C++ STL - 1 - List
List
G2.9
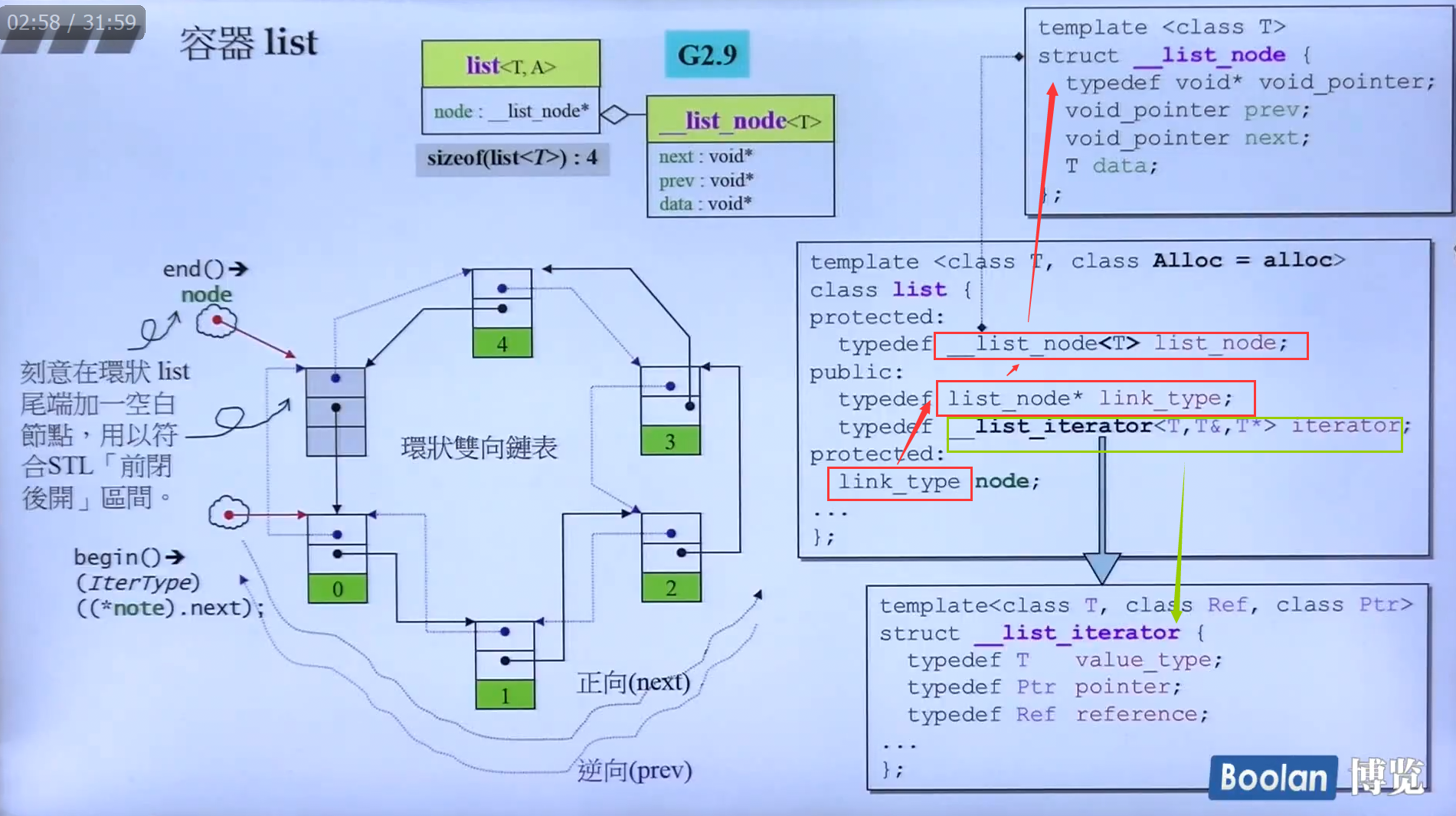
List自己本身只有一个指针指向了一个节点。它的数据__list_node和数据结构list是分开设计的。
数据本身不做过多叙述。一个指针指向前一个节点,一个指针指向下一个节点,一块数据区域。
List的迭代器
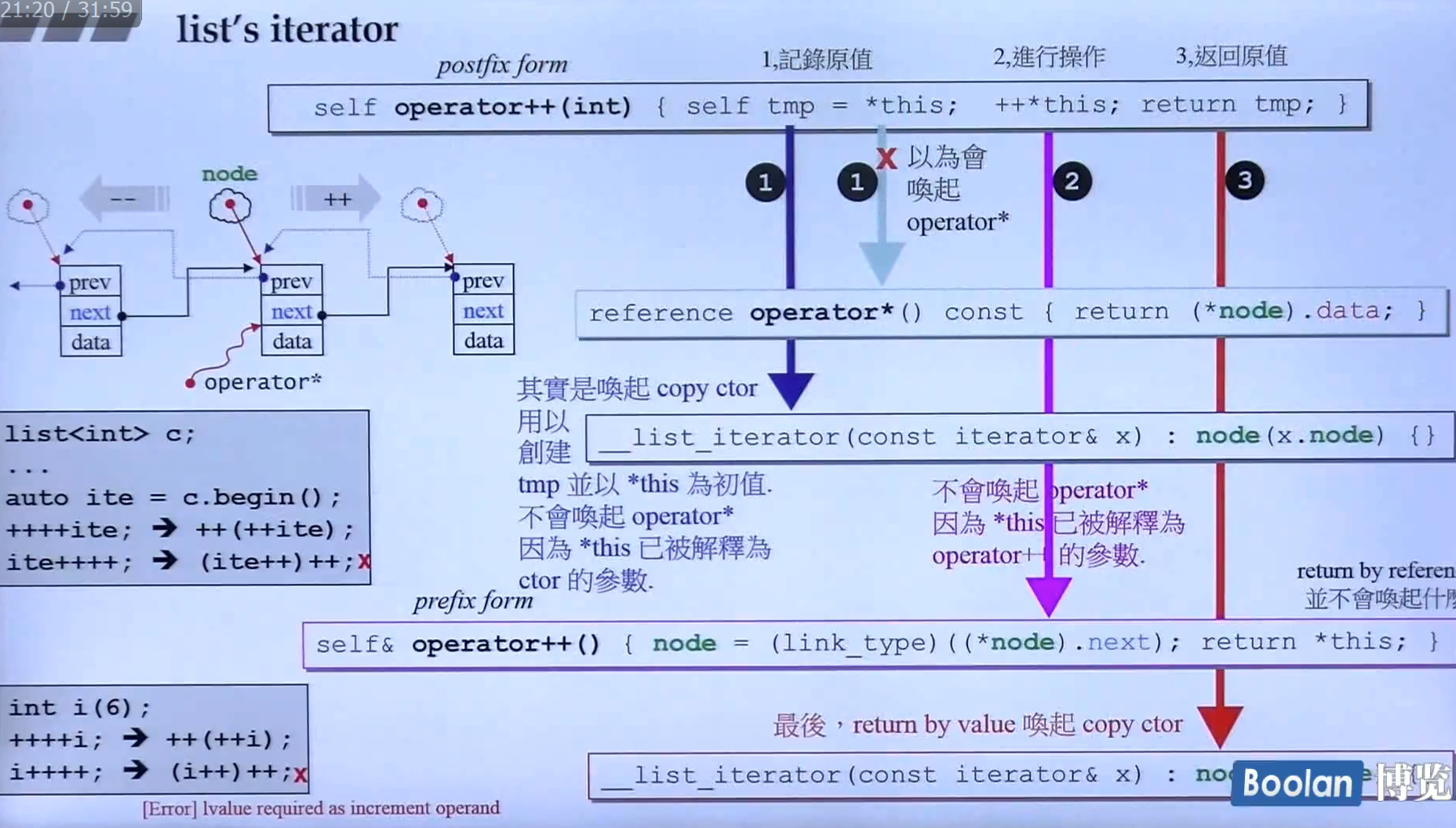
注意i++和++i的重载区别
在C++中,由于
++i和i++都只有一个参数,那么如何对这两种分别进行重载呢?- 在C++中,规定了带有参数的是后置++,没有参数的是前置++。比如说
operator++(int) {}; //对i++进行重载operator++() {}; //对++i进行重载
- 在C++中,规定了带有参数的是后置++,没有参数的是前置++。比如说
注意点:
1.后置++的* 操作符不是解引用,而是调用了拷贝构造函数来制造一个副本
2.为了模拟C++的整数不能进行如下操作:
1 2 3 4
(i++)++; //不允许 i++++; //不允许 (++i)++; //允许 ++++i; //允许
记住,i++是右值。++i是左值。
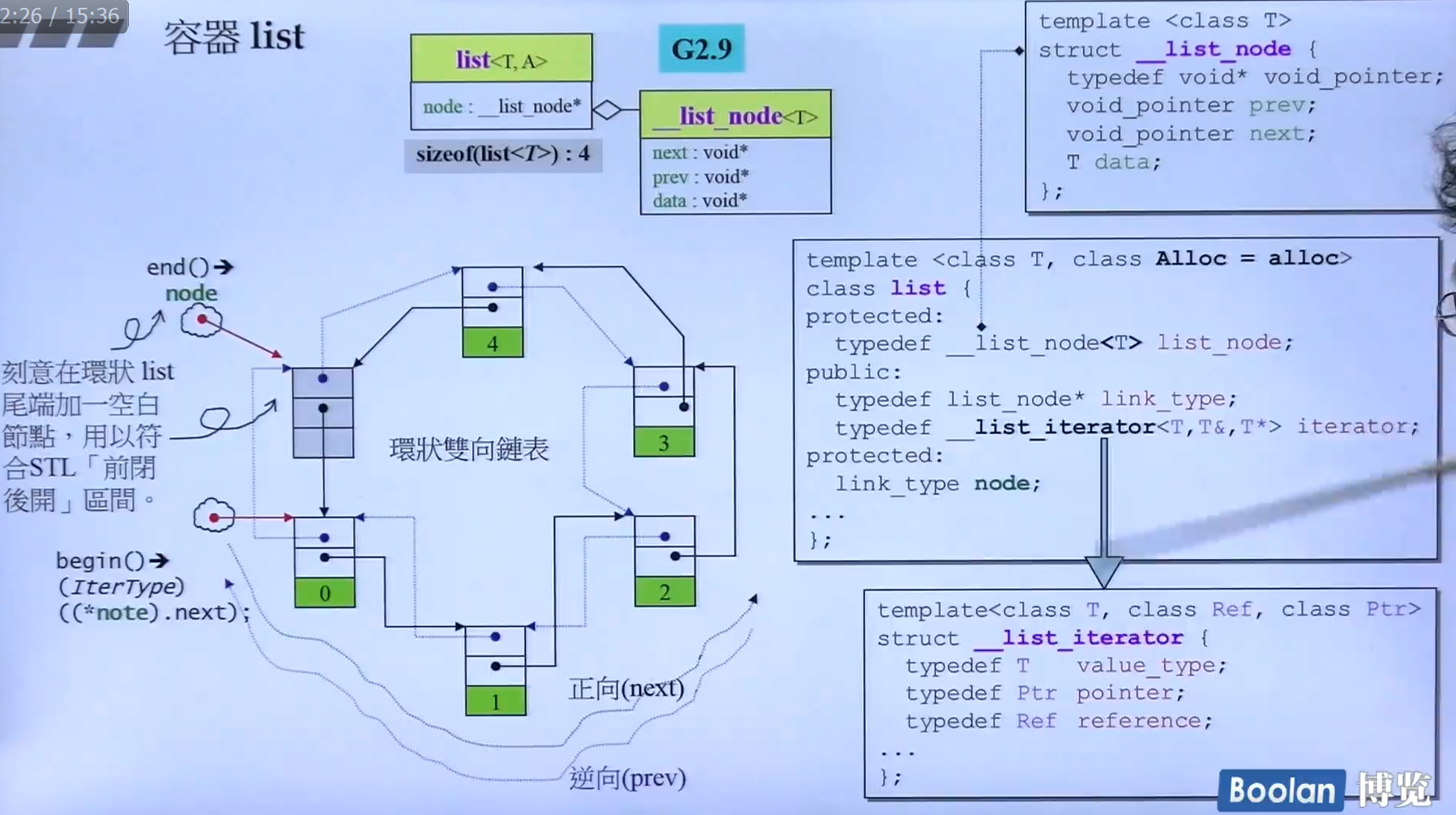
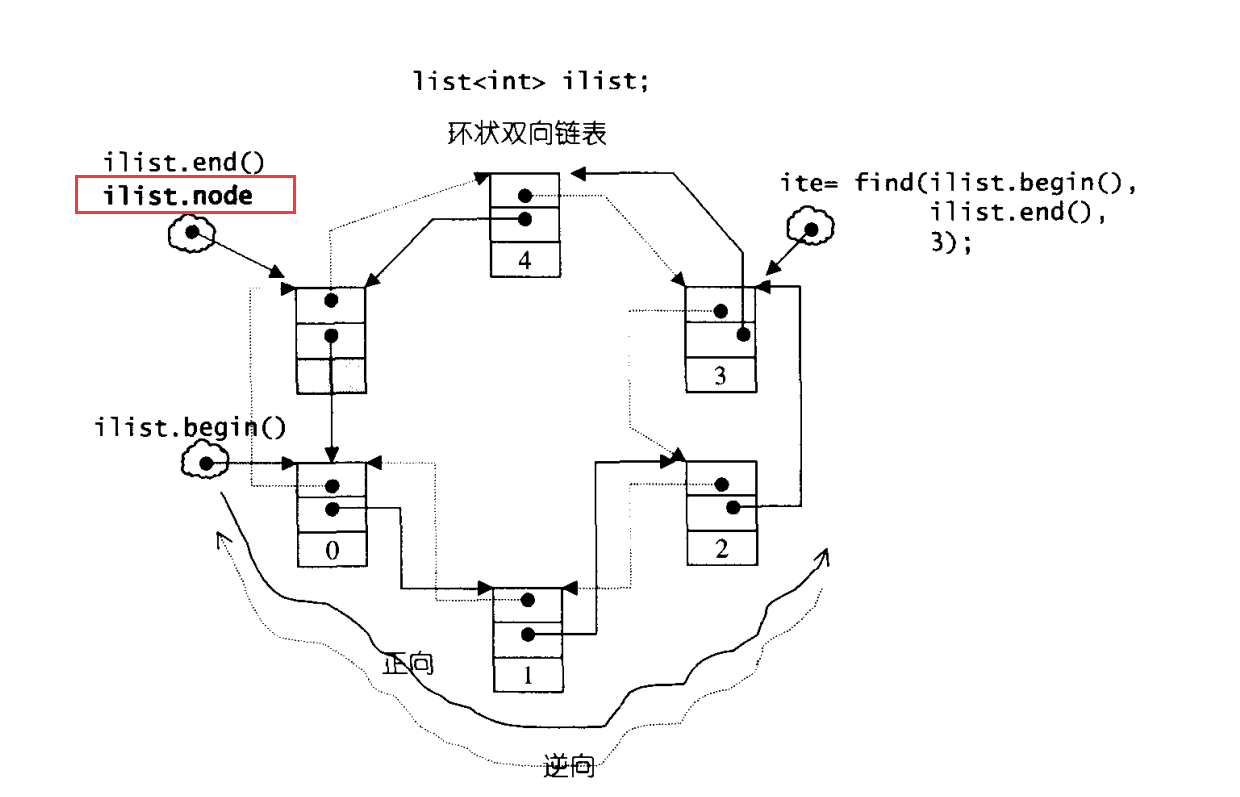
List为了满足STL的前闭后开区间原则,会在末尾处添加一个空白的节点。什么是前闭后开?STL迭代器的end()是超尾的。也就是指向最后一个元素的下一个。
一般来说。一开始我们看到的List本身的那一个指针就是指向的这个空节点。
迭代器内部的node指针 link_type node是他自己的。

我们使用迭代器的时候一般会 list<int>::iterator iter = list.begin(); 或 list<int>::iterator iter2(list.begin());这样来赋值。begin()会返回一个对应类型的迭代器。如果放入这个例子的话就是将对应类型的迭代器赋值给了迭代器iter自己的node指针。然后进行操作。

