设计模式
创建型模式部分
创建型模式主要关注与对象的创建。通常这类模式被用于创建对象的时候。比如抽象工厂被用于创建产品族,原型模式被用来模拟更自由的深拷贝等等。
简单工厂模式
流程
- 设计一个抽象产品类,它包含一些产品类公共方法的实现;
- 从抽象产品类中派生出多个具体产品类,如篮球类、足球类、排球类,具体产品类中实现具体产品生产的相关代码;
- 设计一个工厂类,工厂类中提供一个生产各种产品的工厂方法,该方法根据传入参数(产品名称)创建不同的具体产品类对象;。客户只需调用工厂类的工厂方法,并传入具体产品参数,即可得到一个具体产品对象。
结构
- 工厂(Factory)︰根据客户提供的具体产品类的参数,创建具体产品实例
- 抽象产品(AbstractProduct):具体产品类的基类,包含创建产品的公共方法。可以做为抽象类(不提供实现)
- 具体产品(ConcreteProduct):抽象产品的派生类,包含具体产品特有的实现方法,是简单工厂模式的创建目标。
缺点
每次新增具体产品,不仅要新增具体产品类,而且要更改工厂类。
总结
- 简单工厂模式中,工厂只有一个。
- 工厂生产所有种类的产品
- 工厂类的返回值是一个指向具体产品类的基类指针以满足多态调用。
- 工厂类中依据传入参数来调用对应的具体产品类。
- 抽象产品类可以做为抽象类也可以做为普通类。
- 具体产品类中进行具体产品的实现。
工厂方法模式
代码参考factory.cpp
流程
- 设计一个抽象产品类,它包含一些产品类公共方法的实现;
- 从抽象产品类中派生出多个具体产品类,如篮球类、足球类、排球类,具体产品类中实现具体产品生产的相关代码;
- 设计一个抽象工厂类。是所有生产具体产品的工厂类的基类。提供工厂类的公共方法。
- 从抽象工厂类中派生出多个具体工厂类,具体工厂类中提供一个生产特定具体产品的方法,该方法可以返回一个具体产品类对象的指针。
- 使用时声明抽象工厂类指针,new一个具体工厂类的对象。让抽象工厂类指针指向具体工厂类对象。通过该指针调用具体工厂类的生产方法拿到一个指向具体产品类的抽象产品类指针。
结构
- 抽象工厂(AbstractFactory):所有生产具体产品的工厂类的基类,提供工厂类的公共方法;
- 具体工厂(ConcreteFactory) : 生产具体的产品
- 抽象产品(AbstractProduct):所有产品的基类,提供产品类的公共方法。
- 具体产品(ConcreteProduct) ︰具体的产品类
缺点
虽然我们这次不需要修改具体工厂类,只需要添加具体工厂类即可。但是:
- 这样做增加系统复杂度,因为类的数量变多了。
- 同时,由于工厂和产品都有抽象类,而且调用中也需要拿到对应的抽象类类型的指针,导致增加理解难度。降低代码可读性。
总结
- 我们这次拥有了抽象工厂类,这样我们就可以有多个不同的具体工厂类,让每一个工厂类都生产特定类别的具体产品。
- 抽象工厂类是抽象类。不提供具体实现。调用的时候需要声明一个抽象工厂类的指针指向某一个具体工厂
- 这里的意思是必须要指明我们需要哪种工厂。
- 拿到具体工厂类指针后,可以通过具体工厂类的生产方法得到一个指向具体产品类的抽象产品类指针。
- 工厂方法模式把产品的具体创建过程延迟到了具体工厂类中。
抽象工厂模式
代码参考abstractfactory.cpp
和工厂方法模式的区别
抽象工厂和工厂方法非常相似。唯一的区别是:
- 在工厂方法中,我们每一个具体工厂类只能生产一个特定的具体产品。
- 在抽象工厂中,每一个具体工厂可以生产多种同类相关的产品。也就是一个产品族
在代码中,我们的产品族指的是足球产品族和篮球产品族。每一个产品族包含球和球衣。
也就是说,抽象工厂模式是为了创建一组(有多类)相关或依赖的对象提供创建接口,而 工厂模式是为一类对象提供创建接口或延迟对象的创建到子类中实现。
缺点
这就是所谓的抽象工厂的开闭原则的倾斜性。
- 增加产品族:对于增加新的产品族,工厂方法模式很好的支持了“开闭原则”,对于新增加的产品族,只需要对应增加一个新的具体工厂即可,对已有代码无须做任何修改。假设我们新增排球产品族,只需要新增工厂即可。
增加新的产品具体内容:对于增加新的产品具体内容,需要修改所有的工厂角色,包括抽象工厂类,在所有的工厂类中都需要增加生产新产品的方法,不能很好地支持“开闭原则”。比如我们现在需要特定的能量饮料,就需要在所有工厂类中新增一个能量饮料的产品。
- 当抽象工厂模式中每一个具体工厂类只创建一个产品对象,也就是只存在一个产品具体内容时,抽象工厂模式退化成工厂方法模式;当工厂方法模式中抽象工厂与具体工厂合并,提供一个统一的工厂来创建产品对象,并将创建对象的工厂方法设计为静态方法时,工厂方法模式退化成简单工厂模式。
总结
工厂模式有非常高的自由度。比如可以把工厂写成嵌套类,然后定义一个嵌套类内的静态变量以达到隐藏嵌套工厂类的效果。也更加清晰明确某些类的对象就是必须使用工厂类来创建。也可以把创建方法写成lambda放入容器。总而言之,工厂模式的核心思想就是帮助我们创建对象,管理对象的创建方法,提供一个统一的接口。
创建者模式(Builder)
创建者模式最好的解释方法就是看它的名字。实际应用的场景主要是:在某些对象如果有复杂的创建过程的时候,比如可能需要10个构造函数的参数,或者是像是组成一个HTML文件,这个时候让一个类来进行实现就显得非常不雅。创建者模式的核心就是让复杂对象的创建和表示(展示)分离开来。在每一个构造中都可以引入参数。
在软件开发中,也存在大量类似汽车一样的复杂对象,它们拥有一系列成员属性,这些成员属性中有些是引用类型的成员对象。而且在这些复杂对象中,还可能存在一些限制条件,如某些属性没有赋值则复杂对象不能作为一个完整的产品使用;有些属性的赋值必须按照某个顺序,一个属性没有赋值之前,另一个属性可能无法赋值等。
或者我们简单理解为,使用不同的配置文件来使得创建的对象具有不同的参数。
结构
- 产品(Product):具体的产品对象
- 抽象建造者(AbstractBuilder):创建产品(Product)对象的各个部件指定的抽象接口
- 具体建造者(ConcreteBuilder):实现 抽象建造者(AbstractBuilder)的接口,实现各个部件的具体构造方法和装配方法,并返回创建结果。
- 指挥者(Director):构建一个使用抽象建造者(AbstractBuilder)接口的对象,安排复杂对象的构建过程,客户端一般只需要与指挥者交互,指定建造者类型,然后通过构造函数或者setter方法将具体建造者对象传入指挥者。它主要作用是隔离客户与对象的生产过程,并负责控制产品对象的生产过程。
流程
参考代码builder.cpp
注意在我们的代码中,我们选择让抽象建造者管理一个产品对象(利用RAII)。我们也可以选择不让它管理。
优点
- 在建造者模式中, 客户端不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象。
- 每一个具体建造者都相对独立,而与其他的具体建造者无关,因此可以很方便地替换具体建造者或增加新的具体建造者, 用户使用不同的具体建造者即可得到不同的产品对象 。
- 也就是理解为我们说的 “替换配置文件“
- 可以更加精细地控制产品的创建过程 。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰,也更方便使用程序来控制创建过程。
- 也就是我们建造中拆分出来的步骤。
- 增加新的具体建造者无须修改原有类库的代码,指挥者类针对抽象建造者类编程,系统扩展方便,符合“开闭原则”。
- 具体建造者只需要更换具体实现,就可以当做“配置文件”传入建造者。指挥者保有一个抽象建造者。也就是指挥者面向抽象建造者编程。我们会发现指挥者调用的就是抽象建造者的纯虚函数。
缺点
- 建造者模式所创建的产品一般具有较多的共同点,其组成部分相似,如果产品之间的差异性很大,则不适合使用建造者模式,因此其使用范围受到一定的限制。
- 假如产品的建造模式有大的区别,比如需要更换抽象建造者,则不适用于这种模式。
- 如果产品的内部变化复杂,可能会导致需要定义很多具体建造者类来实现这种变化,导致系统变得很庞大。
总结
适用场景:
需要生成的产品对象有复杂的内部结构,这些产品对象通常包含多个成员属性。
需要生成的产品对象的属性相互依赖,需要指定其生成顺序。
对象的创建过程独立于创建该对象的类。在建造者模式中引入了指挥者类,将创建过程封装在指挥者类中,而不在建造者类中。
隔离复杂对象的创建和使用,并使得相同的创建过程可以创建不同的产品。
建造者模式与抽象工厂模式的比较:
- 抽象工厂模式相比, 建造者模式返回一个组装好的完整产品 ,而 抽象工厂模式返回一系列相关的产品,这些产品拥有不同的具体内容,构成了一个产品族。
- 在抽象工厂模式中,客户端实例化工厂类,然后调用工厂方法获取所需产品对象,而在建造者模式中,客户端可以不直接调用建造者的相关方法,而是通过指挥者类来指导如何生成对象,包括对象的组装过程和建造步骤,它侧重于一步步构造一个复杂对象,返回一个完整的对象。
- 如果将抽象工厂模式看成 汽车配件生产工厂 ,生产一个产品族的产品,那么建造者模式就是一个 汽车组装工厂 ,通过对部件的组装可以返回一辆完整的汽车。
- Builder 模式强调的是一步步创建对象,并通过相同的创建过程可以获得不同的结果对象,一般来说 Builder 模式中对象不是直接返回的。而在 AbstractFactory 模式中对象是直接返回的。
其他技巧:
- 我们可以增添链式调用以达到fluent builder的效果
- 我们可以和facade模式结合在一起。参考代码
facade_builder
原型模式 (Prototype)
