递
const X&- 由于什么类型的参数都可以接。包括右值。但是不可修改参数。所以主要目的是防止拷贝,并且接收任意类型数据。
按照左值引用传递
X&- 主要目的是为了更改参数,并且防止拷贝。
按照右值引用传递
X&&- 主要是为了接收形参为右值的参数。参数可以被更改或被窃取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
//更改的例子 //注意不能直接写,要写完美转发。因为具名右值是左值。 void func(int&& a){ a = 200; } template<typename T> void capsule(T&& c){ cout << c << endl; //20 func(forward<T>(c)); cout << c << endl;//200 } int main(){ capsule(20); return 0; }
一般来说,在如下情况下我们需要使用引用传递参数。
- 对象不允许被拷贝的时候
- 入参需要被修改的时候(参数被用于返回数据)
参数及其所有属性需要被模板转发到别的地方的时候。
- 拷贝开销极大,所以使用引用传递可以获得明显的性能提升之时。
其余情况可以使用值传递。
7.1 按值传递
有关临时对象,隐式类型转换的笔记在杂记2
有关各种拷贝构造相关的在杂记
我们先来简单看看按值传递的情况
当按值传递参数时,原则上所有的参数都会被拷贝。因此每一个参数都会是被传递实参的一份拷贝。对于 T类的对象,参数会通过 T类的拷贝构造函数来做初始化。
事实上,编译器自己可以通过移动语义(move semantics)来优化掉对象的拷贝,这样即使是对复杂类型的拷贝,其成本也不会很高。
假设我们有如下函数模板:
1
2
3
4
template<typename T>
void func(T obj){
//一些内容
}
在我们应用于myobj类型参数后,实例化后的代码为
1
2
3
4
5
6
void func(myobj obj){
//一些内容
}
myobj v1(10);
func(v1);
传递myobj类型的时候,obj会是传入参数v1的拷贝。如果myobj类型对象的拷贝的成本非常高,那么会很痛苦。但并不是所有情况都会调用拷贝构造
1
2
3
4
5
6
7
8
9
//假设myobj类对象提供了全部6个特殊成员函数,所以
myobj a(20); //构造
func(a); //拷贝构造
func(myobj(20)); //构造 注意,只有一次构造。
func(move(a)); //移动构造
在第一次调用中,被传递的参数是左值(lvalue),因此拷贝构造函数会被调用。
但是在第二次调用中,被传递的参数是纯右值 (prvalue 多在临时对象或者某个函数的返回值),此时编译器会优化参数传递,使得拷贝构造函数不会被调用。从C++17开始,C++标准要求这一优化方案必须被实现。在C++17之前,如果编译器没有优化掉这一类拷贝,它至少应该先尝试使用移动语义,这通常也会使拷贝成本变得比较低廉。
编译器会尝试拷贝优化,如果不行,会尝试移动语义。
在最后一次调用中,被传递参数是将亡值(xvalue ,一个使用了move()的已经存在的对象), 这会通过告知编译器我们不再需要a的值。通过这种方式,我们强制调用移动构造。
NRV优化在杂记2。复制省略在杂记3
- 再次重申按照值传递会导致参数类型退化。
auto也会退化。(杂记3)
7.2 按引用传递
7.2.1 按常量左值引用传递 const&
为了避免(不必要的)拷贝,在传递非临时对象作为参数时,可以使用 const 引用传递。
- 比如这个函数模板就永远不会拷贝被传递对象
1
2
3
4
template <typename T>
void func(const T&){
//一些内容
}
- 内置类型通过引用传递不会提升性能。
之所以不能提高性能,是因为在底层实现上,按引用传递还是通过传递参数的地址实现的。地址会被简单编码,这样可以提高从调用者向被调用者传递地址的效率。不过按地址传递可能会使编译器在编译调用者的代码时有一些困惑:被调用者会怎么处理这个地址?理 论上被调用者可以随意更改该地址指向的内容。这样编译器就要假设在这次调用之后,所有缓存在寄存器中的值可能都会变为无效。而重新载入这些变量的值可能会很耗时(可能比拷贝对象的成本高很多)。你或许会问在按 const 引用传递参数时:为什么编译器不能推断出 被调用者不会改变参数的值?不幸的是,确实不能,因为调用者可能会通过它自己的非 const引用修改被引用对象的值(这个解释太好,另一种情况是被调用者可以通过 const_cast 移除参数中的 const)。
inline可能会对此情况有所优化。
- 按照引用传递不会引发类型退化。也就是说数组不退化为指针,也不会移除CV限定。但是要注意函数模板参数类型。
T的类型推断不会是一个const类型,因为const已经是函数参数的一部分了,所以不会是模板参数类型的一部分。这里搭配1.2和函数模板参数推导看。
1
2
3
4
5
6
7
8
9
10
template <typename T>
void f(T& param) { //注意这里是T&
std::puts(__PRETTY_FUNCTION__);
}
int main() {
const int p = 2;
f(p); //T的类型为const int。很好理解。因为引用不会去除cv
//所以在f函数内使用T声明的变量自然会带const
}
但是如果是这样的:
1
2
3
4
5
6
7
8
9
10
template <typename T>
void f(const T& param) { //注意这里是const T&
std::puts(__PRETTY_FUNCTION__);
}
int main() {
const int p = 2; //T的类型为int。也很好理解。因为const已经被函数模板参数匹配了。T自然就剩下了int。
//所以在f函数内使用T声明的变量自然不会带const
f(p);
}
7.2.2 按照普通(左值/右值)引用传递
如果想通过调用参数来返回变量值(比如修改被传递变量的值),就需要使用非 const 引用(要么就使用指针)。同样这时候也不会拷贝被传递的参数。被调用的函数模板可以直接访问被传递的参数。
假如我们有如下函数模板:
1
2
3
4
5
6
7
8
9
10
template<typename T>
void func (T& arg) {
//一些内容
}
int main() {
string s = "miku";
func(s);
func(string("miku"));//不可以。左值引用不可绑定右值
func(move(s));//不可以。左值引用不可绑定右值
}
左值引用不可绑定右值(废话)
但是有个问题。如果传入的参数是
const的。则在一些情况下参数类型会被推导为const引用。也就是这时候可以传递右值。原因:
const引用的初始化方式:在初始化常量引用时允许用任意表达式作为初始值,只要该表达式的结果能转换成引用的类型即可。—-《C++ Primer》第五版2.4.1第55页- 这就是为什么常量左值引用可以接任何类型参数。
- 也就是你可以这样:
1 2 3
const string& a = string("abc"); string s = "miku"; const string& b = move(s); //注意这里并不调用移动构造或移动赋值。因为并没有构造对象或者是进行赋值。
所以说一旦我们把东西换成这样:
1
2
3
4
5
6
7
8
9
10
template<typename T>
void func (T& arg) {
//一些内容
}
int main() {
const string s = "miku"; //换成const
func(s);
func(string("miku"));//不可以。左值引用不可绑定右值
func(move(s));//可以。T被推导为const string
}
- 在这种情况下,在函数模板内部,任何试图更改被传递参数的值的行为都是错误的。所以我们可以使用
enable_if或static_assert搭配is_const来禁止向非const应用传递const对象
1
2
3
4
5
6
7
8
9
10
11
12
//使用static_assert
template<typename T>
void func (T& arg) {
static_assert(!is_const<T>::value, "can't use const type variable");
cout << "called" << endl;
}
//使用enable_if
template<typename T, typename = enable_if_t<!is_const<T>::value>>
void func (T& arg) {
cout << "called" << endl;
}
7.2.3 按照万能引用传递 T&&
在杂记中我们详细说明了万能引用和引用折叠的部分。这里就不赘述了。
唯一要再次提醒的是,万能引用是唯一一种可能把T推导为引用类型的情况。因为有引用折叠。
比如
1
2
3
4
5
6
7
8
9
10
11
12
template <typename T>
void f(T&& param) {
std::puts(__PRETTY_FUNCTION__);
}
int s =5;
int& ref = s;
const int& ref2 = s;
f(5); //T推导为 int
f(ref);//T推导为 int&
f(ref2);//T推导为 const int&
- 在第二次调用中,如果在模板内部直接用 T 声明一个未初始化的局部变量,就会触发一个错误(引用对象在创建的时候必须被初始化)所以需要格外的注意。
7.3 使用ref和cref
看下面的ref和cref介绍即可。
7.5 处理返回值。
返回值也可以被按引用或者按值返回。但是按引用返回可能会带来一些麻烦,因为它所引用的对象不能被很好的控制。不过在日常编程中,也有一些情况更倾向于按引用返回:
- 返回容器或者字符串中的元素(比如通过
[]运算符或者front()方法访问元素)—EFFSTL笔记提到过。 - 允许修改类对象的成员
- 为链式调用返回一个对象(比如
>>和<<运算符以及赋值运算符)
但是使用不当可能会造成悬空引用。因此如何保证函数模板可以采用按值返回是一个问题。
因为:
- 在某些情况下,尤指万能引用的时候,
T会被隐式推断为引用类型
1
2
3
4
template<typename T>
T retR(T&& p){ // p 是万能引用
return T{…}; // 一旦传入的T类型是左值或左值引用,则T会被统一推导为引用类型。此时T就变成引用了。
}
- 即使函数模板被声明为按值传递,也可以显式地将
T指定为引用类型:
1
2
3
4
5
6
template<typename T>
T retV(T p){ //T完全可以被指定为引用类型 比如:
return T{…};
}
int x;
retV<int&>(x); // 在这里,显式指定这个函数模板的模板参数T为int&。
所以,解决方案有两个。
- 第一个:使用类型萃取的
remove_reference去掉T类型的引用。(下面有提到该部分)decay也可以。目前还没有看到这一部分。
1
2
3
4
template<typename T>
typename remove_reference<T>::type retV(T p){
return T{…}; // T一定会被推导为非引用类型
}
- 第二个:声明返回值为
auto类型。auto类型会导致类型退化,也就是隐式去掉类型的引用。杂记3中提到过。
1
2
3
4
template<typename T>
auto retV(T p){//返回值设置为auto
return T{…}; //一定会被推导为非引用类型。
}
7.6 应该如何声明模板参数?
我们在拷贝构造一章中详细分析了如何构建构造函数和几种方法的优劣。这里谈一谈和模板参数结合的情况。
- 将参数声明成按值传递:
- 这一方法很简单,它会对字符串常量和裸数组的类型进行退化,但是对比较大的对象可能会受影响性能。在这种情况下,调用者仍然可以通过
cref()和ref()按引用传递参数,但是要确保这一用法是有效的。
- 这一方法很简单,它会对字符串常量和裸数组的类型进行退化,但是对比较大的对象可能会受影响性能。在这种情况下,调用者仍然可以通过
- 将参数声明成按引用传递:
- 对于比较大的对象这一方法能够提供比较好的性能。尤其是在下面几种情况下:
- 将已经存在的对象(
lvalue)按照左值引用传递, - 将临时对象(
prvalue)或者被move()转换为可移动的对象(xvalue)按右值引用传递,
- 将已经存在的对象(
- 或者是将以上几种类型的对象按照万能引用+完美转发传递。
- 由于这几种情况下参数类型都不会退化,因此在传递字符串常量和裸数组时要格外小心。
- 对于万能引用,需要意识到模板参数可能会被隐式推断为引用类型(引用折叠)。
- 对于比较大的对象这一方法能够提供比较好的性能。尤其是在下面几种情况下:
综上所述:
- 默认情况下,将参数声明为按值传递。这样做比较简单,即使对字符串常量也可以正常工作。对于比较小的对象、临时对象以及可移动对象,其性能也还不错。对于比较大的对象,为了避免成本高昂的拷贝,可以使用
ref()和cref()。 - 如果需要一个参数用于输出,或者即用于输入也用于输出,那么就将这个参数按非
const引用传递。但是需要按照 7.2.2 节介绍的方法禁止其接受const对象。因为针对普通引用类型为形参,如果传入一个const引用则会带着其形参推导为const引用。 - 如果使用模板是为了转发它的参数,那么就使用完美转发。也就是将参数声明为万能引用并在合适的地方使用
forward<>()。考虑使用decay<>或者common_type<>来处理不同的字符串常量类型以及裸数组类型的情况。 - 如果重点考虑程序性能,而参数拷贝的成本又很高,那么就使用
const引用。不过如果最终还是要对对象进行局部拷贝的话,这一条建议不适用
7.7 不要过分泛型化
通常来说,我们在使用函数模板的时候,不可能允许该函数传递任意类型的对象。因为针对不同的对象我们会有不同的操作。比如我们可能已经知道函数模板的参数只会是某些类型的 vector。这时候最好不要将该函数模板定义的过于泛型化,否则,可能会有一些令人意外的副作用。针对这种情况应该使用如下的方式定义模板:
1
2
3
4
template<typename T>
void printVector (const vector<T>& v){ //为啥不是T v?
//一些内容
}
- 为啥我们不直接
T v?- 首先,我们可以确定
T不可能是引用类型。因为传入的参数必定是一个vector,变动的只是vector存储的元素类型。因为容器不能使用引用作为其元素类型。 - 其次,通常来说,针对容器我们会使用引用传递。因为不必要的拷贝会极大降低性能。甚至针对不修改的情况我们要使用
const引用传递。 - 最后,使用这种不过分泛型化的参数传递可以很容易的让其他人看出来我们这个函数的作用:它会干什么,它不会干什么。如果我们直接传入一个
T,则会非常不清晰。
- 首先,我们可以确定
第八章 编译期编程
8.4 SFIANE
在一个函数调用的备选方案中包含函数模板时,编译器首先要决定应该将什么样的模板参数用于各种模板方案,然后用这些参数替换函数模板的参数列表以及返回类型,最后评估替换后的函数模板和这个调用的匹配情况(就像常规函数一样)。但是这一替换过程可能会遇到问题:替换产生的结果可能没有意义。不过这一类型的替换不会导致错误,C++语言规则要求忽略掉这一类型的替换结果。
但是上面讲到的替换过程和实际的实例化过程不一样:即使对那些最终被证明不需要被实例化的模板也要进行替换(不然就无法知道到底需不需要实例化)。不过它只会替换直接出现在函数模板声明中的相关内容(不包含函数体)
我们有下面的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
template<typename T, unsigned N>
std::size_t len (T(&)[N]){ //这个版本是为没有size_type成员的对象准备的。
cout <<"no size" << endl;
return N;
}
template<typename T>
typename T::size_type len (T const& t){ //这个版本是为有size_type成员的对象准备的。
cout <<"size" << endl;
return t.size(); //同时要求必须有size成员函数
}
std::size_t len (...) //使用可变参数来对其他任何没有size_type成员 !!!!!!注意这里没有模板头
{
cout <<"other" << endl;
return 0;
}
int main(){
int a[10];
len(a); // OK 原始数组没有size_type
len("tmp"); //OK: 字符串没有size_type
std::vector<int> v;
len(v); // OK: vector有size_type
int* p;
len(p); //OK: 指针类型全都不匹配。走最下面的应急类型。
return 0;
}
- 针对原始数组和字符串。因为他俩没有
size_type所以会忽略第二个函数模板 - 针对
vector,因为有size_type所以匹配第二个。- 注意,如果有一些类型有
size_type,但是由于我们在第二个函数模板中使用了size成员函数。如果类型没有这个size成员函数,会报错说缺少size成员函数
- 注意,如果有一些类型有
- 针对指针,啥都匹配不了,只能匹配第三个。
SFIANE 和重载解析:
除非在某些情况下,该模板不应该参与重载解析过程 的意思就是在该情况下,使用 SFINAE 方法 SFINAE 掉了这个函数模板
我们在6.2,6.4和6.5详细说明了某些特殊成员函数模板(尤指构造函数模板)在一些情况下会导致一些错误的匹配。所以我们需要使用enable_if让其在某些特殊情况下禁用这个函数模板。也就是在某些情况下(enable_if不满足的条件下),让这个函数退出重载候选集。
SFINAE 需要什么条件?
SFINAE特性的激活需要三个条件发生:替换/推导语境,失败发生和其他可行选项。
连起来一句话就是:当模板形参在替换/推导中失败时,从重载集中丢弃这个特化,转而寻找其他可行选项,而非导致编译失败。
替换失败不是错误 (Substitution Failure Is Not An Error) 在函数模板的重载决议中会应用此规则:当模板形参在替换成显式指定的类型或推导出的类型失败时,从重载集中丢弃这个特化,而非导致编译失败。
….
以上类型或表达式在以用来替换的实参写出时谬构(并带有必要的诊断)的场合是替换失败。替换以词法序进行,并在遇到失败时终止。
所以,
- 替换中出现错误,是替换失败。
- 不是替换场合就只是失败。
- 是替换场合但是没发生错误就只是替换。
例子请查看modern C++ design的2.5
8.4.1 使用decltype 和 SFIANE搭配解决我们上一部分的问题
首先说明,这一部分在decltype和逗号表达式的部分理解不透彻,而且属于奇技淫巧,非常复杂。我会把所有找得到的相关资料贴在这里。
我们之前一节说道:
注意,如果有一些类型有
size_type,但是由于我们在第二个函数模板中使用了size成员函数。如果类型没有这个size成员函数,会报错说缺少size成员函数
这个问题还是挺痛苦的。我们如果没有在在函数声明中以某种方式要求 size()成员函数必须存在,这个函数模板就会被选择并在实例化过程中发生错误。
- 处理这一情况有一种常用模式或者说习惯用法:
- 通过尾置返回类型语法(trailing return type syntax)来指定返回类型(在函数名前使用auto,并在函数名后面的->后指定返回类型)。
- 通过
decltype和逗号运算符定义返回类型。将所有需要成立的表达式放在逗号运算符的前面(为了预防可能会发生的运算符被重载的情况,需要将这些表达式的类型转换为 void)。
- 在逗号运算符的末尾定义一个类型为返回类型的对象。
例子:
1
2
3
4
template<typename T>
auto len (T const& t) -> decltype( (void)(t.size()), typename T::size_type()){
return t.size();
}
类型指示符 decltype 的操作数是一组用逗号隔开的表达式,因此最后一个表达式 T::size_type()会产生一个类型为返回类型的对象(decltype 会将其转换为返回类型)。而在最后一个逗号前面的所有表达式都必须成立,在这个例子中逗号前面只有 t.size()。之所以将其类型转换为void,是为了避免因为用户重载了该表达式对应类型的逗号运算符而导致的不确定性
typename T::size_type()为啥要这么写?- 首先,我们希望
size_type是一个类型。但是必须要加typename指明T::size_type是个类型。其次,我们对一个类型使用()就创建了一个这个类型的匿名对象。这是一个表达式。这个表达式是返回类类型纯右值的函数调用(说人话就是类型名+()生成匿名临时对象,这个对象的类型自然是类类型。临时对象又是纯右值),所以推导出来的类型就是它本身的类型。就好比decltype(int())等于int一样。 - 为啥要放对象不能放类型?因为你不能
decltype(int)。我们是通过一个实体或表达式去推导出类型。而不是通过一个类型推导出一个类型。T::size_type是个类型所以不可以。我们唯一能做的是使用T::size_type这个类型实例化出一个这个类型的对象。
- 首先,我们希望
这一部分转换的粗浅理解 (其实是我理解错了,但是也还是有用信息):
- 首先,根据N4140标准的13.3.1.2/9 [over.match.oper]部分:
对于
operator,、一元operator&和operator->,如果候选函数集中没有可行函数(见后述),那么将运算符解释为内建运算符。
- 其次,
void()是一个表达式。它产生一个类型为纯右值的void。但是它是一个不完整类型。出自这里 - 关于decltype的更多故事
- https://stackoverflow.com/questions/16044514/what-is-decltype-with-two-arguments
- https://stackoverflow.com/questions/69366618/the-full-story-about-the-decltype-comma-trick
- https://stackoverflow.com/questions/28837332/sfinae-static-castvoid-or-void
- https://stackoverflow.com/questions/14003366/what-does-the-void-in-auto-fparams-decltype-void-do#comment19335347_14003374
- https://stackoverflow.com/questions/11775639/how-is-type-deduced-from-auto-return-type
- https://stackoverflow.com/questions/39279074/what-does-the-void-in-decltypevoid-mean-exactly
- https://stackoverflow.com/questions/4031228/why-is-operator-void-not-invoked-with-cast-syntax
- https://stackoverflow.com/questions/69314599/casting-to-void-to-avoid-use-of-overloaded-user-defined-comma-operator
最终我的核心理解为何要转换为void?答案是使用它来确认该函数具有返回值,我们已断言忽略它是安全的。也可以不使用c风格转换专用static_cast。出自这里和这里
转换为
void后,表达式的值被丢弃。
比如换成这样c++风格:
1
2
3
4
template<typename T>
auto len (T const& t) -> decltype(static_cast<void>(t.size()), typename T::size_type() ){
return t.size();
}
所以说这里转换为void的目的是:先判断t.size()这个表达式是否成立,也就是这个函数调用是否能成功,也就是t是否有这个成员函数。因为我们不关心返回值,所以转成void。decltype可以在第一层接受如void这种不完整类型。其次,就算有人重载了operator,()做了一些乱七八糟的事情,由于左侧是空,所以也不会做一些什么奇怪的举动。逗号运算符只保留最右侧的作为结果。所以返回值最后还会是T::size_type()。
他防止的是comma的重载定义在
t.size()的返回值类型上,因此添加到void的转换,使得这个返回值被丢弃,不能被利用,所以就不触发comma的重载 —-萧叶轩大佬的回答和这个很相似
我们之前链接里有,operator void()不会被覆盖看这里。
假设我们有个这样的残疾类型
1
2
3
4
5
6
struct foo {
struct size_type {
bool operator,(size_type) { return false;}
};
size_type size() { return {};}
};
它确实有一个size_type并且它确实有一个size()函数。但是,如果没有转换为void,模板不会推断出正确的返回类型,因为decltype( (t.size()), typename T::size_type() )是bool类型:
1
2
decltype( (t.size()), typename T::size_type());//等价于下面
decltype((t.size()).operator,(typename T::size_type())); //这个会返回一个false。
换成void之后,也就是前面的t.size()变为void类型,不会触发size_type类型的operator,()重载。
最后,我们的整体解决方案:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
template<typename T, unsigned N>
std::size_t len (T(&)[N]){
cout <<"no size" << endl;
return N;
}
template<typename T>
auto len (T const& t) -> decltype(t.size(), typename T::size_type()){
cout <<"has size"<<endl;
return t.size();
}
std::size_t len (...)
{
cout <<"other" << endl;
return 0;
}
第十一章 泛型库
11.1 可调用对象
注意:函数对象是可调用对象的一种。
函数对象类型可以是:
- 函数指针类型
- 重载了
operator()的 类类型(有时被称为仿函数),这其中包含 lambda 函数 - 包含一个可以产生一个函数指针或者函数引用的转换函数的 类类型。
注意:函数和到函数的引用不是函数对象类型,但因为函数到指针隐式转换,它们能用在期待函数对象类型的地方。但是他们都是可调用对象类型
这样的类型对应的值被称之为函数对象。
可调用对象除了函数对象以外,还包括:
- 比如包装在
std::function或std::bind的对象。(个人理解) - 成员函数指针类型。
- 成员变量类型。
由于lambda是重载了operator()的匿名类,所以符合函数对象要求。所以lambda是可调用对象,更是函数对象。
- 函数对象和可调用对象最大的区别是,函数对象可以像函数一样调用。比如
f(args...),但是可调用对象不一定可以。比如成员函数指针,就必须要进行this的添加。
尤为注意成员函数指针不是函数对象,因为不能使用如f(args)这样的方式调用。有关成员函数指针在杂记2
11.1.1 标准库中对函数对象的支持
我们在EFFSTL中详细介绍了for_each。在这里我粘贴一部分源码。
1
2
3
4
5
6
7
8
9
10
11
12
template <class _InIt, class _Fn>
_CONSTEXPR20 _Fn for_each(_InIt _First, _InIt _Last, _Fn _Func) { // perform function for each element [_First, _Last)
_Adl_verify_range(_First, _Last);
auto _UFirst = _Get_unwrapped(_First);
const auto _ULast = _Get_unwrapped(_Last);
for (; _UFirst != _ULast; ++_UFirst) {
_Func(*_UFirst); //这里已经对迭代器对象解引用了,所以直接传入的是迭代器对应的值。
// 注意这里调用函数的方式是直接把参数塞进去。所以传递函数对象就行 不用() 加了括号叫调用
}
return _Func; //看好了!!有返回值!!
}
- 当把函数名当作函数参数传递时,并不是传递函数本体,而是传递其指针或者引用。和数组情况类似,在按值传递时,函数参数退化为指针,如果参数类型是模板参数,那么类型会被推断为指向函数的指针。(函数指针可以直接使用而不用解引用。语法糖。参见杂记2)
- 和数组一样,按引用传递的函数的类型不会退化。但是函数类型不能真正用
const限制。如果将foreach()的最后一个参数的类型声明为const _Fn _Func &,const会被省略。(通常而言,在主流 C++代码中很少会用到函数的引用。) - 我们可以对函数进行
&去地址后显式传入函数指针。这和第一种调用方式相同(函数名会隐式的退化为成指针),但是相对而言会更清楚一些。
- 和数组一样,按引用传递的函数的类型不会退化。但是函数类型不能真正用
- 如果传递的是仿函数,就是将一个类的对象当作可调用对象进行传递。通过一个类类型进行调用通常等效于调用了它的
operator()。因此下面这样的调用:
1
_Func(*_UFirst);
会被转换为
1
_Func.operator()(*_UFirst);
注意在定义 operator()的时候最好将其定义成 const 成员函数。否则当一些框架或者库不希望该调用会改变被传递对象的状态时,会遇到很不容易发现的错误。
- 对于 类 类型的对象,有可能会被转换为指向 surrogate call function(代理函数,参见 C.3.5)的指针或者引用。此时,下面的调用:
1
_Func(*current);
会被转换为
1
(_Func.operator F())(*_UFirst);
其中 F 就是类类型的对象可以转换为的某一个指向函数的指针或者指向函数的引用的类型。
代理函数处于 C++ 最晦涩的角落。参考这里
Lambda 表达式会产生仿函数(也称闭包),因此它与仿函数(重载了
operator()的类)的情况一致。不过 Lambda 引入仿函数的方法更为简便,因此它们从 C++11 开始变得很常见。虽然我不喜欢。我们在杂记4的lambda章节中提到了一点:
在捕获列表为空的时候,lambda还有合成的用户定义转换函数。它的作用是返回一个函数指针。这个函数指针指向内部合成的静态成员函数,这个函数内部会调用本类的函数调用运算符
operator()- 但是它从来不会被当作代理函数,因为它的匹配情况总是比常规仿函数的
operator()要差。
11.1.2 处理成员函数和其额外的参数
我们这一节主要讲一下上一节没有讲到的成员函数和成员函数指针。
我们在杂记2的成员函数指针,杂记3的std::bind和深度探索对象模型的4.4中详细介绍了其使用方法和原理。
这种时候就可以会用invoke。
看下面的invoke部分即可。
11.1.3 函数调用的包装 (也就是invoke)
如果我们想要完美转发被调用函数的返回值给调用者,我们可以使用decltype(auto)搭配完美转发。
之所以要用decltype(auto)而非auto的原因是因为auto会导致类型退化。
我们提到过,auto一定会推导出返回类型为对象类型并且应用退化。而auto&或auto&&一定会推导为引用类型。而decltype(auto)则可以根据具体返回值的类型进行推导。
1
2
3
4
5
6
7
8
9
10
11
myobj start_const(myobj s){
return myobj(move(s));
}
template<typename callable, typename... Arg>
decltype(auto) calls(callable func, Arg&&... args){
return invoke(func, forward<Arg>(args)...); //要使用完美转发
}
int main(){
auto f = calls(start_const, myobj(4));
}
关于接收invoke的返回值的部分在下面invoke返回值部分。
11.2 类型萃取
什么是类型萃取?我的个人理解是: 计算(查询)和修改类型。
- 计算类型,就比如我们在STL2中提到的,增加一个中间层。有一些东西不是类,自己不能包含类型,那么我们就为它增加一个中间层,比如增加一些
typedef/using来实现类型的计算。同时,标准库提供给我们的比如is_const,is_convertable都算是计算类型。 - 修改类型,就比如标准库给的一些函数,比如
remove_reference,可以把一个类型修改为另一个类型。
通过类型萃取可以实现在编译期计算、查询、判断、转换和选择,增强了泛型编程的能力,也增强了程序的弹性,使得我们在编译期就能做到优化改进甚至排错,能进一步提高代码质量。
11.2.1 类型萃取中的一些注意事项
比如我们下面提到的remove_cv,
std::remove_cv_t<const int&>返回的类型依旧是const int&。因为这个const是底层const。- 所以这时候如果我们需要拿到
int,需要注意顺序和搭配:
1 2
std::remove_const_t<std::remove_reference_t<const int&>>; // 结果是int std::remove_reference_t<std::remove_const_t<const int&>>; // 结果是const int
- 所以这时候如果我们需要拿到
还有比如使用
add_rvalue_reference(declval提到过)的时候,并不是一定会返回一个右值引用。因为如果传入一个左值引用会导致引用坍缩,返回左值引用
1
2
cout << is_same_v<const int&&, add_rvalue_reference_t<const int>> << endl; //true。给const int加右值引用变成const int&&
cout << is_same_v<const int&, add_rvalue_reference_t<const int&>> << endl; //true。给const int&加右值引用导致坍缩变成const int&
所以我们说,使用类型萃取相关的标准库函数的时候,一定要详细查阅文档,了解其精确定义!!!
11.3 完美转发临时变量
很多时候我们可以完美转发一些泛型参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
void process(myobj& obj){
cout <<"&process called" << endl;
}
void process(myobj&& obj){
cout <<"&&process called" << endl;
}
template<typename... Args>
void forward_func(Args&&... args){
process(forward<Args>(args)...); //&&process called
process(args...); //&process called
}
int main(){
forward_func(myobj(10)); //注意传入的得是右值。forward是维持右值的右值性和左值的左值性,和move不同。不多赘述
return 0;
}
/*
const
&&process called
&process called
dest
*/
但是某些情况下,在泛型代码中我们需要转发一些不是通过参数传递进来的数据。此时我们可以使用 auto &&创建一个可以被转发的变量。
11.4 做为模板参数的引用(也就是模板参数类型为引用) [非常重要]
假如我们有如下代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
template<typename T>
void ref_test1(T arg){
cout <<std::boolalpha;
cout <<is_same_v<int&, decltype(arg)> << endl; //false
cout <<is_same_v<int&, T> << endl; //false
}
template<typename T>
void ref_test2(T& arg){
cout <<std::boolalpha;
cout <<is_same_v<int&, decltype(arg)> << endl; //true
cout <<is_same_v<int&, T> << endl; //false
}
int main(){
int a = 20;
int& ref_a = a;
ref_test1(a);
ref_test2(a);
ref_test1(ref_a);
ref_test2(ref_a);
ref_test1<int&>(a); //true true
ref_test2<int&>(a); //true true
return 0;
}
- 需要注意的是,无论我们传入的是否是引用类型,函数的输出都是一致的。为什么?
- 因为
ref_a本身是个引用,意思是表达式ref_a的类型是引用。但是整体表达式的类型永远不会是引用。- 比较难以理解?也就是说这种情况下,
T永远不会被推导为引用类型。因为T代表的是整体表达式的类型。 - 7.2.3反复强调,万能引用是唯一一种可能把
T推导为引用类型的情况。因为有引用折叠。
- 比较难以理解?也就是说这种情况下,
但是,如果
arg是按照T&类型传入的,那么arg的类型会是T&。所以arg此时是引用类型。- 如果硬要指定为引用类型,则需要显式指定模板参数。但是很多时候会有严重问题。具体看书吧,太复杂了。
- 表面上看,好像一般不会让模板参数类型为引用类型。但是在C++17 中,非类型模板参数可以通过推断得到。也就是模板参数类型可能是
template<typename T, decltype(auto) SZ>这样的形式。但是我们在invoke的返回值一章中提到过,decltype(auto)会很容易的根据表达式类型推导出引用类型。所以会出现问题。
- 表面上看,好像一般不会让模板参数类型为引用类型。但是在C++17 中,非类型模板参数可以通过推断得到。也就是模板参数类型可能是
11.5 推迟计算
可能某些时候我们会遇到不完整类型。如某个类可能是这样:
1
2
3
4
5
6
7
template<typename T>
class myclass{
public:
T* elem;
typename std::conditional<std::is_move_constructible<T>::value, T&&,T&>::type foo();
//...
};
- 这里通过使用
std::conditional来决定foo()的返回类型是T&&还是T&。决策标准是看模板参数T是否支持 移动构造。问题在于std::is_move_constructible要求其参数必须是完整类型。所以这时候,T如果是不完整类型,则会报错。 - 此时的解决方案是使用一个成员函数模板来替换现有的
foo()函数。因为模板只有在调用的时候会被实例化,所以可以将std::is_move_constructible的计算推迟到foo()函数的实例化阶段。
1
2
3
4
5
6
7
8
template<typename T>
class myclass{
public:
T* elem;
template<typename D = T>
typename std::conditional<std::is_move_constructible<D>::value, T&&,T&>::type foo(); //成员函数模板。第一个换成D就足够。
//...