这里这张图是list本身。红框的node不是迭代器的node。是list自己的node。我们可以看见node指向了超尾。因为是双向循环链表,所以begin就是node指向的节点的next部分。这里的begin()和end()里面,首先把指向节点的指针也就是*node.next转型成link_type(因为这个指针的类型是void*) 然后转型为iterator。
这里是怎么把link_type转换成iterator类型的呢?这里他的返回值使用了构造函数进行隐式转换。我们看上上张图。通过typedef我们知道iterator就是__list_iterator。然后我们发现 __list_iterator类中的其中一个构造函数(上上张图的绿框)接受一个link_type的参数。而刚好,我们begin()函数的返回值刚好是link_type。然后函数头声明的返回值是iterator类型的。这时候就自动调用了iterator(__list_iterator)类的接受link_type类型的参数的构造函数进行了隐式转换。
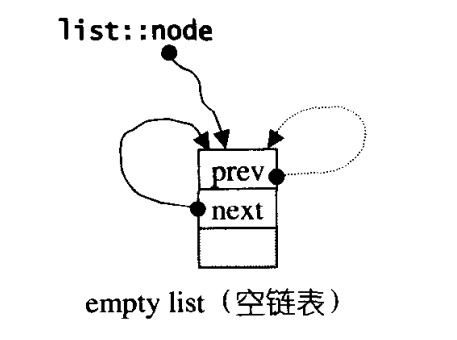
空链表长这样。
总结:
list自己只有一个指针,是一个迭代器。一开始这个迭代器会指向end。因为begin()函数会去访问这个迭代器,找到这个迭代器指向的list的实际节点的next指针,把这个next指针返回出来。也就是把next指针指向的地址(下一个节点地址)拿回来。
增删时间复杂度
- 任何位置的插入删除:O(1)(假设告诉了你插入删除的位置,不需要你线查找再删除)
- 头尾查询:O(1)
- 其他位置查询:O(N)
隐式类型转换
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
class tmp{
public:
string _text;
tmp(string c): _text(c) {}
};
class test{
public:
string _text;
test(string a): _text(a){}
/*explicit*/ test(tmp s): _text(s._text){} //test类的构造函数接受tmp类型的对象。
};
class twonumber{
public:
test ret(){