定义:
- 使用原型实例指定待创建对象的类型,并且通过复制这个原型来创建新的对象。
解释:
- 原型模式的工作原理是将一个原型对象传给要发动创建的对象(即客户端对象),这个要发动创建的对象通过请求原型对象复制自己来实现创建过程。
- 从工厂方法角度而言,创建新对象的工厂就是原型类自己。
- 软件系统中有些对象的创建过程比较复杂,且有时需要频繁创建,原型模式通过给出一个原型对象来指明所要创建的对象的类型,然后用复制这个原型对象的办法创建出更多同类型的对象,这就是原型模式的意图所在。
个人感受:我们通过某一个东西来创建出来一个它的副本。这个看上去很像拷贝构造和拷贝赋值。只不过这个模式是建立在这个基础上的。因为我们可能复制的只是一部分。可以理解为一个支持更加细粒度和更多种类操作的拷贝构造和拷贝赋值。比如拷贝特定部分,替换特定参数等等。
结构
- Abstract Prototype: 抽象原型类
- 声明一个clone自身的接口
- Concrete Prototype: 具体原型类
- 实现clone接口
- Client: 客户端类
- 客户端中声明一个抽象原型类,根据客户需求clone具体原型类对象实例。
流程
参考代码。里面设计有点问题。理论上应该直接使用并且返回抽象原型类指针。
优点
- 当创建新的对象实例较为复杂时,原型模式可以简化创建过程,提高创建对象的效率;
- 可扩展: 模式中提供了抽象原型类,具体原型类可适当扩展;
- 创建结构简单: 创建工厂即为原型对象本身
缺点
- 深克隆代码较为复杂
- 每一个类都得配备一个clone方法,且该方法位于类的内部,修改时违背开闭原则;
总结
适用环境:
- 当创建新的对象实例较为复杂时,原型模式可以简化创建过程;
- 结合优点第3条,需要避免使用分层次的工厂类来创建分层次的对象,并且类的实例对象只有一个或很少几个的组合状态,通过复制原型对象得到新实例,比通过使用构造函数创建一个新实例会更加方便。
原型模式可以理解为一个支持更加细粒度和更多种类操作的拷贝构造和拷贝赋值。比如拷贝特定部分,替换特定参数等等。但是尤其要注意深拷贝和浅拷贝问题。
在多态类中尤其要使用原型模式,或者相似的方法实现拷贝接口。
因为我们在vptr中提到过,如果我们想通过一个父类指针获取指向的子类对象的拷贝,直接解引用调用的拷贝构造是父类的。因为解引用后元素的类型依靠的是静态类型,所以提取出来的元素类型是父类类型的引用。所以此时无法实现多态。因为你会发现new一个子类的时候没有一个对应的拷贝构造。所以这时候你只能使用类型转换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
struct a {
a() = default;
virtual void f() {
cout <<"A" << endl;
}
a(const a&) {
cout << "a copy" << endl;
}
};
struct b :public a {
b() = default;
virtual void f() {
cout <<"B" << endl;
}
b(const b&) {
cout << "b copy" << endl;
}
};
int main() {
a* p = new b;
a* err = new b(*p); //不可以。因为*p是a&类型。除非你在b新建一个构造函数,如 b(const a&)
a* p1 = new b(*dynamic_cast<b*>(p)); //只能先转成b。这样会调用b的拷贝构造。输出b copy
p->f();
p1->f();
delete p;
delete p1;
return 0;
}
如果这时候使用原型模式实现克隆接口就会非常顺畅:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
struct a {
a() = default;
virtual void f() {
cout <<"A" << endl;
}
a(const a&) {
cout << "a copy" << endl;
}
virtual a* clone(){ //克隆接口
return new a;
}
};
struct b :public a {
b() = default;
virtual void f() {
cout <<"B" << endl;
}
b(const a&){
cout <<"wtf" << endl;
}
b(const b&) {
cout << "b copy" << endl;
}
virtual a* clone(){ //克隆接口
return new b;
}
};
int main() {
a* p = new b;
a* pclone = p->clone(); //克隆
p->f();
pclone->f(); //正确多态
delete p;
delete pclone;
return 0;
}
结构型模式部分
结构型模式主要是用于设计更合理的API。也就是如何组织整个代码的结构。比如类的组织,继承,包含。哪些接口应该开放,对谁开放。这一部分中,很多模式是一种对底层类接口的包装。目的是简化使用,隐藏具体细节等等。
适配器模式 (Adapter)
- 类适配器中,适配器类通过继承适配者类,并重新实现适配者的具体接口来达到适配客户所需要的接口的目的。
- 从图中我们可以看到,类适配器不仅要继承自目标抽象类,同时也要继承自所有的适配者类。所以类适配器需要多重继承的支持。所以如Java就不适用于这种方式。
- 对象适配器中,适配器类通过在类中实例化一个适配者类的对象,并将其封装在客户所需功能的接口里,达到最终的适配目的。
- 我们的代码是对象适配器。
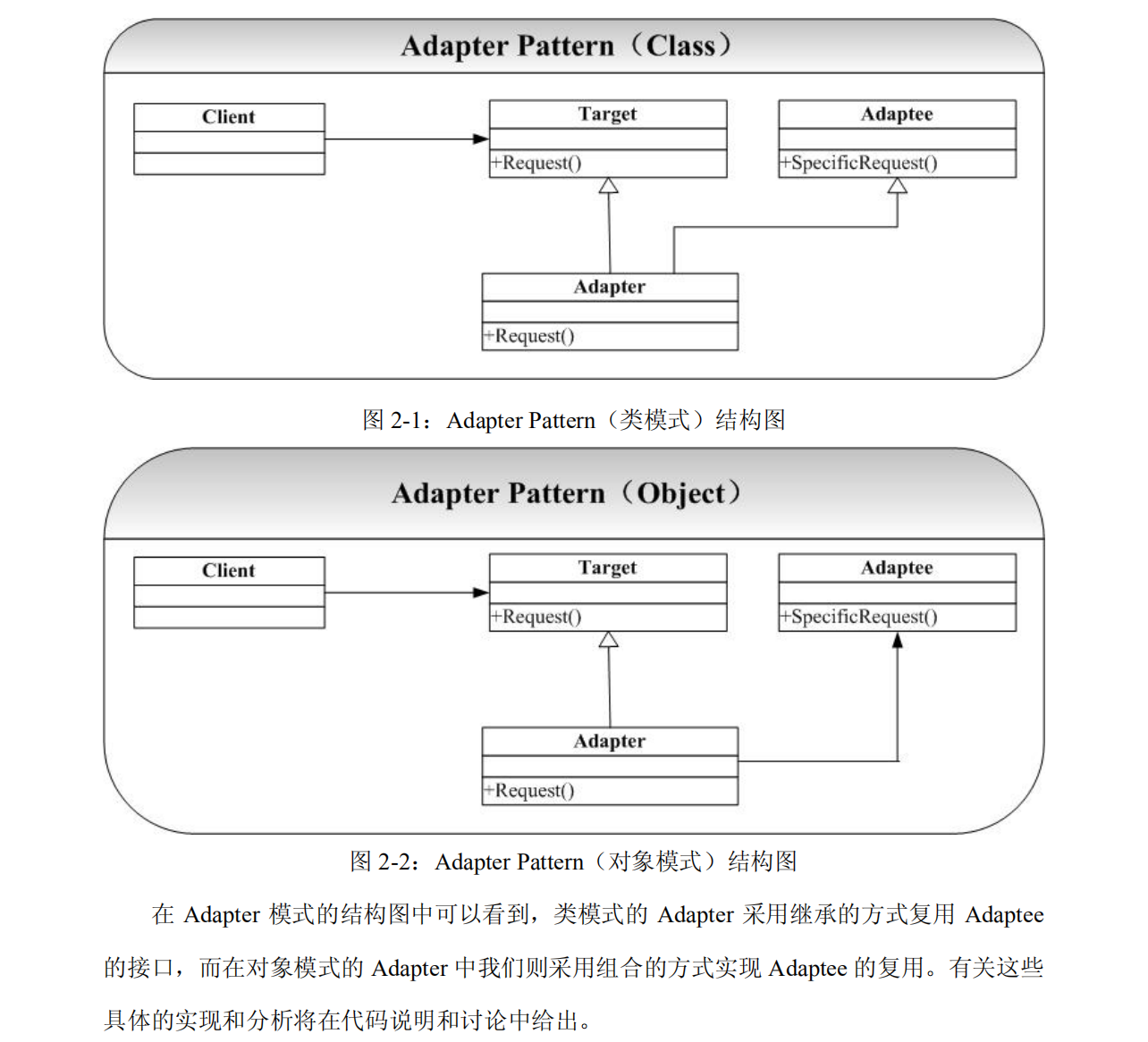
结构
- Target:目标抽象类
- Adapter:适配器类
- Adaptee:适配者类
- Client:客户类 (可以简化成调用对象)
流程:
- 创建target类。这个类是抽象基类。
- 创建adapter类。adapter类新增接口。调用所需的适配者类。
- 客户通过adapter类对象调用adapter类暴露出来的接口。
总结:
个人理解:当我们有一个任务需要调用多个类。我们就可以新增一个目标抽象类。然后适配器类继承自该目标抽象类。适配器类负责调用所需的适配者类,也就是假如我们需要调用ABCDE五个类来完成这个任务。然后五个类关联不是很大,但是想让他们一起工作。我们就可以新增一个类。在这个类里面去调用ABCDE这五个类。我们外部客户只需要调用这个适配器类即可完成任务。
适配器模式和外观模式的核心区别:
- 适配器模式的前提是你无法改变已经既有的类的需求。简单例子就是参数不同,类型不同等。
- 也就是适用于想使用一个已经存在了的接口,而这个接口却不符合你的需求,此时就可以考虑使用适配器模式。所以是事后设计(擦屁股)
- 适配器模式的核心是转换。也就是包了一层的wrapper
- 外观模式是你自己设计的时候,想要提供一个整洁一致的(看起来简洁的)接口给调用端。强调是事前设计。
- 外观模式的核心是提供统一接口给客户端。注意是提供给客户端。
- STL中的栈,队列,优先队列就是适配器模式的典范。

我们在杂记5中提到的
pmr多态资源分配器,是memory_resource的适配器。![QQ截图20230514175956]()

外观模式(Facade)
核心的个人理解:一个操作需要调用五个函数,太麻烦了,我们提供统一接口。这个接口内调用五个函数,但是客户只需要调用接口。
核心区别上面写过了。
结构
- 一个外观类(接口)
- 一堆你需要调用函数的类。
缺点:
- 增加或者减少子系统,必须要修改外观类。违反开闭原则。
- 客户端可以直接与子系统交互。如果加强限制则使系统灵活性降低。
总结
- 不要试图通过外观类为子系统增加新行为
- 不要通过继承一个外观类在子系统中加入新的行为,这种做法是错误的。外观模式的用意是为子系统提供一个集中化和简化的沟通渠道,而不是向子系统加入新的行为,新的行为的增加应该通过修改原有子系统类或增加新的子系统类来实现,不能通过外观类来实现。
- 可以考虑新增抽象外观类来一定程度上缓解违背开闭原则的情况。
- 在一个系统中,通常情况下,一个外观类只需要一个实例。所以可以考虑将其实现为单例。当然这并不意味着在整个系统里只能有一个外观类,在一个系统中可以设计多个外观类,每个外观类都负责和一些特定的子系统交互,向用户提供相应的业务功能。
享元模式 (Flyweight)
细粒度对象的大面积复用。Flyweight 模式在实现过程中主要是要为共享对象提供一个存放的“仓库”(对象(享元)池)
- 如果一个系统在运行时创建太多相同或者相似的对象,会占用大量内存和资源,降低系统性能。享元模式通过共享技术实现相同或相似的细粒度对象的复用,提供一个享元池存储已经创建好的对象,并通过享元工厂类将享元对象提供给客户端使用。
- 运用共享技术有效地支持大量细粒度对象的复用。系统只使用少量的对象,而这些对象都很相似,状态变化很小,可以实现对象的多次复用。由于享元模式要求能够共享的对象必须是细粒度对象,因此它又称为轻量级模式,它是一种对象结构型模式。
- 例子1:我们有一万颗树。但是这些树的纹理,叶子的种类等等只有那么固定的几种,变化的部分不过是位置,和具体使用的种类而已。
- 例子2:围棋只有两种颜色。棋子与棋子之间的区别除了颜色和位置,没什么不同。也就是说,每个棋子对象的大部分状态都是一样的(形状、材料、质地等)。如果我们要设计一个程序来实现下围棋的功能,该如何来创建或者表示这上百个棋子对象呢?