};
11.6 在写泛型库的时候需要考虑的事情
- 在模板中使用万能引用来实现对参数的完美转发。如果转发的参数并不是通过外部传入的,就可以使用
auto &&(参见 11.3)。 - 如果一个参数被声明为万能引用,并且传递给它一个左值的话,那么模板参数会被推断为引用类型(参见杂记)。
- 在需要一个依赖于模板参数的对象的地址的时候,最好使用
std::addressof()来获取地址,这样能避免因为对象拥有一个重载了的operator &而导致的意外情况 - 对于成员函数,需要确保它们不会比预定义的 拷贝或移动构造函数或者赋值运算符更能匹配某个调用(参见 6.4)。
- 如果我们需要把函数处理的结果写回依赖于模板参数的调用参数,需要考虑如果传入参数是带有
const的情况。这种情况可能会以外导致该函数可以接受右值。(参见 7.2.2) - 请为将引用用于模板参数的副作用做好准备(参见 11.4 节)。当然非常不推荐这么做。尤其是在需要确保返回类型不会是引用的时候(参见 7.5)。
- 请为将不完整类型用于嵌套式数据结构这一类情况做好准备(参见 11.5 节)。比如二叉树。
- 为所有数组类型进行重载,而不仅仅是
T[SZ](参见 5.4 节)。
第十二章 深入模板基础
12.1 参数化声明
C++有四种基础模板。他们既可以出现在命名空间作用域,也可以出现在类作用域。
- 类模板
- 嵌套类模板
- 函数模板
- 成员函数模板
- 变量模板
- 静态数据成员模板
- 别名模板(就是using的那个)
- 成员别名模板
此处举例说明如何类外定义类模板的成员函数模板。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
template<typename T>
class myclass{
public:
template<typename U>
void func(T a, U b){ //类内
cout <<"in" << endl;
cout << a << b << endl;
}
template<typename U>
void out_class_func(T a, U b);
};
//类外
template<typename T>
template<typename U>
void myclass<T>::out_class_func(T a, U b){
cout <<"out" << endl;
cout << a << b << endl;
}
定义在类外的成员模板需要多个template<... >参数化子句:每个外围作用域的类模板一个,成员模板本身也需要一个。子句从类模板最外层开始逐行展示。
12.1.1 虚成员函数
在尾部我们已经说明了为什么成员函数不能既是虚函数又是函数模板。额外注意一点,类模板的普通成员函数可以是虚函数。因为它们的数量是固定的
12.1.3 主模板
类模板和函数模板都必须要有一个主模板
模板的一般性声明声明了主模板(primary templates)。如此声明的模板在模板名后无需书写尖括号模板参数子句。
非主模板会在声明类模板或变量模板的偏特化时出现。函数模板始终必须是主模板(因为函数模板没有偏特化)
12.2 模板参数(Template Parameters)
我们之前提到过模板参数主要有三种
- 类型模板参数
- 非类型模板参数 (3.1~3.2)
- 模板模板参数(5.7)
这些基本类型的模板参数中的任何一种都可以用作模板参数包的类型。但不可多种类型当做同一个参数包(4.1)
不一定所有的模板参数都需要名称。如果没有用到,则无需命名。同时需要注意的是,模板参数名可以在后续参数声明中引(使)用(但前置则不行):
1
2
3
4
template<typename T, //这个T在后面的参数声明中使用了。
T root,
template<T> class Buf>
class Structure;
12.2.1 类型模板参数
好像没啥可说的吧?
类型参数由关键字
typename或class所引导:二者是完全等价的。关键字后必须有一个简单的标识符,并且该标识符后必须带有逗号,以表示下一个参数声明的开始,闭合的尖括号>用以指示参数化子句的结束,=用以指示一个默认模板参数的起始。
12.2.2 非类型模板参数
搭配3.1~3.2,此处做补充
针对非类型模板参数有更多深入的限制。
- 非类型模板参数不可以有非类型指示符,比如
static、mutable等等 - 它们可以有
const和volatile限定符,但是如果这种限定符出现在参数类型的最顶层,就会被忽略。换句话说,对左值引用或指针来说支持底层const - 在表达式中使用时,非引用类型的非类型参数始终都是
prvalue。它们的地址无法被窃取,也无法被赋值。而另一方面,左值引用类型的非类型参数是可以像左值一样使用。
1
2
3
4
template<typename T, static int MAXSIZE> //例子1,错误。不能有static
void func1(T obj){
}
1
2
template<const int length> class Buffer; //二者相同。因为最顶层CV限定会被忽略
template<int length> class Buffer;
使用引用类型做为非类型模板参数时有诸多陷阱和要求。此处不做过多讲述,下面的两个链接非常有用。
https://zh.cppreference.com/w/cpp/language/template_parameters
https://stackoverflow.com/questions/28662784/reference-as-a-non-type-template-argument
12.2.3 模板模板参数
参考 5.7
12.2.4 模板参数包
参考第四章。此处做为补充
- 主模板中的类模板、变量模板和别名模板至多只可以有一个模板参数包,且模板参数包必须作为最后一个模板参数。函数模板则少些限制:允许多个模板参数包,只要模板参数包后面的每个模板参数都具有默认值或可以推导
- 类和变量模板的偏特化声明可以有多个参数包,这与主模板不同。这是因为偏特化是通过与函数模板几乎相同的推导过程所选择的。
12.2.5 模板的默认实参
参考 1.4 2.7。此处作为补充
模板参数包不能有默认实参。
其他的模板参数可以有默认实参。但是它必须和相应的参数类型匹配。比如类型参数不能有一个非类型默认实参
默认实参不能依赖于其自身的参数,因为参数的名称直到默认实参之后才在作用域内生效。然而,他可以依赖前面的参数
1 2
template<typename T, typename Allocator = allocator<T>> //OK class List;
类模板、变量模板或别名模板的模板参数遵照函数(不是函数模板)的默认参数规则:即从有默认实参的参数开始,后面的每一个参数都必须有默认实参。
- 是的你没看错,可以重复声明。但是只能有一个定义(ODR原则)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<typename T1, typename T2, typename T3, typename T4, typename T5> //可以,每一个都没有默认实参
class myclass;
template<typename T1, typename T2, typename T3, typename T4 = int, typename T5 = int> //可以,从T4开始每一个都有默认实参
class myclass;
template<typename T1, typename T2, typename T3 = int, typename T4, typename T5> //可以,由于T4和T5在上面的声明中已有默认实参,所以在这里是T3后的都有默认实参
class myclass{
public: //只有一个定义
void func(){
std::puts(__PRETTY_FUNCTION__);
}
};
//----以下是错误例子
template<typename T1 = char, typename T2, typename T3, typename T4, typename T5> //错误。T1后的参数都没有默认实参
class myclass;
- 而函数模板的模板参数的默认模板实参则不受此限制。即不需要后续的模板参数必须都有默认模板实参:
- 锐评:非常智能。
1
2
3
4
5
6
7
8
template<typename T1 = int, typename T2, typename T3 = float, typename T4 = char, typename T5>
void func(T1, T2, T3, T4, T5){
std::puts(__PRETTY_FUNCTION__);
}
/*
void func(T1, T2, T3, T4, T5) [with T1 = int; T2 = int; T3 = float; T4 = char; T5 = char]
*/
许多上下文不允许使用默认模板实参
偏特化(第二章说过)
- 模板参数包(刚说过)
- 类模板成员类外定义(不太常见)
- 友元类模板声明(更不太常见)
- 友元函数模板声明。除非它是定义并且在编译单元的其他任何地方都没有声明(啥东西)
12.3 模板实参(Template Arguments)
12章至16章非常精彩,尤其是在原理分析方面。但是内容过于庞多繁杂,涉及到大量的语法和规范内容。此处暂时略过。从19章起将会讲解实践性的内容
##
第十三章 模板中的名称
13.4 派生和类模板
类模板可以继承或被继承,模板和非模板场景之间没有显著的区别。然而,当从依赖名称引用的基类派生类模板时,有一个微妙区别。让我们首先看看非依赖型基类的情况。
13.4.1 非依赖型基类
类模板中,非依赖型基类是具有完整类型的类,可以在不知道模板参数的情况下即可确定的基类。换句话说,这个基类的名称是使用非依赖型名称表示的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
template <typename T>
class Base{
public:
int baseval;
using Type = int;
};
class D1:public Base<double>{ //非依赖名基类。
public:
void func(){
baseval = 200;
}
Type D1val = 300;
};
int main(){
D1 obj;
obj.func();
cout << obj.baseval << obj.D1val << endl;
}
- 模板中的非依赖型基类类似于普通非模板类中的基类,但当在模板派生中查找非限定名称时,非依赖型基类会优先考虑该名称,而后才是模板参数列表。类模板
D1的成员D1val总是对应Base<double>::Type(就是int) 的类型Type。
13.4.2 依赖型基类
前面的例子中,基类完全确定,不依赖于模板参数。只要知道模板定义,C++ 编译器就可以在这些基类中查找非依赖性名称。
针对这一部分看笔记深度探索c++对象模型的7.1
第十五章 模板实参推导
15.1 推导过程
基本的推导过程会比较“函数调用的实参类型”与“函数模板对应位置的参数化类型”,然后针对要被推导的一到多个参数,分别尝试去推断一个正确的替换项。每个实参-参数对都会独立分析,并且如果最终得出的结论产生矛盾(differ),那么推导过程就失败了。
这里有一个非常简单的例子:
1
2
3
4
5
template<typename T>
T max(T a, T b){
return b < a ? a : b;
}
auto g = max(1, 1.0);
这里第一个调用实参的类型是int,因此我们的max()模板的参数T会被推导成int。然而,第二个调用实参是double类型,基于此,T会被推导为double,但是这就与前一个推导产生了矛盾。注意:我们称之为“推导过程失败”,而不是“程序非法”。毕竟,可能对于另一个名为max的模板来说推导过程可能是成功的。也就是SFINAE
即使所有被推导的模板实参都可以一致地确定(即不产生矛盾),推导过程仍然可能会失败。这种情况发生于:在函数声明中,进行替换的模板实参可能会导致无效的结构 比如:
1
2
3
4
5
6
7
template<typename T>
typename T::ElementT at(T a, int i){
return a[i];
}
void f(int* p){
int x = at(p, 7);
}
这里T被推导为int*(T出现的地方只有一种参数类型,因此显然不会有解析矛盾)。然而,将T替换为int*在C++中对于返回类型T::ElementT显然是非法的,因此推导就失败了。
- 推导规则在1.2部分讲过了。
15.2 推导语境(上下文)
这一章是核心,:也就是比T复杂得多的参数化类型也可以匹配一个给定的实参类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
template<typename T>
void f1(T*);
template<typename E, int N>
void f2(E(&)[N]);
template<typename T1, typename T2, typename T3>
void f3(T1 (T2::*)(T3*));
class S {
public:
void f(double*);
};
template<typename... Args>
void f4(Args... callable){
std::puts(__PRETTY_FUNCTION__);
}
template<typename... Args>
void f5(std::function<void(Args...)> callable){
std::puts(__PRETTY_FUNCTION__);
}
void callablefunc(int a, int b, int c){
cout <<"callablefunc" << endl;
};
template<typename T>
void f6(T callable){
std::puts(__PRETTY_FUNCTION__);
}
template<typename T>
void f7(vector<T> callable){
std::puts(__PRETTY_FUNCTION__);
}
void g(int*** ppp){
f1(ppp); // 形参T的类型被推导为int**
bool b2[42];
f2(b); // 形参E的类型被推导为bool,形参N的类型被推导为42
f3(&S::f); // 形参T1的类型被推导为void, 形参T2的类型被推导为S, 形参T3的类型被推导为double
std::function<void(int, int, int)> myfunc(callablefunc);
f4(myfunc); //形参Args...的类型被推导为{int, int, int}
f5(myfunc); //形参Args...的类型被推导为std::function<void(int, int, int)>
vector<int> a{1,2,3};
f6(a); //形参T的类型被推导为std::vector<int>
f7(a); //形参T的类型被推导为int
}
复杂的类型声明都是用比它更基本的结构(例如指针、引用、数组、函数声明;成员指针声明;模板ID等)来组成的,匹配过程从最顶层结构开始处理,一路递归其各种组成元素。可以说基于这一方法,大部分类型声明结构都可以进行匹配,而这些结构也被称为“推导语境“。
然而,有些结构不能作为推导语境。查看0.6,搜索“语境”或直接查看文档。
第十九章 萃取的实现
19.1.1 实现简单的固定萃取
假设我们需要对一个原始数组求和。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template<typename T>
class calc_accumu_old{
public:
T ret_val{}; //使用值初始化,确保每一个类型都有合适的初始化值。
auto getsum(const T* start, const T* end){
while(start != end){
ret_val += *start;
++start;
}
cout << ret_val << endl;
return ret_val;
}
};
int main(){
int num[] = {1,2,3,4,5};
char str[] = "abcdefg";
calc_accumu_old<int> calc;
calc.getsum(num, num+5);//正常
calc_accumu_old<char> calc_char;
calc_char.getsum(str, str+7);//错误了
return 0;
}
- 表面上万事大吉,但是遇到
char却错误了。为什么?因为char按照ASCII编码后相加,明显超出了char的数据范围,就发生了溢出,这时候怎么办? - 我们确实可以引入额外参数,或者针对整个类进行特化,但是非常不便。我们尝试一下萃取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
template<typename T>
struct retvalTypeTraits{ //主模板
using retType = T; //类型定义
};
template<>
struct retvalTypeTraits<char>{ //针对char类型特化
using retType = int; //类型定义
};
template<>
struct retvalTypeTraits<int>{ //针对int类型特化
using retType = unsigned int; //类型定义
};
template<typename T>
class calc_accumu{
public:
using Ret = typename retvalTypeTraits<T>::retType; //为了方便起见使用别名模板。
Ret ret_val{}; //使用值初始化,确保每一个类型都有合适的初始化值。此处有问题,如果Ret类型没有默认构造,就不保证能够正确初始化。
auto getsum(const T* start, const T* end){
while(start != end){
ret_val += *start;
++start;
}
cout << ret_val << endl;
return ret_val;
}
};
int main(){
int num[] = {1,2,3,4,5};
char str[] = "abcdefg";
calc_accumu<int> calc;
calc.getsum(num, num+5);
calc_accumu<char> calc_char;
calc_char.getsum(str, str+7);
return 0;
}
- 这样就解决了问题。我们成功应用了萃取。
retvalTypeTraits就是我们提到的元函数。返回类型的元函数。
19.1.2 值萃取
我们在上面的例子中提到,如果值初始化的类对象没有默认构造,就不能保证其被正确初始化。那么这时候我们可能需要额外新增一种萃取。也就是值萃取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
template<typename T>
struct retvalTypeTraits{
using retType = T; //类型定义
static const retType zero = 0; //版本1
};
template<typename T>
struct retvalTypeTraits{
using retType = T; //类型定义
static constexpr retType zero = 0; //版本2
};
template<>
struct retvalTypeTraits<char>{ //某种特化
using retType = int; //类型定义
static const retType zero;//版本3 类内仅声明
};
const int retvalTypeTraits<char>::zero = 0;
template<typename T>
struct retvalTypeTraits{
using retType = T; //类型定义
inline static const retType zero = 0; //版本4 C++17
};
版本1:使用
static const。- 限制:只能使用整型或枚举类型进行类内初始化
版本2:使用
static constexpr。- 优点:可以使用浮点类型以及其他字面值类型进行类内初始化
- 缺点:自定义类型可能不是字面值类型,比如其构造函数并不是
constexpr
版本3:类内定义类外声明
- 缺点:比较麻烦
版本4:使用
inline[c++17]C++17 后 静态数据成员可以声明为
inline。inline静态数据成员可以在类定义中定义,而且可以指定初始化器。它不需要类外定义
这种就算是返回值的元函数。又因为我们既有值萃取又有类型萃取,这种可以被称为多返回值的元函数。
19.1.3 参数化萃取
我们在上面的基础例子中,发现一个问题。也就是我们的返回值类型是和萃取类绑定到一起的。而且萃取类是不能更改的。始终为retvalTypeTraits。
这样的话,如果用户想要增添更多的特化,就必须找到retvalTypeTraits的文件然后添加更多的特化,比较丑陋。为了解决这一问题,可以为萃取引入一个新的模板参数 PT,其默认值就是我们萃取模板的对应值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
template<typename T>
struct retvalTypeTraits{ //主模板
using retType = T; //类型定义
static const retType zero = 0;
};
template<>
struct retvalTypeTraits<char>{ //针对char类型特化
using retType = int; //类型定义
static const retType zero = 0;
};
struct my_customize_trait{ //用户定义的萃取模板
using retType = unsigned int; //类型定义
static const retType zero = 1000;
};
template<typename T, typename PT = retvalTypeTraits<T>> //第二个参数拥有默认值,默认值就是默认萃取模板
class calc_accumu{
public:
using Ret = typename PT::retType; //为了方便起见使用别名模板。
Ret ret_val = PT::zero;
auto getsum(const T* start, const T* end){
while(start != end){
ret_val += *start;
++start;
}
cout << ret_val << endl;
return ret_val;
}
};
PT拥有默认值,默认值就是默认萃取模板。这样的好处是用于可以完全不关心第二个模板参数。而如果确有需求,可以放入自己的萃取模板。
19.2 萃取和策略(policy)
我们有没有发现上面的代码表面是用到了模板,但其实也就仅仅是用到了模板而已。我们的getsum对任意类型的T都有统一的计算方式。那么问题来了,如果我想要针对某种场景进行特化呢?比如某个指针是自定义的智能指针或迭代器,且没有间接访问运算符呢?
这时候我们很容易想到一点:给getsum也换成可变的。这种行为我们就可以叫做policy。策略。
我们看一下书里的例子:
1
2
3
4
5
6
7
8
9
10
template<typename T, typename Policy = SumPolicy, typename Traits = AccumulationTraits<T>>
auto accum (T const* beg, T const* end){
using AccT = typename Traits::AccT;
AccT total = Traits::zero();
while (beg != end) {
Policy::accumulate(total, *beg);
++beg;
}
return total;
}
在这一版的
accum()中,SumPolicy是一个策略类,也就是一个通过预先商定好的接口(accumulate),为算法实现了一个或多个策略的类。如果提供一个不同的策略对数值进行累积的话,我们可以计算完全不同的事情。比如我们完全可以有一个
multpolicy
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class SumPolicy { //加法
public:
template<typename T1, typename T2>
static void accumulate (T1& total, T2 const& value) {
total += value;
}
};
class MultPolicy { //乘法
public:
template<typename T1, typename T2>
static void accumulate (T1& total, T2 const& value) {
total *= value;
}
};
- 但是此时注意,还记得我们把初始值设为0了吗?此时对于乘法就就会出现问题。因为乘以0永远是0。这就说明了需要仔细设计到底哪些是萃取,哪些是策略。同时,应该记住不是所有的东西都要用萃取和策略。比如标准库的
accumulate就把初始值作为了第三个参数。
19.2.1 萃取和策略的区别
- 策略更侧重于行为,而萃取更侧重于类型
- 策略代表的是泛型函数和类型(通常都有其常用地默认值)的可以配置的行为。萃取代表的是一个模板参数的本质的、额外的属性。
- 萃取:
- 萃取在被当作固定萃取(19.1)的时候会比较有用(比如,当其不是被作为模板参数传递的时候)
- 一般来说,迭代器就是这么设计的。做为固定萃取
- 萃取参数通常都有很直观的默认参数(很少被重写,或者简单的说是不能被重写)。
- 比如有固定的
某个萃取类::type或某个萃取类::value
- 比如有固定的
- 萃取参数倾向于紧密的依赖于一个或者多个主模板参数。
- 比如19.2,
Traits依赖于T
- 比如19.2,
- 萃取在大多数情况下会将类型和常量结合在一起,而不是成员函数。
- 一般萃取都是采取
typedef/using或static而非成员函数
- 一般萃取都是采取
- 萃取倾向于被汇集在萃取模板中。
- 萃取在被当作固定萃取(19.1)的时候会比较有用(比如,当其不是被作为模板参数传递的时候)
- 策略:
- 策略类如果不是被作为模板参数传递的话,那么其作用会很微弱。
- 比如19.2,我们需要把策略类传入模板参数来确定具体使用的是哪一个Policy
- 策略参数不需要有默认值,它们通常是被显式指定的(虽有有些泛型组件通常会使用默认策略)。
- 策略参数通常是和其它模板参数无关的。
- 比如19.2,策略和
T无关
- 比如19.2,策略和
- 策略类通常会包含成员函数。
- 一般策略都是采用的成员函数而非萃取的
typedef之类。
- 一般策略都是采用的成员函数而非萃取的
- 策略可以被包含在简单类或者类模板中。
- 策略类如果不是被作为模板参数传递的话,那么其作用会很微弱。
- 记住,策略是表达出我们希望依照某种用户提供的规则进行某项操作。所以不一定是像上面的例子那么死板。比如
std::accumulate的第四个参数要求输入一个函数对象。这就是策略。或者是容器类的allocator分配器,也是策略。再比如unordered_set的hash,keyequal,allocator都是策略。还有,unique_ptr的自定义删除器deleter,也是策略。
19.2.2 使用成员函数模板还是模板模板参数?
我们可以像书上那样不使用成员函数模板,转而使用模板模板参数。这样就要求了我们需要调整策略类为类模板(原来是普通类+成员函数模板,现在是模板类)。这样做其实不太好,有点不直观而且麻烦许多。
19.2.3 多个策略和萃取(说白了就是多个模板参数按照什么顺序写)
一般来说,如果这个模板参数越可能使用其默认参数,则越应该靠后。我们可以看到上面的例子中,第一个参数是类型(必须显式指定),第二个是策略类(更有可能替换,但有默认值),第三个是萃取类(不太可能被替换)。
19.3 类型函数(Type Function)
我们在最下面提到了什么叫元函数。其实就是这里的类型函数。在书中是这样定义的:
值函数(value functions):它们接收一些值作为参数并返回一个值作为结果。
类型函数(type functions):它们接收一些类型作为参数并返回一个类型或者常量作为结果
sizeof就是一个经典的内置的类型函数。
19.3.1 元素类型
比如此时我们希望实现一个函数打印某个容器的元素类型。这时候可以通过偏特化实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
template <typename T> //主模板
struct ElementType;
template <typename T>
struct ElementType<vector<T>>{ //针对vector类型的偏特化
using Type = T;
};
template <typename T>
struct ElementType<list<T>>{ //针对list类型的偏特化
using Type = T;
};
template <typename T>
struct ElementType<deque<T>>{ //针对deque类型的偏特化
using Type = T;
};
//.....其他容器类型
template<typename T>
void printType(const T& container){
std::puts(__PRETTY_FUNCTION__);
cout << typeid(typename ElementType<T>::Type).name() << endl; //打印元素类型
}
int main(){
vector<int> vec_a;
vector<bool> vec_b;
deque<char> deq_a;
list<double> list_a;
printType(vec_a);
printType(vec_b);
printType(deq_a);
printType(list_a);
return 0;
};
- 此时是一个不错的实现方式。当然了,如果我们把容器分类为标准库容器(提供了
value_type的容器)和自定义容器,则可以这样实现:
1
2
3
4
5
6
7
8
9
10
template <typename T>
struct ElementType{ //针对提供了value_type或没有写入偏特化的类型的 默认实现
using Type = typename T::value_type;
};
template <>
struct ElementType<myobj>{ //针对myobj类型的特化。
using Type = int;
};
注意,如果某个类型没有value_type的同时我们没有针对其类型定义偏特化萃取类模板,则会出现问题。需要特别注意。
- 我们可能会觉得这样写是脱裤子放屁。然而不是。它允许我们根据容器类型参数化一个模板,但是又不需要提供代表了元素类型和其它特性的参数。比如下面这个函数
1
2
template<typename T, typename C>
T sumOfElements (C const& c);
在这个函数中,我们的返回类型是容器的元素类型。如果此时使用的话,我们必须显式指定T的类型。因为T的类型无法通过函数参数进行推导。
- 所以,针对这样的情况,我们可以换成这样的模板:
1
2
template<typename C>
typename ElementType<C>::Type sumOfElements (C const& c);
这个时候我们就不必显式指定返回类型。因为可以通过萃取类模板进行推导,通过类型函数得到。
在上面的情况下,ElementType被称之为萃取类。因为它是用来获取一个已有容器类型的萃取。因此我们发现萃取类的功能并不局限于描述容器参数的特性,而是可以描述任意主参数T的特性
- 如果想更方便一点,可以使用别名模板。
1
2
3
4
5
6
7
template<typename T>
using a_ElementType = typename ElementType<T>::Type; //别名模板
template<typename C>
a_ElementType<C> sumOfElements (C const& c){
cout <<"called" << endl;
}
19.3.2 转换萃取(Transformation Traits)
在刚才的一节中,我们主要使用萃取的“抽取”特性。也就是访问主参数的某些特性。在这一节中,我们会使用萃取的“转换”特性。比如添加或移除引用,CV限定等。
删除引用
- 删除引用是比较常见的萃取操作。比如标准库的
remove_reference。其具体实现已经在下面介绍了。此处不赘述。
添加引用
- 对于添加引用,标准库提供的是
add_rvalue_reference和add_lvalue_reference。注意我们在11.2.1中提到的。add_rvalue_reference会施加引用折叠。一定要格外注意。
移除CV限定
- 对于这一系列操作,标准库提供了
remove_cv/remove_volatile/remove_const
退化
- 对于退化操作,标准库提供了
decay。其模拟实现可以在书中的这一节简单了解。
19.3.3 预测型萃取(Predicate Traits) — 也就是类型预测(判断)
我们之前所提到的萃取类型都是针对单个模板参数的。我们针对该模板参数进行修改或提炼。有些时候我们会针对多个模板参数进行萃取。这种就叫做类型预测。也就是一个返回true或false的类型函数。
经典的预测型萃取有比如is_same等。尤为注意在预测型萃取中,我们会返回一个bool值。为了支持标记派发,产生bool的萃取实现都应该通过std::true_type和std::false_type的类型进行继承。
19.3.4 针对返回结果类型进行萃取(Result Type Traits)
假设我们有一个需求,是对两个vector求和的函数模板。我们的第一个版本可能会长成这个样子:
1
2
template<typename T>
vector<T> add(const vector&<T> vec1, const vector<T>& vec2);
但是我们可能会允许两个不同类型的vector相加。但是我们如何处理返回值呢?
这个时候可以使用返回值类型模板:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class wtf{
public:
int val;
wtf() = default;
wtf(int x):val(x){};
wtf operator+(const wtf& rhs) const{ //细节1
cout <<"wtf+" << endl;
return wtf(val + rhs.val);
}
};
template<typename T1, typename T2>
struct VecPlusTrait{ //返回值类型萃取
using Type = decltype(T1() + T2()); //细节2
};
template<typename T1, typename T2>
vector<typename VecPlusTrait<T1, T2>::Type> operator+(const vector<T1>& vec1, const vector<T2>& vec2 ){
if(vec1.size() != vec2.size()){
return {};
}
vector<typename VecPlusTrait<T1, T2>::Type> myvec;
myvec.reserve(vec1.size());
for(int i = 0; i < vec1.size(); i++){
myvec.emplace_back(vec1[i] + vec2[i]);
}
return myvec;
}
int main(){
vector<wtf> vec1{1,2,3,4,5,6,7};
vector<wtf> vec2{2,3,4,5,6,7,8};
auto ret = vec1+vec2;
for(auto& i:ret){
cout <<i.val << endl;
}
return 0;
};
- 这里细节较多。
- 第一个细节:
wtf的operator+必须加const。原因是下面调用wtf的operator+的时候,我们入参的容器是常量引用接受的。此时从容器中提出来的元素也是常量引用。此时常量引用不能调用wtf的非常量成员函数。会报错。 第二个细节:此处我们使用的
decltype要记住传入的是表达式。类型+()等于创建匿名对象,然后调用其对应类型的operator+然后判断表达式的返回值。- 但是这里有个问题,如果
wtf的operator+返回的是一个引用呢?或者更为常见的例子是它返回的是一个const wtf,这样就出问题了。容器不能储存引用也不能储存常量。那么这时候不要忘记使用decay,像这样
1
2
3
4
5
6
7
8
9
10
11
12
template<typename T1, typename T2>
vector<typename std::decay<typename VecPlusTrait<T1, T2>::Type>::type> operator+(const vector<T1>& vec1, const vector<T2>& vec2 ){ //使用decay
if(vec1.size() != vec2.size()){
return {};
}
vector<typename std::decay<typename VecPlusTrait<T1, T2>::Type>::type> myvec; /使用decay
myvec.reserve(vec1.size());
for(int i = 0; i < vec1.size(); i++){
myvec.emplace_back(vec1[i] + vec2[i]);
}
return myvec;
}
- 这里还有第二个问题,我们用的
decltype要求T1和T2类型必须可以构造临时对象(有并且可以访问默认构造)。但是我们并不一定非得要让这两个类拥有默认构造,所以这时候可以用declval
1
2
3
4
template<typename T1, typename T2>
struct VecPlusTrait{
using Type = decltype(declval<T1>() + declval<T2>());
};
19.4 基于SFINAE的萃取
我们在8.4和void_t中介绍了SFINAE和其做为排除某些重载函数或排除某些偏特化的技巧。这里再聊聊。
19.4.1 使用SFINAE排除某些重载函数
比如我们想模仿标准库写一个简单的is_default_constructible
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template<typename T>
struct ChectIsDefaultConstructible{
private:
template<typename U, typename = decltype(U())> //细节1
static char check(void*); //细节2
template<typename>
static int check(...); //细节3
public:
static constexpr bool value = is_same<decltype(check<T>(nullptr)), char>::value; //细节4
};
int main() {
cout <<std::boolalpha;
cout << ChectIsDefaultConstructible<myclass>::value << endl;
return 0;
}
核心原理就是利用函数重载。如果类型T是可默认构造的,那么T()是合法表达式。如果T()不合法,该选择会被丢弃,转而匹配万能匹配的第二个函数。至于具体返回值,仅是当做标签使用。细节4当中就是判断其重载后函数的返回值是否是我们期待的。
- 首先第一个细节,我们没有使用
T而是使用U。原因是我们在细节4当中把T做为函数的U传了进去。如果直接使用T像这样:template<typename, typename = decltype(T())>。因为类模板在实例化的时候会直接把所有的T换成传入的类型。如果传入的类型不可默认构造,则会出现意外的结果。比如我们这里使用了一个已删除的默认构造函数(如果传入的类型是不可默认构造的)。虽然g++不会报错(clang会报错),但是结果是错的。 - 第二个细节和第三个细节是使用static是为了可以不通过对象调用。同时函数入参必须有区别。为了不麻烦,我们传入空指针。
- 细节三是
...可以接受任意类型和数量的参数。因为函数不能仅通过返回值重载。 - 细节四是因为静态不能类内初始化。除非是静态
constexpr对象。
19.4.2 使用SFINAE排除偏特化
- 还记得我们在
void_t章节详细讲述的它和SFINAE的关系吗?这里又来啦。还是19.4.1的例子,判断是否可以默认构造。但是我们从依靠函数重载做决定变成了依靠偏特化做决定。
1
2
3
4
5
6
7
8
9
10
template<typename T, typename = void> //原因不解释了。都在void_t章节
struct ChectIsDefaultConstructible : false_type{}; //主模板默认是false_type
template<typename T>
struct ChectIsDefaultConstructible<T, void_t<decltype(T())>> : true_type{};
int main() {
cout <<std::boolalpha;
cout << ChectIsDefaultConstructible<myclass>::value << endl;
return 0;
}
是不是感觉明显比使用函数重载的清爽了很多?但是19.4.1依靠函数重载的实现可以允许我们使用额外的辅助函数或辅助类。此处依靠偏特化的则要求我们必须能把条件放入模板参数的声明中。
19.4.4 SFINAE友好的萃取。注意什么是立即语境。
SFINAE并不能永远保护我们。如果错误发生在非立即语境,则会出现问题。比如我们19.3.4写的VecPlusTrait萃取,当我们的两个传入参数并不能相加的时候就不会发生SFINAE,而是一个硬错误。
立即语境(立即上下文)
下面的俩链接过于抽象。什么是立即语境?