test(tmp("cde"));
return(tmp("abc")); //此处返回的对象是一个tmp,但是函数头的返回类型却是test。因为这里使用了构造函数的隐式转换。也就是test类的构造函数接受tmp类型的对象
//!由于return语句内是隐式转换,所以对应的构造函数如果有explicit关键字则无法进行隐式转换。
有四种情况会发生隐式类型转换
- 混合类型的算数运算表达式。
1 2 3
int a = 3; double b = 4.5; a + b; // a将会被自动转换为double类型,转换的结果和b进行加法操作
- 不同类型的赋值操作。
1 2
int a = true ; ( bool 类型被转换为 int 类型) int * ptr = null;(null被转换为 int *类型)
- 函数参数传值
1 2
void func( double a); func(1); // 1被隐式的转换为double类型1.0
- 函数返回值。(此处例子)
1 2 3 4
double add( int a, int b) { return a + b; } //运算的结果会被隐式的转换为double类型返回
哈希表
线性探测:
我们有一个容器,把元素用hashfunction哈希过后,放入容器内。如果发生冲突就往后移动一个,直到找到空位。如果放入的元素数量等于了容器大小,就要放到一个新容器内,元素也需要rehash。在此情况下,最坏的时候就是线性搜索整个数组,平均情况就是巡访一半数组。
二次探测:
在线性探测的基础上,冲突的时候并不单纯移动一个,而是用一个方程再次hash。如果我们假设桶的大小M为质数,而且永远保持负载系数在0.5以下(也就是说超过0.5就重新配置并重新整理桶中的元素),那么可以确定每插入一个新元素所需要的探测次数不多于2。
STL 开链法
- 哈希表的装bucket的是vector。vector的每一个下标对应的元素是一个bucket。
- bucket储存了一个单向链表。如果发生哈希冲突就挂在链表上。
- 但是如果一直发生冲突,则链表会越来越长,效率会越来越低。所以一旦元素数量大于桶的数量,就会扩容,大小为当前容量一倍的容量附近的质数。然后元素需要rehash。