结构
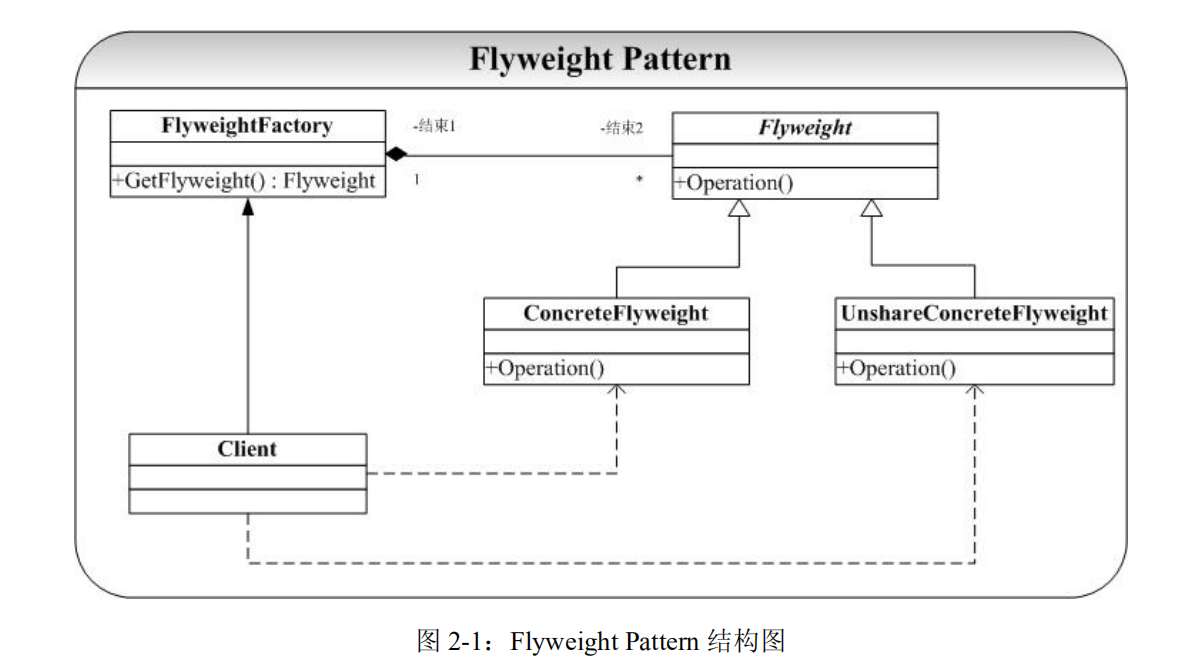
- FlyWeight: 抽象享元类
- 声明了具体享元类的公共方法。比如提供内部状态数据(比如例子里的名字)和设置(注入)外部状态(比如例子里的端口和IP)。
- ConcreteFlyWeight: 共享具体享元类
- 里面会含有一些具体享元类中应有的数据和方法。为内部状态提供存储空间。比如例子中的具体享元类自己的名字。
- 一般情况下每个享元类对象只应被创建一次。所以应该是单例模式。但是例子中的代码懒得写单例了。
- UnsharedConcreteFlyweight: 非共享具体享元类
- 不是所有抽象享元类的子类都需要被共享。可以把不全部共享的子类设计为非共享具体享元类。
- FlyweightFactory: 享元工厂类
- 创建并管理具体享元对象。将各种具体享元类对象储存在一个享元池中。享元池一般设计为一个储存键值对的容器。可以结合工厂模式设计。客户需要某个享元对象时,如果已有该实例,则直接返回该实例。如果没有该实例,则新建一个实例然后返回给客户,同时放入享元池。
流程
具体参考代码。
优点
- 享元模式的优点在于它可以极大减少内存中对象的数量,使得相同对象或相似对象在内存中只保存一份。
- 享元模式的外部状态相对独立,而且不会影响其内部状态,从而使得享元对象可以在不同的环境中被共享。
缺点
- 享元模式使得系统更加复杂,需要分离出内部状态和外部状态,这使得程序的逻辑复杂化。
- 为了使对象可以共享,享元模式需要将享元对象的状态外部化,而读取外部状态使得运行时间变长。
总结
在以下情况下可以使用享元模式:
- 一个系统有大量相同或者相似的对象,由于这类对象的大量使用,造成内存的大量耗费。
- 对象的大部分状态都可以外部化,可以将这些外部状态传入对象中。
使用享元模式需要维护一个存储享元对象的享元池,而这需要耗费资源,因此,应当在多次重复使用享元对象时才值得使用享元模式。
- 享元模式在编辑器软件中大量使用,如在一个文档中多次出现相同的图片,则只需要创建一个图片对象,通过在应用程序中设置该图片出现的位置,可以实现该图片在不同地方多次重复显示。
单纯享元模式和复合享元模式
- 单纯享元模式:在单纯享元模式中,所有的享元对象都是可以共享的,即所有抽象享元类的子类都可共享,不存在非共享具体享元类。
- 复合享元模式:将一些单纯享元使用组合模式加以组合,可以形成复合享元对象,这样的复合享元对象本身不能共享,但是它们可以分解成单纯享元对象,而后者则可以共享。
享元模式与其他模式的联用
- 在享元模式的享元工厂类中通常提供一个静态的工厂方法用于返回享元对象,使用简单工厂模式来生成享元对象。
- 在一个系统中,通常只有唯一一个享元工厂,因此享元工厂类可以使用单例模式进行设计。
- 享元模式可以结合组合模式形成复合享元模式,统一对享元对象设置外部状态。
桥接模式(bridge)
桥接模式简而言之就是两个独立的继承体系,通过“桥接”的方式结合在一起。
第一个例子:
设想如果要绘制矩形、圆形、椭圆、正方形,我们至少需要4个形状类,但是如果绘制的图形需要具有不同的颜色,如红色、绿色、蓝色等,此时至少有如下两种设计方案:
- 第一种设计方案是为每一种形状都提供一套各种颜色的版本。
- 第二种设计方案是根据实际需要对形状和颜色进行组合
对于有两个变化维度(即两个变化的原因)的系统,采用方案二来进行设计系统中类的个数更少,且系统扩展更为方便。设计方案二即是桥接模式的应用。桥接模式将继承关系转换为关联关系,从而降低了类与类之间的耦合,减少了代码编写量。
第二个例子:
设想如果有两台手机,我们至少需要2个形状类,但是如果手机需要具有不同的应用程序,此时至少有如下两种设计方案:
- 第一种设计方案是为每一台手机都提供一套安装了各个程序的版本。
- 第二种设计方案是根据实际需要对手机和程序进行组合
桥接模式(Bridge Pattern):将抽象部分与它的实现部分分离,使它们都可以独立地变化。它是一种对象结构型模式,又称为柄体(Handle and Body)模式或接口(Interface)模式。
结构
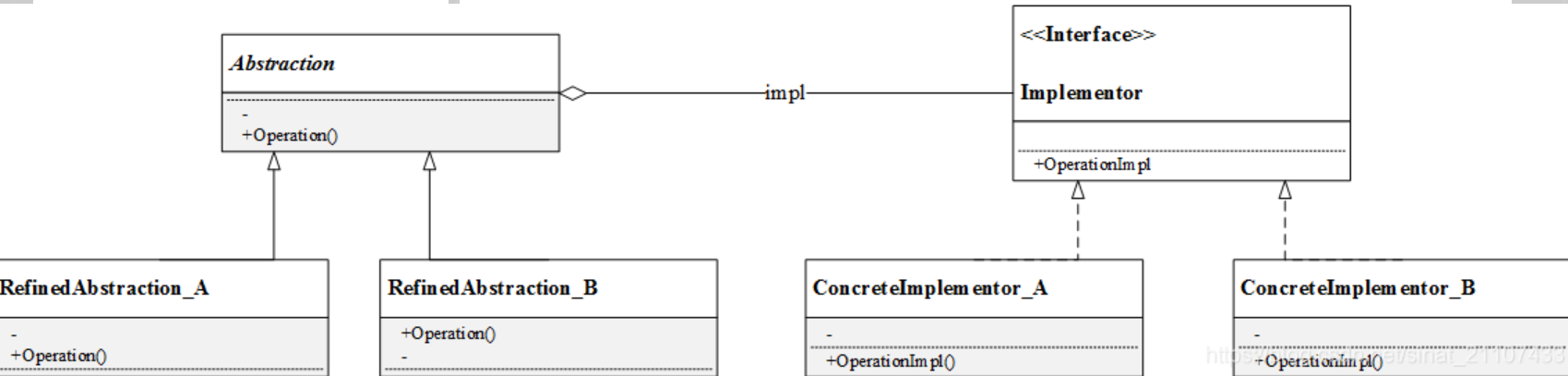
通过这张图我们能非常清楚地看到两个独立的继承体系通过桥接方式组合在一起。
Abstraction(抽象类)︰定义抽象类的接口(抽象接口),由聚合关系可知,抽象类中包含一个Implementor类型的对象,它与Implementor之间有关联关系,既可以包含抽象业务方法,也可以包含具体业务方法;
lmplementor(实现类接口)︰定义实现类的接口,这个接口可以与Abstraction类的接口不同一般而言,实现类接口只定义基本操作,而抽象类的接口还可能会做更多复杂的操作。
RefinedAbstraction (扩充抽象类)︰具体类,实现在抽象类中定义的接口,可以调用在lmplementor中定义的方法;
Concretelmplementor(具体实现类)︰具体实现了Implementor接口,在不同的具体实现类中实现不同的具体操作。运行时Concretelmplementor将替换父类。
简言之,在Abstraction类中维护一个Implementor类指针,需要采用不同的实现方式的时候只需要传入不同的Implementor派生类就可以了。
流程
查看代码。
优点
- 分离抽象接口与实现部分,使用对象间的关联关系使抽象与实现解耦;
- 桥接模式可以取代多层继承关系,多层继承违背单一职责原则,不利于代码复用;
- 桥接模式提高了系统可扩展性,某个维度需要扩展只需增加实现类接口或者具体实现类,而且不影响另一个维度,符合开闭原则。
缺点
- 桥接模式难以理解,因为关联关系建立在抽象层,需要一开始就设计抽象层
- 如何准确识别系统中的两个维度是应用桥接模式的难点。
总结
个人感受这个东西非常像一种组合。但是注意不是组合模式。这是两个不同的东西。重点需要理解如何将抽象化(Abstraction)与实现化(Implementation)脱耦,使得二者可以独立地变化。
- 抽象化:抽象化就是忽略一些信息,把不同的实体当作同样的实体对待。在面向对象中,将对象的共同性质抽取出来形成类的过程即为抽象化的过程。
- 实现化:针对抽象化给出的具体实现,就是实现化,抽象化与实现化是一对互逆的概念,实现化产生的对象比抽象化更具体,是对抽象化事物的进一步具体化的产物。
- 脱耦:脱耦就是将抽象化和实现化之间的耦合解脱开,或者说是将它们之间的强关联改换成弱关联,将两个角色之间的继承关系改为关联关系。桥接模式中的所谓脱耦,就是指在一个软件系统的抽象化和实现化之间使用关联关系(组合或者聚合关系)而不是继承关系,从而使两者可以相对独立地变化,这就是桥接模式的用意。
在以下情况下可以使用桥接模式:
- 如果一个系统需要在构件的抽象化角色和具体化角色之间增加更多的灵活性,避免在两个层次之间建立静态的继承联系,通过桥接模式可以使它们在抽象层建立一个关联关系。
- 抽象化角色和实现化角色可以以继承的方式独立扩展而互不影响,在程序运行时可以动态将一个抽象化子类的对象和一个实现化子类的对象进行组合,即系统需要对抽象化角色和实现化角色进行动态耦合。
- 一个类存在两个独立变化的维度,且这两个维度都需要进行扩展。
- 虽然在系统中使用继承是没有问题的,但是由于抽象化角色和具体化角色需要独立变化,设计要求需要独立管理这两者。
- 对于那些不希望使用继承或因为多层次继承导致系统类的个数急剧增加的系统,桥接模式尤为适用。
适配器模式与桥接模式的联用:
- 桥接模式和适配器模式用于设计的不同阶段,桥接模式用于系统的初步设计,对于存在两个独立变化维度的类可以将其分为抽象化和实现化两个角色,使它们可以分别进行变化;而在初步设计完成之后,当发现系统与已有类无法协同工作时,可以采用适配器模式。但有时候在设计初期也需要考虑适配器模式,特别是那些涉及到大量第三方应用接口的情况。
- 换句话说,类无法协同工作的意思是各个类的所需的参数之类的都不同,很难组合到一起工作,就可以使用适配器模式,给这些类外面包一层。
所以我们看到,两个不同的类,抽象和实现可以沿着自己的维度独立的变化。
装饰模式 (Decorator)
装饰模式的核心思想是:不通过继承,而是通过组合的方式来进行对象功能的扩展。
结构
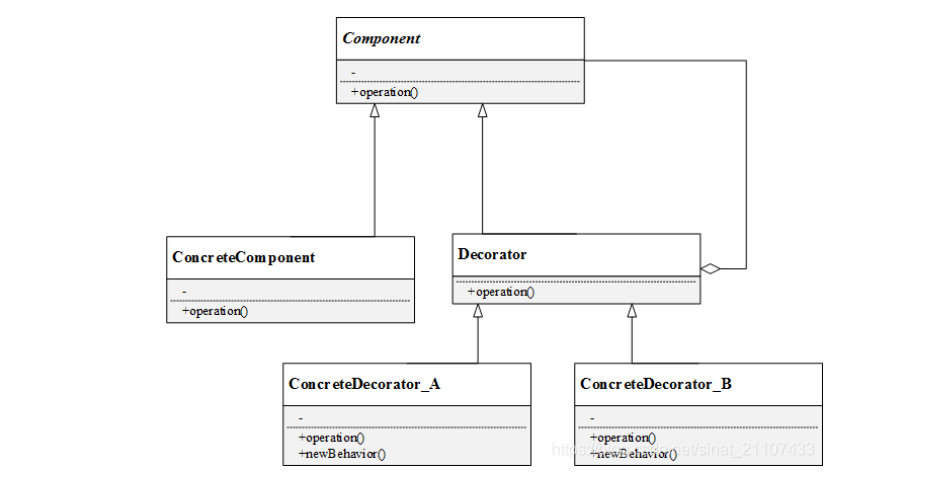
- Component(抽象构件)︰是具体构件类和装饰类的共同基类,声明了在具体构件中定义的方法,客户端可以一致的对待使用装饰前后的对象
- ConcreteComponent(具体构件)︰具体构件定义了构件具体的方法,装饰类可以给它增加更多的功能;
- Decorator(抽象装饰类)∶用于给具体构件增加职责,但具体职责在其子类中实现。抽象装饰类通过聚合关系蕴含一个抽象构件的对象,通过该对象可以调用装饰之前构件的方法,并通过其子类扩展该方法,达到装饰的目的;
- ConcreteDecorator(具体装饰类)︰向构件增加新的功能。
例子就是我们假设现在有手机,我们需要给手机贴膜,加手机壳,加挂绳。我们如果不通过继承的方式而是通过组合的方式实现就可以使用装饰模式。
在这里我们的代码中,手机和抽象装饰类共同继承抽象构件接口。同时,抽象装饰类保有一个抽象构件的对象。为什么既要继承又要包含呢?查看我们的项目代码decorate.cpp,我们发现在main中,我们的每一个指针,无论是语义上的具体构件,还是具体装饰类,我们统一赋值给了抽象构件类。
这样做的第一个好处是我们可以把装饰器类的指针当成
component的指针。也就是把装饰器对象当做一个component对象去使用。比较符合语义。第二点是,不继承的话不符合链式装饰语义。因为每一个具体装饰器类都是接受
component来构造。
而链式装饰要求把每一个装饰过的装饰器指针当做component传入。如果不继承component的话,无法当做component传入。因为没有多态性。比如115行的Decorator *PhoneRope = new DecoratorRope(PhoneSticker2);。这是一种递归的函数调用。每次我们先getComponent,所以先拿到贴纸的装饰器对象,然后调用对应的函数调用运算符。然后在里面继续拿,拿到了手机壳的装饰器对象,然后继续调用对应的函数调用运算符,直到拿到了component类对象,这时候不拿了,直接调用。然后再依次弹出。
和模板结合以产生静态装饰
我们有没有发现上面的模式有一个缺点?因为具体构件和抽象装饰类都是继承自抽象构件。所以说他们俩的共同接口就是抽象构建提供的几个接口。假设具体构件有一些自己独特的函数,我们应该怎么做?可以采用Mixin方法搭配完美转发。这个例子有点复杂并且和我们上面的例子不太一样。因为使用了Mixin,所以抽象装饰类不见了。每一个具体装饰类都继承自模板参数T,而且这个T不再是抽象构件,而是具体构件了。因为我们不再依赖于接口的动态。改为依赖模板的静态了。同时,由于我们继承的是T类,也就是具体构件,所以我们必须使用完美转发来直接调用T类的构造函数。同时,如果我们的具体装饰类有一些自己的参数需要传入,也很方便实现,只需要拆分可变参数就可以了。
优点
- 装饰模式与继承关系的目的都是要扩展对象的功能,但是装饰模式可以提供比继承更多的灵活性。
- 可以通过一种动态的方式来扩展一个对象的功能,通过配置文件可以在运行时选择不同的装饰器,从而实现不同的行为。
- 通过使用不同的具体装饰类以及这些装饰类的排列组合,可以创造出很多不同行为的组合。可以使用多个具体装饰类来装饰同一对象,也就是堆一个对象进行多次装饰以得到功能更为强大的对象。
- 具体构件类与具体装饰类可以独立变化,用户可以根据需要增加新的具体构件类和具体装饰类,在使用时再对其进行组合,原有代码无须改变,符合“开闭原则”
缺点
- 使用装饰模式进行系统设计时将产生很多小对象,这些对象的区别在于它们之间相互连接的方式有所不同,而不是它们的类或者属性值有所不同,同时还将产生很多具体装饰类。这些装饰类和小对象的产生将增加系统的复杂度,加大学习与理解的难度。
- 这种比继承更加灵活机动的特性,也同时意味着装饰模式比继承更加易于出错,排错也很困难,对于多次装饰的对象,调试时寻找错误可能需要逐级排查,较为烦琐。
## 总结
- 在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
- 需要动态地给一个对象增加功能,这些功能也可以动态地被撤销。
- 当不能采用继承的方式对系统进行扩充或者采用继承不利于系统扩展和维护时。不能采用继承的情况主要有两类:第一类是系统中存在大量独立的扩展,为支持每一种组合将产生大量的子类,使得子类数目呈爆炸性增长;第二类是因为类定义不能继承(如final类).