直接上下文基本上是模板声明(包括模板参数列表、函数返回类型和函数参数列表)。
只有函数类型、其模板参数类型及其显式说明符的直接上下文中的无效类型和表达式才会导致推导失败。SFINAE
在推断或者替换一个备选函数模板的时候,任何发生在类模板定义的实例化过程中的事情都不是函数模板替换的立即上下文
只有在函数类型或其模板形参类型的立即语境中的类型与表达式中的失败是 SFINAE 错误。如果对替换后的类型/表达式的求值导致副作用,例如实例化某模板特化、生成某隐式定义的成员函数等,那么这些副作用中的错误被当做硬错误。
通俗解释就是,我们调用函数的时候首先要实例化,如果实例化阶段就非法,那是硬错误。因为没到SFINAE阶段。所以这不是立即语境。
如果实例化阶段结束,到了重载阶段,这个阶段发生的错误可以被SFINAE掉。这是立即语境。
当你发现模板声明中的东西可以直接确定的时候,这就是立即语境。当你发现模板声明中的东西不能直接确定,而是需要再实例化一个别的模板,那么这个实例化一个别的模板的过程中就不是立即语境。
或者是理解为模板只管替换本身成不成功,不管其他的。如果模板本身替换失败,则触发sfinae
如果不是立即语境,那么在非立即语境中的错误都是硬错误。
https://stackoverflow.com/questions/15260685/what-exactly-is-the-immediate-context-mentioned-in-the-c11-standard-for-whic
https://www.cppstories.com/2022/sfinea-immediate-context/
回到例子中来。假设我们单独为某两个没有相加操作的类的数组提供一个单独的相加函数:
1
2
3
4
vector<noaddA> operator+(vector<noaddA>& a, vector<noaddB>& b){
cout << "called" << endl;
return{};
}
还是会出现问题。因为程序无法判断是这个单独为noaddA和noaddB准备的更好还是模板的更好。然后会尝试实例化。但是实例化中又会遇到noaddA没有和noaddB相加的操作的问题。因为我们有一个萃取的decltype操作。在两个operator+中,返回值的萃取操作涉及到了额外的模板实例化,所以这部分不是立即语境,如果此时decltype的表达式无效,则会立即报错。
既然如此,那么我们就需要改一下。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
template<typename, typename, typename = void> //void_t章节介绍。此处不介绍更多了。
struct HasPlusFunction: false_type{}; //判断类型是否有内置的相加操作。
template<typename T1, typename T2>
struct HasPlusFunction<T1, T2, void_t<decltype(declval<T1>() + declval<T2>())>> : true_type{}; //如果有相加的函数,则没问题。细节1
class wtf{
public:
int val;
wtf() = default;
wtf(int x):val(x){};
wtf operator+(const wtf& rhs) const{ //细节1
cout <<"wtf+" << endl;
return wtf(val + rhs.val);
}
};
class noaddA{
public:
int val;
noaddA() = default;
noaddA(int x):val(x){};
};
class noaddB{
public:
int val;
noaddB() = default;
noaddB(int x):val(x){};
};
template<typename T1, typename T2, bool = HasPlusFunction<T1, T2>::value>
struct VecPlusTrait{ //第二次萃取,细节2
using Type = decltype(declval<T1>() + declval<T2>());
};
template<typename T1, typename T2>
struct VecPlusTrait<T1, T2, false>{}; //针对没有内置相加操作的类型的偏特化。
template<typename T1, typename T2>
vector<typename std::decay<typename VecPlusTrait<T1, T2>::Type>::type> operator+(const vector<T1>& vec1, const vector<T2>& vec2 ){
if(vec1.size() != vec2.size()){
return {};
}
vector<typename std::decay<typename VecPlusTrait<T1, T2>::Type>::type> myvec;
myvec.reserve(vec1.size());
for(int i = 0; i < vec1.size(); i++){
myvec.emplace_back(vec1[i] + vec2[i]);
}
return myvec;
}
vector<noaddA> operator+(vector<noaddA>& a, vector<noaddB>& b){
cout << "called" << endl;
return{};
}
int main(){
vector<wtf> vec1{1,2,3,4,5,6,7};
vector<int> vec2{2,3,4,5,6,7,8};
auto ret = vec1+vec2;
for(auto& i:ret){
cout <<i.val << endl;
}
vector<noaddA> vec3{1,2,3,4,5,6,7};
vector<noaddB> vec4{2,3,4,5,6,7,8};
auto ret2 = vec3+vec4;
return 0;
};
- 既然在两个
operator+中我们涉及到了额外的模板实例化操作,那么我们再次增加一层。注意我们的VecPlusTrait有了第三个参数。这个参数涉及到了HasPlusFunction的实例化。我们通过HasPlusFunction可以判断一个类型是否有内置的加法操作。这里可以正确SFINAE掉。因为它发生在HasPlusFunction的里面。这个里面是立即语境。因为针对HasPlusFunction的选择操作没有额外的模板介入。 - 随后,我们会获取到
true或false。如果是true,则decltype不会出现问题。因为合法。如果是false则会直接返回。不会经过decltype语句。 - 因为我们是在两个
operator+中进行抉择,如果刚才的返回是false,则这时候我们的模板operator+会被SFINAE掉。因为只有萃取部分不是立即语境(对替换后的类型的实例化某些模板特化中的错误被当做硬错误。理解为进入了另一个实例化的模板中)。但是这时候脱离了萃取部分,仅仅是两个operator+中选择的话,是立即语境。所以就会去专门选择noaddA和noaddB指定的operator+重载版本。 - 注意,如果我们的相加操作的类型同时内置支持相加,并且也写出了单独的版本,此时会选择单独版本。因为两者重载决议中显然会选择非模板函数。
- 我们在1.5和重载决议中提到:重载决议只看声明,不看定义。但是我们的萃取,
decltype之类的都在声明里。所以它依旧会去进行计算。
- 我们在1.5和重载决议中提到:重载决议只看声明,不看定义。但是我们的萃取,
19.5 简单实现is_convertible
我们在下面介绍了is_convertible的用法。这里尝试进行一个简单实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
template <typename From, typename To>
struct IsConvertible{
private:
static void try_call(To); //细节1
template<typename>
static std::false_type check(...); //细节2
template<typename F, typename = decltype(try_call(declval<F>()))> //细节3
static std::true_type check(void*);
public:
using Type = decltype(check<From>(nullptr)); //细节4
};
template <typename From, typename To>
struct IsConvertibleValue:IsConvertible<From, To>::Type{}; //细节5
int main(){
cout << std::boolalpha;
cout << is_convertible<int, string>::value << endl;
cout << IsConvertibleValue<int, string>::value << endl;
cout << is_convertible<string, int>::value << endl;
cout << IsConvertibleValue<string, int>::value << endl;
cout << is_convertible<double, int>::value << endl;
cout << IsConvertibleValue<double, int>::value << endl;
cout << is_convertible<int, double>::value << endl;
cout << IsConvertibleValue<int, double>::value << endl;
}
- 首先,所有成员函数都要是
static为了可以直接调用。 - 第一个细节。这个函数的目的是使用细节3中的
decltype检查From类型参数能否放入To类型的形参。如果合法证明可以convert。不合法证明不可以。会被丢弃。转而匹配细节2的万能fallback方案。 - 第二个细节。
...匹配任意数量任意类型的参数。做为fallback方案 - 第三个细节。我们采用
declval避免创建临时对象。然后传入try_call后使用decltype判断是否合法。 - 第四个细节。显式指定模板函数
check的形参F的类型是From。然后传入一个参数。最后使用decltype判断是false_type还是true_type。- 注意必须有
F,如果直接写declval<From>则会在实例化阶段报错。
- 注意必须有
- 第五个细节。
IsConvertibleValue将会继承自计算后的IsConvertible的type类型。也就是要么继承自false_type要么继承自true_type。
特殊情况
上面的代码无法处理以下三种情况:
- 向数组类型的转换要始终返回
false,但是在上面的代码中,try_call()声明中的类型为To的参数会退化成指针类型,因此对于某些From类型,它会返回true。 - 向指针类型的转换也应该始终返回
false,但是和 1 中的情况一样,上述实现只会将它们当作退化后的类型。 - 向(被
const/volatile修饰)的void类型的转换需要返回true。但是不幸的是,在To是void的时候,上述实现甚至不能被正确实例化,因为参数类型不能包含void类型(而且try_call()的定义也用到了这一参数)。
解决这个问题可以引入额外模板参数,使用is_array, is_function和is_void(注意不是void_t)来进行判断。
19.6 探测(检查)成员
19.6.1 检查类型成员 (Detect Member Type)
查看void_t章节。但是这里额外增加一点注意事项。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
struct A {
using mytype = int; //类A含有mytype类型
};
struct B{
using mytype = void; //类B也含有mytype类型
};
template<typename T1 , typename T2 = void > //主模板,第二个参数默认值是void,非常重要
struct has_type_member : std::false_type { //主模板继承false_type
};
template<typename T1> //针对第二个参数进行偏特化
struct has_type_member<T1, std::void_t<typename T1::mytype>>: std::true_type { //偏特化继承true_type,并且使用void_t进行类型判断。
};
int main(){
auto a = has_type_member<A>::value;
auto b = has_type_member<B>::value;
cout << a << endl;
cout << b << endl;
auto c = has_type_member<A&>::value; //注意这两个
auto d = has_type_member<B&>::value; //注意这两个
cout << c << endl;
cout << d << endl;
}
- 比如上面代码。如果正常传入一个类型本身没什么问题。但是我们如果传入引用就会出现问题。因为引用类型确实没有成员。引用类型和其本身类型并不是同一种类型。但是我们可能会希望,当我们传递进来的模板参数是引用类型的时候,依然根据其指向的类型做判断。为了这一目的,我们可以使用
remove_reference进行辅助。
1
2
3
4
5
6
7
template<typename T1 , typename T2 = void >
struct has_type_member : std::false_type {
};
template<typename T1> //针对第二个参数进行偏特化
struct has_type_member<T1, std::void_t<typename remove_reference<T1>::type::mytype>>: std::true_type { //偏特化继承true_type,并且使用void_t进行类型判断。
};
注入类的名字 (injected-class-name)杂记4中提过。
- 注入类名是在类的作用域内该类自身的名字。
- 在类作用域中,当前类的名字被当做它如同是一个公开成员名一样;这被称为注入类名(injected-class-name)。该名字的声明点紧跟类定义的开花括号之后。
- 与其他成员类似,注入类名可被继承,但是依旧受可见性制约。在私有或受保护继承的场合,可能导致某个间接基类的注入类名在派生类中最后变得不可访问。
- 所以我们的萃取代码,可以检测注入类的名字。换句话说,就是检测是否继承自某个特定类。
- 这里仍然受到可见性限制,也就是私有继承会返回
false
- 这里仍然受到可见性限制,也就是私有继承会返回
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
struct A{
};
struct B:public A{
};
struct C:private B{
};
int main(){
auto a = has_type_member<A>::value;
auto b = has_type_member<B>::value;
auto c = has_type_member<C>::value;
cout << a << endl; //true
cout << b << endl; //true
cout << c << endl; //false
}
19.6.2 检查任意类型成员。
目前只能通过宏来实现这一操作。##的作用在杂记4
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#define DEFINE_HAS_TYPE(MemType)\
template<typename, typename = void>\
struct HasTypeT_##MemType : std::false_type{};\
template<typename T>\
struct HasTypeT_##MemType<T, std::void_t<typename T::MemType>> : std::true_type{} // 注意没有分号!
struct A{
using mytype = int;
};
struct B{
using anothertype = float;
};
DEFINE_HAS_TYPE(mytype); //我们上面故意去掉的分号原因是这里是那个分号。
DEFINE_HAS_TYPE(anothertype);
int main(){
cout << boolalpha;
cout << HasTypeT_mytype<A>::value << endl;
cout << HasTypeT_mytype<B>::value << endl;
cout << HasTypeT_anothertype<A>::value << endl;
cout << HasTypeT_anothertype<B>::value << endl;
}
- 由于我们传入的变量叫做
MemType。所以我们传入mytype的时候,HasTypeT_##MemType会变成HasTypeT_mytype。其他的同理。
19.6.3 检查非类型成员
void_t中介绍了。稍微补充一下。
针对数据成员,也可以使用检查成员函数的第二种方式:<取成员地址>是否合法来判断。
但是:
- 成员名字,也就是
&T::Member中的Member名字不能有歧义。比如不能是重载,不能是多继承中的同名成员。 - 必须可以访问。
- 必须是非类型和非枚举成员,否则
&无效。 - 如果是
static静态成员,则对应类型必须提供有效的operator&,如果无效,如设置operator&为私有则无效。
19.6.4 检查其他表达式 (比如是否有特定操作,如大于小于)
这种基于偏特化的SFINAE可以应用在很多方面,包括其他表达式。也可以把多个条件放在一起(都放在void_t里面,只要一个条件无效就整个偏特化丢弃。)比如我们下面的例子是探测两个类型T1和T2是否有小于操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
struct A {
};
struct B{
bool operator <(A o1){ //B和A的小于操作
}
};
bool operator <(int, A o1){ //int和A的小于操作
}
template<typename T1 , typename T2, typename = void >
struct has_less_operation:std::false_type {
};
template<typename T1, typename T2>
struct has_less_operation<T1, T2, std::void_t<decltype(declval<T1>() < declval<T2>())>>: std::true_type { //判断是否有小于操作
};
int main(){
cout <<std::boolalpha;
cout << has_less_operation<int, int>::value << endl;
cout << has_less_operation<string, string>::value << endl;
cout << has_less_operation<B, A>::value << endl;
cout << has_less_operation<int, A>::value << endl;
cout << has_less_operation<string, int>::value << endl;
cout << has_less_operation<A, B>::value << endl;
/*
输出
true
true
true
true
false
false
*/
}
采用这种方式探测表达式有效性的萃取是很稳健的:如果表达式没有问题,它会返回 true,而如果<运算符有歧义,被删除,或者不可访问的话,它也可以准确的返回 false。
19.7 其他的萃取技术
19.7.1 If-then-Else
个人理解这个的用处非常像enable_if。但我们提到了,enable_if不能用于类模板。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template<bool cond, typename TypeIfTrue, typename TypeIfFalse>
struct IfthenElse{
using Type = TypeIfFalse;
};
template<typename TypeIfTrue, typename TypeIfFalse>
struct IfthenElse<true, TypeIfTrue, TypeIfFalse>{
using Type = TypeIfTrue;
};
int main() {
IfthenElse<(sizeof(int) >= 4), int, double>::Type a;
cout << boolalpha;
cout << is_same<int, decltype(a)>::value << endl; //true
}
核心目的是如果表达式
cond是true,则让type是truetype。反之亦然。标准库提供的是
std::conditional
19.7.2 检查操作是否抛出异常
- 我们在杂记4中介绍了
noexcept可以是运算符,也就是后面可以跟随一个表达式。这样做可以通过表达式结果是true或false来声明函数是否是noexcept。 - 这种形式比较经典的应用在了
vector的移动构造函数中。如果元素的移动构造不能保证noexcept,就不会调用移动构造而是调用拷贝构造。
我们也用我们的方式来实现一下。
- 准备一个针对
true_type和false_type的类型萃取。这一步的目的是可以在某个类型没有移动或构造函数的时候仍旧可以SFINAE。- 没有移动或构造函数,则
T1(declval<T1>())无效
- 没有移动或构造函数,则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<bool check = false> //默认是false
struct bool_extraction{
using value = false_type;
void func(){
cout <<"false" << endl;
}
};
template<>
struct bool_extraction<true>{ //true的偏特化。
using value = true_type;
void func(){
cout <<"true" << endl;
}
};
第一个版本:使用基于默认类型的SFINAE。
1
2
3
4
5
6
7
8
9
template<typename T1, typename = true_type> //必须是true_type
struct Is_Nothrow_Move_Constructible : std::false_type{
};
template<typename T1>
struct Is_Nothrow_Move_Constructible<T1, typename bool_extraction<noexcept(T1(declval<T1>()))>::value> : std::true_type{
};
如果
noexcept(T1(declval<T1>())表达式无效,则会匹配至bool_extraction的主模板。为什么
Is_Nothrow_Move_Constructible默认值必须是truetype?- 原理和
void_t基本差不多。 - 如果是
false_type,假如T1的拷贝构造或移动构造是非noexcept,则类型会被推导为<T1, false_type>。此时由于下面的比上面的更特化。导致继承了下面的,导致value是true_type。如果是noexcept,则类型会被推导为<T1, true_type>。但是我们的默认值是false_type则相当于指定<T1, false_type>为模板实参。此时模板实参和推导的模板实参不匹配,第二个版本会被丢弃。主模板可以匹配,则回退至主模板。继承了false_type。 - 所以我们看到,如果默认值是
false_type,则结果会完全相反。
- 原理和
第二个版本:使用基于void_t的SFINAE
1
2
3
4
5
6
7
8
template<typename T1, typename = void>
struct Is_Nothrow_Move_ConstructibleV2 : std::false_type{
};
template<typename T1>
struct Is_Nothrow_Move_ConstructibleV2<T1, void_t<decltype(T1(declval<T1>()))>> : bool_extraction<noexcept(T1(declval<T1>()))>::value{
};
- 说实话,我真的没感觉出来有什么具体的差别。但是在看到第一个版本默认值类型的坑后,我觉得第二个版本更加人道一些。更少的magic。
测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
struct A { //无拷贝构造和移动构造
A(){}
A(const A&) = delete;
A(A&&) = delete;
};
struct B{ //有拷贝构造和移动构造且都为noexcept
B(){}
B(const B&) noexcept{}
B(B&&) noexcept{}
};
struct C{ //有拷贝构造和移动构造且都无noexcept
C(){}
C(const C&){}
C(C&&){}
};
struct D{ //有拷贝构造和移动构造且只有拷贝构造为noexcept
D(){}
D(const D&) noexcept{}
D(D&&){}
};
cout <<"A test:" << endl;
cout << is_nothrow_move_constructible<A>::value << endl; //false
cout << Is_Nothrow_Move_Constructible<A>::value << endl;
cout << Is_Nothrow_Move_ConstructibleV2<A>::value << endl;
cout <<"B test:" << endl;
cout << is_nothrow_move_constructible<B>::value << endl; //true
cout << Is_Nothrow_Move_Constructible<B>::value << endl;
cout << Is_Nothrow_Move_ConstructibleV2<B>::value << endl;
cout <<"C test:" << endl;
cout << is_nothrow_move_constructible<C>::value << endl; //false
cout << Is_Nothrow_Move_Constructible<C>::value << endl;
cout << Is_Nothrow_Move_ConstructibleV2<C>::value << endl;
cout <<"D test:" << endl;
cout << is_nothrow_move_constructible<D>::value << endl; //false
cout << Is_Nothrow_Move_Constructible<D>::value << endl;
cout << Is_Nothrow_Move_ConstructibleV2<D>::value << endl;
cout <<"int test:" << endl;
cout << is_nothrow_move_constructible<int>::value << endl; //true
cout << Is_Nothrow_Move_Constructible<int>::value << endl;
cout << Is_Nothrow_Move_ConstructibleV2<int>::value << endl;
cout <<"string test:" << endl;
cout << is_nothrow_move_constructible<string>::value << endl; //true
cout << Is_Nothrow_Move_Constructible<string>::value << endl;
cout << Is_Nothrow_Move_ConstructibleV2<string>::value << endl;
- 需要详细说明几个问题。我们可以理解移动是特殊的拷贝操作。所以如果
- 同时拥有拷贝构造和移动构造。只移动构造为
noexcept,则是true。 - 同时拥有拷贝构造和移动构造。只拷贝构造为
noexcept,则是false。 - 提供拷贝构造,不声明且不提供(不是
=delete)移动构造,且拷贝构造是noexcept,则是true。- 原因是编译器虽然压根不隐式生成移动构造,但不会标记为弃置。
- 提供拷贝构造,但是声明移动构造为弃置(
=delete),就算拷贝构造是noexcept,也是false。- 由于我们使用了
declval。declval是强制转换为右值引用。 - 因为这是
=delete的意义。我们已经通过declval转换为右值引用了。然后进行构造函数匹配的时候检测到移动构造这个签名最为匹配,但是是delete,就不应该继续选择次级匹配的。而是提示使用了不该用的东西。
- 由于我们使用了
- 同时拥有拷贝构造和移动构造。只移动构造为
坑点 - 为什么必须要用declval?
为什么必须用declval,不就是少构造一个么?
原因不仅是避免构造,旁通掉构造函数被删除或不可用的情况,更是因为它可以旁通掉构造函数为非noexcept的情况。
假设有如下代码:
1
2
3
4
5
6
7
8
9
10
struct B{
B(){}
B(const B&) noexcept{
}
B(B&&) noexcept{
}
};
cout << noexcept(B(declval<B>())) << endl; //true
cout << noexcept(B(B())) << endl; //false
为啥有区别?
declval不要求构建对象。所以构造函数不参与。直接换成B&&。B(B&&)自然匹配noexcept的移动构造。返回true。- 非
declval要求构建对象。有构造函数参与。但是构造函数为非noexcept。最终结果自然是非noexcept。返回false。
19.8 类型分类
19.8.1 检测基本类型
检测基本类型我们可以使用标准库的std::is_fundamental或std::intergral进行检测。具体的原理其实就是写一堆偏特化。
19.8.2 检测复合类型
指针
检测指针类型我们可以使用标准库的std::is_pointer。具体原理也是偏特化。
引用
检测引用类型我们可以使用标准库的std::is_lvalue_reference 和 std::is_rvalue_reference。具体原理还是偏特化。
数组
检测数组类型我们可以使用标准库的std::is_array。具体原理依旧是偏特化。
指向成员的指针
针对这个类型可以使用std::is_member_pointer, std::is_member_object_pointer和std::is_member_function_pointer。原理是偏特化和提到的函数类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
template<typename T>
struct IsPointerToMemberT : std::false_type {
};
template<typename T, typename C>
struct IsPointerToMemberT<T C::*> : std::true_type { //也可以写为<T(C::*)>。之前函数类型的那种必须加括号是因为语法限制。
using MemberT = T;
using ClassT = C;
};
class cls {};
int main() {
cout << (IsPointerToMemberT<int cls::*>::value //也可以写为<int(cls::*)>。之前函数类型的那种必须加括号是因为语法限制
? "T is member pointer"
: "T is not a member pointer") << '\n';
cout << (IsPointerToMemberT<int>::value
? "T is member pointer"
: "T is not a member pointer") << '\n';
}
- 注意带括号和不带括号的写法在这里是一个意思。
19.8.3 检测函数类型
针对函数类型我们可以使用标准库的std::is_function()。具体细节就是一堆偏特化。
值的注意的是,这个东西的实现中,偏特化的数量非常多。一是因为会有任意多的参数,需要用可变参数。其次就是需要处理CV限定。
19.8.4 检测类类型
这个就比较有意思了。因为我们不能专门偏特化或枚举某个未知类型。但是我们可以利用一个技巧:
- 表达式
X Y::*只有在Y是类类型的时候才合法。- 注意,我们只利用声明判断。所以
X具体是什么类型我们不关心。随意选一个就好。
- 注意,我们只利用声明判断。所以
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
template<typename T, typename = void>
struct IsClassT : std::false_type {
};
template<typename T>
struct IsClassT<T, void_t<char T::*>> : std::true_type { //这里char是随便选的。而且依旧加括号不加括号都可以。
};
int main() {
cout << std::boolalpha;
cout << IsClassT<int>::value << endl; //False
cout << IsClassT<myobj>::value << endl; //True
cout << IsClassT<myobj&>::value << endl; //False
cout << IsClassT<myobj*>::value << endl; //False
}
- 标准库中提供了
std::is_class和std::is_union
19.8.5 检测枚举类型
- 标准库提供了
std::is_enum。最基础的原理是检查一个类型是否是基础类型,指针类型,引用类型,数组类型,成员指针类型,函数类型和类类型。都不是的话就是枚举类型。
19.9 策略特征
我们在19.2详细探讨了策略和萃取的区别。但是我们在那一章节提到的是策略类而非策略特征。
- 策略类通常独立于其他模板参数。
- 策略特征通常是与模板参数相关联的唯一属性。
19.9.1 利用if-then-else 处理只读参数类型
我们在19.7.1谈到了if-then-else可以看做是一种enable_if。具体的用法之一就是判断传入参数的类型应该是值还是引用。
- 假设我们打算针对小于两个指针大小的数据类型采用值传递,大于两个指针大小的数据采用常量左值引用传递:
- 尽管这么做不一定正确。因为对象的拷贝或移动成本不一定和对象的体积成正相关。比如一个10个
int的类和一个两个指针但是每一个指针都持有一个大型资源的类。或者是本身就不大的容器类。针对这些情况我们可以进行特化和偏特化处理
- 尽管这么做不一定正确。因为对象的拷贝或移动成本不一定和对象的体积成正相关。比如一个10个
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
//IfthenElse查看19.7.1
template<typename T>
struct PassByWhat{
using Type = typename IfthenElse<sizeof(T) <= 2*sizeof(void*), T, const T&>::Type; //如果小于两个指针大小就是T,否则就是const T&
void func(){
std::puts(__PRETTY_FUNCTION__);
cout <<"normal" << endl;
}
};
template<typename T>
struct PassByWhat<vector<T>>{ //举个例子。针对vector类型的特化。如果下面传入的是vector<T>如vector<int>则会正确匹配到这里。不要惊讶。
using Type = const vector<T>&;
void func(){
std::puts(__PRETTY_FUNCTION__);
cout <<"vector" << endl;
}
};
template<typename T1, typename T2>
void testfunc(typename PassByWhat<T1>::Type p1, typename PassByWhat<T2>::Type p2){
std::puts(__PRETTY_FUNCTION__);
}
int main() {
myobj obj;
testclass2 testobj;
testfunc<myobj, testclass2>(obj, testobj);
}
/*
myobj const
testclass2 const
myobj copy const
void testfunc(typename PassByWhat<T1>::Type, typename PassByWhat<T2>::Type) \
[with T1 = myobj; T2 = testclass2; typename PassByWhat<T1>::Type = myobj; typename PassByWhat<T2>::Type = const testclass2&]
myobj dest
testclass2 dest
myobj dest
*/
- 针对
vector<T>类型的偏特化可以正确匹配:
1
2
3
4
5
6
PassByWhat<vector<int>> check;
check.func();
/*
void PassByWhat<std::vector<_Tp> >::func() [with T = int]
vector
*/
这么做有缺点。第一个缺点是函数声明乱,很复杂。第二个缺点是此时无法使用函数模板的参数推导。因为模板参数只出现在函数参数的限定符中,并不是函数参数的本身。这里是不推导语境。
用有限定标识指定的类型的 嵌套名说明符(作用域解析运算符
::左侧的所有内容)我们看到我们函数签名的所有的模板形参均在作用域解析运算符左侧。
- 可以配合与一个包装函数模板,提供完美转发服务。
第二十章 类型属性上的重载
我们知道,函数模板可以重载。类模板不可以。我们将要讨论如何实现这一类似行为
20.1 算法特化(重载)
这个部分非常直观。就是为某一个特定类型提供一个更为特化的算法实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template<typename T>
void swap(T a, T b){
cout <<"T swap" << endl;
}
template<typename T>
void swap(vector<T> a, vector<T> b){ //针对vector类型提供的特化版本。
cout <<"vector T swap" << endl;
}
int main(){
vector<int> a{1,2,3,4};
swap(1,2);
swap(a, a);
return 0;
}
- 但是不是所有的场合都能成功实现这一操作。
1
2
3
4
5
6
7
8
template<typename InputIter>
void swap(InputIter a, InputIter b){
cout <<"InputIter swap" << endl;
}
template<typename RandomAccessIter>
void swap(RandomAccessIter a, RandomAccessIter b){
cout <<"RandomAccessIter swap" << endl;
}
由于只有函数模板形参名字不同的函数模板不可以被重载,所以会有重定义问题。这时候我们可以使用标记派发。
20.2 标记派发/标记分派(tag dispatching)
可以同时参阅effective modern C++ 条款27 - 3
我们发现上一节中提到的例子,核心是只有函数模板形参名字不同的函数模板不可以被重载。那么我们可以让这个名字成为模板形参的一部分。也就是打标签。
- 下面的
tag其实就是传入一个对应特定类型的匿名对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
//这部分迭代器分类套用标准库的一套。
struct my_input_iterator_tag {};
struct my_output_iterator_tag {};
struct my_forward_iterator_tag : public my_input_iterator_tag {};
struct my_bidirectional_iterator_tag : public my_forward_iterator_tag{};
struct my_random_access_iterator_tag : public my_bidirectional_iterator_tag {};
//这部分模拟某一种迭代器。
struct my_InputIter{
using IterType = my_input_iterator_tag; //迭代器里面有一个成员类型指明自己是哪一个迭代器类别。
};
struct my_RandomAccessIter{
using IterType = my_random_access_iterator_tag;
};
//迭代器类型萃取
template <typename Iter>
struct IterTraits{
using IterType = typename Iter::IterType; //获取当前传入的迭代器的迭代器类别
};
template<typename Iterator>
void my_swapImpl(Iterator& x, Iterator& y){ //作为标签分派的转发函数。
my_swap(x, y, typename IterTraits<Iterator>::IterType()); //细节注意,使用typename指明是类型后,使用()生成对应类型的匿名对象。
//因为我们下面的标签是函数参数,需要一个对象。
}
template<typename InputIter> //对应的具体swap函数。
void my_swap(InputIter& a, InputIter& b, my_input_iterator_tag){ //第三个参数是tag。tag也是对象。
cout <<"InputIter swap" << endl;
}
template<typename RandomAccessIter>
void my_swap(RandomAccessIter& a, RandomAccessIter& b, my_random_access_iterator_tag){
cout <<"RandomAccessIter swap" << endl;
}
int main(){
my_RandomAccessIter r1;
my_RandomAccessIter r2;
my_InputIter i1;
my_InputIter i2;
my_swapImpl(r1, r2);
my_swapImpl(i1, i2);
return 0;
}
- 标记派发非常适合用于有天然层次结构,并且拥有对应的萃取机制的情况。但是如果要依赖于专有类型属性的时候,比如某个类型是否有拷贝赋值,标记派发就不太方便了。
标签分派的实现可以有特化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
struct a{};
struct b{};
struct c{};
template<typename T>
struct Test{
static const int num = 0;
};
template<>
struct Test<a>{
static const int num = 1;
};
template<>
struct Test<b>{
static const int num = 2;
};
template<>
struct Test<c>{
static const int num = 3;
};
int main(){
cout << Test<a>::num << endl; // 1
cout << Test<b>::num << endl; // 2
cout << Test<c>::num << endl; // 3
}
这种可以让你给某一个类型的标签进行特化。具体应用可以查看杂记5的让enum支持位运算。
20.3 Enable/Disable 启用或禁用函数模板
我们在第六章的时候讲了一些关于使用enable_if启用或禁用函数模板的例子。enable_if的核心其实就是在函数模板的偏序和重载机制上,再次强化选择的能力。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
template<typename Iter> //变量模板。判断是否是random迭代器。这里有细节。为什么要用is_convertible而不用is_same?
constexpr bool IsRandomAccessIter = is_convertible<typename IterTraits<Iter>::IterType, my_random_access_iterator_tag>::value;
template<typename Iter> //如果是random
typename enable_if<IsRandomAccessIter<Iter>>::type process(Iter& a, Iter& b){
cout <<"IS random access iter" << endl;
}
template<typename Iter> //如果不是random
typename enable_if<!IsRandomAccessIter<Iter>>::type process(Iter& a, Iter& b){
cout <<"NOT random access iter" << endl;
}
int main(){
cout << boolalpha;
my_RandomAccessIter r1;
my_RandomAccessIter r2;
my_InputIter i1;
my_InputIter i2;
process(i1, i1);
process(r1, r2);
return 0;
}
- 细节为何要使用
is_convertible而不用is_same?- 这是关于语义的。迭代器属于拓展类语义。越子类功能越丰富。比如如果我们想要允许有ABC功能的对象使用此类,则应该也允许有ABCDE功能的对象使用此类。也就是允许当前类的子类使用。所以使用
is_convertible - 这里注意应当把子类放在第一个参数,父类放在第二个参数。因为是判断子类是否可以转为父类。(子转父。不能父转子)
- 这是关于语义的。迭代器属于拓展类语义。越子类功能越丰富。比如如果我们想要允许有ABC功能的对象使用此类,则应该也允许有ABCDE功能的对象使用此类。也就是允许当前类的子类使用。所以使用
- 第二是我们需要写两个版本。这是为了激活SFINAE特性。因为我们不仅要指明符合要求时应该使用的方法,也要指明不符合要求的时候应该使用的方法。也就是确保对任意一个需要比较的类型,都应该只有一个模板可以被激活。
20.3.1 提供多种特化版本(enable_if的坑点)
假如我们还要有一个额外的条件需要判断,比如判断是否满足A功能。则我们要添加更多的enable_if去区分每一个更细致的特化。因为需要让它们彼此互斥。
这就是enable_if的缺点。也就是随着条件增加,需要判断的条件越来越多,则需要越来越多的enable_if。
标记派发和enable_if通常适用于不同的两种情况。
- 标记派发可以基于分层的(具有天然结构性的)tags支持简单的派发(条件性选择)。
enable_if则是基于类型萃取获得的任意一组属性来支持更为复杂的派发。(之前提到的专有类型属性)
20.3.2 enable_if应该怎么用?