- 需要删除的元素只有在rehash的时候在会被删除。
- 装桶的vector的大小是有提前定义的。质数。
deque
deque的核心是分段连续区间。这是依靠一个控制区块来完成的。
- 控制区块可以是一个vector。vector的每个元素储存着一个指向实际数据区域的指针。
- deque自己的数据:
- 一个指向中控器的指针
- 一个整数,表达的是中控器的大小
- 一个迭代器,指向deque的第一个分配的数据区域(
deque::begin()传回这个) - 一个迭代器,指向deque的最后一个分配的数据区域(
deque::end()传回这个)
- deque自己的迭代器是不一样的:
- 一个指针指向当前数据
cur - 一个指针指向当前数据区块的头
first - 一个指针指向当前数据区块的尾
last - 一个指针指向中控器 (自己当前所在的位置)
node
- 一个指针指向当前数据
增删时间复杂度
deque是两头开。所以除了中间以外,增删都是O(1)
- 头部尾部插入删除:O(1)
- 中间插入删除:O(N)
- 查找:O(N)
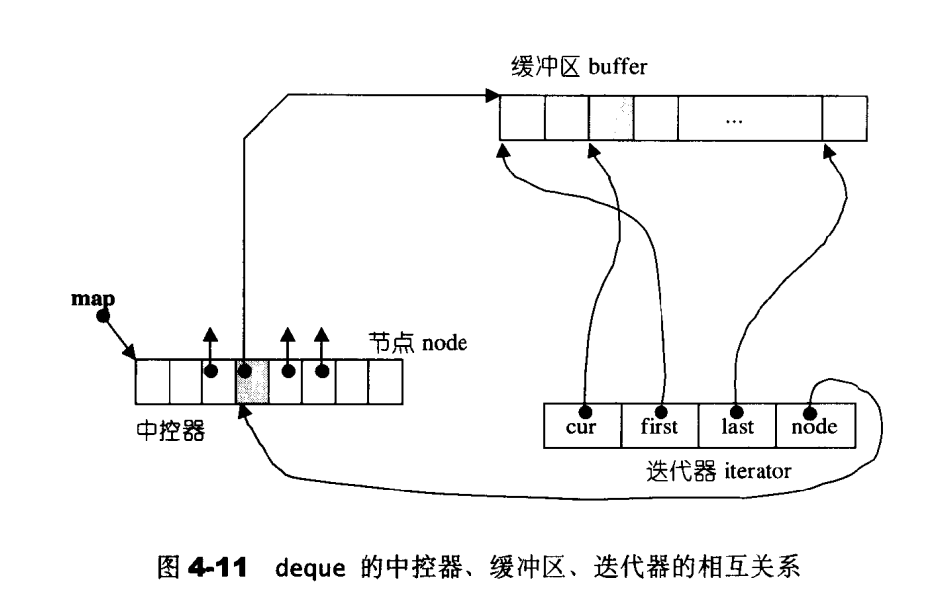
vector
vector自己是三根指针。储存数据的区域是一个连续的线性内存空间也就是个数组。
- 一个迭代器
start指向内存分配起始位置(vector::begin()返回这个) - 一个迭代器
finish指向当前最后一位数据的下一个位置(记住end是超尾,需要指向最后一个数据的下一位。vector::end()返回这个)。size就是这个迭代器和start的距离。 - 一个迭代器
end_of_storage指向内存分配的最后位置。(capacity就是这个迭代器和start的距离)
2倍扩容
增删时间复杂度
由于vector在除尾部外的位置对数据进行增添或删除会导致元素搬移,所以头部和中间都是O(N)
- 头部插入删除:O(N)
- 中间插入删除:O(N)
- 尾部插入删除:O(1)
- 查找:O(N)
stack 容器适配器
栈的底层容器可以接受deque或vector或list。默认是deque
queue 容器适配器
队列的底层容器可以接受deque或list。默认是deque
priority_queue 容器适配器