- 一个装饰类的接口必须与被装饰类的接口保持相同,对于客户端来说无论是装饰之前的对象还是装饰之后的对象都可以一致对待。
- 尽量保持具体构件类Component作为一个“轻”类,也就是说不要把太多的逻辑和状态放在具体构件类中,可以通过装饰类
对其进行扩展。 - 如果只有一个具体构件类而没有抽象构件类,那么抽象装饰类可以作为具体构件类的直接子类。
组合模式 (Composite)
组合模式的核心在于解决树状组合结构的管理。
结构
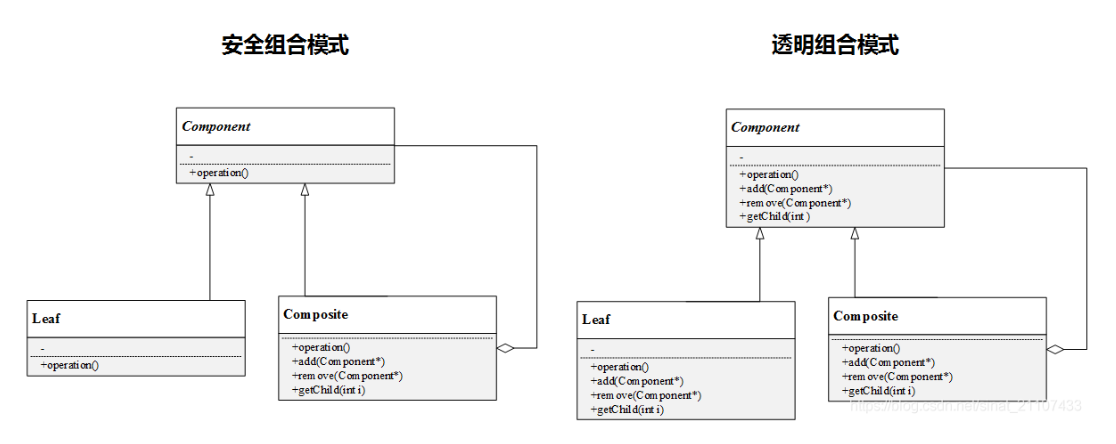
- Component(抽象构件): Component是一个抽象类,定义了构件的一些公共接口,这些接口是管理或者访问它的子构件的方法(如果有子构件),具体的实现在叶子构件和容器构件中进行。
- Leaf(叶子构件)︰它代表树形结构中的叶子节点对象,叶子构件本身在一般情况下没有子节点,它是我们需要通过树状组织来管理的具体节点。叶子构件它实现了在抽象构件中定义的行为。对于抽象构件定义的管理子构件的方法,叶子构件可以通过抛出异常、提示错误等方式进行处理。
- Composite(容器构件)︰容器构件在一方面具体实现公共接口,另一方面通过聚合关系包含子构件,子构件可以是容器构件,也可以是叶子构件。也就是说,容器构件一般来说会有一个
vector或其他的容器来储存所有的Component*/&对象。因为容器构件本身也继承自Component,所以容器构件可以包含容器构件,形成一种嵌套,也就是树状的关系。
之所以区分安全组合模式和透明组合模式,是因为叶子构件不应该具有如添加,移除,获得叶子结点的操作。透明模式的优点是可以通过抽象构件接口获知全部动作,客户端可以一致的对待所有对象。缺点是可能会无意间调用叶子构件类的几个不应提供的函数。所以需要妥善处理。
而安全组合模式中,我们就不能通过抽象构件接口获知全部动作,客户端就要进行区别对待。尽管较为安全,但是不够透明。
优点
- 清楚地定义分层次的复杂对象,表示出复杂对象的层次结构,让客户端忽略层次的差异。
- 客户端可以一致地使用层次结构中各个层次的对象,而不必关心其具体构件的行为如何实现。
- 在组合模式中增加新的叶子构件和容器构件非常方便,易于扩展,符合开闭原则。
- 为树形结构的案例提供了解决方案。
缺点
- 子构件或容器构件的行为受限制,因为它们来自相同的抽象层。如果要定义某个容器或者某个叶子节点特有的方法,那么要求在运行时判断对象类型,增加了代码的复杂度。
- 此处可以使用CRTP方法来实现所谓的定义某个容器或叶子结点特有的方法。
技巧
有时候我们可以把单个对象当成一个组合(容器对待),方法就是提供begin()和end()函数。
具体实现可以像是这样:
1
2
3
4
5
6
Foo* begin(){
return this;
}
Foo* end(){
return this+1;
}
这样,这个单个对象会表现的和含有一个对象的容器一样。
总结
组合模式的核心在于解决树状组合结构的管理。在系统中需要用到树形结构和系统中能够分离出容器节点和叶子节点的时候比较适合使用。在具有整体和部门的层次结构中,能够通过某种方式忽略层次差异,使得客户端可以一致对待。
组合模式通过和装饰模式有着类似的结构图,但是组合模式旨在构造类,而装饰模式重在不生成子类即可给对象添加职责。装饰模式重在修饰,而组合模式重在表示
代理模式 (Proxy)
我们曾经在MoreEffectiveC++中的条款30曾经提到过代理类。那是代理模式的一种之一。我们在这里讨论一些比较宽泛,简单,易于理解的代理模式。
代理模式的核心是创造出一个真实对象的替身,在客户端眼里,代理对象的行为和真实对象应该是一模一样的。而在幕后,可以进行一些功能的附加。比如说记录日志,增加引用计数等等。所以我们最常见的智能指针就是代理模式的一个经典例子。
结构
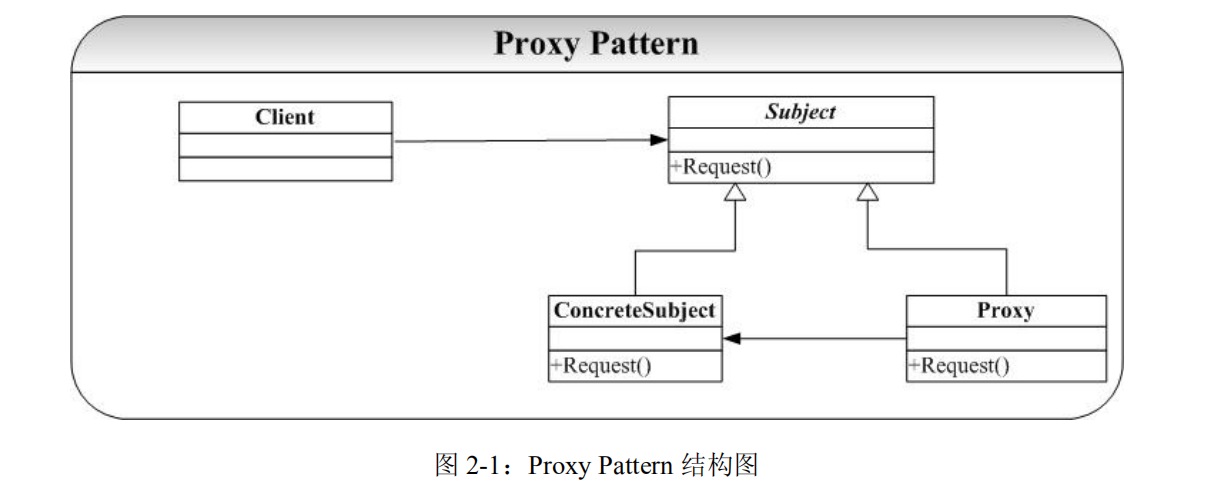
- 抽象主题角色(Subject):声明了代理主题角色和真实主题角色共同的一些接口,因此在任何可以使用真实主题对象的地方都可以使用代理主题角色,这就是我们说的代理对象的行为和真实对象应该是一模一样的,客户端通常针对抽象主题编程。
- 代理主题角色(Proxy):代理主题角色通过关联关系引用真实主题角色,因此可以控制和操纵真实主题对象。代理主题角色中提供一个与真实主题角色相同的接口(以在需要时代替真实主题角色),同时还可以在调用对真实主题对象的操作之前或之后增加新的服务和功能
- 真实主题角色(ConcreteSubject或RealSubject):真实主题角色是代理角色所代表的真实对象,提供真正的业务操作,客户端可以通过代理主题角色间接地调用真实主题角色中定义的操作。
一般来说,代理角色Proxy会蕴含真实角色ConcreteSubject。同时,如果想在幕后执行其他操作,也可以蕴含其他操作的对象。
在实际开发过程中,代理模式产生了很多具体化的类型:
- 远程代理(Remote Proxy):为一个位于不同地址空间的对象提供一个本地的代理对象。不同的地址空间可以在相同或不同的主机中。
- 虚拟代理(Virtual Proxy):当创建一个对象需要消耗大量资源时,可以先创建一个消耗较少资源的虚拟代理来表示,当真正需要时再创建。延迟加载时机。
- 这部分查看代码
proxy_virtual.cpp
- 这部分查看代码
- 保护代理(Protect Proxy)︰给不同的用户提供不同的对象访问权限。
- 缓冲代理(Cache Proxy)︰为某一个目标操作的结果提供临时存储空间,以使更多用户可以共享这些结果。
- 智能引用代理(Smart Reference Proxy):当一个对象被引用时提供一些额外的操作,比如将对象被调用的次数记录下来等。比如智能指针
优点
- 代理模式能够协调调用者和被调用者,降低系统耦合度;
- 客户端针对抽象主题角色编程,如果要增加或替换代理类,无需修改源代码,符合开闭原则,系统扩展性好
- 远程代理优点:为两个位于不同地址空间的对象的访问提供解决方案,可以将一些资源消耗较多的对象移至性能较好的计算机上,提高系统整体性能;
- 虚拟代理优点:通过一个资源消耗较少的对象来代表一个消耗资源较多的对象,节省系统运行开销;
- 缓冲代理优点:为某一个操作结果提供临时的存储空间,可以在后续操作中使用这些结果,缩短了执行时间;
- 保护代理优点:控制对一个对象的访问权限,为不同客户提供不同的访问权限。
缺点
- 由于在客户端和真实主题之间增加了代理对象,因此 有些类型的代理模式可能会造成请求的处理速度变慢。
- 实现代理模式需要额外的工作,有些代理模式的实现 非常复杂。
总结
我们反复强调了,代理代理模式中,代理对象对用户暴露的行为应该和真实对象一致。这也是代理模式和装饰器模式的核心区别。
- 代理模式和装饰器模式的区别:
- 代理模式提供的是一个行为完全一致的接口。而装饰器则是一种已有接口的增强(添加功能)。
- 代理模式并不一定要含有一个需要代理的对象。而装饰器模式基本都需要含有一个需要装饰的对象。
- 代理模式(尤其是虚拟代理模式)中,代理对象可以在不创建真实对象的情况下工作。因为此时可能并不需要创建真实对象。
- 同时,我们可以针对不同需求来对代理模式进行不同的调整。
- 当客户端对象需要访问远程主机中的对象——可以使用远程代理
- 当需要用一个资源消耗较少的对象来代表一个资源消耗较多的对象——虚拟代理
- 当需要限制不同用户对一个独享的访问权限——保护代理