enable_if 通常被用于函数模板的返回类型。但是enable_if 本身不适用于:
- 构造函数模板
- 类型转换模板
因为它们都没有被指定返回类型。而且,使用 enable_if 也会使得返回类型很难被读懂。
解决办法就是把enable_if放入一个额外的模板参数中当做默认模板参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
class Itertest{
public:
Itertest() = default;
template<typename Iter, typename = typename enable_if<IsRandomAccessIter<Iter>>::type>
Itertest(Iter begin, Iter last){
cout <<"construct called Random" << endl;
}
template<typename Iter, typename = typename enable_if<!IsRandomAccessIter<Iter>>::type> //不可以。
Itertest(Iter begin, Iter last){
cout <<"construct called Otheriter" << endl;
}
};
- 但是这时候我们不能使用老方法重载。因为只有函数模板参数的默认值不同是无法重载的。因为默认参数不算做函数签名。
- 这个问题可以使用额外模板参数(dummy parameter)来解决。另一个方法是6.3中重定义问题中的 “让参数本身不同”。
1
2
3
4
template<typename Iter, typename = typename enable_if<!IsRandomAccessIter<Iter>>::type, typename = int> //第三个参数是dummy parameter。
Itertest(Iter begin, Iter last){
cout <<"construct called Otheriter" << endl;
}
20.4 类的特化
类模板的偏特化和函数模板的重载很像。
20.4.1 启用/禁用 类模板
这个就是6.6提到的enable_if嵌入到类模板形参。
1
2
3
4
5
6
7
8
9
template<typename T1, typename T2, typename = void>
class myclass{
};
template<typename T1, typename T2>
class myclass<T1, T2, enable_if<....>>{
};
20.4.2 类模板的标记派发
这个明显较为复杂。注意,这不是CRTP。
我们的核心还是要在不同的模板特化中做选择。我们沿用迭代器的例子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
//-------可替换部分---------
template<typename...> //1
struct GetBestMatch{};
template<> //2
struct GetBestMatch<>{ //3
static void match(...); //4
};
//----------可以把上面的两个换成下面的一个。区别下面说--------------
template<typename...>
struct GetBestMatch{
static void match(...);
};
//----------------------------
template<typename T1, typename... Args> //5
struct GetBestMatch<T1, Args...>: public GetBestMatch<Args...>{ //6
static T1 match(T1){ //7
}
GetBestMatch(){ //测试函数签名用
std::puts(__PRETTY_FUNCTION__);
}
using GetBestMatch<Args...>::match; //8
};
template<typename T1, typename... Args>
struct GetBestMatchT{
using Type = decltype(GetBestMatch<Args...>::match(declval<T1>())); //9
};
template<typename T1, typename... Args>
using GetBestMatchValue = typename GetBestMatchT<T1, Args...>::Type; //10
template<typename Iter, typename tag = GetBestMatchValue <typename IterTraits<Iter>::IterType,
my_bidirectional_iterator_tag,
my_forward_iterator_tag,
my_input_iterator_tag,
my_output_iterator_tag,
my_random_access_iterator_tag>> //11
class myoperation{};
template<typename Iter>
class myoperation<Iter, my_input_iterator_tag>{
public:
void func(Iter& iter){
cout << "input iter" << endl;
}
};
template<typename Iter>
class myoperation<Iter, my_random_access_iterator_tag>{
public:
void func(Iter& iter){
cout <<"random iter" << endl;
}
};
int main(){
my_RandomAccessIter r1;
my_RandomAccessIter r2;
my_InputIter i1;
my_InputIter i2;
myoperation<my_InputIter> obj;
obj.func(i1);
myoperation<my_RandomAccessIter> obj2;
obj2.func(r1);
GetBestMatch<my_InputIter, my_bidirectional_iterator_tag,
my_forward_iterator_tag,
my_input_iterator_tag,
my_output_iterator_tag,
my_random_access_iterator_tag> test;
return 0;
}
1
2
3
4
5
6
GetBestMatch<T1, Args ...>::GetBestMatch() [with T1 = my_random_access_iterator_tag; Args = {}]
GetBestMatch<T1, Args ...>::GetBestMatch() [with T1 = my_output_iterator_tag; Args = {my_random_access_iterator_tag}]
GetBestMatch<T1, Args ...>::GetBestMatch() [with T1 = my_input_iterator_tag; Args = {my_output_iterator_tag, my_random_access_iterator_tag}]
GetBestMatch<T1, Args ...>::GetBestMatch() [with T1 = my_forward_iterator_tag; Args = {my_input_iterator_tag, my_output_iterator_tag, my_random_access_iterator_tag}]
GetBestMatch<T1, Args ...>::GetBestMatch() [with T1 = my_bidirectional_iterator_tag; Args = {my_forward_iterator_tag, my_input_iterator_tag, my_output_iterator_tag, my_random_access_iterator_tag}]
GetBestMatch<T1, Args ...>::GetBestMatch() [with T1 = my_InputIter; Args = {my_bidirectional_iterator_tag, my_forward_iterator_tag, my_input_iterator_tag, my_output_iterator_tag, my_random_access_iterator_tag}]
这个还是比较复杂。一点一点看。
GetBestMatch就是我们模仿重载的类。- 1是这个类的主模板。可以匹配任意情况,但是没有实现。为什么要这么写,下面说。
- 2是针对空参数包(parameter pack)实现的全特化。
- 3是具体的零长(空)参数包语法细节(12.4.5节)。因为是全特化所以特化部分声明依旧需要
<>。 - 4是使用
...接受参数包的任意参数。
- 3是具体的零长(空)参数包语法细节(12.4.5节)。因为是全特化所以特化部分声明依旧需要
- 5是一个偏特化。类的可变参数模板的偏特化是可以从变长模板里拆分的(12.4.1节)。
- 6这个类是继承自
GetBestMarch以剩余参数为参数的类的。这就是递归的模板展开。我们一会儿看函数签名。 - 7测试函数签名
- 8是使用
using引入父类的match函数。不引入的话,父类的match函数会被隐藏。 - 9使用
declval搭配decltype来判断输入的迭代器到底和哪个匹配。
关于我们的 static T1 match(T1) 函数,目的就是找到一个匹配的版本。也就是如果我们有ABC三个tag。则根据递归模板展开,会有三个match函数:
A match (A)B match (B)C match (C)
模板展开的同时我们使用using引入了父类的match,所以三个match都会被看见。最后在重载选择的时候,如果我们的T1是A就会正确匹配到A。以此类推。
- 同时为什么返回值也要是
T1不是void,因为我们用了decltype
我们看函数签名,我们发现就是一层一层的递归。每一个参数模板依次被当做T1。然后剩余参数包内容继续递归直到参数包空了为止。
- 整体逻辑:
首先我们的myoperation类的模板形参是iter类型和一个此处调用了GetBestMatchValue的检查最佳匹配的模板。
然后,进入到GetBestMatchValue别名模板。这时候的T1是当前迭代器入参的类型。参数包是所有迭代器的类型。调用GetBestMatchT。
然后进入GetBestMatchT萃取模板。首先把T1也就是当前迭代器类型使用declval模拟一个对象,调用GetBestMatch模板类内的match函数。同时使用decltype获取返回值类型。
我们此时进入核心模拟重载类模板GetBestMatch。这时候传入的Args是五个tag。然后进入递归阶段。模板一直展开至参数包为0,则 五个tag的最后面一个依次被当做T1,剩下的当做参数。
比如my_random_access_iterator_tag是最后一个,当前的T1就是my_random_access_iterator_tag。则match函数就是my_random_access_iterator_tag match(my_random_access_iterator_tag)。此时继承的基类是针对零长参数包的特化。使用using引入继承来的match函数。那个match可以接受任意参数。
以此类推。比如my_output_iterator_tag是倒数第二个。然后就是有自己的match函数。然后引入继承来的match函数。因为此时的父类是GetBestMatch<my_random_access_iterator_tag>
然后继续。剩下的看上面的函数签名推一下就好了。
最后,我们GetBestMatchValue应该返回的是和输入的迭代器类型最匹配的那一个类型。然后实例化myoperation类的对象的时候,模板实参会被默认参数补齐。tag会被替换成正确版本。然后进行匹配至特定的偏特化版本。
- 最后关于两种替换的写法。
这两种结果都可以。但是第一种带全特化的明显更好。原因是在这种情况下,可能有一些边缘情况我们没有考虑到。所以我们不应该让主模板接受任意参数,做为默认的版本。我们不应该提供主模板的实现,只提供一个针对零长参数包的特化。这样在某些边缘情况只能匹配到主模板的时候,应该报错。因为没有考虑过边缘情况。核心就是防止误用。
20.5 实例化安全的模板
这个例子比较长。简而言之书里X3不行的原因是X3的operator<是接受两个非常量左值引用类型。而我们HasLess里面的test用了临时对象<临时对象(无论是declval还是直接U1()都不行。因为都是右值)。但是非常量左值引用不能接受右值,自然就不行。
- 额外提到了的坑是
X7。X7的boollike虽然不能隐式转为bool。但是可能发生显式的向bool类型的转换可以被隐式使用,比如控制语句的bool类型条件,内置的!,&&,||运算符和三目运算符?:。在这些情况下,该值被认为是 语境上可以转换为bool
这可能会发生问题。但是我们可以解决。虽然语句和被任意类型重载的逻辑不能出现在SFINAE上下文,但是三目运算符是表达式且不能被重载。所以可以用它来测试语境上是否可以转换为bool。
接着讨论一下HasLess的细节
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<typename T1, typename T2>
class HasLess {
template<typename T> struct Identity; //细节1
template<typename U1, typename U2>
static std::false_type test(...);
template<typename U1, typename U2>
static std::true_type test(Identity<decltype(declval<U1>() < declval<U2>())>*); //细节2
public:
static constexpr bool value = decltype(test<T1, T2>(nullptr))::value;
};
- 我们发现他的实现有一些不同。细节1使用了一个额外的
struct,并且细节2使用了这个struct的指针,为什么?- 首先,我们的目的和之前的不同。之前可以使用一个函数形参来检测隐式转换。但是这里我们需要让整个小于表达式合法。我们可以在下面也使用之前的形式。但是这里更为方便。
- 我们如果
U1和U2拥有合法的小于比较操作,则这个decltype是bool类型。可以实例化一个Identity的指针。为什么是指针?因为Identity是不完整类型。 - 如果没有合法操作,则匹配至
...万能版本。
所以我们更改一下实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
template<typename T1, typename T2>
class AnotherHasLess {
template<typename T> struct Identity{}; //细节1
template<typename U1, typename U2>
static std::false_type test(...);
template<typename U1, typename U2, typename = decltype(Identity<decltype(declval<U1>() < declval<U2>())>())> //细节2
static std::true_type test(void*);
public:
static constexpr bool value = decltype(test<T1, T2>(nullptr))::value;
};
- 由于我们此时给
Identity提供的是完整类型,所以我们在下面可以不使用指针而是使用()生成匿名对象。 - 同时我们也不一定非得放到函数参数里。我们也可以放到模板参数里。
甚至可以这样参考19.4.1和19.5来实现
1
2
3
4
5
6
7
8
9
10
11
12
13
template<typename T1, typename T2>
class MoreHasLess {
static bool try_call(bool); //细节1
template<typename U1, typename U2>
static std::false_type test(...);
template<typename U1, typename U2, typename = decltype(try_call(declval<U1>() < declval<U2>()))> //细节2
static std::true_type test(void*);
public:
static constexpr bool value = decltype(test<T1, T2>(nullptr))::value;
};
- 这里我们依旧模拟了19.4.1的形式。使用一个函数。但是这有一个小问题。问题就是我们笃定
operator<一定返回bool。但其实不一定。也不一定能隐式转换。这里其实就是看语义了。 - 细节2就是这里可以和19.5一样了。
第二十一章 模板和继承
21.2 CRTP 奇异递归模板模式
CRTP的一个最明显的特点就是把派生类作为基类的模板参数
1
2
3
4
5
6
7
8
template<typename T>
class Base{
};
class Derive: public Base<Derive>{
};
CRTP 的第一个概要展示了一个非依赖性基类: 子类(Derive)不是模板,因此不受依赖基类的一些名称可见性问题的影响。
在CRTP模式中,基类被声明成一个类模板,派生类继承自基类的一个特化——基于派生类自身的特化。如上面的代码所示,基类Base根据派生类Derive进行实例化,而派生类Derive则继承基类Base根据Derive实例化的那个类。
- CRTP的核心是利用子类的信息生成代码,使用静态多态而不是动态多态。
我们首先以一个例子和一个理由来阐述为什么需要CRTP。
- 我们用一个最简单的例子解释什么叫静态多态替换了动态多态
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
template <typename T>
class Base{
public:
void func(){ //注意这个不是虚函数。不是动态多态
static_cast<T*>(this)->func(); //使用static_cast转换为子类指针
}
};
class myclass:public Base<myclass>{
public:
void func(){
cout <<"called" << endl;
}
};
int main(){
Base<myclass>* obj = new myclass;
obj->func();
}
这里的核心原理是,我们在父类的func函数中使用static_cast把this指针cast为子类指针,然后调用子类对象。可以用static_cast是因为我们基本上可以从语义上保证这一操作绝对合法。
可以使用智能指针,因为允许不完整类型。
表面看上去没什么用,但是这确实是介绍CRTP的一个好方式。但是坑有很多
第一个坑 子类没有实现父类调用的函数
如果在我们上一个例子中,子类没实现func函数会有什么问题?答案是无限递归。并段错误。但是编译期并没有问题。我们调用Base::func()的时候,紧接着会调用myclass::func(),但是子类没有自己的func(),此时父类的func()会被调用,自然无限递归。
这里的问题是,没有什么规定来强制我们重写派生类中的成员函数func(),但是如果我们不重写,程序就会产生错误。问题的根源在于,我们将接口和实现混在了一起——基类中的公共成员函数声明表示所有派生类都必须有一个函数void func()作为其公共接口的一部分,而派生类则应该对此函数提供不同版本的实现。针对此问题,一种临时的解决方法是,让函数实现和函数声明具有不同的函数名,如下所示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template <typename T>
class Base{
public:
void func(){
static_cast<T*>(this)->func_impl();
}
//void func_impl(){}//默认实现,如果想要的话。
};
class myclass:public Base<myclass>{
public:
void func_impl(){ //换个名字
cout <<"called" << endl;
}
};
此时,如果我们忘记实现myclass::func_impl(),那么程序就不会被编译通过,因为派生类myclass中不存在这样的成员函数。通过将函数声明和实现相分离的方式,我们在编译期多态中实现了纯虚函数的机制。如果我们想实现一个常规的虚函数,只需要在基类中提供一个func_impl的默认实现。
第二个坑 析构函数
CRTP模式面临的一个问题是,如何根据一个基类指针删除对应的派生类对象?在运行期多态下,这就很容易,我们直接把析构函数声明成虚函数即可。但是在编译期多态中,不依赖虚函数,该如何解决这个问题呢?一个错误的解决方法是直接对基类指针调用delete操作符。在这种情况下,只有基类的析构函数被调用了,派生类的析构函数没有被调用。因为此时基类的析构函数不是虚函数。。另一个错误的解决方法是在基类的析构函数中将基类类型转换成派生类类型,再调用派生类的析构函数。然而,在基类的析构函数中,任何对派生类的非虚成员函数的调用都可能产生未定义行为。即使没有产生未定义行为,派生类的析构函数会调用基类的析构函数,从而产生递归调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template <typename T>
class Base{
public:
void func(){
static_cast<T*>(this)->func_impl();
}
int* baseval = new int(10);
virtual ~Base(){ //如果不加virtual,就会泄漏
delete baseval;
}
};
class myclass:public Base<myclass>{
public:
void func_impl(){
cout <<"called" << endl;
}
int* deval = new int(20);
~myclass(){
delete deval;
}
};
这个问题的解决方案有两个。
- 一是使用一个额外的函数模板,将编译期多态性应用到删除操作上。比如
1
2
3
4
template <typename T>
void destroy(Base<T>* b) {
delete static_cast<T*>(b);
}
但是比较违背RAII特性。
- 另一个解决方案是让析构函数成为真正的虚函数,也就是直接把析构函数声明为虚的。这种方法会略微增加虚函数调用的开销。不过我们只把析构函数声明成虚函数,相比于把所有成员函数声明成虚函数要好得多。
CRTP和委托模式
这是最为常见的一种CRTP用法。
我们之前通过CRTP实现了编译期多态,可以通过基类指针或引用访问派生类对象中的方法。在这种情况下,基类会定义若干通用接口,而派生类负责提供不同的实现,这种用法也被称为静态接口。但是,如果我们直接使用派生类对象,那么情况就会变得不同——基类不再是接口,派生类也不仅仅是实现。派生类扩展了基类的接口,基类的一些行为被委托给派生类。
假设我们有一个需求:为所有的提供了operator==的类自动提供一个operator!=。我们这时候就可以使用CRTP。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
template <typename T>
class Base{
public:
// bool operator!=(const Base& rhs){ //两种写法,这种更清晰
// if(static_cast<const T&>(*this).operator==(static_cast<const T&>(rhs)) == true){
// return false;
// }
// return true;
// }
bool operator!=(const Base& rhs){
if((static_cast<const T&>(*this) == static_cast<const T&>(rhs)) == true){ //注意cast
return false;
}
return true;
}
};
class myclass:public Base<myclass>{
public:
int val = 0;
myclass() = default;
myclass(int x):val(x){}
bool operator==(const myclass& rhs) const { //必须const
return val == rhs.val;
}
};
- 这里我们主要注意cast。我们由于入参是
base类的引用,所以要给this解引用后cast为T的引用,同时因为static_cast不能移除const,所以要cast为const引用。同时常量引用不能调用非常量成员函数,下面的operator==依旧要为const。
CRTP和enable_shared_from_this
STL里面最经典的CRTP应用便是这个了。如果我们想获取一个指向自己的智能指针,就必须继承自这个类。然后使用shared_from_this()
使用举例:
1
2
3
4
5
6
struct Good: std::enable_shared_from_this<Good> // 注意:继承,模板参数是本类类型。符合CRTP特征。
{
std::shared_ptr<Good> getptr() {
return shared_from_this();
}
};
部分源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
template<typename _Tp>
class enable_shared_from_this
{
protected:
enable_shared_from_this(const enable_shared_from_this&) noexcept { }
~enable_shared_from_this() { }
public:
shared_ptr<_Tp>
shared_from_this()
{ return shared_ptr<_Tp>(this->_M_weak_this); } //通过弱指针来创建shared_ptr并返回。
shared_ptr<const _Tp>
shared_from_this() const
{ return shared_ptr<const _Tp>(this->_M_weak_this); }
private:
mutable weak_ptr<_Tp> _M_weak_this; //维护的类类型的弱指针
};
enable_shared_from_this的核心原理是:通过自身维护了一个std::weak_ptr让所有从该对象派生的shared_ptr都通过std::weak_ptr构造派生。关于这个弱指针在哪儿被赋值,看这里
CRTP和计数器
可以查看more effective c++ 条款26
https://www.youtube.com/watch?v=ZQ-8laAr9Dg
https://blog.csdn.net/breadheart/article/details/112451022
https://www.cnblogs.com/shuo-ouyang/p/15773193.html
https://www.cnblogs.com/happenlee/p/13278640.html
https://blog.csdn.net/lgp88/article/details/7529254
21.3 mixin 混合类
这是一个非常神奇的东西。有一点依赖倒置样子。鼓励代码重用,且不会有多重继承导致的歧义(菱形问题)。
继承的问题是无法自由的组合这些具体类,但是mixin是一种灵活的组合概念。
它可以通过多继承来实现。
上面又说组合,又说可以通过继承来实现,是不是非常疑惑?看看下面的第一个例子。
我想出来了两种例子,但是我并不确定mixin是否有严格定义。
- 第一种情况。
这种情况较为常见。就是传统意义的多继承。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
class printBase{
public:
virtual void print_val() = 0;
};
class printMethod1 : public virtual printBase{
public:
void my_print(){
cout <<"method1" << endl;
}
void print_val(){
my_print();
}
};
class printMethod2 : public virtual printBase{
public:
void my_print(){
cout <<"method2" << endl;
}
void print_val(){
my_print();
}
};
class I_want_all:public printMethod1, printMethod2{
public:
void print_val(){
printMethod1::my_print();
}
void print_method1(){
print_val();
}
void print_method2(){
printMethod2::my_print();
}
};
int main(){
I_want_all obj;
obj.print_method1();
obj.print_method2();
}
问题在于虚继承会有损性能。如何用mixin改写?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
template<typename T>
class printMethod1 : public T{
public:
void my_print(){
cout <<"method1" << endl;
T::my_print();
}
};
template<typename T>
class printMethod2 : public T{
public:
void my_print(){
cout <<"method2" << endl;
T::my_print();
}
};
class myclass{
public:
void my_print(){
cout <<"my print" << endl;
}
};
int main(){
myclass obj;
obj.my_print();
cout<<"-----------------------"<<endl;
printMethod1<myclass> obj2;
obj2.my_print();
cout<<"-----------------------"<<endl;
printMethod2<myclass> obj3;
obj3.my_print();
cout<<"-----------------------"<<endl;
printMethod1<printMethod2<myclass>> obj4;
obj4.my_print();
cout<<"-----------------------"<<endl;
printMethod2<printMethod1<myclass>> obj5;
obj5.my_print();
}
/*
my print
-----------------------
method1
my print
-----------------------
method2
my print
-----------------------
method1
method2
my print
-----------------------
method2
method1
my print
*/
我们主要注意到了,不再有printBase基类了。也就是这里不存在严格的单继承或多继承关系。但是非常神奇的一点是在最后obj4和obj5的使用中,神奇的所有需要打印的都打印了。以obj4为例。printMethod1继承自printMethod2<myclass>。printMethod2继承自myclass。所以在printMethod1中,打印了自己的后T是printMethod2<myclass>,进入printMethod2中的打印,打印自己后T是myclass,所以最后进入myclass打印。
我们发现,这么看起来,myclass反而是基类。这就是一种依赖倒置。我们提供实现了my_print的类,而库只需要调用我们的类即可。
如果严格按照继承来进行,失去了灵活的组合能力。必须固定化某个顺序。比如我们假设想要调整打印顺序,如果是默认的单继承是不可能的。
- 第二个例子
这个例子中,非常明显的体现出了依赖倒置原则。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
template<typename... Mixin>
class PointMixin : public Mixin...{
public:
PointMixin() = default;
PointMixin(int x, int y): Mixin()..., posx(x), posy(y){} //Mixin()...是一个参数包展开。作用是调用所有继承来的类的默认构造。这里最好调用一下。养成好习惯。虽然此处不调用也没差。
int posx = 0;
int posy = 0;
};
class color{
public:
color(){
cout <<"color const called" << endl;
}
int colorID = 234;
void colorfunc(){
cout <<"color" << endl;
}
};
class label{
public:
label(){
cout <<"label const called" << endl;
}
char charId = 'a';
void labelfunc(){
cout <<"label" << endl;
}
};
int main(){
PointMixin<color, label> obj;
obj.labelfunc();
obj.colorfunc();
}
这个例子的依赖倒置就非常非常明显。我们提供的color和label被PointMixin继承。所以就算PointMixin可能是库提供的,但是它依旧是子类。这里利用了可变参数包展开的多继承。
我们可以发现,PointMixin成功获得了我们的color和label类的属性,也就是我们成功把可变属性添加到了不可变的类当中。这种依赖倒置还是非常常见的。
- 我们甚至还可以用容器储存:
1
2
3
4
5
6
7
8
9
10
11
12
13
template<typename... Mixins>
class containerMixins{
public:
vector<PointMixin<Mixins...>> myvec;
};
int main(){
PointMixin<color, label> obj;
containerMixins<color, label> mycontainer;
mycontainer.myvec.push_back(obj);
mycontainer.myvec[0].labelfunc();
mycontainer.myvec[0].colorfunc();
}
- 混合类还可以和CRTP共同使用
https://fuzhe1989.github.io/2018/04/21/mixin/
https://blog.csdn.net/jiang4357291/article/details/103325488
第二十二章 桥接(此处的桥接是动词,连接的意思)静态和动态多态
22.1 函数对象,函数指针和std::function
这是老生常谈的问题了。std::function使用类型擦除可以同时接收多种可调用对象。
假设我们需要让一个函数接受多种可调用对象,可能的一种方式是使用模板:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
struct myobj{ //重载了函数调用运算符的类
void operator()(int x){
cout << "called" << x << endl;
}
};
void func(int x){ //函数指针
cout << "called" << x << endl;
}
template<typename F>
void test(int x, F f){ //调用
std::puts(__PRETTY_FUNCTION__);
f(x);
}
int main(){
auto mylambda = [](int x){cout <<"called" << x << endl;}; //lambda
test(10, mylambda);
test(20, func);
test(30, myobj());
}
- 原因是:
- 重载了函数调用运算符的类不能直接转换为函数指针。它是成员函数指针,和函数签名不符合。
- lambda只有在捕获符为空的时候才能被转换为函数指针(参见lambda介绍,只有捕获符为空的时候用户定义转换函数才会被定义)
我们可以看到,三者的F类型推导结果并不一致
1
2
3
4
5
6
void test(int, F) [with F = main()::<lambda(int)>]
called10
void test(int, F) [with F = void (*)(int)]
called20
void test(int, F) [with F = myobj]
called30
- 所以如果不使用模板,这三者并不能被兼容。
这样做有一个问题:三种类型的实例化会导致代码膨胀,所以我们有类型擦除的典范:std::function。但是它性能很差。
剩下的是std::function的模拟实现和桥接模式
给我脸都看绿了。
https://blog.csdn.net/zdy0_2004/article/details/50652934
https://blog.csdn.net/weixin_43798887/article/details/116571325
https://zhuanlan.zhihu.com/p/560964284
https://zhuanlan.zhihu.com/p/66301236
第二十四章 类型列表
24.1~24.2 类型列表剖析和操作
- typelist简单的说就是一个类型容器,能够对类型提供一系列的操作(把类型当成数据来操作)。就象C++标准库中的list容器(能够对各种数值提供各种基本操作),但typelist是针对类型进行操作。
- 从实现上,typelist是一个类模板,中文名字叫:类型列表。该类模板用来表示一个列表,在该列表中存放着一堆类型。
注意:typelist的值不可以被修改。也就是我们下面例子中任何对typelist的操作,如增添,删除,都是通过对应操作创建的新的typelist
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
template<typename... Items>
class typeList{}; //类型列表 主类 。你没看错,就这么简单
//-----获取第一个元素------
template<typename Items> //Item代表了整个typeList。所以此处不需要变参。
class FrontItem{}; //获取第一个元素的主模板。
//因为我们整个塞进去的是typeList。所以我们下面的特化是基于typeList里面的参数的。
template<typename First, typename... Other>
class FrontItem<typeList<First, Other...>>{ //偏特化,把元素按照第一个和其余的拆开。
public:
using type = First; //只保留第一个元素
};
//-----移除第一个元素------
template <typename Items> //此处同FrontItem
class PopFront{}; //移除第一个元素
template<typename First, typename... Other> //此处同FrontItem
class PopFront<typeList<First, Other...>>{
public:
using type = typeList<Other...>; //去掉第一个元素,成为新的typelist
};
//-----获取typelist的大小------
template<typename Items>
class ListSize{}; //获取类型列表的大小。此处同FrontItem
template<typename... Items> //因为我们不再需要拆开了,所以不需要First模板形参了。
class ListSize<typeList<Items...>>{
public:
static inline size_t value = sizeof...(Items);
};
//-----头部插入元素------
template<typename Items, typename NewItem> //此处同FrontItem, Items是整个typelist, NewItem是新的元素(类型)。
class PushFront{}; //头插
template<typename... Items, typename NewItem> //和pop相反
class PushFront<typeList<Items...>, NewItem>{ //和pop相反
public:
using type = typeList<NewItem, Items...>; //直接组合成新的typelist
};
//-----尾部插入元素------
template<typename Items, typename NewItem> //此处同FrontItem, Items是整个typelist, NewItem是新的类型。
class PushBack{}; //尾插
template<typename... Items, typename NewItem> //和头插相同
class PushBack<typeList<Items...>, NewItem>{ //和头插相同
public:
using type = typeList<Items..., NewItem>; //直接组合成新的typelist,只是和头插顺序相反。
};
//-----替换第一个元素------
template<typename Items, typename ReplaceItem>
class ReplaceFront{}; //替换第一个元素。
template<typename First, typename... Other ,typename ReplaceItem> //注意这里有三个元素。第一个,剩下的和替换的。
class ReplaceFront<typeList<First, Other...>, ReplaceItem>{
public:
using type = typeList<ReplaceItem, Other...>; //直接把第一个换成替换的即可。
};
//-----判断是否为空------
template<typename Items>
class isEmpty{ //判断是否为空。
public:
static inline const bool value = false;
};
template<>
class isEmpty<typeList<>>{ //直接全特化。如果列表为空直接匹配过来。
public:
static inline const bool value = true;
};
//-----真正的typelist-----
using Typelist1 = typeList<int, char, string, double, float>; //类型列表
using emptylist = typeList<>;//空的类型列表
int main(){
cout << boolalpha;
cout << typeid(FrontItem<Typelist1>::type).name() << endl; //输出类型列表第一个元素的类型。int
cout << ListSize<Typelist1>::value << endl;//输出类型列表的大小。5
cout << typeid(FrontItem<PopFront<Typelist1>::type>::type).name() << endl; //先把类型列表的第一个元素去掉,然后输出第一个元素类型。char。记住,我们针对所有原始类型列表的操作,都不是作用于原始列表。都是新建列表。
cout << ListSize<PopFront<Typelist1>::type>::value<<endl; //获取移除第一个元素后的列表大小。4
cout << typeid(FrontItem<Typelist1>::type).name() << endl; //获取原始类型列表的第一个元素,证明操作不作用于原始列表。int
using pushedback = PushBack<Typelist1, int>::type; //使用别名方便使用。这个操作是在类型列表尾部插入新的类型int
cout << ListSize<pushedback>::value<<endl; //插入后,新列表大小。6(原来是5)
using pushedfront = PushFront<pushedback, double>::type; //在尾插后的类型列表头插double
cout << ListSize<pushedfront>::value<<endl;//新列表大小7
using replaced_front = ReplaceFront<Typelist1, float>::type; //把类型列表首元素换位float
cout << typeid(FrontItem<replaced_front>::type).name() << endl; //新列表首元素 float
cout << isEmpty<Typelist1>::value << endl; //是否为空,否
cout << isEmpty<emptylist>::value << endl; //是否为空,是
return 0;
}
我们可以发现,整个过程其实就是针对typelist元素的组合。应用了偏特化和全特化的知识。
- 额外介绍一下索引
1
2
3
4
5
6
7
8
9
10
template<typename Items, unsigned int m_index> //item是个typelist,m_index是索引
class find_element: public find_element<typename PopFront<Items>::type, m_index-1>{};
//这里面用了递归,每次都继承自把首元素去掉的typelist。注意需要使用type因为那才是我们定义的typelist。并且加typename显式指明是类型。然后index-1
template<typename Items>//这个是针对找到了对应index的特化。因为index最终会减到0。这时候的特化版本继承自FrontItem,因为这个时候typelist的首元素就是我们想要找的那个元素。
class find_element<Items, 0>: public FrontItem<Items>{};
cout << typeid(find_element<Typelist1, 3>::type).name() << endl; //输出double
所以整个过程就是
find_element<typelist<int, char, string, double, float>,3>继承自find_element<typelist<char, string, double, float>,2>- 然后继承自
find_element<typelist<string, double, float>,1> - 然后当前变为
find_element<typelist<double, float>,0>,继承自特化版本,就是FrontItem<typelist<double, float>> - 因为
FrontItem定义了type。所以可以直接用了。
24.3~ 这部分比较枯燥,暂时略过
第二十五章 元组
元组就是一种可以储存不同类型的容器。通常使用模板元编程和typelist来实现。元组在语法上有一个不同的地方,也就是元组中的元素是用位置信息(下标)索引的。而不是通过名字。
25.1 基本的元组设计
元组的核心原理和上面的typelist几乎一模一样。
25.1.1 存储
我们应该记得标准库的元组的使用方式。存储通过函数模板get()进行访问。对于元组t,语法为get<I>(t)。I是元素下标。此时返回的是第I个元素的引用(和其他容器一样)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
template<typename... Types>
struct my_tuple{}; //主模板。和typelist一样。
template<typename First, typename... Others>
struct my_tuple<First, Others...>{
First first; //头元素
my_tuple<Others...> others; //其他的元素组成的my_tuple
my_tuple(){
cout <<"const" << endl; //默认构造
};
my_tuple(const First& head, const my_tuple<Others...>& tail):first(head), others(tail){
cout <<"tuple const called" << endl;
//这个构造的意义是使用一个元素和另一个tuple进行构造。
};
my_tuple(const First& head, const Others&... tail):first(head), others(tail...){
cout << first << endl;
cout << "size of rest elements: "<< sizeof...(tail) << endl;
std::puts(__PRETTY_FUNCTION__);
cout <<"element const called" << endl;
//这个构造才是我们直观的,使用一堆独立的元素构造
};
First& getHead(){
cout <<"getHead called" << endl;
return first;
}
const First& getHead() const{
cout <<"getHead called" << endl;
return first;
}
my_tuple<Others...>& getTail(){
cout <<"getTail called" << endl;
return others;
}
const my_tuple<Others...>& getTail() const{
cout <<"getTail called" << endl;
return others;
}
~my_tuple(){
cout <<"dest" << endl;
}
};
template<> //这个特化是针对空参数。也就是最后剩余参数为0的情况
struct my_tuple<>{
};
template <unsigned int m_index>
struct find_element{
template<typename First, typename... Others>
static auto m_get(const my_tuple<First, Others...>& t){
cout <<"current index: " << m_index << endl;
return find_element<m_index-1>::m_get(t.getTail());
//这里的类模板是get<N>的N我们要显式指定
//这里的函数模板是通过my_tuple进行推导。可变参数被拆分了。
//随后递归调用,m_index每次-1然后调用getTail,也就是去掉每一次的头部。
}
};
template<> //find_element的特化。也就是此时index减到为0了。我们找到了想找的元素
struct find_element<0>{
//下面是两个版本而已。
template<typename First, typename... Others>
static const First& m_get(const my_tuple<First, Others...>& t){
cout <<"m_get called" << endl;
return t.getHead();
//由于此时头部元素就是我们想要找的,所以直接调用getHead
}
template<typename First, typename... Others>
static First& m_get(my_tuple<First, Others...>& t){
cout <<"m_get called" << endl;
return t.getHead();
}
};
//----------const和非const的get。注意get不是成员函数。标准库也是这样设计的。
template<unsigned int m_index, typename... Types>
auto get(const my_tuple<Types...>& t ){
return find_element<m_index>::m_get(t);
}
template<unsigned int m_index, typename... Types>
auto get(my_tuple<Types...>& t ){
return find_element<m_index>::m_get(t);
}
int main(){
my_tuple<int, char, double, float> testtuple(10, 'a', 2.3, 3.4);
cout<<"--------------------------------------" << endl;
cout << get<2>(testtuple) << endl;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
3.4
size of rest elements: 0
my_tuple<First, Others ...>::my_tuple(const First&, const Others& ...) [with First = float; Others = {}]
element const called
2.3
size of rest elements: 1
my_tuple<First, Others ...>::my_tuple(const First&, const Others& ...) [with First = double; Others = {float}]
element const called
a
size of rest elements: 2
my_tuple<First, Others ...>::my_tuple(const First&, const Others& ...) [with First = char; Others = {double, float}]
element const called
10
size of rest elements: 3
my_tuple<First, Others ...>::my_tuple(const First&, const Others& ...) [with First = int; Others = {char, double, float}]
element const called
--------------------------------------
current index: 2
getTail called
current index: 1
getTail called
m_get called
getHead called
2.3
dest
dest
dest
dest
- 我们发现,构造过程中和CRTP一样,是递归调用。我们通过函数签名发现,每次在构造函数中初始化本类的
others的时候,都会进入下一层的递归。所以在最后一层Others参数包为空的时候,first就是tuple的最后一个元素。
所以第一个打印出来的是3.4 (最后一个元素)。参数包size为0。然后逐层弹出。
所以我们发现,一共有四个my_tuple对象被构造了。因为我们的others成员变量本身就是一个my_tuple对象。
所以 10, 'a', 2.3, 3.4 相当于
my_tuple(10, my_tuple('a', my_tuple(2.3, my_tuple(3.4, my_tuple<>))))
- 然后看一下
get。
这个get和typelist的get如出一辙。都是通过index逐次-1然后去掉头部元素(这里是通过gettail保留尾部)实现的
我们从打印中能看出来。index每次减掉1,然后getTail被调用。
当index为0的时候匹配至特化,这时候调用getHead。
剩下的还是比较多的,看书吧。
https://blog.csdn.net/baidu_41388533/article/details/109818986
std::is_same
- is_same的主要作用是判断两个类型是否相同。
1
2
template< class T, class U >
struct is_same;
- 如果T与U是考虑
const-volatile限定的相同类型,则is_same<T,U>::value为true,否则为false。
举例:
1
2
3
4
5
int main(){
cout << is_same<int, int>::value << endl; //输出1 (true)
cout << is_same<int, string>::value << endl; //输出0 (false)
return 0;
}
可能的实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
template<typename _Tp,_Tp _v>
struct intergral_constant{
static constexpr _Tp value = _v; //表示值
typedef _Tp value_type; //值类型
typedef intergral_constant<_Tp,_v> type; //表示自己的类型
constexpr operator value_type () const noexcept {return value;}
constexpr value_type operator()() const noexcept {return value;} //since c++14
};
//定义true_type 和 false_type
typedef intergral_constant<bool, true> true_type;
typedef intergral_constant<bool, false> false_type;
//is_same的实现
template <typename T1,typename T2>
struct is_same: public false_type {};
//类型相同就相当于一个模板参数
template <typename _Tp>
struct is_same<_Tp,_Tp>: public true_type {};
- 首先定义了一个类模板
is_same,这个类模板有两个模板参数T和U。接着针对这个类模板T和U类型相同的情况进行偏特化。所以,当T和U为同一种类型时,将匹配到1,不同则匹配到0。两个版本唯一的不同是父类。 - 然后是判断两个类型,如果两个类的类型不同,那么应该是继承自
false_type,如果类型相同的话应该继承自true_type。
自己模拟一下简单实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
template<typename T1, typename T2>
class MyClass {
public:
//主模板 如果两个类型不一则会匹配到这里
MyClass(T1 a, T2 b):val1(a), val2(b){
cout <<"diff type" << endl;
}
T1 val1;
T2 val2;
};
template<typename T>
class MyClass<T,T> {
public:
//同一类型的偏特化模板。如果两个类型一致则会匹配到这里
MyClass(T a, T b):val1(a), val2(b){
cout << "same type" << endl;
}
T val1;
T val2;
};
int main(){
MyClass<int, int> myobj1(19,22); //输出 same type
MyClass<int, string> myobj2(11, "abcde"); //输出 diff type
return 0;
}
std::is_convertible
is_convertible用于判断两个类型之间是否可以隐式转换:第一个模板参数的类型是否可以隐式转换为第二个模板参数的类型。
1
2
template< class From, class To >
struct is_convertible;
首先,如果满足下列条件,则 std::is_convertible<From, To>::value 为 true,否则为 false
From和To均为void类型(可含有cv限定)std::declval<From>()可隐式转换为To类型- 例子1:如果
From,to都是基本类型,那么可以隐式转换。 - 例子2:如果
From是子类,To是基类,那么From可以转换为To。 - 核心就是查看两个类之间是否有一个转换序列可以满足类型转换。
- 使用例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
struct A { };
struct B : A { };
int main() {
cout << std::boolalpha; /* 输出流将bool输出true/false, 而不是1/0 */
cout << "is_convertible:" << endl;
cout << "int => float: " << is_convertible<int,float>::value << endl;
cout << "int = >const int: " << is_convertible<int,const int>::value << endl;
cout << "A => B: " << is_convertible<A,B>::value << endl; /* A不能转换为B */
cout << "B => A: " << is_convertible<B,A>::value << endl; /* B能转换为A */
return 0;
}
/*
is_convertible:
int => float: true
int = >const int: true
A => B: false
B => A: true
*/
- 进阶例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class myobj2{
public:
int val;
myobj2() = default;
myobj2(int a):val(a){}; //注意这里是没有explicit
operator int(){ //注意这里加了用户定义转换函数
return val;
}
};
int main(){
cout << "myobj2 => int: " << is_convertible<myobj2, int>::value << endl; //true myobj2可以隐式转换为int
cout << "int => myobj2: " << is_convertible<int, myobj2>::value << endl; //true int可以隐式转换为myobj2。
return 0;
}
由于我们加了用户定义转换函数,所以可以从myobj2隐式转为int。我们也有转换构造函数,所以也可以从int隐式转换为myobj2
- 如果去掉类型转换函数:
1
2
3
4
5
6
7
8
9
10
11
12
class myobj2{
public:
int val;
myobj2() = default;
myobj2(int a):val(a){}; //注意这里是没有explicit
};
int main(){
cout << "myobj2 => int: " << is_convertible<myobj2, int>::value << endl; //false myobj2不可以隐式转换为int
cout << "int => myobj2: " << is_convertible<int, myobj2>::value << endl; //true int可以隐式转换为myobj2。
return 0;
}
- 如果给构造函数添加explicit,禁止隐式类型转换:
1
2
3
4
5
6
7
8
9
10
11
12
class myobj2{
public:
int val;
myobj2() = default;
explicit myobj2(int a):val(a){}; //有explicit
};
int main(){
cout << "myobj2 => int: " << is_convertible<myobj2, int>::value << endl; //false myobj2不可以隐式转换为int
cout << "int => myobj2: " << is_convertible<int, myobj2>::value << endl; //false int不可以隐式转换为myobj2。
return 0;
}
详细:https://www.cnblogs.com/fortunely/p/16216310.html
关于判断对象类型还是指针类型之间是否可以转换的坑在智能指针的MEC++28条部分
std::is_base_of
1
2
template< class Base, class Derived >
struct is_base_of;
若 Derived 派生自 Base 或为同一非联合类(均忽略 cv 限定),则提供等于 true 的成员常量 value 。否则 value 为 false 。
其实没啥好说的,就是看Derived是不是派生自Base。但是这个和上面的std::is_convertible有啥区别?