优先队列的底层是堆。底层容器接受vector或deque。默认是vector
- 优先队列的
top函数返回的是const的值。所以无法直接修改在优先队列内的元素的值。如pri_queue.top()++;这样的行为是禁止的。- 可以理解,因为堆是把整个元素当做排序依据的。也就是
元素无法更改。如果更改必然会对数据结构进行破坏。所以只能进行拿出,修改,再插入这样的操作。
- 可以理解,因为堆是把整个元素当做排序依据的。也就是
- 构建优先队列需要堆排序。所以构建优先队列的时间复杂度是线性的
O(nlogn) - 优先队列采用堆排序,由于堆排序的特性,入队后的队列(最大堆/最小堆)只保证父节点比子节点大或者小,他不保证子节点的绝对顺序。 所以如果把内容放入优先队列后,直接查看内存会发现并不保证绝对顺序。但是出队的时候是保证顺序的。
使用std::bind搭配priority_queue 和 vector的自定义排序。
注意优先队列的自定义排序器需要做为参数传入。注意在传入匿名对象的时候应使用花括号避免语义问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
#include <iostream>
#include <string>
#include<memory>
#include <queue>
#include <functional>
#include <algorithm>
using namespace std;
/*
text 我们的目的是传入一个数字X,让容器内的数字依据和X的差值进行排序。
*/
class mycomp{ //&priority_queue 的比较器
public:
bool operator()(int a, int b, int x){
if(abs(a-x) >= abs(b-x)){
return false;
}
return true;
}
};
class mycomp1{ //&vector 的比较器。注意和优先队列是相反的。
public:
bool operator()(int a, int b, int x){
if(abs(a-x) <= abs(b-x)){
return false;
}