- 当需要为一个频繁访问的操作结果提供临时存储空间——缓冲代理;。当需要为一个对象的访问提供一些额外的操作——智能引用代理。
vector<bool>就是代理模式
行为型模式部分
行为型模式每一种都不太一样,尽管有一些之间可能长得比较像,但是行为型模式每一种都是有针对性的,它们有针对性地解决某一种特定的问题。行为型模式不仅仅关注类和对象的结构,而且重点关注它们之间的相互作用。通过行为型模式,可以更加清晰地划分类与对象的职责,并研究系统在运行时实例对象 之间的交互。在系统运行时,对象并不是孤立的,它们可以通过相互通信与协作完成某些复杂功能,一个对象在运行时也将影响到其他对象的运行。
责任链模式 (Chain of Responsibility)
责任链模式,顾名思义,一个链条。当我们的某一个对象需要在一个链条上面进行处理的时候,这个模式就大显神威了。什么叫链条上处理?其中一种比较简单的情况就是,根据一个条件的不同,需要层层递进去进行处理。比如请假,小于1天需要班主任批准,大于1天小于3天需要主任批准,大于3天需要校长批准。但是学生肯定是从班主任开始递交。如果某一个角色发现处理不了,则会“转发”至责任链的下一个人,让他去处理。以此类推。这种就是一个链条。
另一种比较常见的情况是,当我们有一个请求,比如一个游戏角色服用了增益药水。根据增益药水的种类不同,我们可能有不同的增益效果。这时候我们可以把所有的增益视为一种链条。依次把增益请求传递给增益链条上的每一个处理对象。每一个处理对象根据传进来的增益信息来判断是否需要当前处理对象进行操作。无论是否操作,都将增益请求传递给链条上的下一个处理对象。直到处理完毕。
通常情况下,这种链条会以一种链表的形式出现。也就是责任对象的衔接。
结构
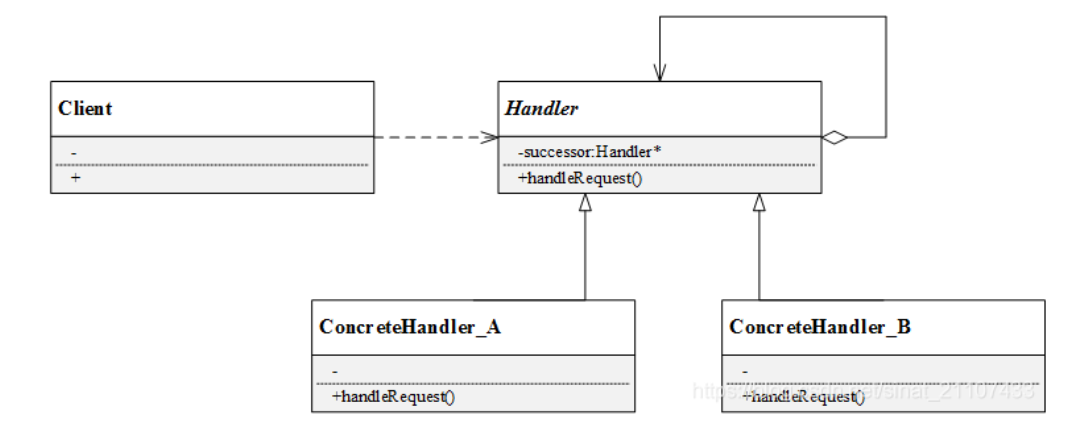
责任链模式本身结构比较简单,包含两个角色:
- Handler(抽象处理者)︰抽象处理者一般为抽象类,声明了一个处理请求的接口
handleRequest(),定义了一个抽象处理者类型的对象,作为其对下游处理者的引用,通过该引用可以形成一条责任链。 - ConcreteHandler(具体处理者)︰是抽象处理者的子类,实现了处理请求的接口。在具体的实现中,如果该具体处理者能够处理该请求,就处理它,否则将该请求转发给后继者。具体处理者可以访问下一个对象。
由上述可知,在职责链模式中很多对象由每一个对象对其下家的引用连接起来形成一条链条,请求在这个链条上逐级传递,知道某一级能够处理这个请求为止。客户端不知道也不必知道是哪一级处理者处理了该请求,因为每个处理者都有相同的接口handleRequest()。接下来通过一个实例来进一步认识职责链模式。
优点
- 将请求的接收者和处理者解耦,客户端无需知道具体处理者,只针对抽象处理者编程,简化了客户端编程过程,降低系统耦合度
- 在系统中增加一个新的处理者时,只需要继承抽象处理者,重新实现
handleRequest()接口,无需改动原有代码,符合开闭原则 - 给对象分配职责时,职责链模式赋予系统更多灵活性。
缺点
- 请求没有一个明确的接收者,有可能遇到请求无法响应的问题
- 如果有比较长的职责链,其处理过程会很长。
- 建立职责链的工作是在客户端进行,如果建立不当,可能导致循环调用或者调用失败。
总结
适用环境:
- 有多个对象处理同一个请求,具体由谁来处理是在运行时决定,客户端只需发出请求到职责链上,而无需关心具体是谁来处理
- 可动态指定一组对象处理请求,客户端可以动态创建职责链来处理请求,还可以改变职责链中各个处理者之间的上下级关系。
- 同时,责任链模式也经常搭配中介者模式和观察者模式。它可以非常简单,也可以非常复杂。我们后面会用额外例子说明。
命令模式 (Command)
在软件设计中,我们经常需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个,我们只需在程序运行时指定具体的请求接收者即可,此时,可以使用命令模式来进行设计,使得请求发送者与请求接收者消除彼此之间的耦合,让对象之间的调用关系更加灵活。
命令模式可以对发送者和接收者完全解耦,发送者与接收者之间没有直接引用关系,发送请求的对象只需要知道如何发送请求,而不必知道如何完成请求。这就是命令模式的模式动机。
举个例子:
- 鼠标点击某个键,就好像用户在向图片浏览器发送指令,图片浏览器内部接收到指令后开始调用相应的函数,最终结果是播放上一张或下一张图片,即执行或响应了用户发出的命令。客户并不知道发出的命令是什么形式,也不知道图片浏览器内部命令是如何执行的;同样,浏览器内部也不知道是谁发送了命令。命令的发送方和接收方(执行方)没有任何关联。
命令模式的命令是一个对象,是一个命令的载体。也就是说,我们把命令这个行为封装成一个对象
- 要正确区分命令command和请求query的区别
- 命令作用于对象上的时候通常会导致对象状态被修改。比如请求某些动作,或请求某些更改。也就是说,命令强调了对状态的修改。
- 请求作用于对象的时候通常不会导致对象状态的修改。比如请求某些信息。也就是说,请求强调的是信息的获取。
结构
- Command:抽象命令类
- 一般只有一个
execute执行接口。
- 一般只有一个
- ConcreteCommand:具体命令类。
- 这个类会实现
execute执行接口。它对应具体的接收者对象。也就是一般来说,每一个对象都会有一个对应的具体命令类。将接收者的动作(action)绑定其中。 execute执行的就是接受者的动作。
- 这个类会实现
- Invoker:调用者类
- 请求的发送者。通过命令对象来执行请求。一个调用者不需要在设计时确定接收者。所以调用者通过聚合或注入与命令类产生关联。也就是可以将一个具体命令对象注入到调用者中,再通过调用具体命令对象的
execute实现间接请求命令执行者(接收者)的操作。
- 请求的发送者。通过命令对象来执行请求。一个调用者不需要在设计时确定接收者。所以调用者通过聚合或注入与命令类产生关联。也就是可以将一个具体命令对象注入到调用者中,再通过调用具体命令对象的
- Receiver:接收者类
- 一般实现处理请求的具体操作。也就是实现我们命令执行的动作(action)。
- Client:客户类
- 在我们实例里客户就是
main
- 在我们实例里客户就是
流程
较为复杂 参考代码。
命令队列模式
有时候,当请求者发送一个请求时,有不止一个接收者产生响应(Qt信号槽,一个信号可以连接多个槽),这些接收者将逐个执行业务方法,完成对请求的处理,此时可以用命令队列来实现。比如按钮开关同时控制电灯和风扇,这个例子中,请求发送者是按钮开关,有两个接收者产生响应,分别是电灯和风扇。
比如在代码中,我们设置一个命令队列。里面可以储存不同的命令。然后请求者只需要使用一次touch(包含命令队列类的execute)就可以执行所有的命令。
执行过程就是请求者使用touch调用命令队列类的execute,命令队列再依次调用所有具体命令类的execute来完成具体执行。
命令队列+组合模式 = 组合命令模式(宏命令)
查看command_composite.cpp
这种就稍微复杂了,并且和业务绑定的比较紧密。但是核心还是这两个模式的核心。
组合命令本身也是一个具体命令,不过它包含了对其他命令对象的引用,在调用宏命令的execute()方法时,将递归调用它所包含的每个成员命令的execute()方法,一个宏命令的成员对象可以是简单命令,还可以继续是宏命令。执行一个宏命令将执行多个具体命令,从而实现对命令的批处理。是不是非常像组合模式?