还是有区别的。因为std::is_convertible核心是查看能否隐式转换。当然了,在继承链条上大部分情况都可以。但是还是有例外,比如私有继承的时候就不能转。所以说std::is_base_of做的就是一件事,查看是否是派生关系。然而std::is_convertible做的事情就更多了。
std::is_constructible
1
2
template <class T, class... Args>
struct is_constructible;
如果通过使用 Args 中的参数类型可构造类型 T,则类型谓词的实例保持 true;否则保持 false。 如果变量定义 T t(std::declval<Args>()...); 的格式正确,则可以构造类型 T。 T 和 Args 中的所有类型都必须是完整的类型、void,或者是未知边界的数组。
这一大堆官方文档其实就是意思是看
Args的这些参数能不能构造T类型对象。上面的
is_convertable是来判断能否隐式转换。而这里可以被用来测试是否可以显式转换。杂记1中我们提到过:显式地调用构造函数进行直接初始化实际上是显式类型转换的一种。
例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class myobj{
public:
int val;
char single;
string name;
myobj(){}
myobj(int a):val(a){};
myobj(int a, char b, string& c): val(a), single(b), name(move(c)){};
};
int main(){
cout << is_constructible<myobj, int>::value << endl; //trus
cout << is_constructible<myobj, int, char, string>::value << endl; //false
cout << is_constructible<myobj, int, char, string&>::value << endl; //true
return 0;
}
为啥第二个传值是false?我们不是可以如这样:
1
2
string name = "abc";
myobj a(12,'a',name);
- 注意了,这里的
name虽然是值,但是由于函数签名是string&,所以name这个参数在我们传递到函数内的时候,函数内会创建一个name的引用,叫做c。 - 这里可以理解为函数签名。你想把一个函数
void function(int& x)塞进这样的函数指针void(*ptr)(int)是错的。引用和值在签名处不可混为一谈。 - 同时,针对这个构造函数,如果我们尝试这样做:
1
myobj(1, 'c', std::string{"lalala"});
这时候就会失败。因为左值引用不能接右值。
所以在这里,函数的形参类型是
string还是string&有很大差别。当然了,这里如果给构造函数换成const string&就都是true了。或者是换成string值传递也都是true。因为常量左值引用可以接一切。值传递的函数塞引用也没问题。因为引用会被脱去。进阶例子:
上面我们提到了,我们给转换构造函数加了explicit,所以不能隐式转换。所以is_convertible<int, myobj2>::value是false。我们可以尝试用这里的is_constructible来看是否可以显示转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class myobj2{
public:
int val;
myobj2() = default;
explicit myobj2(int a):val(a){}; //依旧explicit
};
int main(){
cout << "is_constructable:" << endl;
cout << "int => myobj2: " << is_convertible<int, myobj2>::value << endl;
cout << "is_convertible:" << std::endl;
cout << "int => myobj2: " << is_constructible<myobj2,int>::value << endl;
return 0;
}
/*
is_constructable:
int => myobj2: false
is_convertible:
int => myobj2: true
*/
我们看到依旧不能隐式转换所以第一个是false。但是我们可以使用int来构造myobj2 所以第二个是true。
注意一下参数顺序。能不能转换是第一个转到第二个。能不能构造是第二个构造第一个。
std::is_const
1
is_const<T>::value
用于判断T类型是否是被const修饰的类型。
- 若 T 为引用类型则
is_const<T>::value始终为false。检查可能为引用的类型的常性的正确方式是移除引用:is_const<typename remove_reference<T>::type>。- 原因是引用的
const限定符仅仅意味着不能通过引用参数修改值。 它仍然可以被其他方法修改。比如直接修改变量
- 原因是引用的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int main()
{
std::cout << std::boolalpha;
std::cout << "is_const:" << std::endl;
std::cout << "int: " << std::is_const<int>::value << std::endl;
std::cout << "const int: " << std::is_const<const int>::value << std::endl;
std::cout << "const int&: " << std::is_const<const int&>::value << std::endl;
std::cout << "const int* " << std::is_const<const int*>::value << std::endl;
std::cout << "int* const:" << std::is_const<int* const>::value << std::endl;
return 0;
}
/*
is_const:
int: false
const int: true
const int&: false
const int*: false 这里的false是因为指针本身非const。也就是顶层非const。
int* const:true 这里的true是因为指针本身是const。也就是顶层为const
*/
模拟简单实现
也是简单的匹配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template<typename _Tp>
struct my_is_const{
void func(){
cout <<"not const" << endl;
}
};
template<typename _Tp>
struct my_is_const<_Tp const>{
void func(){
cout <<"const" << endl;
}
};
my_is_const<int> a;
my_is_const<const int>b;
a.func(); //not const
b.func(); // const
std::ref, std::cref, std::reference_warpper
之前一直想整理一下这几个。这次一起探讨一下
在很多时候比如使用bind和thread这种一定会拷贝参数的标准库组件时,我们如果想要按照引用传递,就必须使用ref或cref包装一下。
一句话总结。
ref和cref都是reference_warpper的包装器。cref只是变成了带const的ref。所以下面不分析cref了。reference_warpper内部包含一个指向了原始对象类型的指针。其实他就是一个包含了一个指针的包装器对象。- 它有用户定义转换函数。
- 他还有一个
get()函数用于返回其原始对象的引用,通过这个方式可以像引用一样,内部修改的值可以传递到外面。
其实应该说
ref和cref是reference_warpper的辅助函数。std::reference_warpper其实是一种强别名. 参考资料来自这里 看下CPO的故事(3)的后半部分
ref 源代码
1
2
3
4
5
6
7
8
9
10
11
template<typename _Tp>
inline reference_wrapper<_Tp> ref(_Tp& __t) noexcept
{ return reference_wrapper<_Tp>(__t); }
template<typename _Tp>
void ref(const _Tp&&) = delete; //禁止接受右值
template<typename _Tp>
inline reference_wrapper<_Tp> ref(reference_wrapper<_Tp> __t) noexcept
{ return ref(__t.get()); }
- 我们可以一眼看出,
ref就是一个返回reference_wrapper的函数 - 因为禁止接受了形参为右值的参数。所以
ref不能包装右值。
1
std::ref(5);//不可以
ref的传入参数可以是一个普通的引用,也可以是另外一个reference_wrapper对象
reference_wrapper 源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
template<typename _Tp>
class reference_wrapper : public _Reference_wrapper_base<typename remove_cv<_Tp>::type> //这里去掉了CV。
{
_Tp* _M_data; //内部就是包含一个指向原始对象的指针。
public:
typedef _Tp type;
reference_wrapper(_Tp& __indata) noexcept
:_M_data(std::__addressof(__indata))
{
}
reference_wrapper(_Tp&&) = delete;
reference_wrapper(const reference_wrapper<_Tp>& __inref) noexcept
:_M_data(__inref._M_data)
{
}
reference_wrapper& operator=(const reference_wrapper<_Tp>& __inref) noexcept
{
_M_data = __inref._M_data;
return *this;
}
operator _Tp&() const noexcept //用户定义转换函数。使用了get
{ return this->get(); }
_Tp& get() const noexcept //get用于返回原始对象的引用。起到引用的效果。
{ return *_M_data; }
template<typename... _Args>
typename result_of<_Tp&(_Args&&...)>::type
operator()(_Args&&... __args) const
{
return __invoke(get(), std::forward<_Args>(__args)...);
}
};
- 该类继承于
_Reference_wrapper_base_ - 有一个类成员
_M_data,类型为所引用类型的指针。这个指针指向了原始对象。 - 第一个构造函数通过调用
std::__addressof函数,获得了指向引用参数的指针,并赋值给了_M_data(这也是为什么不支持右值引用的原因,因为取不到对应的地址)- 至于这里为什么要使用
std::__addressof,是因为如果有些类重载了operator &的话可能我们不能取到真实地址。使用这个函数不管是否重载了取地址操作符,都可以取到原始地址。具体细节不分析了。
- 至于这里为什么要使用
- 拷贝构造函数和赋值函数就只是简单地将
_M_data的值进行传递而已,没有什么特殊操作。都是常规 其余方法就是为了让
reference_wrapper展现出和普通的引用一样的效果而进行的运算符重载。- 比如重载了
operator ()可以让我们在reference_wrapper对象储存了一个可调用对象的时候,直接使用()调用其储存的可调用对象
1 2 3 4 5 6 7 8 9
void this_func(){ cout <<"called" << endl; } int main() { auto func_ptr = this_func; auto ref3 = ref(func_ptr); //ref3是一个reference_wrapper储存了一个函数指针 ref3();//调用。 }
- 比如有
get()可以获取一个原始对象的引用。 - 用户定义转换函数使得它支持了向原始类型的隐式类型转换。
- 比如重载了
举一个非常不太对劲的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
template <typename T>
void another_func(T a){
a.get() = 2000;
}
int main() {
int a = 1;
another_func(ref(a));
cout << a << endl; //修改为2000。
}
//或者是
void changeval(int& a){
a = 20000;
}
template <typename T>
void func(T a){
changeval(a); //因为有用户定义转换函数。这里的T本来是reference_wrapper类型的,但是可以隐式转换为原始类型。比如这里就是int&
}
int main() {
int a = 1;
func(ref(a));
cout << a << endl; //修改为20000
}
注意了。在这些情况下,reference_wrapper对象本身依旧是按值传递的。
https://blog.csdn.net/weixin_43798887/article/details/116562336
std::remove_reference
- 若类型
T为引用类型,则提供成员 typedeftype,其为T所引用的类型。否则type为T。
这个的实现比较简单。
1
2
3
4
5
6
7
8
9
10
11
12
template<class T>
struct remove_reference{
typedef T type;
};
template<class T>
struct remove_reference<T&>{
typedef T type;
};
template<class T>
struct remove_reference<T&&>{
typedef T type;
};
当T是&或者&&的时候,自然都会有每一个匹配的版本。都会让其T本身的类型成为其类型。也就是脱去引用。
std::remove_cv/remove_volatile/remove_const
- 第一个移除最顶层CV
- 第二个移除最顶层V
- 第三个移除最顶层C
如果忘了什么叫顶层,去杂记2搜“顶层”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int a = 200;
const int b = 200;
const int* ptr = &a;
int* const c_ptr = &a;
const int* const cc_ptr = &a;
using anothertype = remove_cv_t<const int>;
cout <<std::boolalpha;
cout << is_same_v<decltype(a), remove_cv_t<decltype(b)>> << endl;
cout << is_same_v<const int*, remove_cv_t<decltype(ptr)>> << endl;
cout << is_same_v<int*, remove_cv_t<decltype(c_ptr)>> << endl;
cout << is_same_v<const int*, remove_cv_t<decltype(cc_ptr)>> << endl;
/*
true
true
true
true
*/
- 第一个,移除了
b的最顶层const,变成了int - 第二个,移除了
ptr的最顶层const,但是ptr本身并非const,而是ptr指向的对象是const。所以此时移除无效。依旧是const int* - 第三个,移除了
c_ptr的最顶层const。这个c_ptr本身是const,所以移除后变成了int* - 第四个,移除了
cc_ptr的最顶层const。这个cc_ptr不仅本身是const,指向的对象也是const。由于仅移除最顶层,所以变成const int*
简单实现
依旧是非常直观的偏特化匹配
1
2
3
4
5
6
7
8
9
10
template< class T > struct remove_cv { typedef T type; };
template< class T > struct remove_cv<const T> { typedef T type; };
template< class T > struct remove_cv<volatile T> { typedef T type; };
template< class T > struct remove_cv<const volatile T> { typedef T type; };
template< class T > struct remove_const { typedef T type; };
template< class T > struct remove_const<const T> { typedef T type; };
template< class T > struct remove_volatile { typedef T type; };
template< class T > struct remove_volatile<volatile T> { typedef T type; };
std::address_of
1
2
3
4
template< class T >
T* addressof(T& arg) noexcept; //1
template <class T>
const T* addressof(const T&&) = delete; //2
- 获得对象或函数
arg的实际地址,即使存在operator&的重载 (1) - 右值重载被删除,以避免取
const右值的地址。(2) - 返回值是指向
arg的指针。
我们在reference_weapper源代码分析一节中提到了address_of。它的核心作用是取得对象或函数的真实地址。因为有时候可能你使用的operator&是被重载过的。比如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class Test
{
public:
int* operator&() //重载address-of也就是取址运算符
{
return &b;
}
int* a_addr()
{
return &a; //注意,这个&用的不是重载的。因为a是int类型,这句等于a.operator&(),也就是int自己的取址而不是这里Test的取址
}
int* b_addr()
{
return &b; //注意,这个&用的不是重载的。因为b是int类型,这句等于b.operator&(),也就是int自己的取址而不是这里Test的取址
}
private:
int a;
int b;
};
int main(int argc, char* argv[])
{
Test t;
std::cout << "&t.a:" << t.a_addr() << std::endl; //0x7ffe80a9fc10
std::cout << "&t.b:" << t.b_addr() << std::endl; //0x7ffe80a9fc14
std::cout << "&t:" << &t << std::endl; //0x7ffe80a9fc14 注意,这里变成了b的地址。
std::cout << "addressof(t):" << std::addressof(t) << std::endl;//0x7ffe80a9fc10
}
我们看到,直接对t.a和t.b取地址是正常的。但是使用了t的重载的operator&,由于我们让它取了t.b的地址,所以返回的一定是t.b的地址。但是我们用了addressof就可以避免这个问题。
实现分析
1
2
3
4
5
6
7
8
9
10
11
12
template<class T>
typename std::enable_if<std::is_object<T>::value, T*>::type addressof(T& arg) noexcept{
return reinterpret_cast<T*>(//第四步
&const_cast<char&>(//第二步和第三步。第三步单独指的取址&
reinterpret_cast<const volatile char&>(arg))); //第一步
}
template<class T>
typename std::enable_if<!std::is_object<T>::value, T*>::type addressof(T& arg) noexcept{
return &arg;
}
- 第一步,将
arg由类型T&强制转换为const volatile char&,这样做有两个作用:- 一是防止后面(第三步)使用
&操作符获取地址时触发原类型(即T)的重载操作(operator&),就像上面那个例子那样。 - 二是
reinterpret_cast不可以去掉原类型的const或volatile,但是可以合法的在原类型的基础上增加const或volatile, 所以,如果T原来就带有const或volatile的话, 通过reinterpret_cast去掉是不允许的, 因此需要加上const volatile来避免编译器报错, 也就是此时不用再管T是否本来就带有const或volatile属性了。- 可能会问为啥不直接
const_cast?char和T是无关类型,只能用reinterpret_cast - 可能会问为啥要
cast到引用&?因为如果cast到变量就会生成新变量,这样地址不就变了么?
- 可能会问为啥不直接
- 一是防止后面(第三步)使用
- 第二步,将前面转换得到的结果强制转换为
char&类型,此时如果转换成其它类型有可能会触发强制地址对齐的操作,这样的话真实地址就有可能会被改变了,最终造成程序错误。需要注意的是这个转换过程使用的是const_cast,可以顺便将前面留下的const和volatile属性给去掉了。 - 第三步使用
&符号将前面的结果的地址给取出来(此时已经不会触发重载了) - 最后一步使用
reinterpret_cast将前面获取到的地址转换回T*类型,并且此时也会保留T的const或volatile属性(如果有的话)
https://stackoverflow.com/questions/16195032/implementation-of-addressof
https://blog.csdn.net/weixin_43798887/article/details/117966866
重载取址运算符用在哪?代理类的时候会用到
参考more effective C++ 条款30 P.224
一般当一个对象内涵一个代理类,通过某些操作返回一个代理类对象的指针的时候,由于不同类型指针之间不存在天然的转换关系,所以这个时候需要重载一个取址运算符来自然化语义。让对一个代理类取址的时候取到的是一个我们真正想取地址的类型的地址。
但是非常不建议使用,原因参考Modern C++ design 7.6 P.170
std::invoke [C++17]
https://youtu.be/zt7ThwVfap0 非常好的视频。
std::invoke 是什么
invoke是C++17新出的功能。
我们在上面11.1提到了可调用对象。比如有函数指针,成员函数指针,std::function等. invoke让我们有一个更统一的方式来调用任何的可调用对象。
std::invoke 和 std::function 和 其他可调用对象的关系
1
2
3
template< class F, class... Args >
std::invoke_result_t<F, Args...>
invoke( F&& f, Args&&... args ) noexcept;
……
以参数
f调用可调用 (Callable) 对象。如同以INVOKE(std::forward<F>(f), std::forward<Args>(args)...)。此重载只有在std::is_invocable_v<F, Args...>为true时才参与重载决议。…….
标准文档一向不说人话。
具体就是:std::function可以包装其他的可调用对象。而std::invoke可以调用如std::function这样的可调用对象。
- 注意
invoke是有返回值的。
https://stackoverflow.com/questions/39398740/what-is-the-difference-between-stdinvoke-and-stdfunction
std::invoke 怎么用
std::invoke在模板类中调用成员函数指针的时候尤为有用。
看看语法
调用函数对象
1 2 3
invoke(func, args...); //等同于 func(args...);
调用成员函数指针(pointer to member function)
如果可调用对象是一个指向成员函数的指针,它会将
args...中的第一个参数当作this对象(不是指针)。Args...中其余的参数则被当做常规参数传递给可调用对象。具体原始调用方式在杂记2
1 2 3 4 5 6 7
invoke(pmf, obj, rest...);//通过对象调用 //等同于 (obj.*pmf)(rest...); invoke(pmf, ptr, rest...);//通过指针调用 //等同于 (ptr->*pmf)(rest...);
- 为了化简使用,有一个特殊例子。如果可调用对象是一个指向成员函数的指针,它会将
args...中的第一个参数当作this对象(不是指针)。Args...中其余的参数则被当做常规参数传递给可调用对象。否则,所有的参数都被直接传递给可调用对象。
调用成员变量指针 (pointer to member data)
具体原始调用方式在杂记2
1 2 3 4 5 6 7
invoke(pmd, obj);//通过对象调用 //等同于 obj.*pmd; invoke(ptr, obj);//通过指针调用 //等同于 ptr->*obj;
一点儿具体例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
//函数对象
template<typename _funcObj, typename... Args>
void test_func(_funcObj ptr, Args&&... args){
// ptr(args...);
std::invoke(ptr, forward<Args>(args)...); //注意加了forward
}
//成员函数指针,对象调用。
template<typename _Obj, typename _Ptr, typename... Args>
void test_memberfunc( _Ptr ptr, _Obj& obj, Args&&... args){
//(obj.*ptr)(args...);
std::invoke(ptr, obj, forward<Args>(args)...); //注意加了forward
}
//成员函数指针,指针调用。
template<typename _Obj, typename _Ptr, typename... Args>
void test_memberfunc_ptr(_Ptr ptr, _Obj* obj, Args&&... args){
//((*obj).*ptr)(args...);
std::invoke(ptr, obj, forward<Args>(args)...); //注意加了forward
}
1
2
3
4
5
6
7
8
9
10
11
12
myobj obj1(1);
function<void(int)> task = bind(&myobj::add, &obj1, placeholders::_1);
std::invoke(task, 5); //调用function包装的成员函数
test_memberfunc(&myobj::getval, obj1); //使用成员函数指针,对象调用
test_memberfunc(&myobj::add, obj1, 8);
test_memberfunc_ptr(&myobj::add, &obj1, 8); //使用成员函数指针,指针调用
test_func(&myobj::add, &obj1, 8); //使用提到的特殊例子,使用成员函数指针。会被特殊处理。
- 注意直接调用模板函数必须指明模板参数:
1
2
3
4
5
6
7
8
9
10
11
template<typename T>
T func(T obj){
cout << "called" << endl;
return obj;
}
int main() {
auto f = std::invoke(func<int>, 100); //必须显式指明<int>
return 0;
}
这里由于是直接调用一个模板函数。invoke没办法帮我们推导这个函数应该用哪个模板参数实例化。我们上面用到的都是包了一层的,也就是invoke的时候,invoke内的参数有确定类型。比如上面的ptr在传入invoke的时候,类型已经确定为_Ptr。而当前这里还需要推导,但是无法推导。所以必须显式指明。
std::invoke 源码和实现
目前有点看不懂
https://www.cnblogs.com/windpiaoxue/p/10009172.html
https://codechina.gitcode.host/programmer/cpp-update/3-C++17-features-spotlights-2.html#stdinvoke
std::invoke 什么时候用
- 非泛型编程没必要用,除非痛恨成员函数指针语法。
- 泛型编程可以使用,但是不要指定其
invoke的模板参数。把它留给invoke决定
实现invoke功能是非常困难的事情。
std::invoke 的陷阱,到底要不要使用forward
书中提到了,invoke中传递的参数不应该使用完美转发, 因为第一次调用可能会偷取相关参数的值(使用移动构造),导致随后的调用中出现错误。
但是如果一个对象是不可拷贝仅可移动的呢?比如unique_ptr,这时候就必须要使用forward了。来自这里
1
2
3
4
5
6
void p_2(unique_ptr<int> myptr){
cout <<"p_2 called"<< endl;
cout << *myptr << endl;
}
unique_ptr<int> ptrs(new int(10));
test_func(p_2, move(ptrs)); //外面记得也要移动
当然了,问题出现在这里。如果你无意间传递了一个右值进去:
1
2
3
4
5
6
7
8
9
10
11
12
void p_3(myobj x){
cout <<"p_3 called"<< endl;
cout << *x.val << endl;
}
test_func(p_3, myobj(234));
template<typename _funcObj, typename Args> //为了方便测试,这里不用变参列表了。
void test_func(_funcObj ptr, Args&& args){
// ptr(args...);
std::invoke(ptr, forward<Args>(args)); //如果这里使用了完美转发
cout << *args.val << endl; //args的右值特性被forward保留,触发移动构造。这里会段错误。
}
所以说,具体要不要用forward需要根据情况使用。
std::invoke的返回值
从函数签名中,我们看到了invoke是有返回值的。
1
2
3
4
5
6
7
8
9
10
11
12
template<typename T>
T func(T obj){
cout << "called" << endl;
return obj;
}
int main() {
decltype(auto) f = std::invoke(func<int>, 100); //f 类型是 int。刚才说过此处必须显示指明这个函数的模板参数。
cout << f << endl; //输出100
return 0;
}
- 之所以要用
decltype(auto)而非auto的原因是因为auto会导致类型退化。- 我们提到过,
auto一定会推导出返回类型为对象类型并且应用退化。 - 而
auto&或auto&&一定会推导为引用类型。 - 而
decltype(auto)则可以根据具体返回值的类型进行推导。
- 我们提到过,
- 那么为什么不用auto&&呢?因为
auto&&会延长临时对象的生命周期- 返回值是临时对象,纯右值,使用右值(此处顺带万能引用)引用会延长其生命周期。
我们看到了这玩意的返回值类型是:
1
2
template< class F, class... Args >
std::invoke_result_t<F, Args...>
那我们就要研究一下这个是个什么东西了。
std::result_of[C++11~17]/invoke_result[C++17]
- 首先强调一点。对于如
F(args...)这样的东西,由于2.6部分提到的原因,我们把它看成是是以Args...为参数而以F为返回类型的函数类型。这一点非常重要,因为后面会遇到这个错误,同时它也是为什么我们在C++20后弃用result_of。 - 第二点:你不能问编译器一个函数对象的返回类型是什么。因为其返回类型很可能和使用的参数有关。所以你需要问:使用这一堆参数调用这个函数对象的时候的返回类型是什么。
1
2
3
4
template< class >
class result_of; // 不定义
template< class F, class... ArgTypes >
class result_of<F(ArgTypes...)>;
- 作用是在编译时推导INVOKE 表达式的返回类型。
- 这个INVOKE表达式是广义的可调用类型。
- 成员
type是以参数ArgTypes...调用可调用 (Callable) 类型F的返回类型。仅若F能以参数ArgTypes...在不求值语境中调用才得到定义。 - 再次强调,F和ArgTypes都必须是类型!!!!
我们看几个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
struct F{
int operator ()(int i) {
return i;
}
};
int f(int i){
return i;
}
int main(){
cout << std::boolalpha;
cout << is_same_v<std::result_of_t<F(int)>, int><< endl; //可以
cout << is_same_v<std::result_of_t<f(int)>, int><< endl; //不可以
return 0;
}
- 为什么
F(int)可以但是f(int)不可以?这里非常重要 - F是类型。仿函数是对象。它是类类型。所以
F是个类型。而f不是类型,f是函数。- 上面其实不严谨。具体一点:
F(int)是一个函数类型。这个类型指的是一个函数它接受一个int参数,返回F类型对象。很明显这不是F类型,同时没有F到int的转换,为什么这样做可以?原因在2.6写了。也就是它会把F和int类型拆开。最后会变成declval<F>()(declval<int>())这个样子。但是这样做有个非常大的问题,也是为何result_of在C++20被弃用。
- 上面其实不严谨。具体一点:
1
2
cout << is_same_v<F, F><< endl; //可以。F是类型。我们可以有F obj
cout << is_same_v<f, f><< endl; //不可以。f不是类型。f是函数
- 所以为了获取到函数类型,有几种方案。第一种是使用
using定义一个函数引用别名或函数指针别名即可。
1
2
3
4
5
6
7
8
9
using f_ref = int(&)(int); //函数引用
using f_ptr = int(*)(int); //函数指针
using fdef = int(int); //函数类型
cout << is_same_v<std::result_of_t<f_ref(int)>, int><< endl; // OK
cout << is_same_v<std::result_of_t<f_ptr(int)>, int><< endl; // OK
int(*pf)(int) = f;
cout << is_same_v<std::result_of_t<pf(int)>, int><< endl; // 错误
cout << is_same_v<std::result_of_t<fdef(int)>, int><< endl; // 错误
为什么第三种错误?因为using f_ptr = int(*)(int); 是定义类型别名。而int(*pf)(int) = f;是声明一个变量。说到底,f_ptr依旧是类型,而pf变成了函数指针本身,而函数指针是实体,并不是类型。pf的类型是int(*)(int)。
为什么第四种错误?这里有个非常关键的语法层面的问题。 对于如F(args...)这样的东西,由于2.6部分提到的原因,我们把它看成是是以 Args... 为参数而以 F 为返回类型的函数类型。再次回到函数头,我们能看到class result_of<F(ArgTypes...)>;这个声明。
所以我们现在result_of_t<fdef(int)>进去之后会变成啥呢?会变成一个以fdef为返回类型,以int为参数的函数类型。那么fdef是啥呢?fdef是一个函数类型。C++函数不是一等公民,不能传入和返回函数,但是可以传入和返回函数的指针或引用。
所以这个不能跑的原因是,我们无法定义一个返回函数的函数。而为什么用函数指针或引用的时候能跑?因为我们可以定义一个返回函数指针或函数引用的函数。
- 第二种是使用
decltype。我们这里拆解来看
1
2
3
4
using f_1 = decltype(f); //decltype函数名
using f_2 = decltype((f)); //decltype函数表达式加括号了。相当于上面的f_ref
cout << is_same_v<std::result_of_t<f_1(int)>, int><< endl; //不可以
cout << is_same_v<std::result_of_t<f_2(int)>, int><< endl; //可以
为什么第一个f_1不可以?我们说过,F必须是一个类型而不能是函数。而且此时f_1是函数类型。所以f_1(int)又变成了一个返回函数的函数。所以还是有问题。第二个可以是因为函数加括号后decltype的是表达式的type,所以返回引用类型。所以可以。
- 第三种是直接使用函数模板推导让其退化为函数指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
template<typename T>
void func(T f){
//T会被推导为int (*)(int)。等同于上面的f_ptr
std::puts(__PRETTY_FUNCTION__);
cout <<boolalpha;
cout <<is_same<typename result_of<T(int)>::type, int>::value <<endl;
}
int sample(int){
return 0;
}
int main(){
func(sample);
}
总结解决方案:
使用using直接定义函数指针或函数引用。
使用decltype的时候,把函数做为表达式传入。
或者是在使用的时候加一个
&(依旧相当于变为函数引用),比如
1
2
3
4
cout << is_same_v<std::result_of_t<f_1&(int)>, int><< endl; //可以
//其实就相当于变为函数引用
cout << is_same_v<f_1&,int(&)(int)><< endl; //相当于函数引用类型
cout << is_same_v<f_1,int(int)><< endl; //相当于函数类型
- 直接使用函数模板推导让其退化为函数指针。
进入invoke_result的世界
我们已经提过了result_of由于设计上的问题导致的诡异行为。所以invoke_result的定义是这样的
1
2
template< class F, class... ArgTypes>
class invoke_result;
F不能是函数类型或数组类型(但能是到它们的引用);- 若任何
Args拥有“T的数组”类型或函数类型T,则它被自动调整为T*; F或任何Args...都不能是抽象类类型;- 若任何
Args...拥有顶层 cv 限定符,则舍弃之; Args...均不可为 void 。
最明显的两点区别是:
- 首先,不会把模板参数合成为一个函数类型了。也就是不会产生
F(args...)的问题。 - 其次,明确限制F不能是函数类型。
所以使用的时候就不再是跟着括号了,而是逗号即可。
1
2
is_same<std::result_of_t<f_2(int)>, int>;// result_of_t
is_same<std::invoke_result_t<f_2, int>, int>; // invoke_result_t
其他资料如更细节的语法等:
https://stackoverflow.com/questions/54065009/using-stdinvoke-to-call-templated-function
https://blog.csdn.net/tcy23456/article/details/110583343
https://blog.csdn.net/hanxiaoyong_/article/details/120618869
例子
比如下面我们的想法是对一个有T类型元素的vector容器vec,对其每一个元素调用可调用对象c,然后将返回值存入新vector,排序后并返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
template<typename T, typename Callable>
auto transform_sort(const vector<T>& vec, Callable c){
vector<decay_t<result_of_t<Callable&(const T&)>>> ret; //查看对元素施加callable对象后,返回的值类型。然后创建这个类型的容器
for(const T& item: vec){ //对每一个元素
ret.push_back(invoke(c, item));//使用invoke施加callable,然后存入ret
}
sort(ret.begin(), ret.end());
return ret;
}
int my_callable(const string& s){
return s.size();
}
int main(){
vector<string> my_vec{"a","abcd","abc","ab"};
for(const auto& item: transform_sort(my_vec, my_callable)){
cout << item << endl;
}
/*
输出
1
2
3
4
*/
return 0;
}
result_of_t<Callable&(const T&)>>这里的细节是使用了Callable&而非Callable。也就是解决方案2。这样避免了我们上面提到的诡异行为。- 使用
decay_t的原因是,可能callable的返回类型是引用或带有cv限定的。有这样元素的的容器是不合法的。 invoke的语法不多讲。第一个是可调用对象,第二个是其参数。- 最后的结果我们看到了,我们的
callable目的是返回这个字符串的长度。所以整体目的是检查vector内每一个字符串的长度,然后存到vector中并返回。
建议
建议不要使用result_of,除非必须场合。
std::decay
之前总谈到它,现在不整理不行了。不然看不懂书了。
1
2
template< class T >
struct decay;
- 对类型
T应用左值到右值(lvalue-to-rvalue)、数组到指针(array-to-pointer)和函数到指针(function-to-pointer)的隐式转换,移除 cv 限定符,并定义结果类型为成员typedef type。正式而言:- 若
T指名“U的数组”或“到U的数组的引用”类型,则成员typedef type为U*。- 强制给数组和数组引用类型退化为指针。
- 否则,若
T为函数类型F或到它的引用,则成员typedef type为std::add_pointer<F>::type。- 强制给函数和函数引用类型退化为指针
- 否则,成员
typedef type为std::remove_cv<std::remove_reference<T>::type>::type- 强制给普通成员移除引用和CV限定符。
- 若
看看原理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
template<typename _Tp>
class decay
{
typedef typename remove_reference<_Tp>::type __remove_type; //先去掉引用
public:
typedef typename __decay_selector<__remove_type>::__type type; //然后使用下面的 __decay_selector
};
template<typename _Up,
bool _IsArray = is_array<_Up>::value,
bool _IsFunction = is_function<_Up>::value>
struct __decay_selector; //主模板,判断是不是数组或函数类型。!!!注意这里is_function判断的是函数类型而非函数指针类型。
template<typename _Up>
struct __decay_selector<_Up, false, false> //如果不是数组也不是函数,则直接去掉CV即可。第一步已经去掉过引用了。
{ typedef typename remove_cv<_Up>::type __type; };
template<typename _Up>
struct __decay_selector<_Up, true, false> //如果是数组类型,则直接弄成*就行
{ typedef typename remove_extent<_Up>::type* __type; };
template<typename _Up>
struct __decay_selector<_Up, false, true> //如果是函数类型,
{ typedef typename add_pointer<_Up>::type __type; }; //使用add_pointer转换为指针类型。这里需要细说。后面会有介绍
- 其实从上面我们也发现了。主要核心就是把三种情况分开讨论,使用三个偏特化的模板进行匹配。
- 比较需要注意的一点是,针对数组类型退化的时候,
CV特性会被保留。 - 至于
add_pointer,我们下面说。
https://blog.csdn.net/weixin_43798887/article/details/118311126
std::void_t [C++17]
这部分需要结合6.6部分来看。
1
2
template <class... _Types>
using void_t = void;
- 功能:能够配合我们检测到应用SFINAE(替换失败并不是一个错误)特性时出现的非法类型。换句话说,给进来的类型
_Types必须是一个有效的类型,不能是一个非法类型。- 它可以判断一个类内是否有个特定的类型别名、成员函数或成员变量
这个东西看起来贼鸡肋,我们分析分析它的简单使用。假设现在我们的目的是判断一个类内是否有一个叫type的类型
判断是否存在成员类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
struct A {
using mytype = int; //类A含有mytype类型
};
struct B{
using mytype = void; //类B也含有mytype类型
};
template<typename T1 , typename T2 = void > //主模板,第二个参数默认值是void,非常重要
struct has_type_member : std::false_type { //主模板继承false_type
};
template<typename T1> //针对第二个参数进行偏特化
struct has_type_member<T1, std::void_t<typename T1::mytype>>: std::true_type { //偏特化继承true_type,并且使用void_t进行类型判断。
};
int main(){
auto f = has_type_member<float>::value;
auto a = has_type_member<A>::value;
auto b = has_type_member<B>::value;
cout << f << endl;
cout << a << endl;
cout << b << endl;
/*
输出
0
1
1
*/
}
- 我们解析一下标准例子。为什么是这个结果。
- 首先,我们拥有类
A和类B。他们都有一个mytype类型。- 其次,我们的判断类的主模板继承自
false_type,第二个参数的默认值是void - 判断类的偏特化继承自
true_type,针对第二个参数进行偏特化。
- 其次,我们的判断类的主模板继承自
- 我们在6.6中强调了:当模板参数有默认值的时候,它会被隐式填进去,而不是被忽略。它依旧存在。也就是我们要把默认值理解为:虽然我们不需要显式指定,但是它依旧存在。
1
2
3
auto f = has_type_member<float>::value; //扩展为has_type_member<float, void>::value;
auto a = has_type_member<A>::value; //扩展为has_type_member<A, void>::value;
auto b = has_type_member<B>::value; //扩展为has_type_member<B, void>::value;
我们首先看
f。我们使用<float>的时候会由于有默认参数被扩展为<float, void>。然后开始进行匹配。首先选用特化模板。T1会被替换为float。然后在第二个模板参数std::void_t<typename float::mytype>>进行匹配的时候,由于float没有mytype类型,不合法。此时会发生替换失败。SFINAE发生。所以这个模板会被丢弃。回退到主模板,应用到主模板的void。因为我们提供的是<float,void>。而主模板完美匹配。这个时候实例化出来的是继承自false_type的。所以是0- 然后我们看
a。我们使用<A>的时候会由于有默认参数被扩展为<A, void>。然后开始进行匹配。首先选用特化模板。T1会被替换为A。然后在第二个模板参数std::void_t<typename A::mytype>>进行匹配的时候,发现A有type类型。合法。所以此时通过决议。我们看到了,此时void_t的推导通过,void_t就是void。此时整个std::void_t<typename A::mytype>>会变为void。- 关键的来了。我们提供的是
<A,void>,主模板可以匹配。同时特化版本也可以匹配,因为此时也被替换成了<A,void>。但是由于下面的特化版本更特化,我们知道全特化版本 > 特化版本 > 主模板。所以此时选择了偏特化版本,继承了true_type所以是1
- 关键的来了。我们提供的是
- b同a。
为什么必须要用void_t?