return true;
}
};
void func(vector<int>& vec, int x){
sort(vec.begin(), vec.end(), bind(mycomp1(), placeholders::_1, placeholders::_2, x)); //&使用bind对sort所需的自定义比较器参数进行绑定。
auto cmp = [=](int a, int b) { return abs(a-x)< abs(b-x); };//&使用lambda做为自定义比较器
priority_queue<int, vector<int>, decltype(cmp)> my_que{cmp}; //%注意,类型使用decltype自动推导,并且需要在优先队列构造函数内传入该比较器对象。
//* 可以换成花括号。尤其是当要传入一个匿名对象的时候,防止语义问题。
auto cmp1 = bind(mycomp(), placeholders::_1, placeholders::_2, x); //&使用bind生成的可调用对象做为自定义比较器
priority_queue<int, vector<int>, decltype(cmp1)> my_que1(cmp1);//%注意,类型使用decltype自动推导,并且需要在优先队列构造函数内传入该比较器对象。
priority_queue<int, vector<int>, decltype(bind(mycomp(), placeholders::_1, placeholders::_2, x))> my_que2(bind(mycomp(), placeholders::_1, placeholders::_2, x)); //直接写入。会非常长。
//------测试部分---------
for(int i = 0; i < vec.size(); i++){
my_que1.push(vec[i]);
my_que.push(vec[i]);
my_que2.push(vec[i]);
}
cout <<"myque" << endl;
while(!my_que.empty()){
cout << my_que.top() << endl;
my_que.pop();