优点
- 降低系统的耦合度。
- 新的命令可以很容易地加入到系统中。
- 可以比较容易地设计一个命令队列和宏命令(组合命令)。
- 宏命令也就是上面提到的组合命令模式
- 可以方便地实现对请求的Undo和Redo。
缺点
- 使用命令模式可能会导致某些系统有过多的具体命令类。因为针对每一个命令都需要设计一个具体命令类(符合我们说的,每一个命令都是一个对象),因此某些系统可能需要大量具体命令类,这将影响命令模式的使用。
总结
- 可以看到,客户端只需要有一个调用者和抽象命令类,在给调用者注入命令时,再将命令类具体化。这也就是定义中“可用不同的请求对客户进行参数化”的体现。客户端并不知道命令是如何传递和响应,只需发送命令
touch()即可,由此实现命令发送者和接收者的解耦。 如果系统中增加了新的功能,功能键与新功能对应,只需增加对应的具体命令类,在新的具体命令类中调用新的功能类的
action()方法,然后将该具体命令类通过注入的方式使调用者可以执行,无需修改原有代码,符合开闭原则。- 在以下情况下可以使用命令模式:
- 系统需要将请求调用者和请求接收者解耦,使得调用者和接收者不直接交互。
- 系统需要在不同的时间指定请求、将请求排队和执行请求。
- 系统需要支持命令的撤销(Undo)操作和恢复(Redo)操作。
- 系统需要将一组操作组合在一起,即支持宏命令
- 命令模式在STL中也有很多地方使用了。但是这种命令模式和策略模式很像。我们在策略模式中说明了如何区分。:

迭代器模式(Iterator)
迭代器模式的核心就是为某一种数据结构提供一种遍历(顺序或随机访问)的方式。
其整体实现可繁可简,因为就相当于是实现了一个迭代器。但是具体功能的多少,完全取决于具体业务。
结构
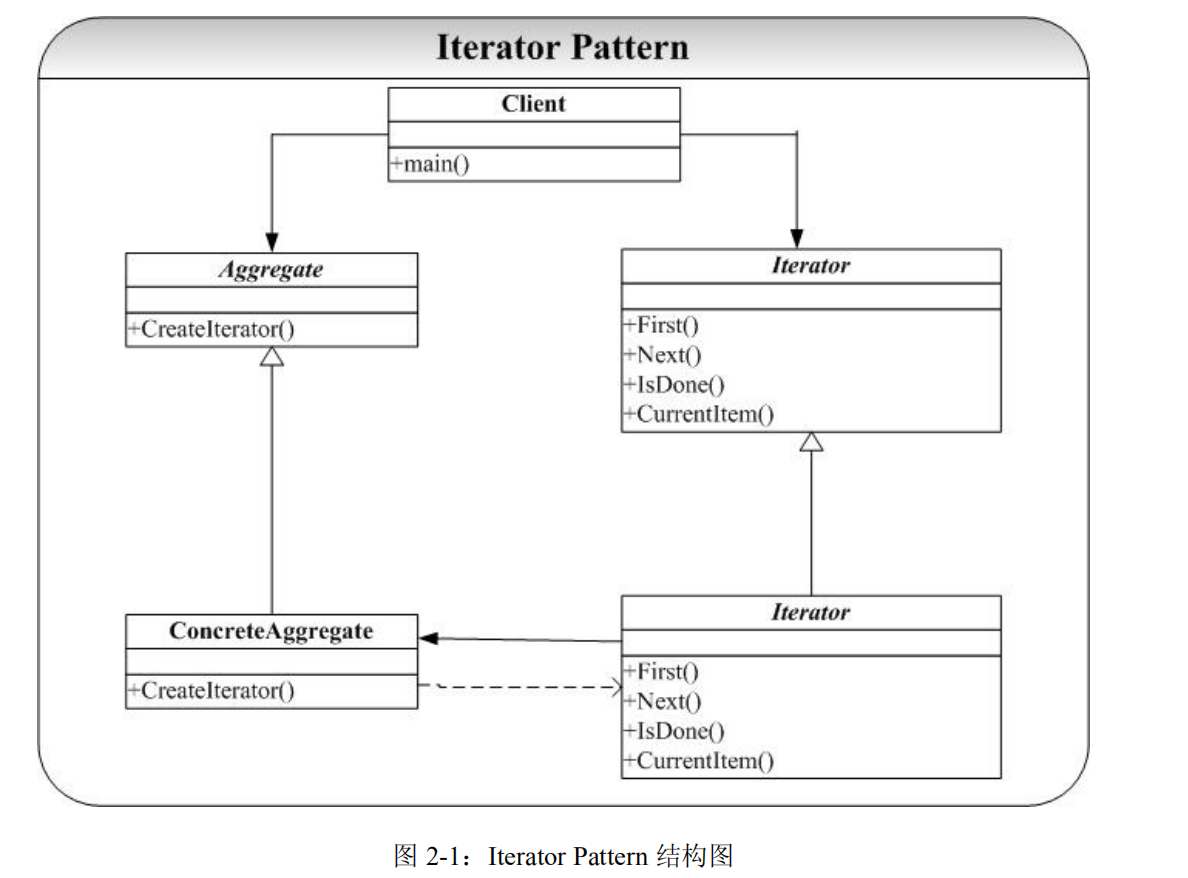
- lterator(抽象迭代器)︰声明了访问和遍历聚合对象元素的接口,如
first()方法用于访问聚合对象中第一个元素,next()方法用于访问下一个元素,hasNext()判断是否还有下一个元素,currentltem()方法用于获取当前元素。 - Concretelterator(具体迭代器)︰实现抽象迭代器声明的方法,通常具体迭代器中会专门用个变量来记录迭代器在聚合对象中所处的位置。
- 具体迭代器类包含一个具体聚合类的的指针。一定要注意。
- 在我们的代码里就是
RemoteControl类有一个Television类的指针。
- 在我们的代码里就是
- 具体迭代器类包含一个具体聚合类的的指针。一定要注意。
- Aggregate (抽象聚合类)︰用于存储和管理元素对象,声明一个创建迭代器的接口,其实是个抽象迭代器工厂的角色。
- ConcreteAggregate(具体聚合类)∶实现了方法
CreateIterator(),该方法返回一个与该具体聚合类对应的具体迭代器Concretelterator的实例。- 这时候通常需要前向声明
优点
- 支持以不同的方式遍历一个聚合对象,在同一个聚合对象上可以定义多个遍历方式。
- 简化了聚合类,使得聚合类的职责更加单一
- 迭代器模式中引入抽象层,易于增加新的迭代器类,便于扩展,符合开闭原则。
缺点
- 将聚合类中存储对象和管理对象的职责分离,增加新的聚合类时同样需要考虑增加对应的新的迭代器类,类的个数成对增加,不利于系统管理和维护
- 设计难度极大,需要充分考虑将来系统的扩展。尤其是涉及到模板的时候。
总结
其实我不太认为平时有需要自己设计迭代器。理解STL的迭代器的精髓就已经足够了。
中介者模式 (Mediator)
中介者模式的核心是使得需要互相交互的对象解耦。
用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。中介者模式又称为调停者模式,它是一种对象行为型模式。
也就是说,原本互相需要交互的对象不需要维护互相的引用。他们共同被中介者管理。
结构
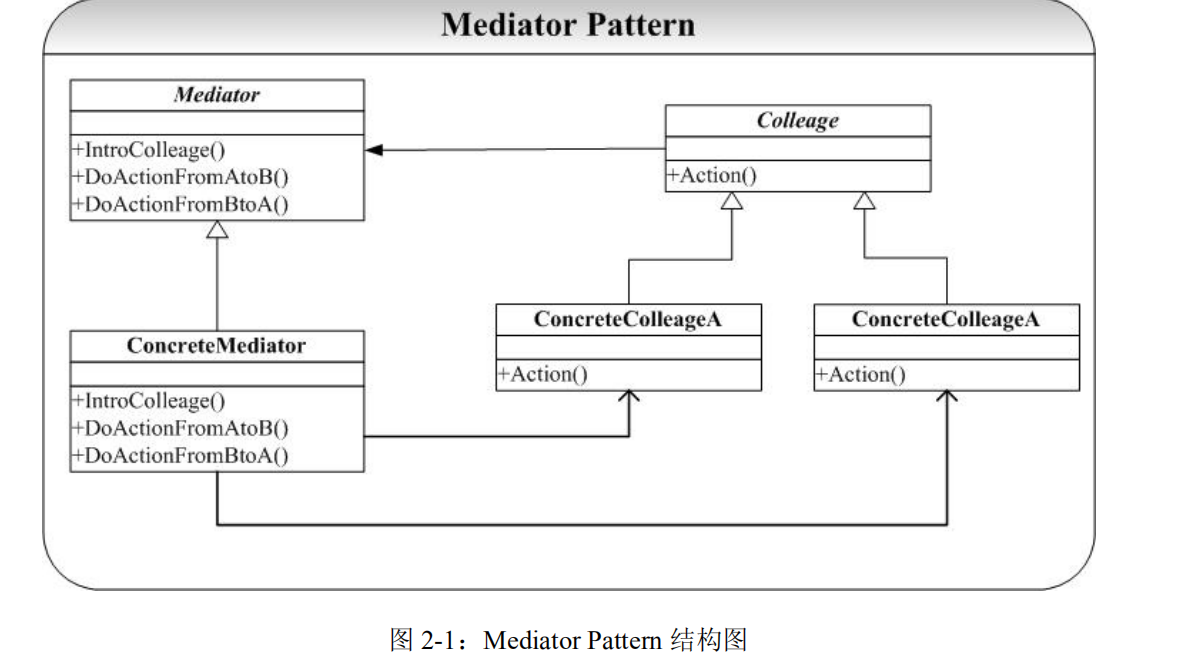
- Mediator(抽象中介者):声明一个用于与各个同事对象之间交互的接口,通常声明一个注册方法,用于增加同事对象
- ConcreteMediator(具体中介者):实现上面的接口,协调各个同事对象来实现协作行为,维持对各个同事对象的引用
- 一般来说,会有一个或多个容器在具体中介者内存储同事类对象的指针。
- 一般来说中介者是单例类。
- Colleague(抽象同事类):声明各个同事类公有的接口,同时维持了一个对抽象中介者类的引用
- concreteColleague(具体同事类):具体实现接口,具体同事类只需与中介者通信,通过中介者完成与其他同事类的通信。
我们刚提到了,原本互相需要交互的对象不需要维护互相的引用。他们共同被中介者管理。所以我们再次强调,一般来说,中介者会维护各个同事类对象的指针,而同事类维护一个中介类的指针。这样就达成了同事类通过中介类和其他同事类交互的目的。
优点
- 简化了对象之间的交互,通过中介者,对象之间的多对多关系就简化了相对更简单的一对多关系
- 可将各个同事对象解耦,利于各个同事之间的松散耦合,可独立地改变和复用每一个同事对象,增加新的中介者和同事都比较方便,符合开闭原则
- 可减少子类生成,将原本分布于多个对象之间的行为封装在一起,只需生成新的具体中介者类就可以改变这些行为
缺点
- 在具体中介者类中包含了同事之间的交互细节,可能会导致具体中介者类非常复杂,使得系统难以维护。
总结
中介者承担了两个层次的职责:
- 结构上起中转作用
- 通过中介者的中转,各个同事类的对象之间不必再相互显式的调用,或持有,只需通过中介者就可以实现交互。
- 行为上起协调作用
- 中介者可以进一步地将各个同事类之间的关系进行封装,同事类对象可以一致地和中介者进行交互,而不必指出中介者具体该如何操作,中介者根据封装在自身内部的协调逻辑对同事类对象的请求进一步处理,将同事类对象之间的关系行为进行分离和封装。
所以一般来说,当:
- 系统中的对象之间存在复杂的交互关系,使得系统内逻辑错综复杂,难以管理
- 一个对象引用了其他很多对象,并直接和这些对象交互,导致该对象难以复用。
如上这几种情况发生的时候,可以考虑使用中介者模式。
备忘录模式(Memento)
备忘录模式,顾名思义。目的是提供一种保存某一对象当前状态的方法。
换句话说,就是快照。我们提供一种方法让我们可以保存某一对象的某一个状态,一般情况下会同时提供Undo和Redo的功能
在不破坏封装的前提下捕获一个对象的内部状态,并在该对象之外保存这个状态,这样可以在以后将对象恢复到原先保存的状态。
结构
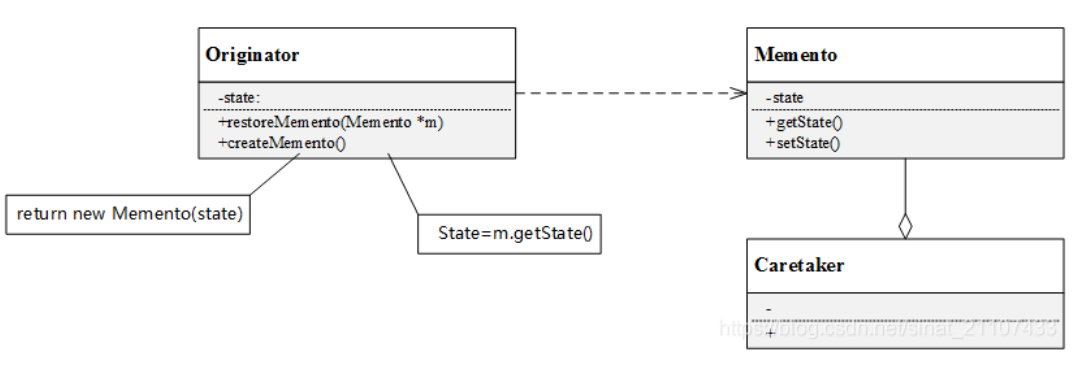
- Originator(原发器)︰这就是我们的业务代码,通常是将系统中需要保存内部状态的类设计为原发器。提供一个方法通过创建一个备忘录对象存储当前的内部状态,也可以使用备忘录来恢复其内部状态。
- 重申,业务代码也就是原发器当中需要有两个方法。一个是类似于
restore,即通过一个备忘录memento来恢复状态。一个是类似于save或者是create,即创建一个memento备忘录对象。
- 重申,业务代码也就是原发器当中需要有两个方法。一个是类似于
- Memento(备忘录)∶用于存储原发器的内部状态。备忘录的设计可以参考原发器的设计,根据需要确定备忘录类中的属性。除了原发器类对象,不允许其他对象修改备忘录。
- 备忘录对象里面存储的就是我们业务代码原发器对象希望让我们存储的。
- Caretaker(负责人)︰负责保存备忘录,可以存储一个或多个备忘录对象,但是负责人只负责保存对象,不能修改对象,也不必知道对象的实现细节。负责人可以存储多个备忘录对象,以实现undo和redo操作。
- 负责人负责保管所有的备忘录对象。
优点
- 实现状态恢复、撤销操作的功能,用户可以恢复到指定的历史状态,让软件系统更加人性化
- 备忘录封装了信息,除了原发器以外,其他对象访问不了备忘录的代码;