我们看下面的例子:
我们假设类A和类B和上面的代码一样,只修改我们的判断类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
template<typename T1 , typename T2 = void > //主模板,第二个参数默认值是void,非常重要
struct has_type_member : std::false_type { //主模板继承false_type
};
template<typename T1> //针对第二个参数进行偏特化
struct has_type_member<T1, typename T1::mytype>: std::true_type { //偏特化继承true_type,注意这里不用void_t,直接判断其type
};
int main(){
auto f = has_type_member<float>::value;
auto a = has_type_member<A>::value;
auto b = has_type_member<B>::value;
cout << f << endl;
cout << a << endl;
cout << b << endl;
/*
输出
0
0 //这个变了!!
1
*/
}
- 第一个f原因同上。我们不多解释。
- 我们来看
a。A会被扩展为<A,void>。然后开始匹配。首先选用特化模板。我们发现A类有mytype,所以正确推导。但是,A::mytype是int类型,导致这时候模板实例化出来的会变成has_type_member<A, int>。但是我们模板实参给的是<A,void>。此时发现不匹配。于是该版本被丢弃。然后发现主模板可以匹配。所以此时会选用主模板而非特化模板。主模板继承自false_type。此时自然是0。 b的原因和上面一样,但是由于B::mytype是void,实例化出来的<B,void>和 实参<B,void>匹配。所以选择了偏特化版本。此时自然是1。
如果像6.6那样更换了主模板的默认值,会发生什么?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
template<typename T1 , typename T2 = int > //主模板,此时第二个参数默认值是int
struct has_type_member : std::false_type { //主模板继承false_type
};
template<typename T1> //针对第二个参数进行偏特化
struct has_type_member<T1, std::void_t<typename T1::mytype>>: std::true_type { //偏特化继承true_type,并且使用void_t进行类型判断。
};
int main(){
auto f = has_type_member<float>::value;
auto a = has_type_member<A>::value;
auto b = has_type_member<B>::value;
cout << f << endl;
cout << a << endl;
cout << b << endl;
/*
输出
0
0 //这个变了
0 //这个也变了
*/
}
- f理由同上不解释。
- 我们来看a。
A会被扩展为<A,int>。然后开始匹配。首先选用特化模板。我们发现A类有mytype,所以正确推导。这时候模板实例化出来的会变成has_type_member<A, void>。但是,我们模板实参给的是<A,int>。此时发现不匹配。于是该版本被丢弃。然后发现主模板可以匹配。所以此时会选用主模板而非特化模板。主模板继承自false_type。此时自然是0。 - 对于b,
B会被扩展为<B, int>。然后开始匹配。首先选用特化模板。我们发现B类有mytype,所以正确推导。这时候模板实例化出来的会变成has_type_member<B, void>。但是,我们模板实参给的是<B,int>。此时发现不匹配。于是该版本被丢弃。然后发现主模板可以匹配。所以此时会选用主模板而非特化模板。主模板继承自false_type。此时自然是0。
搭配decltype判断是否存在成员变量
上面一节是判断是否存在类型别名。这一节看一下判断是否存在成员变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
struct A {
int val = 234; //类A含有val变量
};
struct B{
float val2 = 345; //类B不含有val变量,但是含有val2变量
};
template<typename T1 , typename T2 = void > //主模板,第二个参数默认值是void,非常重要
struct has_type_member : std::false_type { //主模板继承false_type
};
template<typename T1> //针对第二个参数进行偏特化
struct has_type_member<T1, std::void_t<decltype(T1::val)>>: std::true_type { //偏特化继承true_type,并且使用void_t且搭配decltype进行类型判断。
};
int main(){
auto f = has_type_member<float>::value;
auto a = has_type_member<A>::value;
auto b = has_type_member<B>::value;
cout << f << endl;
cout << a << endl;
cout << b << endl;
/*
输出
0
1
0
*/
}
- 核心原理就是我们在这里需要搭配
decltype来对某一个变量的名字进行判断是否合法,但不推导。如果有这个变量则类型合法。如果没有则非法。 - 额外注意!!!在模板内的decltype表达式是不推导语境。我们需要等到特化被生成后,编译器才会开始进入推导语境。也就是目前仅仅对T进行替换但不推导表达式的实际类型。
- 我们直接看
a。A被扩展为<A,void>。然后选择偏特化版本开始匹配。此时进入模板参数推导阶段,所有的T1被替换为A。但是注意,我们说了decltype此处不推导。只是替换。所以此时特化为:
1
2
3
template<> //针对第二个参数进行偏特化
struct has_type_member<A, std::void_t<decltype(A::val)>>: std::true_type {
};
- 此时模板参数已被推导完毕,进入下一阶段。此时
decltype是可评估语境。由于类A有成员变量val,所以此时decltype(A::val)是合法的。此时它会变成int。我们说过任何经过void_t判断合法的东西都会使整个void_t参数变为void。所以此时特化成
1
has_type_member <A,void>
和上面一样,虽然主模板和特化版本都匹配,但还是匹配最特殊的,这里就是偏特化版本,自然就是true。
b和a的原理几乎一致。唯一区别是进行偏特化后,B没有val成员变量。所以decltype非法。所以整个void_t也非法。触发SFINAE特性移出重载集合,转为匹配主模板。
判断是否存在成员函数
我们下面讲了declval。
- 这个是第一种方式,通过
<成员函数的返回值>是否合法来判断。限制是函数不能有参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
struct A {
void funcA();
};
struct B{
void funcB();
};
template<typename T1 , typename T2 = void > //主模板,第二个参数默认值是void,非常重要
struct has_type_member:std::false_type { //主模板继承false_type
};
template<typename T1> //针对第二个参数进行偏特化
struct has_type_member<T1, std::void_t<decltype(std::declval<T1>().funcA())>>: std::true_type { //使用decltype和declval进行成员函数判断。
};
int main(){
auto f = has_type_member<float>::value;
auto a = has_type_member<A>::value;
auto b = has_type_member<B>::value;
cout << f << endl;
cout << a << endl;
cout << b << endl;
/*
输出
0
1
0
*/
}
- 具体不细说了。核心还是判断类型是否存在也就是
decltype内的表达式是否合法。注意两点 - 第一点
declval是函数模板。所以别忘了调用一下。 - 第二点是,
decltpe此处我们的目的是通过函数返回值来判断是否存在函数。由于declval是用来判断函数返回值的,所以必须要“调用”一下。所以这里必须得让他成为表达式。原因在这里和这里 - 有一个问题,如果这个成员函数有参数咋办?这里就不能这么用了。因为如果签名需要参数,但是我们没给,就非法。所以这时候就需要通过成员函数地址来判断了。
https://blog.csdn.net/baidu_41388533/article/details/109700163
https://blog.csdn.net/ding_yingzi/article/details/79983042
https://stackoverflow.com/questions/27687389/how-does-void-t-work
- 另一种方式,通过
<取成员(函数)地址>是否合法来判断。- 这个方式同样可以检测是否有成员变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
struct A {
A() = delete;
void myfunc(int s){
//类A含有myfunc
}
};
struct B{
void myfuncB(){
//类B不含有myfunc,但是含有myfuncB
}
};
template<typename T1 , typename T2 = void > //主模板,第二个参数默认值是void,非常重要
struct has_type_member:std::false_type { //主模板继承false_type
};
template<typename T1>
struct has_type_member<T1, std::void_t<decltype(&T1::myfunc)>>: std::true_type { //通过成员函数地址判断。OK
};
int main(){
auto f = has_type_member<float>::value;
auto a = has_type_member<A>::value;
auto b = has_type_member<B>::value;
cout << f << endl;
cout << a << endl;
cout << b << endl;
/*
输出
0
1
0
*/
}
有没有其他写法?
先说结论,以下三种写法是同一个效果:
1
2
3
void_t<decltype(expression)>; //1
decltype(void(expression)); //2
decltype(expression, void()); //3
- 第一种就是经典写法。
- 第二种是表达式计算完毕后
void转型。所以如果表达式合法,最后的类型结果也是void - 第三种是利用逗号表达式。第一个表达式计算完毕后,如果合法,就丢弃第一个结果继续计算
void()。最后的类型结果也是void。
所以如果换成上面的例子:
1
2
3
4
5
6
7
8
9
template<typename T1>
struct has_type_member<T1, std::void_t<decltype(&T1::myfunc)>>: std::true_type { //1
};
template<typename T1>
struct has_type_member<T1, decltype(void(&T1::myfunc))>: std::true_type { //2
};
template<typename T1>
struct has_type_member<T1, decltype(&T1::myfunc, void())>: std::true_type { //3
};
std::declval
declval基本用于推导成员函数的返回类型。千万注意
1
2
template<class T>
typename std::add_rvalue_reference<T>::type declval() noexcept;
有没有发现这个函数的声明和我们上面的testfunc很像?都是只要声明不要定义,骗过编译器。
函数模板
std::declval()可以被用作某一类型的对象的引用的占位符。该函数模板没有定义,因此不能被调用(也不会创建对象)。因此它只能被用作不会被计算的操作数(比如 decltype 和 sizeof)。也因此,在不创建对象的情况下,依然可以假设有相应类型的可用对象。
书里的话非常抽象。我们看看标准文档怎么说的:
将任意类型
T转换成引用类型,使得在decltype说明符的操作数中不必经过构造函数就能使用成员函数。通常在模板中使用
std::declval,模板接受的模板实参通常可能无构造函数,但有同一成员函数,均返回所需类型。注意,
std::declval只能用于不求值语境,且不要求有定义;求值包含此函数的表达式是错误。正式的说法是 ODR 使用此函数的程序非良构。
这里就非常明确了。declval可以被当做占位符的意思是。declval<T>就相当于创建了一个T类型的对象。但是由于实际并不创建,所以我可以通过不创建实际对象来使用某一个成员函数。所以,使用declval创建虚拟占位符意味着不调用构造。所以在某些时刻会节约其调用成本。但是它只能返回类型,所以它只能用在不求值语境中,比如decltype。(我们已经反复强调decltype并不真正求值。我们在杂记4中详细介绍了decltype的不求值语境。)
1
2
3
4
5
6
7
8
9
10
struct A {
A() = delete;
int foo();
};
int main() {
decltype(A().foo()) foo_no; // 不OK因为构造函数无法访问
decltype(std::declval<A>().foo()) foo = 1; // OK
decltype(A&&.foo())foo = 1; //理论上和上面的相等,但是不能编译
}
我们下面那一行在理论上等于上面那一行。因为decltype不求值,所以这里可以编译通过。因为我们的目的是查看foo这个函数到底返回什么类型。这个函数也不会被调用。所以你看我们根本没有给foo提供定义。他们只关心类型。也就是说,我们告诉编译器:请假设我们现在有这个对象,那么请看看使用这个对象和这些参数来调用这个成员函数的时候,返回值是什么类型。
- 注意一下,
declval是一个函数,所以记得要调用一下
再强调一次,不要花时间思考为什么两行语义相等但是第二行不通过。只要编译器认为它是值就可以了。不要仔细思考decltype是如何被实现的。
关于为啥declval要添加右值引用
必须添加引用是因为可以使用不完整类型。比如数组那种int[10]直接按照值返回是不行的。使用右值引用是因为可以正确施加引用折叠以避免改变类型。
对于可引用的类型,其返回类型总是相关类型的右值引用,这能够使
declval适用于那些不能够正常从函数返回的类型,比如抽象类的类型(包含纯虚函数的类型)或者数组类型。因此当被用作表达式时,从类型
T到T&&的转换对declval<T>()的行为是没有影响的:其结果都是右值(如果T是对象类型的话。上面decltype笔记2.3),对于右值引用,其结果之所以不会变是因为存在引用折叠。
- 所以要注意,如果希望返回类型不是一个引用,记得使用
decay
https://stdrc.cc/post/2020/09/12/std-declval/#%E4%B8%BA%E4%BB%80%E4%B9%88%E8%BF%94%E5%9B%9E%E5%BC%95%E7%94%A8
https://stackoverflow.com/questions/25707441/why-does-stddeclval-add-a-reference
https://stackoverflow.com/questions/28532781/how-does-stddeclvalt-work
- 另外一点要注意:在
noexcept异常规则中提到,一个表达式不会因为使用了declval而被认成是会抛出异常的。当declval被用在noexcept运算符上下文中时,这一特性会很有帮助(参见第 19.7.2节)。
如何理解 declval
在实际使用中,我们只需要理解为declval<T>()是告诉编译器假装在这里我们有一个T类型的对象。我们忽略掉它是引用的事实,忽略掉它的实现(添加右值引用)。这看起来怪异也无所谓。因为它只能用在不求值语境。
- 在不求值语境中,任何函数调用都只需要有声明即可,并不必须提供定义。所以不求值语境中重要的是类型,而不是实例。在整个不求值的语境中,都是一堆类型在进行推导。压根没有值在这里计算。所以实例无所谓。
所以我们说过:必须添加引用是因为可以使用不完整类型。比如数组那种int[10]直接按照值返回是不行的。使用右值引用是因为可以正确施加引用折叠以避免改变类型。所以说,如果不考虑这些奇怪的场景,只考虑简单,最基本的例子,你甚至可以直接写成这样:
1
2
template<class T>
T declval() noexcept;
所以我们可以理解为declval也是一种类型萃取。尤其是在不求值语境中帮我们进行推理。
同时,很多需要SFINAE的时候都需要让表达式内嵌套一个表达式。什么意思?比如这个is_polymophic的实现:
1
2
3
4
5
6
7
8
9
10
11
12
template<class T, class> //主模板
struct IP_impl : false_type {
};
template<class T> //偏特化
struct IP_impl<T, decltype(dynamic_cast<void*>(declval<remove_cv_t<T>*>()))> : true_type {
};
template<class T>
struct is_polymorphic : IP_impl<T, void*> { //外层。注意这里第二个参数必须是void*
//原因是因为如果是void,就算是多态也会匹配到主模板。
//因为我们提供的第二个参数是void,但是如果满足多态,第二个参数会被偏特化模板推导为void*,这时候就不满足了
//然后就会fallback到主模板。
};
- 这里我主要想强调一下为什么必须
declval。我们先不要管remove_cv_t。首先dynamic_cast是可以转换成void*的。但是想使用dynamic_cast则必须要虚函数表。所以只要有虚函数表,就是多态类。回到declval。如果我们这里直接使用dynamic_cast<void*>(T*)可以吗?不可以。因为dynamic_cast的括号里需要表达式。T*是类型,不是表达式。如果我们换成(T*)nullptr可以,但是某些编译器会warning。所以在这里,declval不仅帮助我们获得了一个虚拟对象,更是满足了一些要求提供表达式的场合。- 在理解过程中,我们忽略掉
declval<T*>()会变成T*&&类型的这件事。语义上虽如此,但是不影响程序执行。
- 在理解过程中,我们忽略掉
- 说回来,我们上面提到了,甚至可以写成返回
T的declval。在这个例子中就满足。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
template<typename T>
T fuckval() noexcept; //随便写一个
template<typename T, typename>
struct ip_jmpl:false_type{
};
template<typename T>
struct ip_jmpl<T, decltype(dynamic_cast<void*>(fuckval<T*>()))>:true_type{ //换成fuckval完全没问题。
void f(){
std::puts(__PRETTY_FUNCTION__);
}
};
template<typename T>
struct ip_po : ip_jmpl<T, void*> {
};
来自这里
https://stackoverflow.com/questions/28532781/how-does-stddeclvalt-work
为啥有的declval用引用类型,有的不用?
比如这段代码:
1
2
3
4
5
6
7
8
9
else if constexpr (_Reversed_subrange<_Ty> == 1) {
using _It = decltype(_STD declval<_Rng&>().begin().base());
return {_St::_Subrange_sized,
noexcept(subrange<_It, _It, subrange_kind::sized>{
_STD declval<_Rng&>().end().base(), _STD declval<_Rng&>().begin().base(),
_STD declval<_Rng&>().size()})};
} else if constexpr (_Can_reverse<_Rng>) {
return {_St::_Reverse, noexcept(reverse_view{_STD declval<_Rng>()})};
}
答案是declval会应用正常引用折叠。会在某些情况让你得到意想不到的结果。
1
2
3
4
5
6
7
8
9
10
11
12
struct A {};
struct B {};
struct C {
A f() && { return A{}; }
B f() & { return B{}; }
};
int main() {
static_assert(std::is_same_v<A, decltype(std::declval<C>().f())>);
static_assert(std::is_same_v<B, decltype(std::declval<C&>().f())>);
}
来自这里
std::add_pointer
1
2
template< class T >
struct add_pointer;
- 若
T为引用类型,则提供成员 typedeftype,其为指向被引用类型的指针。- 也就是直接换成指针
- 否则,若 T 指名对象类型、无 cv 或引用限定的函数类型或(可有 cv 限定的) void 类型,则提供成员 typedef
type,其为类型T*- 注意这里:如果是对象类型,无CV或引用限定的函数类型或(可有 cv 限定的) void 类型。
- 也就是给对象或函数换成指针类型
- 否则(若 T 为 cv 或引用限定的函数类型),提供成员 typedef
type,其为类型T。- 注意这里,如果是有CV或引用限定的函数类型。
- 也就是这时候它还是
T,并不添加指针。
通过add_pointer来找到另一种SFIANE的方法(void_t的替代品。也就是函数模板的SFINAE)
在add_pointer的模拟实现中,有这样的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
namespace detail {
template <class T>
struct type_identity { using type = T; }; // 或使用 std::type_identity (C++20 起)
template <class T>
auto try_add_pointer(int) -> type_identity<typename std::remove_reference<T>::type*>;
template <class T>
auto try_add_pointer(...) -> type_identity<T>;
} // namespace detail
template <class T>
struct add_pointer : decltype(detail::try_add_pointer<T>(0)) {};
- 为什么这里会有一个
try_add_pointer(int)和try_add_pointer(...)?- 首先,这是一个函数。它的返回类型是
type_identity<typename std::remove_reference<T>::type*>这个东西。 - 我们替换
T然后先找特化版本。如果这个实参的传入让后面的尾置返回类型合法,推导成功就自然而然选择这个特化版本。 - 如果这个实参的传入导致后面的尾置返回类型非法,推导失败,会触发SFINAE。这时候这个特化版本就会被丢弃。由于
...能够接受任何类型的任何数量的参数,(就像我们上面8.4里面提到的一样)所以其他任何导致特化版本非法的使用都会被匹配到这个通用版本。 - 所以说,这里到底是
int还是float不重要。传入1还是0也不重要。
- 首先,这是一个函数。它的返回类型是
举一个不太好的但是能解释原理的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
struct A {
typedef int mytype;
};
struct B{
typedef int mytypea;
};
template <class T>
auto try_add_pointer(T) -> typename T::mytypea{
cout <<"no" << endl;
}
template <class T>
auto try_add_pointer(...) -> typename T::mytype{
cout <<".." << endl;
}
int main(){
A obj;
B obj1;
try_add_pointer<A>(obj1); //匹配到..
try_add_pointer(obj1); //错误
try_add_pointer<B>(obj); //错误
}
- 首先注意一点,可变参数
...是最低优先级。 - 为何第一个匹配到
..而第二个错误? - 第一个能成功的原因是,首先我们指定了函数模板是
A,所以T换成A。进入特化版本,A没有mytypea。此时甚至都不必考虑obj1是B类型和T不匹配 的问题,特化直接被丢弃。注意,这里不考虑隐式转换。看1.2部分。- 下一步,注意看,我们的变参包并没有指明类型,也就是变参包的类型是真正的任意。此时没办法进行推导。因为尾置返回类型的
T压根没有一个参照。入参没有类型,T从何来? - 所以我们这里有显式指明模板参数类型。这里我们显式指明
T为A。然后发现A有mytype,所以匹配成功。选择泛化版本。
- 下一步,注意看,我们的变参包并没有指明类型,也就是变参包的类型是真正的任意。此时没办法进行推导。因为尾置返回类型的
- 所以第二个错误的原因是
T无法推导。变参包并没有指明类型,也就是变参包的类型是真正的任意。此时没办法进行推导。因为尾置返回类型的T压根没有一个参照。入参没有类型,T从何来?- 如果想修复这个错误,那就变成
auto try_add_pointer(T...) -> typename T::mytype{, 加一个T让形参参与推导即可
- 如果想修复这个错误,那就变成
- 第三个错误的原因是指明类型为
B,T换成B,进入特化版本。B虽然有mytypea,但是和指明的入参类型不符合。所以特化版本被丢弃。- 此时看
...版本,我们指明T为B,但是B没有mytypea,所以这个泛化版本也无法匹配。最终错误。
- 此时看
所以正常应该这么写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
struct A {
typedef int mytype;
};
struct B{
typedef int mytypea;
};
template <class T>
auto try_add_pointer(T) -> typename T::mytypea{
cout <<"no" << endl;
}
template <class T>
auto try_add_pointer(T...) -> typename T::mytype{ //让...参与类型推导
cout <<".." << endl;
}
int main(){
A obj;
B obj1;
try_add_pointer(obj); //OK 不指明模板参数类型。输出..
try_add_pointer(obj1); //OK 不指明模板参数类型。输出no
}
- 这里都可以了是因为
A类型虽然没有mytypea,但是可以匹配到泛化版本。因为有mytype obj1是B类型,这时候因为没有像上面那样子指明类型导致冲突,所以T自然被推导为B。同时有mytypea。自然可以。
https://stackoverflow.com/questions/57506069/a-question-regarding-the-implementation-of-stdadd-pointer
std::conditional
1
2
3
4
template<bool B, class T, class F>
struct conditional { using type = T; };
template<class T, class F>
struct conditional<false, T, F> { using type = F; };
- 提供成员 typedef
type,若B在编译时为true则定义为T,或若B为 false 则定义为F。
实现也很简单。没什么多说的。
- 注意,如果
T或F之一是ill-formed,则整个conditional表达式也会是ill-formed—来自这里
CRTP
先简单介绍,之后慢慢看。
- CRTP的一个最明显的特点就是把派生类作为基类的模板参数
std::type_identity (C++20)
这个是C++20提案的一个小工具. 我们看下它的实现:
1
2
3
4
template <typename T>
struct type_identity {
using type = T;
};
这个东西看起来没什么用. 但是它主要作用是防止某一个参数类型参与类型推导. 核心原理是使用了不推导语境的一条规则:
用有限定标识指定的类型的 嵌套名说明符(作用域解析运算符 :: 左侧的所有内容)
我们看一个例子
1
2
3
4
5
template <typename T>
T add2(T a, T b) {
return a + b;
}
auto sum2 = add2(0.5, 1); // 不可以
因为参数类型被第一个参数推导为double 所以第二个参数类型也必须为double 因为模板参数类型推导不允许隐式类型转换, 所以会推导失败.
如果我们使用type_identity
1
2
3
4
5
template <typename T>
T add(T a, typename type_identity<T>::type b) {
return a + b;
}
auto sum = add(0.5, 1); // T is "double" OK
这样就可以了. 只不过第二个参数可以被隐式转换为了double
第一个参数的类型决定了T是什么类型,其他所有人都必须遵守。我们可以使用它来指定第二个参数是不可推断的
另一个在任务队列中常见的情况:
1
2
3
4
5
6
7
8
9
void enqueue(std::function<void(void)> const& work) {
cout << __PRETTY_FUNCTION__ << endl;
// dosomething
}
template <typename... Args>
void enqueue(std::function<void(Args...)> const& work, Args... args) {
enqueue([=] { work(args...); });
}
这里其实就是一个任务包装器. 把带函数和其参数打包到一个std::function当做一个任务.
如果现在我这样执行, 会有错误:
1
enqueue([](int v) { std::cout << v; }, 42);
原因就是参与了类型推导. std::function和lambda是两种不同类型, 尽管lambda可以转换为std::function. 这个时候就可以使用我们的type_identity 因为这个类型推导失败并不能代表什么, 同时我们很希望忽略掉它.
1
2
3
4
5
template <typename... Args>
void enqueue(typename type_identity<std::function<void(Args...)>>::type const& work, Args... args) {
cout << __PRETTY_FUNCTION__ << endl;
enqueue([=] { work(args...); });
}
参考:
blog来自这里 .可查看文章内的bonus chatter
点击这里查看完整原始proposal
点击这里查看cppreference. 在[不推导语境]一节中的1)
杂项
类成员函数不可以既是虚函数又是模板函数 12.1.1
- 首先简单来说,虚函数是动态多态。模板属于静态多态。这里不能动静结合。
- 其次,我们知道了函数模板在编译的时候会看哪些地方调用了。根据T的不同,每一份T都会导致实例化出一份T类型的函数。这就导致了会有多个入参类型不同的成员函数。但是我们又知道虚函数的虚函数表必须预先确定。而此时父类看不到子类的模板虚函数到底有几个版本,难不成都写一遍?
- 另一个原因是如果我们有模板虚函数,那么编译器为了确定类的虚函数表的大小,就必须要知道我们一共为该成员模板函数实例化了多少个不同版本的虚函数。显然编译器需要查找所有的代码文件,才能够知道到底有几个虚函数,这对于多文件的项目来说,代价是非常高的。
- 也就是说,如果这样做的话,虚函数表的确定时间就需要从编译器推迟到链接期。因为编译期指的是我不需要看具体实现。我只要发现你是
virtual我就可以把你放到表内。如果支持模板虚函数,那么就需要链接的时候把每一个实现都扫一遍然后再整理后放入虚函数表。
为什么类模板有偏特化没有重载,但是函数模板没有偏特化有重载?
问题也是答案。因为类模板没有重载所以有偏特化。因为函数模板有重载所以没有偏特化。
关于偏序 (partial order)
偏序适用于函数模板。也适用于类模板或变量模板。
我们提到过,当可行函数集中所有的函数都是函数模板的时候,这时候要选择最特殊的那一个。
比如
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template <typename T>
void func(T a){ //主模板
cout <<"main" << endl;
}
template <typename T>
void func(T* a){ //重载模板
cout << "overload" << endl;
}
int main(){
int* p;
func(p); //输出overload
}
//注意,调用的时候,如果调用第一个,因为传入的是int*,所以第一个里面的T会被推导为int*
//如果调用第二个,因为传入的是int*, 而里面又已经有了个*所以T就只被推导为int。
为什么我们认为下面的比上面的更特殊?我们用到了偏序的具体步骤
- 先选择两个函数模板,
T1和T2 - 用假设的唯一类型
X取代模板T1的参数 - 用被
X取代后的T1的参数列表,带入T2,看T2是否是一个有效的模板。忽略所有的隐式转换。 - 反过来,先用
X取代T2的参数,再把T2的参数列表带入T1,看看T1是否有效。 - 如果一个模板的参数比如
T1对于另外一个模板T2是有效的,但是反之不成立,那么就说这个模板T1不比T2更特例化。也就是可能T2比T1更特例化。如果这两个模板的参数都可以相互代替,就说它们具有相同的特例性,这样会引起编译器混淆。
所以我们有总结:
- 对于一个模板,特定类型的参数比一般类型的参数,更具有特例性
- 带有
T*的模板比T的模板具有特例性。因为一个假设的类型X*也可以被认为是T类型的, 相反一个有效的T类型参数,可能不是X*类型的。 const T比T更特例化,道理同上。const T*比const T更特例化,理由也是一样的。
https://stackoverflow.com/questions/18283851/template-specialization-in-case-of-multiple-base-templates-in-c/18283933?noredirect=1#comment26823443_18283933
https://www.youtube.com/watch?v=NIDEjY5ywqU
https://blog.csdn.net/weixin_30294295/article/details/94781059
https://zhuanlan.zhihu.com/p/390783543
关于不要显式全特化函数和函数全特化的问题
假如我们有下面的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
template<typename T> // (1) - 主模板
string getTypeName(T){
return "unknown";
}
template<typename T> // (2) - 重载自 (1) 的主模板。 针对指针类型的模板重载
string getTypeName(T*){
return "pointer";
}
template<> // (3) - (2) 的显式全特化。针对int指针类型的显式全特化
string getTypeName(int*){
return "int pointer";
}
// getTypeName2
template<typename T> // (4) - 主模板
string getTypeName2(T){
return "unknown";
}
template<> // (5) - (4) 的显式全特化。 针对int指针类型的显式全特化
string getTypeName2(int*){
return "int pointer";
}
template<typename T> // (6) - 重载自 (4) 的主模板。 针对指针类型的模板重载
string getTypeName2(T*){
return "pointer";
}
int main(){
cout << '\n';
int* p;
cout << "getTypeName(p): " << getTypeName(p) << '\n';
//输出getTypeName(p): int pointer
cout << "getTypeName2(p): " << getTypeName2(p) << '\n';
//输出getTypeName2(p): pointer
cout << '\n';
}
这段代码中,我们有意的把针对指针的模板重载和全特化调换了顺序写成了两个不同的函数。
我们看到了。分别输出getTypeName(p): int pointer 和 输出getTypeName2(p): pointer 。
但是这不对啊?看getTypeName,为什么使用了全特化版本而不是模板重载?我们不是说了全特化版本不参与重载决议吗?