}
cout << "myque1" << endl;
while(!my_que1.empty()){
cout << my_que1.top() << endl;
my_que1.pop();
}
cout << "myque2" << endl;
while(!my_que2.empty()){
cout << my_que2.top() << endl;
my_que2.pop();
}
}
int main(){
vector<int>a {1,2,3,9,100,7,5};
func(a, 2);
cout <<"vec" << endl;
for(auto& i:a){
cout <<i << endl;
}
return 0;
}
下面是简单的版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
class mycomp{ //&priority_queue 的比较器
public:
bool operator()(int a, int b){
if(abs(a-5) >= abs(b-5)){
return false;
}
return true;
}
};
int main(){
priority_queue<int,vector<int>, mycomp>my_que{mycomp()}; //传入匿名对象使用花括号。
my_que.push(10);
return 0;
}
set
set不允许更改值
- 因为set的
key和data是同一个东西,也就是value。- 我们是依靠这个值进行红黑树排序
- 但是set不允许更改值是因为迭代器返回的是常量迭代器也就是
const iterator - map不允许更改key是因为保存至红黑树的pair里面的key是const的。
set不会重复插入且不允许重复元素的原因
set使用的红黑树的insert_unique
multi_set使用的红黑树的insert_equal
map
map不允许重复key。
multi_map允许重复key
map不会重复插入且不允许重复key的原因
map使用的红黑树的insert_unique
multi_map使用的红黑树的insert_equal