缺点
资源消耗大。如果需要保存原生器对象的多个历史状态,那么将创建多个备忘录对象;或者如果原生器对象的很多状态都需要保存,也将消耗大量存储资源。
总结
感觉没什么用。资源消耗比较大。
状态模式 (State)
个人理解就是把状态机换成了OOP。
状态模式将一个对象的状态从对象中分离出来,封装到专门的状态类中,使得对象状态可以灵活变化。对于客户端而言,无需关心对象状态的转换和当前状态。
状态模式定义:
- 允许一个对象在其内部状态改变时改变它的行为。对象看起来似乎修改了它的类。
结构
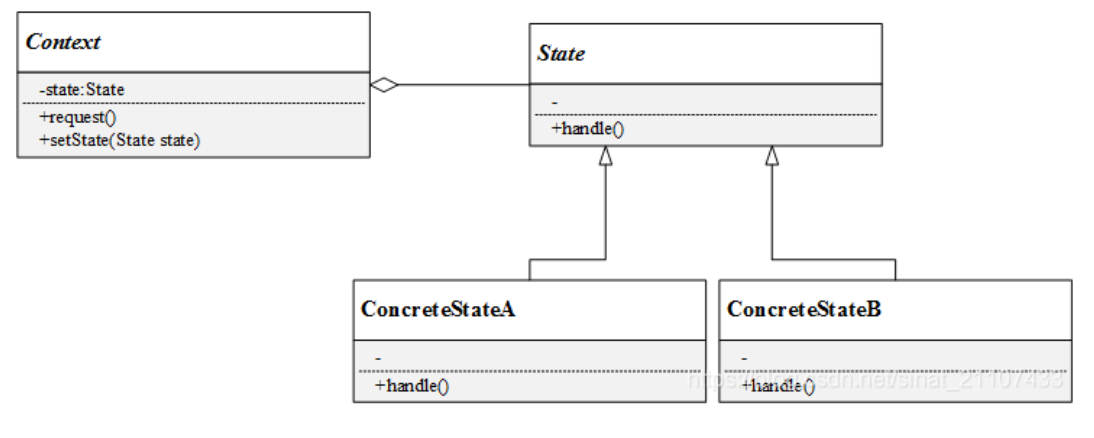
- Context: 上下文类
- 是拥有多种状态的对象。上下文类的状态存在多样性,并且在不同的状态下,对象表现出不同的行为。在上下文类中,维护了一个抽象状态类的实例。
- State:抽象状态类
- 声明了一个接口,用于封装与在上下文类中的一个特定状态相关的行为在子类中实现在各种不同状态对应的方法。不同的子类可能存在不同的实现方法,相同的方法可以写在抽象状态类中。
- ConcreteState:具体状态类
- 实现具体状态下的方法。每一个具体状态类对应一个具体的状态。
- 值得注意的是,上下文中维护了一个状态类的指针或者引用,可以由上下文类来决定具体实例化为哪一个具体的状态对象,也可以由具体的状态类来决定转换为哪一个实例,所以根据实际的业务逻辑的不同,上下文类和状态类之间存在依赖甚至相互引用的关系
流程
搭配代码理解下面内容。
- 这段代码的宗旨是,在使用账户游玩游戏的时候,账户等级随着输赢变化。等级不同又会有不同的游玩技能。
- 所以我们账户内部需要有一个等级的实例。然后通过这个等级去调用不同等级的方法。多态可以天然完成这个行为。
- 每一次在给账户类设置新的等级实例的时候,需要记得回收旧的等级实例的内存。
- 等级类也有一个指向账户的指针用于获取账户信息。每次初始化等级实例的时候都需要设置账户。
每次升级的时候,先在等级类的构造函数内把新的等级类和账户类绑定,然后把当前帐户的等级类设置为新的等级类。
- 上面的代码不管我们账户当前是什么级别,都统一地调用了上下文类封装好的方法
playcard(),即外界并不知道不同级别内部的具体实现细节。运行结果显示,账户的在不同的状态(级别)下能够表现不同的行为(不同的技能),并且能够不断改变自身的状态(升级或降级)。
优点
- 封装了转换规则。
- 枚举可能的状态,在枚举状态之前需要确定状态种类。
- 将所有与某个状态有关的行为放到一个类(具体状态类)中,可以方便地增加新的状态,只需要注入(依赖)不同的状态类对象到上下文类中,即可使上下文类拥有不同的行为。
- 允许状态转换逻辑与状态对象合成一体,而不是某一个巨大的条件语句块。可以让多个环境对象共享一个状态对象,从而减少系统中对象的个数。
缺点
- 状态模式增加了系统中类的个数(不同的具体状态类)。
- 结构相对复杂(如前述实例的UML图),代码逻辑也较复杂。
- 如果要增加新的状态,需要修改负责状态转换的代码,不符合开闭原则。
- 如上述实例,如果增加了一个中间级别,就要修改很多状态转换的逻辑
总结
对开闭原则不太友好。个人理解为适用于if else状态非常多的场景。比如HTTP报文解析,TCP链接等。这种场景下一般很少去修改或增删新的状态了。
适用环境:
- 对象的行为根据它的状态的改变而不同
- 代码中含有大量与对象状态有关的判断逻辑(if else或switch case)
观察者模式(Observer)
观察者模式定义:定义对象之间的一种一对多(变化)的依赖关系。以便当一个对象的状态发生改变时,所有依赖他的对象都会得到通知并自动更新。
简而言之就是如果一个对象被改变了,其他所有我们有关联(被注册)的对象都会得到通知并产生对应的行为。
结构
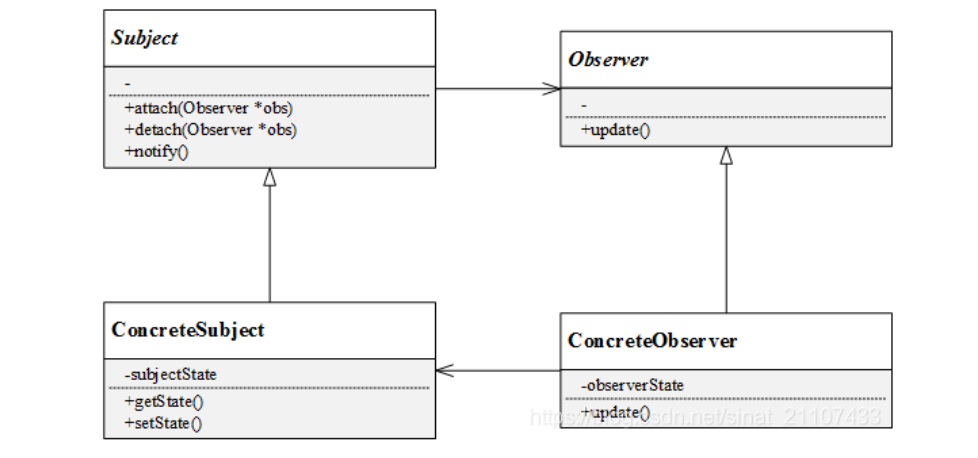
- Subject:被观察者的抽象类。
- 通常这个类会有注册,和取消注册两个方法来进行观察者的管控。也就是控制有多少个对象需要观察这个被观察对象,也就是多少个对象依赖于被观察者。
- 被观察者通常会有个容器。储存所有的观察者
- 同时会有一个
notify函数用于在自身状态改变的时候通知观察者。- 典型实现是遍历同期内所有的观察者,调用所有观察者的
update
- 典型实现是遍历同期内所有的观察者,调用所有观察者的
- Concrete Subject:被观察者的具体目标类。
- 通常会实现这个
notify通知方法。 - 同时具体目标会拥有自身的属性和成员方法。
- 通常会实现这个
- Observer:观察者的抽象类。
- 通常观察者会接收到观察对象的状态改变消息。所以观察者需要有
update来在接收到状态改变消息的时候改变自身状态。
- 通常观察者会接收到观察对象的状态改变消息。所以观察者需要有
- ConcereteObserver:观察者的具体目标类。
- 通常会实现更新方法
update。 - 具体观察者中维护了一个具体目标对象中的引用或指针用来储存目标的状态
- 具体观察者的意义是什么?我们可以理解为体观察者指的是对某个对象(被观察者)的某个部分或整体(消息)感兴趣的对象。
- 所以一个被观察者可以有多个观察者。因为感兴趣的部分不同。
- 通常会实现更新方法
- 通常,观察者模式需要使用前向声明。因为有互相包含的关系。
流程
参见代码。过长导致此处放不下。
优点
观察者模式实现了稳定的消息更新和传递的机制,通过引入抽象层可以扩展不同的具体观察者角色
支持广播通信,所有已注册的观察者(添加到目标列表中的对象)都会得到消息更新的通知,简化了一对多设计的难度
- 在我们的实例里就是遍历装有观察者的容器。
符合开闭原则,增加新的观察者无需修改已有代码,在具体观察者与观察目标之间不存在关联关系的情况下增加新的观察目标也很方便。
- 增加新的观察者在我们的示例里面就是被观察者的
join
- 增加新的观察者在我们的示例里面就是被观察者的
缺点
- 代码中观察者和观察目标相互引用,存在循环依赖,观察目标会触发二者循环调用,有引起系统崩溃的风险
- 如果一个观察目标对象有很多直接和间接观察者,将所有的观察者都通知到会耗费大量时间。
- 因为要遍历观察者容器内的所有元素。
- 观察者模式没有相应的机制让观察者知道所观察的目标对象是怎么发生变化的,而仅仅只是知道观察目标发生了变化。
总结
- 适用场景
- 一个对象的改变会引起其他对象的联动改变,但并不知道是哪些对象会产生改变以及产生什么样的改变
- 如果需要设计一个链式触发的系统,可是使用观察者模式
- 广播通信、消息更新通知等场景。
- 成就系统
策略模式(Strategy)
我们在模板笔记的19.2中提到了策略模式。在那个部分中,策略模式的核心是使用一个模板参数做为策略类的选项,来为一个商定好的具体接口提供不同的实现方法。当然了,核心就是如此。只不过我们当时的重点是模板。但是在这里我们的重点是设计模式本身。策略模式也不一定非得采取模板的方式来实现。
结构
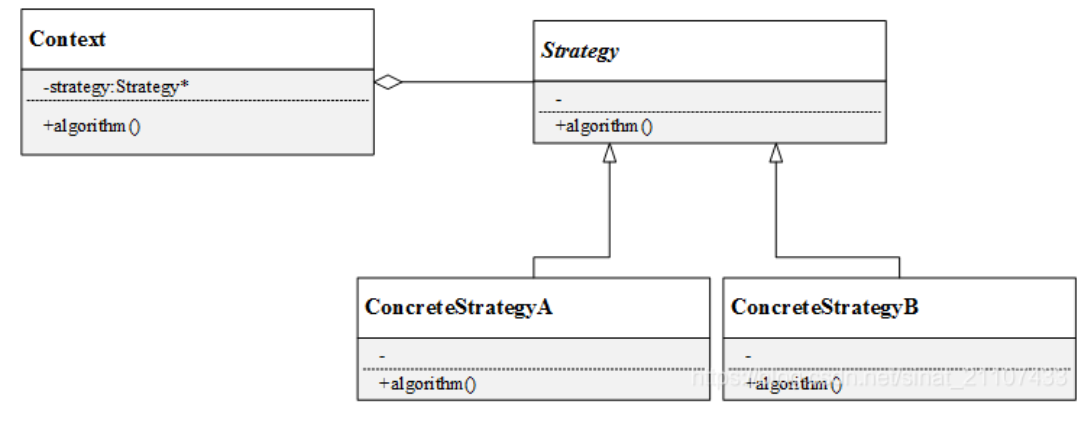
- Context(上下文类) ︰上下文类是使用算法的角色,可以在解决不同具体的问题时实例化不同的具体策略类对象。在动态策略模式中,上下文类通常包含一个抽象策略类的指针。静态策略模式中,则是在模板参数中传入具体策略类的类型。
- Strategy(抽象策略类)︰声明算法的方法,抽象层的设计使上下文类可以无差别的调用不同的具体策略的方法
- ConcreteStrategy(具体策略类):实现具体的算法
优点
- 策略模式符合开闭原则,用户可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为。
- 策略模式提供了管理相关的算法族的办法。
- 策略模式提供了可以替换继承关系的办法。也就是符合里氏替换原则
- 使用策略模式可以避免使用多重条件转移语句。
缺点