我们要理解到底决议的是谁。要看匹配顺序。
针对第一个
getTypeName函数调用,过程是这样的:在一开始,重载解析会考虑 (1) 和 (2)。第三个全特化版本此时不参与重载决议。
template<typename T> std::string getTypeName(T);- (1) - 主模板
template<typename T> std::string getTypeName(T*);- (2) - 重载自 (1) 的主模板
template<> std::string getTypeName(int*);- (3) - (2) 的显式全特化
- 显式全特化版本此时不参与,所以(2) 更合适,因此第一阶段选择 (2)。
- 但是随后看到了(3),我们发现针对我们合成出来的
T为int类型的函数也就是(2),还有一个似乎可以比较一下。而且此时两个函数都是模板函数。并且其中一个是主模板合成出的。所以这时候(3)被加入到了重载决议中,开启偏序部分。 - 此时通过偏序,(3)此时被认为是(2)的显式全特化。和(2)相比,(3)的类型更为特化,所以此时选择了(3)。所以编译器不会从(2)合成一个,而是选取一个已经存在的(3)。这里看一下上面偏序推导和下面的“关于为什么说函数模板不是…”
但是针对第二个
getTypeName2函数调用,过程是这样的:- 在一开始,重载解析会考虑 (4) 和 (6)。
template<typename T> std::string getTypeName2(T);- (4) - 主模板
template<> std::string getTypeName2(int*);- (5) - (4) 的显式全特化
template<typename T> std::string getTypeName2(T*);- (6) - 重载自 (4) 的主模板
- 显式全特化版本此时不参与,所以(6) 更合适,因此选择 (6)。
- 然而此时(5) 被认为是 (4) 的显式全特化而不是(6)的显式全特化。而且因为 (4) 没有被选中,所以重载解析也不会考虑(5)。最后选择(6)。
- 为什么?此时(5) 被认为是 (4) 的全特化而不是(6)的显式全特化。因为在进行到(5)的时候,编译器唯一能看到的只有(4)而没有(6)。[也就是在(5)眼里,只有(4)在作用域内。(6)此时还没有被看见。因为显式全特化的(5)没有名字,这时候必须依附于一个主模板。所以说(5)只能看见(4)所以认为(5)是(4)的显式全特化]
- 在一开始,重载解析会考虑 (4) 和 (6)。
所以我们在这里可以看出来模板特化的混乱程度。所以尽可能不要特化模板函数,而是采用普通函数。也就是不要对函数模板进行特化,而要使用非泛型函数。
所以我们在这里把(3)和(5)函数头的全特化指示template<>删掉,则一切工作正常。都会输出int pointer。因为普通函数总是优先于模板函数。
https://zhuanlan.zhihu.com/p/561977606
- 也就是说,如果在很多个函数模板中挑选,编译器会首先选中一个基础模板。然后针对这个模板再一轮搜索来查看是否有更加匹配的。
为了好玩,再看个像狗一样的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
template<typename T> // (7) - 主模板
string getTypeName3(T){
return "unknown";
}
template<> // (8) - (7) 的显式全特化。 针对int指针类型的显式全特化
string getTypeName3(int*){
return "int pointer";
}
template<typename T> // (9) - 重载自 (7) 的主模板。 针对指针类型的模板重载
string getTypeName3(T*){
return "pointer";
}
template<> // (10) - (9) 的显式全特化。 针对int指针类型的显式全特化
string getTypeName3(int*){
return "another int pointer";
}
int main(){
cout << '\n';
int* p;
int a = 0;
cout << "getTypeName3(p): " << getTypeName3(p) << endl; //输出another int pointer
cout << "getTypeName3(a): " << getTypeName3(a) << endl; //输出 unknown
// cout << '\n';
}
- 就是由于上面的原因。(8)被认为是(7)的显式全特化。因为当时它只能看到,依附于(7)。而(10)被认为是(9)的显式全特化。因为(10)可以看到(9)。而且因为(8)是(7)的显式全特化,我们不考虑(7)所以也不考虑(8)。考虑(9)然后通过偏序发现(10)比9更特殊。最后选择了(10)
什么时候要显式全特化而不是重载?
一个是std::swap。
另外一个是阻止某些隐式转换。比如:
1
2
3
4
5
6
7
8
9
10
11
template <class T>
void testf(T); //注意,这里没有定义!!
template <>
void testf(int) {
//一些内容
}
int main(){
testf(3);//可以
testf(3.3); //不行
return 0;
}
当只有void foo(int)时,以浮点类型调用会发生隐式转换,这可以通过特化来阻止。正常调用int没问题,但是如果入参是float,会匹配到主模板。但是主模板没有定义,自然出现问题。
https://segmentfault.com/q/1010000013299483
关于重载决议 (overload resolution)
https://mp.weixin.qq.com/s/lbPdLfusUqiO-I59PcXrCQ
这个cppcon关于重载解析的视频非常好。
- 如果函数只有返回值不同,无法重载。
- 因为普通函数返回值不算做函数签名。因为返回值是否使用是可选的。
- 如果函数只有形参的默认值不同,无法重载。
因为形参默认值不算作函数签名。
还有一种情况。就是多个函数有相同数量的不带默认值的参数
1 2
int f(); int f(int x = 123);
这种也会二义性。因为在选择可行函数集的时候:
If the candidate function has more than
Mparameters and theM+1‘st parameter and all parameters that follow have default arguments, it is viable. For the rest of overload resolution, the parameter list is truncated atM.M = 调用时实际提供的实参数量
如果候选函数的形参比 M 多,但从第 M+1 个形参开始,所有形参都有默认值,那么这个函数依然是可行函数(viable function)。
在后续的重载决议中,编译器会临时把这个函数的参数表截断到前 M 个形参,然后再和其他候选函数进行优劣比较。
这个时候第二个函数给截断了,所以比较的时候这两个函数都可以是0参数。
- 如果函数的区别只有一个是
static一个不是,无法重载。
重载决议只看声明,不看定义。
所以如果声明中包含一些计算或判断,比如萃取,decltype之类,它依旧会计算。
- 在一个函数调用的备选方案中包含函数模板时,编译器首先要决定应该将什么样的模板参数用于各种模板方案,然后用这些参数替换函数模板的参数列表以及返回类型,最后评估替换后的函数模板和这个调用的匹配情况(就像常规函数一样)
- 也就是类型推导发生在重载决议前。
第一步 确定候选函数集
确定候选集: 在重载函数集中,根据作用域和函数名,来选择同名同域的重载函数
候选函数集特点:
- 该集合中的函数的声明,在该调用点可见
- 也就是,和被调函数在同一作用域下
- 该集合中的函数,与被调函数同名
- 也就是,重载函数的函数名都一致
- 该集合中的函数的声明,在该调用点可见
第二步 选出可行函数集
在确定了候选函数集之后,根据被调函数的参数列表,选择出对应的可行函数集
- 参数列表信息 = 参数个数 + 参数类型
可行函数集特点:
- 每个实参的类型要与对应的形参类型相同,或者是能够转换成形参的类型
- c++支持隐式类型转换!
- 参数个数与被调函数个数匹配
- 参数类型可以隐式转换,但是参数个数相同是最低标准
- 每个实参的类型要与对应的形参类型相同,或者是能够转换成形参的类型
在这个过程中会逐个移除无效的候选函数。无效的候选函数被称为not viable。如果没有找到可行函数集,则编译器将报告无法匹配函数的错误。在这一过程中,仅检查参数个数是否匹配。具体能否转换以满足条件在下一步。
第三步 寻找最佳匹配 Ranking阶段和tie-breaker阶段
- 从可行函数集合中选出所有与本次调用最匹配的函数(注意,并不一定是完全一致的函数)
- 编译器将依次检查可行函数集中的每一个函数
- 依次检查每一个函数的形参,与被调函数的实参
- 寻找到最匹配的那个可行函数。
- 匹配成功条件
- 如果可行函数集合中只有一个函数并且可以匹配,成功调用。
- 如果可行函数集合中有多个函数可能匹配,进入tie breaker阶段:
- 该可行函数每个实参的匹配都不劣于其他可行函数需要的匹配
- 该可行函数至少有一个实参的匹配优于其他可行函数提供的匹配
- 有且只有一个可行函数满足上述两个原则
- 注意: 有且只有一个可行函数满足,如果有多个可行函数同时满足,就会造成函数调用的二义性
https://blog.csdn.net/jiewaikexue/article/details/120089550
https://blog.csdn.net/qq_53558968/article/details/122757998
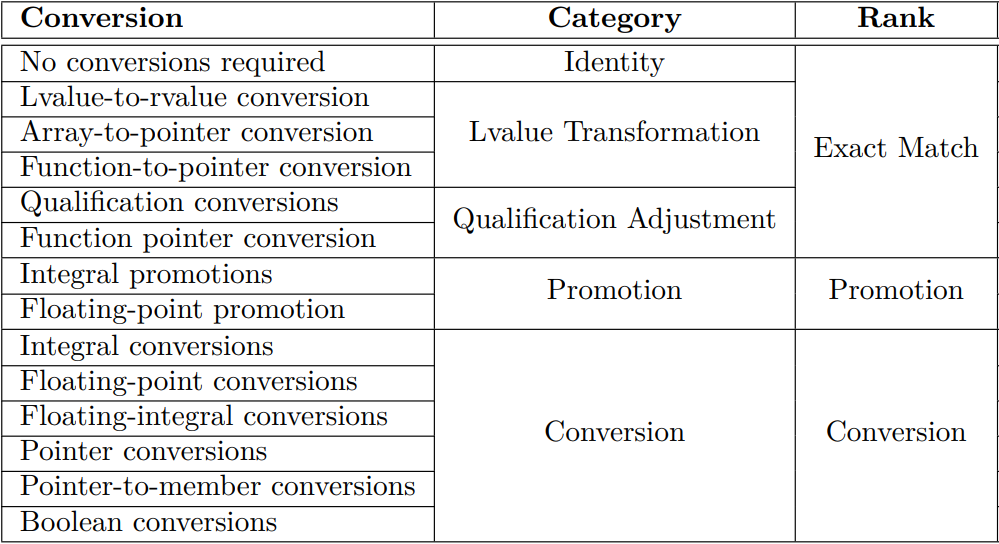
- 上图是重载中的决胜局tie-breaker的匹配表。它们的匹配优先级也是自上往下的,即Exact Match比Promotion更好,Promotion比Conversion更好,可以理解为完全匹配、次级匹配和低级匹配。
- 关于lvalue-to-rvalue转换,看这里
我的理解是,涉及到临时对象的都符合左值到右值转换。比如函数值传递,值返回。因为编译器期望的是值,而不是内存位置,要从内存位置中把值提取出来,就会发生 lvalue to rvalue conversion
int a = b;=右边期望的就是值,最终b还是会有 lvalue to rvalue conversion。不把b的值取出来,那就不叫赋值了。注意,class type的情况下并不是lvalue to rvalue conversion。因为类对象的
a = b调用的是a.operator=()—-来自群讨论



- 关于Promotion中的 Integral promotion整数提升,有如下几种情况
- 核心意思是,任何小于
int的都可以提升为int。- 任何其余的都叫转换。比如
int到long。这不是提升,是转换。
- 任何其余的都叫转换。比如
short提升为intunsigned short,unsigned char提升为unsigned int或intbool提升为intchar提升为int或unsigned int- 还有一些其他例子
- 核心意思是,任何小于
- 关于Promotion中的 Floating-point promotion 浮点提升,只有一种情况
float提升为double
- 关于Conversion中的Integral Conversion 整数转换,核心意思是任何整数类型都可以互相转换。如果该转换列在“整数类型提升”下,那么它是提升而非转换。

在这张图中,我们看到了上面表格里面的五种转换的对应级别。
但是上面表格只到numeric conversion为止。但是在其下面还有两种:用户定义转换和省略号转换
- 用户定义转换比任何标准转换的级别都要低。
- 用户定义转换的定义是:从 任意类型 隐式转换至 任意类型
- 比如从
const char*到string - 这一步多是调用构造函数或用户定义转换函数。我们提到过的functional-style cast
- 省略号转换是最低级别的。也就是最后最后才考虑。所以经常被用作fallback。
Ranking是查找所有的匹配函数。如果有多个匹配,则进入tie-breaker阶段找到最匹配的,或者是,隐式转换次数(步数)最少的一个。
我们看一个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
// A
void doThing_A(double, int, int) { } // overload 1
void doThing_A(int, double, double) { } // overload 2
int main() {
doThing_A(4, 5, 6); // which overload is called?
}
// B
void doThing_B(int, int, double) { } // overload 3
void doThing_B(int, double, double) { } // overload 4
int main() {
doThing_B(4, 5, 6); // which overload is called?
}
- A 编译器会报错,二义性。B是3。为什么?
针对A,编译器考虑的是:针对重载1,传入的第一个参数不能完美匹配。这时候第一个函数已经输了。然后考虑重载2,传入的第二个参数也不能完美匹配,所以重载2也输了一次。同时这两个函数在同一个级别上。都需要conversion,且没有一个tie breaker可以解决这个问题. 因为此时的两个候选函数的参数的隐式转换中没有哪一个是优于另一个的. 这时候产生了二义性。这种属于double lose
针对B,编译器考虑的是:针对重载1和2,传入的第一个参数都可以完美匹配。针对第二个参数,只有第一个重载可以完美匹配。这个时候开始比较第三个参数。二者一致。由于重载1比重载2多赢了一次,进入tie breaker阶段然后选择了重载1。因为我们提到过:
该可行函数每个实参的匹配都不劣于其他可行函数需要的匹配
- 该可行函数至少有一个实参的匹配 优于其他可行函数提供的匹配、
- 有且只有一个可行函数满足上述两个原则
再看一个例子
1
2
3
4
5
6
void doThing_D(int &) { } // overload 1
void doThing_D(int) { } // overload 2
int main() {
int x = 42;
doThing_D(x); // which overload is called?
}
- 为什么二义性?
- 它们都是完美匹配。因为绑定参数到引用不被认为是一种转换。这就是我们经常犯的错误。如果函数有一个值传递和一个左值引用传递,两个版本,则一定会二义性。这种属于double win
人话分析一下就是double win和double lose都不行, 也不能二者各赢一次各输一次。这样就会二义性。必须要有一个比另一个赢得多。
如何解决重载决议中的二义性?
- 增加或移除一些重载
- 给构造函数增加
explicit修饰符以避免隐式类型转换(杂记2) - 函数模板可以使用SFINAE
- 实例化无效的函数模板直接会被丢弃,不会放入重载集。
- 在函数调用前使用显式类型转换。
- 比如使用C或C++风格cast
- 使用构造函数
有时候编译器选择的最佳函数并不是我们所期望的。这个时候的解决办法之一是想办法让其有二义性,然后编译器就会给你一大堆很他妈长的重载决议错误。给你一个candidate列表。
什么时候使用重载,什么时候使用模板?
- 如果针对某一个特定类型,需要有特定的实现,这个时候使用重载。
- 比如
string的构造函数
- 比如
- 如果针对所有类型都有相同的实现,这个时候使用模板。
- 比如
std::sort。
- 比如
极力避免同时使用函数重载和函数模板。
关于为什么说函数模板不是函数。函数模板在其被实例化的时候会合成一个特化的函数
假设我们有如下函数模板:
1
2
3
4
5
template<typename T>
void func(T const&);
func(42); // void func<> (int const&);
func('a'); // void func<> (char const&);
我们在两次函数调用的时候,编译器会使用函数模板帮助我们合成注释里面的函数实例。
- 在实例化过程中,可能会发生当前要实例化的东西已经存在或发生过等效调用。所以如果存在适当的预先的全特化版本,那么那个全特化版本会被编译。(这里就是上面的“关于不要全特化…“部分的例子的原因)
- 也就是有全特化版本了,调用的时候就不再合成,而是直接使用全特化版本。
- 如果没有已经存在的全特化版本,那么编译器此时必须实例化这个全特化版本。编译器会从主模板当中复制它的定义(definition),然后进行适当替换。这就是我们说为什么显式全特化只是一个替换的定义,而不是一个替换的声明。
- 我们想象一下,由于显式全特化的函数模板不参与重载解析。除非重载决议选择最佳匹配的主函数模板后,才检验它的特化以查看最佳匹配者。所以就是假设现在编译器合成出了一个
T是int的函数声明。我们此时有一个显式全特化了int的函数。这时候会考虑显式全特化的那个。所以他会把全特化版本的函数实例化。然后把合成的函数声明给全特化的这个函数拼接到一起。这就是为什么全特化函数没有独立名字。因为它的声明是编译器合成的,定义是我们自己写的。这两个不能分开,自然全特化版本也没有需要独立名字的意义。
限定名、非限定名
限定名(qualified name),故名思义,是限定了命名空间的名称。看下面这段代码,cout和endl就是限定名:
1
2
3
4
5
#include <iostream>
int main() {
std::cout << "Hello world!" << std::endl;
}
cout和endl前面都有std::,它限定了std这个命名空间,因此称其为限定名。
如果在上面这段代码中,前面用using std::cout;或者using namespace std;,然后使用时只用cout和endl,它们的前面不再有空间限定std::,所以此时的cout和endl就叫做非限定名(unqualified name)。
依赖名、非依赖名
依赖名(dependent name)是指依赖于模板参数的名称,而非依赖名(non-dependent name)则相反,指不依赖于模板参数的名称。看下面这段代码:
1
2
3
4
5
6
7
8
9
10
template <class T>
class MyClass {
int i;
vector<int> vi;
vector<int>::iterator vitr;
T t;
vector<T> vt;
vector<T>::iterator viter;
};
因为是内置类型,所以类中前三个定义的类型在声明这个模板类时就已知。然而对于接下来的三行定义,只有在模板实例化时才能知道它们的类型,因为它们都依赖于模板参数T。因此,T, vector<T>和vector<T>::iterator称为依赖名。前三个定义叫做非依赖名。
更为复杂一点,如果用了typedef T U; U u;,虽然T没再出现,但是U仍然是依赖名。由此可见,不管是直接还是间接,只要依赖于模板参数,该名称就是依赖名。
typedef 和作用域解析运算符:: 和 嵌套类
我们很难把class和namespace联系起来,但是这两个在抽象层次上其实是一个概念。
作用域解析运算符::的作用就是制定某一个范围。但是一旦用在了嵌套类或者类内的typedef,我们就很难理解这层含义。
我们都知道直接访问类静态成员必须使用作用域解析运算符::
但是我们如果要通过作用域解析运算符访问非静态成员,可以吗?当然可以。只不过需要通过对象访问。
举个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
class test{
public:
class testinner{ //嵌套类
public:
int _val;
testinner(){}
testinner(int x):_val(x){}
};
test(){}
typedef int testdef;
int s;
};
int main()
{
test::testinner tt1 = test::testinner(5); //OK
test::testinner tt2; //OK 访问嵌套类
test::testdef tt3 = 5; //OK 访问typedef。
test::s = 5; //不行。直接访问的成员必须是静态成员。
test t;
t.test::s = 5; //OK 通过对象访问,但是还是脱裤子放屁加了作用域解析运算符。
return 0;
}
这里我们可以理解为我们需要访问的typedef和嵌套类在test类的命名空间下。我们必须要告知编译器这东西在哪,所以需要通过作用域解析运算符去访问。
至于typedef和嵌套类是否是一个类的成员,我没有查到确切的说法。如果说他们不是成员吧,但是有成员的属性。要是说是成员吧,我们也可以直接访问。但是也有人说嵌套类的static是隐式的。也有人把嵌套类当做一个namespace 来看待。所以我的理解是不要把嵌套类和typedef看做类成员。假设他们可以直接调用即可。
如果嵌套类没有在外部类中实例化,则实例化外部类的时候不会实例化嵌套类内容。
最后说一下必须显式使用typename的情况。
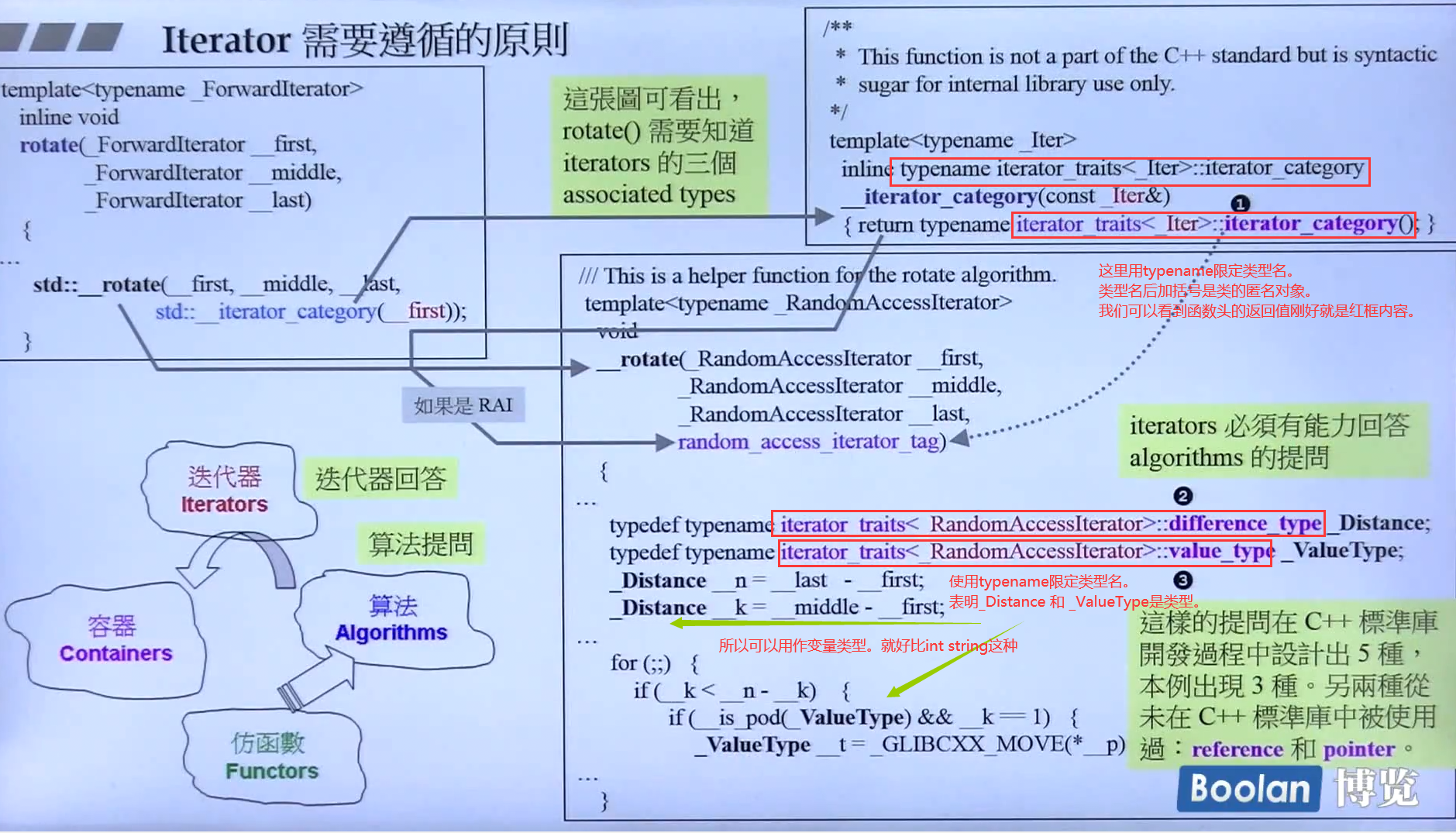
来几个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class test{
public:
struct obj{
int _sb;
};
obj s;
int _val;
test(){}
test(int x):_val(x){}
test(int x, int y){
_val = x;
s._sb = y;
}
};
template<typename T>
void func(){
test t(5,8);
typename T::obj* ptr = &t.s;
//这里我们的意思是有一个指针ptr指向了T类里面的obj类型的对象。翻译成人话也就是ptr是一个T::obj类型的指针。但是如果有一个T类里面的obj是一个变量,如static int obj = 8
//那么这就变成了变量乘法。会有歧义。所以使用typedef显式告知编译器 T::obj不是一个变量,而是一个类型。
cout << ptr->_sb << endl;
}
可能还不够?再来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
typedef iterator_traits<T>::value_type value_type_anothername;
//这句话的意思是value_type_anothername是在模板类iterator_traits中的 变量 value_type的别名。
//所以如果有
value_type_anothername name = "foward_iterator";
//这样是不行的。因为value_type_anothername是一个变量不是类型。
//所以我们需要加typedef告知编译器这个是类型
typedef typename iterator_traits<T>::value_type value_type_anothername;
//这句话的意思是value_type_anothername是iterator_traits<T>::value_type这个 类型 的别名。
//所以这样可以有
value_type_anothername name = "foward_iterator";
//因为value_type_anothername 是个类型。就好比int string这种。
还不够?再来:
这是我们前文的例子。但是为什么这里不需要加typedef呢?
1
2
3
4
5
6
7
8
9
class test{
public:
typedef int inputtype;
};
int main(){
test::inputtype x = 4; //这句话等于告诉你 test类下面的inputtype这个东西是int
}
先送上大佬文章一篇:https://feihu.me/blog/2014/the-origin-and-usage-of-typename/
由于test已经是一个完整的定义,因此编译期它的类型就可以确定下来,也就是说test::inputtype这些名称对于编译器来说也是已知的。
可是,如果是像T::inputtype这样呢?T是模板中的类型参数,它只有等到模板实例化时才会知道是哪种类型,更不用说内部的inputtype。通过前面类作用域一节的介绍,我们可以知道,T::inputtype实际上可以是以下三种中的任何一种类型:
- 静态数据成员
- 静态成员函数
嵌套类型
typename的作用,简单理解就是强制告诉编译器namespace::objname这个东西是一个类型名而不是变量名。
所以在模板类中,如果想要告知编译器一个使用了::作用域解析运算符的东西是类型,而不是变量,就需要加typename
如果直接把这个东西当做一个类型来进行变量的声明,那就不需要搭配
typedef如果需要把这个东西当做一个类型来赋予一个别名,那就需要加
typedef
所以,像这样就必须要加:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class test{
public:
test(){}
typedef int inputtype;
};
template<typename T>
class test1{
public:
test1(){};
typedef typename T::inputtype inputtype; //注意这里,T::inputtype是个类型。比如test::inputtype 就是 int类型
};
In a declaration or a definition of a template, including alias template, a name that is not a member of the current instantiation and is dependent on a template parameter is not considered to be a type unless the keyword typename is used or unless it was already established as a type name, e.g. with a typedef declaration or by being used to name a base class.
在模板(包括别名模版)的声明或定义中,不是当前实例化的成员且取决于某个模板形参的名字不会被认为是类型,除非使用关键词 typename 或它已经被设立为类型名(例如用 typedef 声明或通过用作基类名)。
特殊成员函数能否是函数模板
- 拷贝构造,拷贝赋值,移动构造,移动赋值。这四个成员函数模板不会被当成真正的特殊成员函数。如果只声明模板,编译器依旧会合成默认的。然后调用默认的。
- 构造函数是个例外。
假设我们有这个类:
1
2
3
4
5
6
7
8
9
10
11
class C{
public:
template<typename T>
C(const T&){
cout <<"called" << endl;
}
};
int main(){
C obj1(10); //called
C obj2(obj1); //啥也没有
}
我们第一反应是啥:这个函数看起来非常像拷贝构造对吧。但是它不是。它是个构造函数模板。
拷贝构造有严格定义:
类
T的拷贝构造函数是首个形参是 T&、const T&、volatile T& 或 const volatile T&,而且要么没有其他形参,要么剩余形参均有默认值的非模板构造函数。这里形参必须是引用,如果按照值传递就会有悖论。比如为了调用复制构造函数,必须复制一下。为了复制,必须调用复制构造函数……
我们这个函数他明显形参类型不是C。所以他不会被当做拷贝构造函数。
所以自然而然,符合我们上面说的。我们第一个符合这个构造函数特征。然后类型会被推导。然后
C obj1(10);会被正常调用。然而第二个需要调用拷贝构造的时候,我们等于没有提供,我们此时使用的是编译器合成的。自然啥也没打印。
然而构造函数模板不可显式指定模板参数类型。因为显式模板实参列表跟在函数模板名之后,并且因为转换成员函数模板和构造函数成员函数模板是在不使用函数名的情况下调用的,所以没有办法为这些函数模板提供显式模板实参列表。
注意,C obj1(10);这个东西不是调用构造函数。而是直接初始化。我们称之为调用构造函数是因为直接初始化就是在找构造函数。
https://www.cnblogs.com/silentNight/p/5545643.html
https://stackoverflow.com/questions/3960849/c-template-constructor
构造函数模板的延伸
我们有如下代码:
1
2
3
4
5
6
7
8
struct foo {
foo() = default; // 去掉会无法编译。
// 我们有用户定义的构造函数, 所以编译器不会隐式生成默认构造函数。所以去掉会无法编译。
template<typename T>
foo(){
cout <<"ctor" << endl;
}
};
首先, 构造函数可以是模板. 但是此处这个构造函数模板永远无法被调用, 原因是:
此处编译器永远无法推导出
T的类型. 因为此时T不在推导上下文中(废话你都没有用到它)。同时也不存在为构造函数显式指定模板实参的方法,因为它们不会通过函数名调用.
所以说: 这个函数模板从未被”调用”过. 调用需要加引号的原因是, 因为其实不是没有调用, 而是不存在这个函数. 因为这个函数模板没有被实例化. 所以从符号角度来讲压根没有这个函数.
如何“显式”指定构造函数模板的模板参数?使用std::in_place_type_t
参考自Raymond Chen的这篇文章,和这篇后续文章 简而言之就是多一个参数。
1
2
3
4
5
6
7
8
9
struct foo {
foo() = default;
template<typename T1, typename... Args>
foo(int a, Args&&... args) {
cout <<"ctor foo" << endl;
T1(std::forward<Args>(args)...);
}
};
foo f1<int>(1); 这样做肯定不行。但我们可以使用类似于标签分派的方法,把一个东西扔到入参里面让他推导出T1的类型。直接扔到入参内肯定不雅。所以标准库有一个std::in_place_type_t (这玩意和它的兄弟们都是tag类型。比如std::inplace 可以看看杂记5和EFF STL笔记)。
言归正传,我们稍加修改下代码如这样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
struct myclass{
myclass(int a, int b){
cout << "ctor myclass" << endl;
cout << a << " " << b << endl;
};
};
struct foo {
foo() = default;
template<typename T1, typename... Args>
foo(int a, std::in_place_type_t<T1>, Args&&... args) {
cout <<"ctor foo" << endl;
T1(std::forward<Args>(args)...);
}
};
int main() {
foo f1(1, std::in_place_type_t<int>{});
foo f2(2, std::in_place_type_t<myclass>{}, 2, 3);
}
这样做就可以看到没有任何问题了。
函数模板参数推导表格和测试函数
测试函数:
1
2
3
4
5
6
7
8
9
template <typename T>
void f(const T& param) {
std::puts(__PRETTY_FUNCTION__);
}
int main() {
int p = 2;
f(p);
}
已知A(实参类型)和P(形参类型)推T(T的类型) P的类型可能是T,const T, T&, const T&, T&&, const T&&
1
2
3
4
5
6
7
8
template<typename T>
void f(P param){
//...
}
int main(){
f(A);
return 0;
}
| P | A | T |
|---|---|---|
| T | int | int |
| T | int* | int* |
| T | int& | int |
| T | const int | int |
| T | const int * | const int * |
| T | int * const | int * |
| T | const int & | int |
| T | const int * const | const int * |
| T | char [2] | char * |
| T | const char [12] | const char * |
| T | void (int) | void (*)(int) |
| const T | int | int |
| const T | int * | int * |
| const T | int & | int |
| const T | const int | int |
| const T | const int * | const int * |
| const T | const int & | int |
| const T | const int * const | const int * |
| const T | char [2] | char * |
| const T | const char [12] | const char * |
| const T | void (int) | void (*)(int) |
| T& | int | int |
| T& | int * | int * |
| T& | int & | int |
| T& | const int | const int |
| T& | const int * | const int * |
| T& | const int & | const int |
| T& | const int * const | const int * const |
| T& | char [2] | char [2] |
| T& | const char [12] | const char [12] |
| T& | void (int) | void (int) |
| T&& | int | int & |
| T&& | int * | int *& |
| T&& | int & | int & |
| T&& | const int | const int & |
| T&& | const int * | const int *& |
| T&& | const int & | const int & |
| T&& | const int * const | const int * const & |
| T&& | char [2] | char (&)[2] |
| T&& | const char [12] | const char (&)[12] |
| T&& | void (int) | void (&)(int) |
| T&& | int && | int |
| const T& | int && | int |
https://www.cnblogs.com/5iedu/p/11183878.html
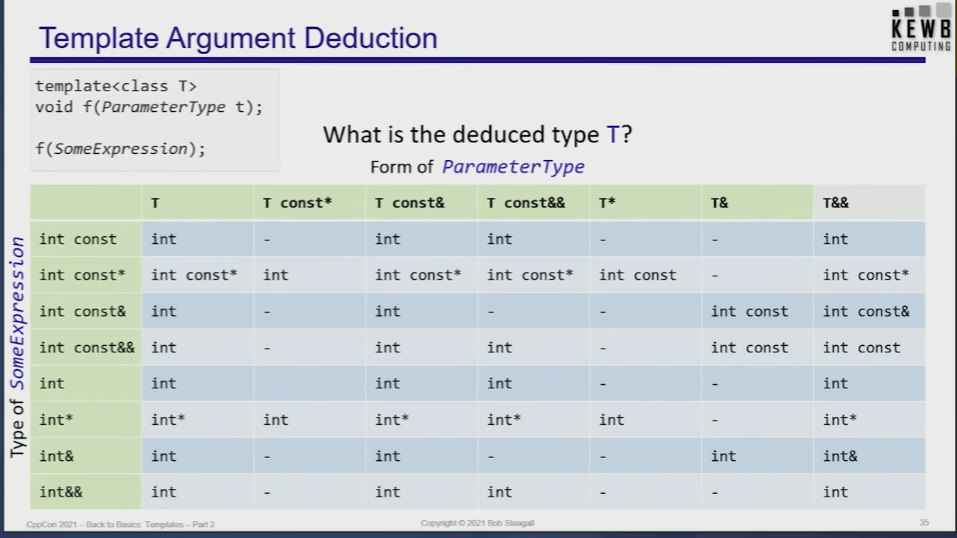
正确区分函数类型和函数指针类型在模板中的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
template<typename T1>
class func{
public:
T1* callable; //这里必须是T1*
func(T1 outter):callable(outter){};
template<typename ...Args>
void call(Args&& ...args){
callable(forward<Args>(args)...);
}
void test(){
std::puts(__PRETTY_FUNCTION__);
}
};
template<typename T1>
class test;
template<typename T1, typename... T2>
class test<T1(T2...)>{//实参匹配
public:
template<typename Func, typename ...Args>
void construct(Func ptr, Args&& ...args){
func<T1(T2...)> obj(ptr);
obj.call(forward<Args>(args)...);
obj.test();
}
};
int testsor(float b, int c){
cout << b << endl;
cout << c << endl;
cout <<"success" << endl;
return 1;
}
int main(){
test<int(float, int)> obj;
obj.construct(testsor, 2.5f, 234);
return 0;
}
为啥上面的部分必须是T1*呢?