- 客户端必须知道所有的策略类,并自行决定使用哪一个策略类。
- 策略模式将造成产生很多策略类,可以通过使用享元模式在一定程度上减少对象的数量。
总结
通常而言,通过模板参数实现的策略模式,我们称之为静态策略模式。通过传入一个对象的方式实现的策略模式,我们称之为动态策略模式。两者各有利弊。动态策略模式因为使用了多态,会有一定的性能损耗。但是优点是可以灵活地在运行时更改策略。而静态模式因为使用了模板参数,虽然没有运行时性能损耗,但会有模板相关的代码膨胀。同时,由于模板参数是类型的一部分,不可能在运行时更换策略,这也限制了其灵活性。
我们发现策略模式和状态模式长得很像,那么他们有什么区别呢?可以通过环境类状态的个数来决定是使用策略模式还是状态模式。
- 策略模式的环境类自己选择一个具体策略类,具体策略类无须关心环境类;而状态模式的环境类由于外在因素需要放进一个具体状态中,以便通过其方法实现状态的切换,因此环境类和状态类之间存在一种双向的关联关系。
- 使用策略模式时,客户端需要知道所选的具体策略是哪一个,而使用状态模式时,客户端无须关心具体状态,环境类的状态会根据用户的操作自动转换。
如果系统中某个类的对象存在多种状态,不同状态下行为有差异,而且这些状态之间可以发生转换时使用状态模式;如果系统中某个类的某一行为存在多种实现方式,而且这些实现方式可以互换时使用策略模式。
- 命令模式在某些时候可能和策略模式非常像。但是有一种方法可以区分
- 策略模式强调如何去做(HOW)
- 命令模式强调做了什么(WHAT)
- 来自这里

模板方法模式(Template Method)
这玩意和模板没有任何关系。而且是最简单的设计模式。就是继承+虚函数+重写的多态。没了。
STL在pmr::memory_resource中使用了这种模式。来自这里
访问者模式 (Visitor)
访问者模式的其中一种的核心是double-dispatch。我们在more effective c++的条款31中提到过这一点。
但是还是有些许差别。非访问者模式的double-dispatch是s.cpp。访问者模式的double-dispatch是sv.cpp
我们能看到,在两个文件中由于具体业务原因,并没有对象结构类。含有对象结构类的访问者模式在文件夹visitor中。同时,非访问者模式中,我们的所有相关函数都叫print。而且没有抽象访问者类。而访问者模式中,我们把print分离出来为accept和visit。同时新增了抽象访问者类。然后具体的访问原理在代码注释,并且和more effective c++中讨论的原理是几乎一致的。
当然,也可以去掉抽象访问者类然后使用模板参数来替代。同时也可以不使用more effective c++中讨论的第二种方法也就是像现在一样只使用虚函数,可以换回dynamic_cast方法
结构
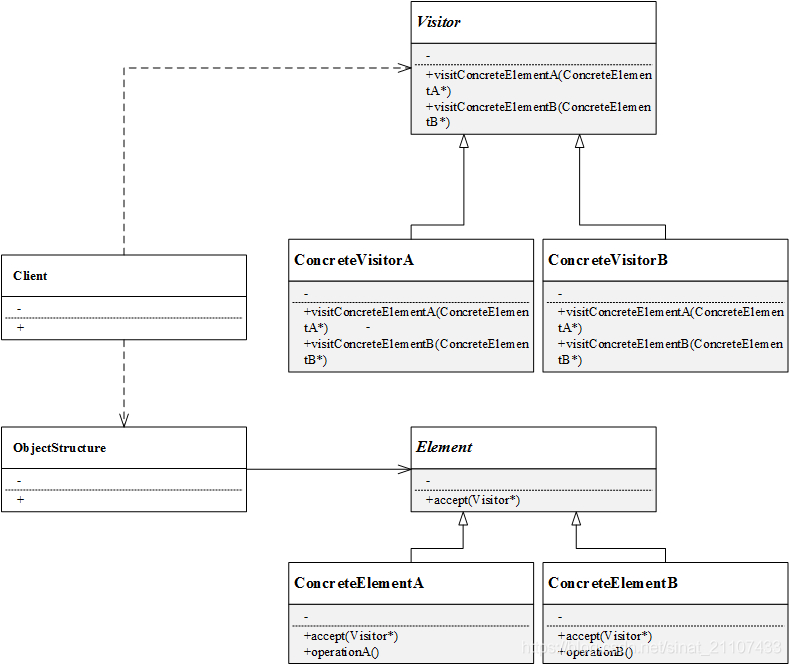
从上图和前述可以看出,访问者模式中有两个层次结构:
- 访问者的层次结构
- 抽象访问者和具体访问者,不同的具体访问者有不同的访问方式(
visit()方式)
- 抽象访问者和具体访问者,不同的具体访问者有不同的访问方式(
- 被访问元素的层次结构
- 抽象元素和具体元素,不同的具体元素有不同的被访问方式(
accept()方式)
- 抽象元素和具体元素,不同的具体元素有不同的被访问方式(
- Visitor(抽象访问者):抽象类,声明了访问对象结构中不同具体元素的方法
visit(),由方法名称可知该方法将访问对象结构中的某个具体元素 - ConcreteVisitor(具体访问者):访问某个具体元素的访问者,实现具体的访问方法
visit() - Element(抽象元素)∶抽象类,一般声明一个
accept()的方法,用于接受访问者的访问,accept()方法常常以一个抽象访问者的指针作为参数 - ConcreteElement(具体元素):针对具体被访问的元素,实现
accept()方法 - ObjectStructure(对象结构):元素的集合,提供了遍历对象结构中所有元素的方法。对象结构存储了不同类型的元素对象,以供不同的访问者访问。
优点
- 增加新的访问者很方便,即增加一个新的具体访问者类,定义新的访问方式,无需修改原有代码,符合开闭原则;
- 被访问元素集中在一个对象结构中,类的职责更清晰,利于对象结构中元素对象的复用;
缺点
- 增加新的元素类很困难,增加新的元素时,在抽象访问者类中需要增加一个对新增的元素方法的声明,即要修改抽象访问者代码。此外还要增加新的具体访问者以实现对新增元素的访问,不符合开闭原则;
- 破坏了对象的封装性,访问者模式要求访问者对象访问并调用每一个元素对象的操作,那么元素对象必须暴露自己的内部操作和状态,否则访问者无法访问。
总结
其实访问者模式就是基于double-dispatch。具体的无需多言了。
有用的资料
Design Patterns: Facts and Misconceptions - Klaus Iglberger - CppCon 2021
类型擦除
https://www.youtube.com/watch?v=4eeESJQk-mw
- 类型擦除有五种:多态,模板,容器,通用类型,闭包。
https://zhuanlan.zhihu.com/p/99532906
我们有最经典的C风格类型擦除。就是全都转换成
void*。但是它类型不安全。什么是类型擦除?我们从生活例子说起。
我们有shape类,然后有circle和square继承自shape。很合理对吧?
然后针对每一个子类,都要有一个draw。所以draw是虚函数。很合理对吧?
问题来了。不同的引擎要用不同的方式draw。所以我们要有metaldraw,opengldraw。所以我们要为每一个draw设计为一个单独的类。这样就会有metalcircle, openglcircle, metalsquare, openglsquare。每一个类有一个自己的draw。
这时候我们不仅仅要画了,还要序列化。而这个序列化是要依赖于我们的四个子类的。这时候有Aserializeopenglsquare, bserializeopenglsquare….
这是噩梦。
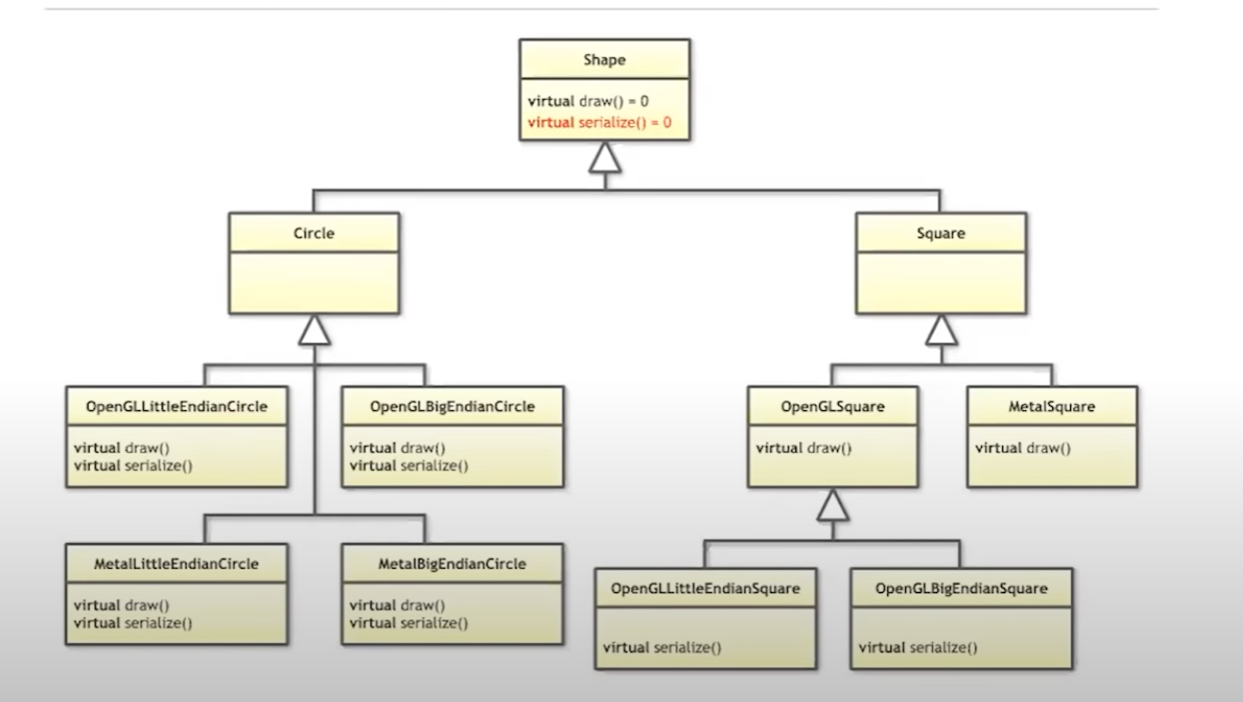
- 我们学习了设计模式,这时候可以使用策略模式。也就是把draw作为一种策略嵌入到我们的每一个子类中。
我们有drawstrategy。这个类有openglstrategy和metalstrategy。openglstrategy下面可以有openglcirclestrategy和openglsquarestrategy。
我们的circle和square内部拥有一个drawstrategy类型的实例(指针,对象都可以)。构造circle或square对象的时候从外部传入对应的到底是openglstrategy还是metalstrategy。我们circle和square内部的draw只需要通过这个策略类实例调用策略类的draw就好了。
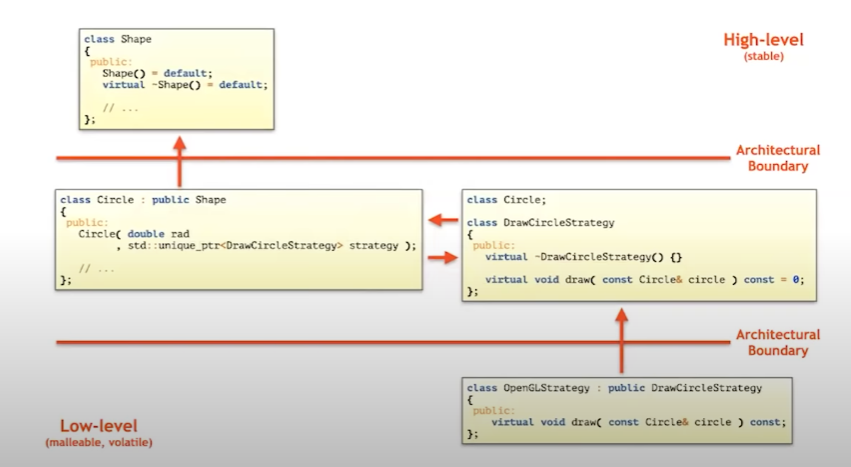
- 但是还有问题。它性能不好,指针太多,虚函数太多,等等等等。怎么办?类型擦除。
类型擦除的特点
类型擦除不是:
- 不是
void*指针。我们确实不再关心类型,但是这是错误理解。不是C那种做法了。 - 不是一个指向基类的指针。这就回到了多态。
- 也不是
std::variant。variant其实是为封闭类型提供开放操作。而类型擦除是为开放类型提供封闭操作。
类型擦除是:
- 构造函数模板 和
- 完全不含有虚机制的接口 和
- 三个设计模式的结合:外部多态(external polymorphism) + 桥接(bridge) + 原型(prototype)
把我们刚才的例子换成类型擦除


- 现在我们的circle和square不需要知道任何关于draw和序列化的事情。他们只是单纯的几何基类。拥有必要的几何元素。