因为T1(T2...)会被推导为函数类型而非函数指针类型。也就是传入func的模板参数时,func的T1会被推导为int(float, int)。
在杂记3中,我们区分了函数类型和函数指针类型。函数类型不可以声明变量。所以此时必须额外增加一个*让其转换为指针类型。
https://stackoverflow.com/questions/17446220/c-function-types
什么是元函数
首先,这个词并不是官方定义的名词。元函数表面看起来非常高雅,但其实就是一个只在编译器进行计算的函数。它和普通的函数(运行期函数)具有截然不同的行为。这个函数不仅仅局限于函数,拥有同样作用的类依旧可以叫做元函数。我们其实可以认为元函数实现了类型萃取的功能。
一个并不官方的元函数定义:
输入(即参数)与输出(即返回值)均只包含两种类型:
- 类型(名)
- 比如我们的类型萃取中的类型定义,在某个函数或者类内实施一个
typedef/using
- 比如我们的类型萃取中的类型定义,在某个函数或者类内实施一个
- 整形常量
- 比如我们固化某一个类型的某一个值为特定的值。
- 类型(名)
可以返回一个或多个值,但不能没有返回值。
此处返回值是广义的。比如下面的
type就算做返回值。1 2 3 4
template <bool B, class L, class R> struct IF{ typedef R type; };
没有副作用:元函数在计算过程中既不能改变参数的值,也不具备“向控制台输入输出”之类的附加功能。
- 元函数其实更多的作用是提供一种注册登记 或 映射的作用。
https://stackoverflow.com/questions/32471222/c-are-trait-and-meta-function-synonymous
https://blog.csdn.net/suparchor/article/details/115236785
完美转发的失败场景—-effective modern c++ 条款30
什么叫完美转发失败了?
假设我们有源函数f和其包装的转发函数wrapperf
如果下面两个函数调用导致的操作不同,则称之为失败。
1
2
f(expression);
wrapperf(expression);
一般来说完美转发会在下面的两个条件中任何一个成立的时候失败:
- 编译器无法为一个或多个
wrapperf的形参推导出型别结果。在此情况下,代码无法编译通过。- 也就是模板参数推导失败。
- 编译器为一个或多个
wrapperf的形参推导出了错误的型别结果 。这里所谓错误的,既可以指wrapperf根据型别推导结果的实例化无法通过编译,也可以指以wrapperf推导而得的型别调用与直接以传递给wrapperf的实参调用行为不一致。这种分裂行为的源泉之一 ,可能在于f是个重载函数的名字,然后,依据不正确的推导型别,wrapperf里调用到的f重载版本,就与直接调用f的版本有异。- 也就是模板参数推导结果是错误的。
情况之一:花括号初始化器(大括号初始化物)
假设我们有如下函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void f(const vector<int>& t){ //目标函数
cout <<"called" << endl;
}
template<typename... T>
void wrapperf(T&&... args){ //转发函数
f(forward<T>(args)...);
}
int main(){
f({1,2,3,4,5}); // OK
wrapperf({1,2,3,4,5}); // 不行
return 0;
}
为啥第一个行,第二个不行?
我们知道,编译器会进行函数的入参和形参比较,进行隐式类型转换,尽最大努力成功调用函数。
第一个行的原因是编译器进行了隐式类型转换。编译器会把
{1,2,3,4,5}隐式转换成vector。第二个不行的原因是如果有转发函数,则没有隐式类型转换。这时候是通过类型推导的方式来获取入参的类型。但是花括号初始化器是不推导语境。注意这里是花括号初始化器而非
std::initializer_list形参 P,其实参 A 是花括号初始化器列表,但 P 非 std::initializer_list、到它的引用(可以有 cv 限定),或者 (C++17 起)到数组的引用
解决方案:
我们在聚合初始化中提到了:auto 变量在以花括号初始化器完成初始化时,型别推导可以成功。这样的变量会被视为 std::initializer_list 类型对象。这样一来就没问题了。因为vector有一个接受 std::initializer_list 对象的构造函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void f(const vector<int>& t){ //目标函数
cout <<"called" << endl;
}
template<typename... T>
void wrapperf(T&&... args){ //转发函数
f(forward<T>(args)...);
}
int main(){
auto param = {1,2,3,4,5};
f(param); // OK
wrapperf(param); // OK
return 0;
}
情况之二:把0或NULL当做空指针
NULL就是0。杂记3中提到了:
而到了C++中,则变成了
#define NULL 0
所以这个情况模板推导会把它推导为int而不是目标类型的空指针。为了避免这个问题可以使用nullptr
情况之三:仅有声明的整型static const成员变量
涉及到常量替换。而且较为依靠编译器和链接器。不做介绍
情况之四:重载的函数和模板名字
假设我们有下面代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
void f(int(*pf)(int)){ //目标函数
pf(100);
}
template<typename... T>
void wrapperf(T&&... args){ //转发函数
f(forward<T>(args)...);
}
int testfunc(int a){
cout <<"testfunc" << endl;
return 10;
}
int testfunc(int a, int b){
cout <<"testfunc overload" << endl;
return 20;
}
int main(){
f(testfunc); // OK
wrapperf(testfunc); //不行
return 0;
}
第一个可以的原因是,编译器能知道我们具体传入的函数到底是哪个版本。因为此处不涉及到类型推导。而是重载决议。
第二个不可以的原因是,这也是不推导语境。
testfunc没有类型信息。也就是入参为函数的时候且有多个候选函数的时候,是不推导语境。形参
P,其实参A是一个函数,没有函数或有多个函数与P匹配的重载集,或包含一个或多个函数模板的重载集的时候属于不推导语境
解决方案
- 把传入函数换成传入函数指针即可。或者是强制类型转换一下。
1
2
3
int(*pf)(int) = testfunc;
f(pf); // OK
wrapperf(pf);// OK
情况之五:位域
不太了解,不做介绍
关于函数形参中的省略号
它其实还是变长参数列表。只不过C和C++规则有点不一样。
因为变长形参对于重载决议而言具有最低的优先级,所以它们常被用作 SFINAE 中的万应后备(catch-all fallback)。
https://zh.cppreference.com/w/cpp/language/variadic_arguments
https://stackoverflow.com/questions/60019443/what-does-ellipsis-as-one-and-only-function-parameter-in-a-function-protot
成员函数指针,成员指针和模板的搭配和坑点
我们在2.6提到了一部分。我们这里举个例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
class obj{
public:
bool func(int, int){
std::cout <<"called" << endl;
}
bool func2(){
std::cout <<"called" << endl;
}
bool func3(int){
std::cout <<"called" << endl;
}
};
template<typename ret, typename... Args>
struct myclass{
myclass() = default;
template<typename T>
myclass(ret(T::*ptr)(Args...)){ //成员指针的表达方法。
std::puts(__PRETTY_FUNCTION__);
};
};
int main(){
myclass<bool, int, int> obj(&obj::func);
}
/*
myclass<ret, Args>::myclass(ret (T::*)(Args ...)) [with T = obj; ret = bool; Args = {int, int}]
*/
- 我们可以清楚地看到,
ret和args形参包都被正确匹配了。T也被正确匹配了。 &obj::func只是提取成员函数的地址。obj是可以被匹配到T的。从字面上就能看出来。
看一下函数模板中的情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
template<typename T, typename ret>
void testextract1(ret (T::*pf)){
std::puts(__PRETTY_FUNCTION__);
}
template<typename T, typename ret, typename... Args>
void testextract2(ret (T::*pf)){
std::puts(__PRETTY_FUNCTION__);
}
template<typename T, typename ret, typename... Args>
void testextract22(ret T::*pf){ //同2
std::puts(__PRETTY_FUNCTION__);
}
template<typename T, typename ret, typename... Args>
void testextract3(ret (T::*pf)(Args...)){
std::puts(__PRETTY_FUNCTION__);
}
template<typename T, typename ret, typename... Args>
void testextract44(ret T::*pf(Args...)){ //错误
std::puts(__PRETTY_FUNCTION__);
}
template<typename T, typename ret, typename... Args>
void testextract4(ret (T::*pf)()){ //特殊
std::puts(__PRETTY_FUNCTION__);
}
int main(){
testextract1(&obj::func);
testextract2(&obj::func);
testextract3(&obj::func);
testextract4(&obj::func);//错误
testextract4(&obj::func2);
}
1
2
3
4
void testextract1(ret T::*) [with T = obj; ret = bool(int, int)]
void testextract2(ret T::*) [with T = obj; ret = bool(int, int); Args = {}]
void testextract3(ret (T::*)(Args ...)) [with T = obj; ret = bool; Args = {int, int}]
void testextract4(ret (T::*)()) [with T = obj; ret = bool; Args = {}]
- 注意,返回值类型和函数指针类型不能分离。这俩是在一起的。所以不能不关心返回值类型。
- 前两个例子当中,成员函数指针的类型是
ret。而T只不过是绑定的对应对象的类型。为什么? - 因为c++语法需要通过
T::*外围是否有括号来判断是成员函数类型或是成员类型。 - 前两个,我们能看到
ret T::*之后没有括号。然后ret整个被推导为指向该类成员的完整类型。 - 后两个,我们能看到
ret(T::*)之后有括号。然后ret被推导为函数的返回值类型。也就是类型被正确的拆分了。 - 注意,
testextract44是错误的。ret T::*pf(Args...)暗示了pf是一个指向类T的数据成员的指针,并期望这个数据成员本身是一个函数类型。但是这是不允许的。因为C++不允许数据成员是函数。 - 注意,此处针对例子1、2、22所谓的返回值类型其实不准确。应该称之为成员类型。
- 前两个例子当中,成员函数指针的类型是
- 从第二个例子可以看出,在有可变参数的情况下,如果函数没有涉及到可变参数,则可变参数会变成空类型。因为允许为空。
- 从第三个例子可以看出,在有可变参数的情况下,如果涉及到可变参数,则可变参数可以正确推导。
- 从第四个例子可以看出,带有可变参数的情况下,如果参数位置是空括号,等同于参数是
void。所以testextract4(&obj::func);是错误的。因为其形参类型是int, int。所以testextract4(&obj::func2);是可以的。 - 所以在要求匹配成员函数指针的时候,根据需求不同,需要给出不同的函数签名。也就是我们是否关心参数类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<typename ret, typename T>
void require1(ret (T::*)){ //不关心函数参数的时候
std::puts(__PRETTY_FUNCTION__);
}
template<typename ret, typename T, typename... Args>
void require2(ret (T::*)(Args...)){ //关心函数参数的时候
std::puts(__PRETTY_FUNCTION__);
}
int main(){
require1(&obj::func);
require1(&obj::func2);
require2(&obj::func);
require2(&obj::func2);
}
理解上述的区别,以及成员指针和成员函数指针的区分方式
先说结论:
- 成员指针包含成员函数指针。也就是成员函数指针是成员指针的子集。
- 成员指针为形参的函数既可以接受成员函数也可以接受成员变量。同时成员函数的参数不受限制。
- 同时,以成员函数指针为形参的函数可以和以成员指针为形参的函数形成重载
- 成员函数指针为形参的函数比成员指针为形参的函数更为特化。
- 这也是区分成员函数指针和成员指针的一个方式。
我们在杂记2中提到过类成员变量指针和类成员指针的具体语法。他们俩最大的区别就是后面有没有括号。
为了方便理解,我们加上名字,然后换为更明显的语法。
ret(T::*pf)/ret T::*pf- 后面没有括号。然后
ret整个被推导为整个成员指针类型。注意。这个时候T::*pf本身带不带括号区别不大。因为此时都被认为是成员指针。(包含数据成员和函数成员)
- 后面没有括号。然后
ret(T::*pf)()- 后面有括号。然后
ret被推导为函数指针指向的函数的返回值类型
- 后面有括号。然后
如何理解?为什么?
- 第一种,我们只知道
pf是一个成员指针。ret是一个成员指针的类型,T是其类类型。如果我们传入一个成员函数指针,则ret就是成员指针类型。 - 第二种,我们知道
pf是一个成员函数指针,所以ret是一个函数的返回值类型,T是其类类型。它只能指向成员函数,不能指向成员变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
template<typename T, typename ret>
void testextractmember1(ret (T::*pf)){
std::puts(__PRETTY_FUNCTION__);
}
template<typename T, typename ret>
void testextractmember2(ret T::*pf){
std::puts(__PRETTY_FUNCTION__);
}
testextractmember1(&obj::sb);
testextractmember2(&obj::sb);
testextractmember1(&obj::func3);
testextractmember2(&obj::func3);
//void testextractmember1(ret T::*) [with T = obj; ret = int]
//void testextractmember2(ret T::*) [with T = obj; ret = int]
//void testextractmember1(ret T::*) [with T = obj; ret = bool(int)]
//void testextractmember2(ret T::*) [with T = obj; ret = bool(int)]
我们可以看到。在针对成员指针的测试中,无论是数据成员指针还是函数成员指针都可以被匹配。
格外注意:函数就算带参数,也可以直接被成员指针接受。
1
2
3
4
5
6
7
8
9
template<typename ret, typename T>
void diff(ret(T::*pf)){ //成员指针
cout <<"called variable" << endl;
}
int main(){
diff(&obj::val); //called variable
diff(&obj::func2); //called variable
diff(&obj::func3);//called variable 注意带参数的也可以
}
- 这个测试证明了:成员指针为形参可以接受成员函数和成员变量。
1
2
3
4
5
6
7
8
9
10
template<typename ret, typename T>
void diff(ret(T::*pf)()){ //成员函数指针
cout <<"called func" << endl;
}
int main(){
diff(&obj::val); //报错
diff(&obj::func2);
diff(&obj::func3);//报错
}
- 这个测试证明了:成员函数指针为形参只可以接受成员函数。并且要参数匹配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
template<typename ret, typename T>
void diff(ret(T::*pf)){
cout <<"called variable" << endl;
}
template<typename ret, typename T>
void diff(ret(T::*pf)()){
cout <<"called func" << endl;
}
int main(){
diff(&obj::val); //called variable
diff(&obj::func2); //called func
diff(&obj::func3); //called variable 格外注意这里匹配的问题
}
- 这个测试证明了:以成员函数指针为形参的函数可以和以成员指针为形参的函数形成重载,且在一定程度上可以正确匹配对应类型。
- 成员函数指针为形参的函数比成员指针为形参的函数更为特化。
- 这也是区分成员函数指针和成员指针的一个方式。
- 但是:为什么
diff(&obj::func3);匹配到了成员指针而非成员函数指针?- 因为成员函数指针的版本,函数指针的形参不一致。所以这个版本无法匹配,但是成员指针的版本总可以匹配。
https://stackoverflow.com/questions/72926596/type-deduction-for-a-member-function-pointer
继承自可变参数包(多重继承),类模板参数推导和用户定义的推导指引
12.4节。
我们看一个C++17的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template<class... Ts>
struct Foo : Ts... { //继承自可变参数包
using Ts::operator()...; //使用using引入所有继承的父类的operator()
};
template<class... Ts>
Foo(Ts...) -> Foo<Ts...>; //用户定义的推导指引 C++20起可以移除这段
// 因为CTAD从C++17引入,然后C++20放宽了限制。聚合类可以不需要用户定义推导指引。
int main() {
Foo foo{
[](int v){std::cout << "int";},
[](double v){std::cout << "double";},
};
foo(1);
foo(1.0);
}
首先,关于继承自可变参数包。
假设可变参数包
Ts...的实参是<T1, T2, T3>则这个
Foo相当于struct Foo: T1, T2, T3{};
然后关于使用
using引入所有继承的父类的operator()。这个没啥好解释的- 最后关于用户定义的推导指引,意思是告诉编译器,依照传入
Foo的构造函数的参数的类型来推导Ts... - 整个这段代码的意思是,我们看到我们构造函数传入了两个
lambda表达式。由于继承自可变参数包,则这个Foo相当于继承自这两个lambda表达式的类型。我们也知道lambda类型相当于一个匿名类,含有operator(),所以我们使用using来引入所有继承的父类的operator()。最后我们可以直接调用。
https://zh.cppreference.com/w/cpp/language/class_template_argument_deduction
一些实际参考案例
根据任意可调用对象获取返回值类型/某一参数类型
下面这段代码的目的是针对任意可调用对象获取返回值类型。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
template <typename T>
struct GetRet { //主模板,如果内部含有operator()就取它的类型
private:
using DT = std::decay_t<T>;
public:
using type = typename GetRet<decltype(&DT::operator())>::type; //比较特殊,因为decltype(&DT::operator())是获取成员函数指针类型。在杂记4中提到过。然后递归调用
using type1 = decltype(declval<T>()()); //展开是这样declval<T>().operator()()
void pivot(){
std::puts(__PRETTY_FUNCTION__);
std::cout << std::is_same_v<decltype(&DT::operator()), int(T::*)()>; // true 注意是成员函数指针类型
std::cout << std::endl;
}
};
// 函数类型的特化
template <typename R, typename... Args>
struct GetRet<R(Args...)> {
using type = R;
void pivot(){
std::puts(__PRETTY_FUNCTION__);
}
};
// 函数指针类型的特化
template <typename R, typename... Args>
struct GetRet<R(*)(Args...)> {
using type = R;
void pivot(){
std::puts(__PRETTY_FUNCTION__);
}
};
// 非静态成员函数指针类型的特化
template <typename T, typename R, typename... Args>
struct GetRet<R(T::*)(Args...)> {
using type = R;
void pivot(){
std::puts(__PRETTY_FUNCTION__);
}
};
// const非静态成员函数指针类型的特化
template <typename T, typename R, typename... Args>
struct GetRet<R(T::*)(Args...) const> {
using type = R;
void pivot(){
std::puts(__PRETTY_FUNCTION__);
}
};
template <typename T>
using GetRet_t = typename GetRet<T>::type;
// 测试用例
int f() { //普通函数
return 0;
}
struct T1 { //非静态成员函数
int mem_func(){
cout <<"T1 mem_func" << endl;
return 0;
}
};
struct T2 {
int operator()(){ //operator()
cout <<"T2 ()" << endl;
return 0;
}
};
int main() {
GetRet_t<decltype(f)> a; // 函数类型
GetRet_t<decltype(&f)> b; // 函数指针类型
GetRet_t<T2> c; // 函数对象类型 -- 仿函数
auto lamb = []()->int{return 0;}; // lambda类型
GetRet_t<decltype(lamb)> d;
GetRet_t<decltype(&T1::mem_func)> e; // 非静态成员函数类型
GetRet_t<std::function<int()>> g; //函数对象类型 -- std::function对象
std::cout << std::is_same_v<std::decay_t<decltype(a)>, int>; // true
std::cout << std::is_same_v<std::decay_t<decltype(b)>, int>; // true
std::cout << std::is_same_v<std::decay_t<decltype(c)>, int>; // true
std::cout << std::is_same_v<std::decay_t<decltype(d)>, int>; // true
std::cout << std::is_same_v<std::decay_t<decltype(e)>, int>; // true
std::cout << std::is_same_v<std::decay_t<decltype(g)>, int>; // true
std::cout << std::is_same_v<decltype(declval<T2>()()), int>; // true
std::cout << std::endl;
GetRet<decltype(f)> x1;
GetRet<decltype(&f)> x2;
GetRet<T2> x3;
GetRet<decltype(lamb)> x4;
GetRet<decltype(&T1::mem_func)> x5;
GetRet<std::function<int()>> x6;
x1.pivot();
x2.pivot();
x3.pivot();
x4.pivot();
x5.pivot();
x6.pivot();
/*
void GetRet<R(Args ...)>::pivot() [with R = int; Args = {}]
void GetRet<R (*)(Args ...)>::pivot() [with R = int; Args = {}]
void GetRet<T>::pivot() [with T = T2]
void GetRet<T>::pivot() [with T = main()::<lambda()>]
void GetRet<R (T::*)(Args ...)>::pivot() [with T = T1; R = int; Args = {}]
void GetRet<T>::pivot() [with T = std::function<int()>]
*/
}
上面的例子中,我们可以清楚的复习几个要点
函数指针类型和函数类型不是一个东西
成员函数和模板搭配的语法
还有
decltype获取成员函数指针类型的语法。- 尤其要注意,在主模板中,我们可以使用
type或type1。而且要注意type里面的decltype(&DT::operator())会获取到成员函数指针类型int(T::*)(),所以是递归调用,然后我们通过它会匹配到成员函数指针类型的特化中,成功获取到int。这也是为什么依旧要保留成员函数指针类型的特化。
- 尤其要注意,在主模板中,我们可以使用
我们上面弄了一堆特化,非常麻烦。不如直接使用
type1,也就是比较直观语义的declval创建对象然后调用operator()declval可以调用任意可调用对象,所以我们不需要区分函数类型和函数指针类型了。也就是不需要函数类型特化和函数指针类型特化的两个模板了。这时候结果就会变成:
1 2 3 4 5 6
void GetRet<T>::pivot() [with T = int()] void GetRet<T>::pivot() [with T = int (*)()] void GetRet<T>::pivot() [with T = T2] void GetRet<T>::pivot() [with T = test()::<lambda()>] void GetRet<R (T::*)(Args ...)>::pivot() [with T = T1; R = int; Args = {}] void GetRet<T>::pivot() [with T = std::function<int()>]
关于获取某一特定参数的类型,就需要使用上面的type了,也就是&DT::operator()的方法,然后手动进行参数匹配,详细见这里
几种类型属性和受支持操作
std::is_copy_constructible / std::is_trivially_copy_constructible / std::is_trivially_copyable
这几种比较看起来容易混淆的概念其实非常好理解。从字面意义上的好理解。
std::is_trivially_copyable
用来检查某个型别是否是可平凡复制的。可平凡复制简而言之就是可以用memcpy这种按字节进行底层逐位拷贝而没有问题的。平凡的意思可以直接去cppreference看。核心来说,平凡的XX函数的含义基本都是这个函数不是由用户提供的。
std::is_trivially_copy_constructible
用来检查某个型别是否有一个平凡的拷贝构造。所以说只要满足is_trivially_copyable,就一定满足is_trivially_copy_constructible
std::is_copy_constructible
检查某个型别是否有个可访问的拷贝构造。
总结
所以说这三种从上到下,是拷贝类型限制的从严格到宽松。
std::is_destructible / std::is_trivially_destructible / std::is_nothrow_destructible
std::is_trivially_destructible
有平凡的析构函数
std::is_nothrow_destructible
析构函数不抛出异常
std::is_destructible
有可访问的析构函数
总结
这一套组更加清晰直观。我们可能只需要知道怎么用一下。一般来说,如果对象是可平凡析构的。那么压根不用调用析构函数。因为析构函数啥也不干。所以在某个实现了std::optional的代码中我们可以看到这种代码段
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
template <class T, bool = ::std::is_trivially_destructible<T>::value>
struct optional_storage_base {
//....其他代码
~optional_storage_base() {
if (m_has_value) {
m_value.~T(); //显式调用伪析构函数。学名就叫伪析构函数。
m_has_value = false;
}
}
//....其他代码
};
// 可平凡析构的特化。
template <class T>
struct optional_storage_base<T, true> {
//....其他代码
// No destructor, so this class is trivially destructible
//....其他代码
};
延伸
来自PVS Studio的这篇文章的Program execution: trivial types and ABI章节
- trivially_constructible 意味着不需要初始化某些东西。
- trivially_destructible 意味着不需要生成析构函数代码。
- trivially_copyable 意味着除了按字节复制以外不需要做任何其他事情。
- trivially_movable 表达的含义和trivially_copyable 一样,只不过是在移动语境下。
检查是否有用户定义的swap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
struct tag {};
template <class T>
tag swap(T &, T &);
template <class T, std::size_t N>
tag swap(T (&a)[N], T (&b)[N]);
template <class, class>
std::false_type uses_std(...);
template <class T, class U>
std::is_same<decltype(swap(std::declval<T &>(), std::declval<U &>())), tag> uses_std(int);
struct myclass {
int x;
};
void swap(myclass &, myclass &) { std::cout << "1" << std::boolalpha; }
int main() {
int a = 1;
int b = 2;
std::cout << std::boolalpha;
std::cout << decltype(swap_adl_tests::uses_std<int, int>(0))::value << std::endl;
std::cout << decltype(swap_adl_tests::uses_std<myclass, myclass>(0))::value << std::endl;
swap(a, b);
return 0;
}
有一个模板合成的swap函数。如果有用户定义的swap函数,那么模板合成的优先级低于用户定义的。用户定义的swap不可能返回tag标签类型。所以如果返回的不是tag类型,标志着不能用std::swap。之所以能找到是因为用了ADL。
相反。如果没有用户定义的swap,我们既没有using namespace std, 也没有using std::swap, 我们也是用无限定名字的swap调用。所以说他看不到std::swap,则肯定只能找到合成的返回tag类型的
获取可变参数包中的最后一个元素
简单粗暴
1
2
3
auto last2 = [](auto... args) {
return (args, ...);
};
来自这里
检查是否是某个类型的特化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
template <typename T, template <typename...> typename Template>
struct is_specialization : std::false_type {};
template <template <typename...> typename Template, typename... Args>
struct is_specialization<Template<Args...>, Template> : std::true_type {
void info() { cout << __PRETTY_FUNCTION__ << endl; }
};
int main() {
static_assert(is_specialization<std::vector<int>, std::vector>{}, "");
is_specialization<std::vector<int>, std::vector>{}.info();
return 0;
}
/*
void is_specialization<Template<Args ...>, Template>::info() [with Template = std::vector; Args = {int, std::allocator<int>}]
*/
模板模板参数template就是vector,vector里面的参数就是Args
SFINAE、enable_if 和 enable_if_t 带来的陷阱
本篇文章来自这里的Broken syntax and standard library: std::enable_if_t vs. std::void_t一节
先来看一段代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
struct X {
struct Inner {};
};
struct Y {
struct Outer {};
};
template <class T>
decltype(void(std::declval<typename T::Inner>())) fun(T) { // 1
std::cout << "f1\n";
}
template <class T>
decltype(void(std::declval<typename T::Outer>())) fun(T) { // 2
std::cout << "f2\n";
}
int main(){
X x;
Y y;
fun(x); // 应该输出 "fun1"
fun(y); // 应该输出 "fun2"
}
在“上古”年代,我们会通过这种质朴而纯真的方法来触发SFINAE。一切看起来还可以。直到后面我们有了std::enable_if,陷阱出现了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
template <class T>
std::enable_if_t<std::is_same_v<typename T::Inner, typename T::Inner>> fun1(T) { // 1
std::cout << "f1\n";
}
template <class T>
std::enable_if_t<std::is_same_v<typename T::Outer, typename T::Outer>> fun1(T) { // 2
std::cout << "f2\n";
}
template <class T>
std::enable_if<std::is_same_v<typename T::Inner, typename T::Inner>> fun2(T) { // 3
std::cout << "f1\n";
}
template <class T>
std::enable_if<std::is_same_v<typename T::Outer, typename T::Outer>> fun2(T) { // 4
std::cout << "f2\n";
}
int main(){
fun1(x); // 应该输出 "f1"
fun1(y); // 应该输出 "f2"
fun2(x); // 应该输出 "f1"
fun2(y); // 应该输出 "f2"
}
注意,1和2我们使用的是std::enable_if_t, 3和4使用的是std::enable_if
看起来没啥问题对吧。但是它存在一个潜在的问题。
如果我们尝试检查fun1和fun2函数的签名。我们会发现,fun1的函数签名是我们希望的,返回类型是void。但是,fun2的函数签名,返回类型是std::enable_if<true, void>
所以说我们发现了陷阱所在。一个_t后缀可能会导致我们需要花大量时间排查。这同样适用于<type_traits>标头中的所有其他神秘生物。每个std::trait_X和std::trait_X_t在混合使用的时候会导致意图不可见。
编译期表达式计算的例子
来自这里
核心是我们想要优化掉Vec x = a + b + c 这样带有中间结果的情况
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
template <typename E>
class VecExpression {
public:
static constexpr bool is_leaf = false;
double operator[](size_t i) const {
// Delegation to the actual expression type. This avoids dynamic polymorphism (a.k.a.
// virtual functions in C++)
return static_cast<E const&>(*this)[i];
}
size_t size() const { return static_cast<E const&>(*this).size(); }
};
class Vec : public VecExpression<Vec> {
std::array<double, 3> elems;
public:
static constexpr bool is_leaf = true;
decltype(auto) operator[](size_t i) const { return elems[i]; }
decltype(auto) operator[](size_t i) { return elems[i]; }
size_t size() const { return elems.size(); }
// construct Vec using initializer list
Vec(std::initializer_list<double> init) { std::copy(init.begin(), init.end(), elems.begin()); }
// A Vec can be constructed from any VecExpression, forcing its evaluation.
template <typename E>
Vec(VecExpression<E> const& expr) {
for (size_t i = 0; i != expr.size(); ++i) {
elems[i] = expr[i];
}
}
};
template <typename E1, typename E2>
class VecSum : public VecExpression<VecSum<E1, E2> > {
// cref if leaf, copy otherwise
typename std::conditional<E1::is_leaf, const E1&, const E1>::type _u;
typename std::conditional<E2::is_leaf, const E2&, const E2>::type _v;
public:
static constexpr bool is_leaf = false;
VecSum(E1 const& u, E2 const& v) : _u(u), _v(v) { assert(u.size() == v.size()); }
decltype(auto) operator[](size_t i) const { return _u[i] + _v[i]; }
size_t size() const { return _v.size(); }
};
template <typename E1, typename E2>
VecSum<E1, E2> operator+(VecExpression<E1> const& u, VecExpression<E2> const& v) {
return VecSum<E1, E2>(*static_cast<const E1*>(&u), *static_cast<const E2*>(&v));
}
int main(){
Vec v1 = {1, 2, 3};
Vec v2 = {4, 5, 6};
Vec v3 = v1 + v2;
std::cout << v3[0] << " " << v3[1] << " " << v3[2] << std::endl;
}
这样的话,这样 a+b+c 的类型是 VecSum<VecSum<Vec, Vec>, Vec>
Vec x = a + b + c 会调用Vec(VecExpression<E> const& expr) elems[i] = expr[i];会展开成elems[i] = a.elems[i] + b.elems[i] + c.elems[i]
这样就没有临时Vec对象了
通过值传递还是引用传递可调用对象
来自这里
假设我们有一个函数模板g接受一个可调用对象f,我们用值传递还是引用传递?
1
2
3
4
5
template <class F>
void g(F f); // (1) by value
template <class F>
void g(F&& f); // (2) by reference
如果我们看看标准库,比如 std::invoke, 可调用对象是引用传递
1
2
3
template< class F, class... Args >
std::invoke_result_t<F, Args...>
invoke( F&& f, Args&&... args ) noexcept(/* see below */);
在其他大多数情况,比如在 <algorithm>头文件中,可调用对象是值传递
1
2
template< class T, class Compare >
const T& max( const T& a, const T& b, Compare comp );
所以按照作者意见:
- 如果
g的主要作用是调用f,则使用引用 - 其他情况下使用值传递。
这样做的好处是可以简化一些代码,同时可以让可调用对象直接被algotirhm使用
对于那些不可拷贝,或者不想拷贝的可调用对象。可以使用std::ref包装
运算符重载
从最近需求中学习,也感谢磊哥的指点。我们有现在的SSCCE代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
struct t1 {
int a;
int b;
};
template <typename T1>
struct F {
F(int x) : val_(x) {};
F() : val_(2) {};
template <typename T2>
friend F<T1> operator*(const F<T1>& a, const F<T2>& b) {
return a.val_ * b.val_;
}
private:
int val_;
};
int main() {
F<int> a;
F<t1> b(3);
auto s = a * b; // NOPE
cout << s.getval() << endl;
}
/*
1107.cpp:16:27: error: ‘int F<t1>::val_’ is private within this context
16 | return a.val_ * b.val_;
| ~~^~~~
1107.cpp:24:9: note: declared private here
24 | int val_;
| ^~~~
*/
我们有一个乘法运算符重载。我们不希望写为成员函数,希望是友元函数。同时我们不想暴露某些私有方法或成员。但是现在我们似乎发现F<T1>看不到F<T2>的成员。这是必然的。因为类模板F<X>和F<Y>并不是同一类型。同时,这种友元函数的定义实际上并不是一个全局模板函数,而是一个成员模板函数。在这种情况下,operator* 只有在 F<T1> 的实例内部才是友元。对于 F<T2> 类型的对象,F<T1> 的 operator* 无法访问 F<T2> 的私有成员 val_。因此编译器会报错。
所以我们用如下方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
struct t1 {
int a;
int b;
};
template <typename T1>
struct F {
F(int x) : val_(x) {};
F() : val_(2) {};
template <typename T11, typename T2> // T11不可是T1,会shadow
friend F<T11> operator*(const F<T11>& a, const F<T2>& b);
int getval(){
return val_;
}
private:
int val_;
};
template<typename T11, typename T2> //T11可以是任何,可以是T1, 无所谓
F<T11> operator* (const F<T11>& a, const F<T2>& b){
return a.val_ * b.val_;
}
int main() {
F<int> a;
F<t1> b(3);
auto s = a * b; // GOOD
cout << s.getval() << endl;
}
这种写法,这里声明了一个独立的全局模板函数,并且声明了它为友元函数。由于这是一个独立的模板函数,它可以访问 F<T11> 和 fuckFT2> 的私有成员。这是因为编译器在第二种情况下将 operator* 视为所有 F<T1> 和 F<T2> 的友元函数,因此无论 F<T11> 和 F<T2> 是什么类型,它们的私有成员 val_ 都可以被访问。
可以查看这里的 模板类的非约束模板友元函数